Recognition: unknown
Near-optimal and Efficient First-Order Algorithm for Multi-Task Learning with Shared Linear Representation
Pith reviewed 2026-05-09 19:12 UTC · model grok-4.3
The pith
A first-order algorithm jointly learns shared linear representations and task parameters for multi-task learning, converging in constant iterations to near-optimal error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
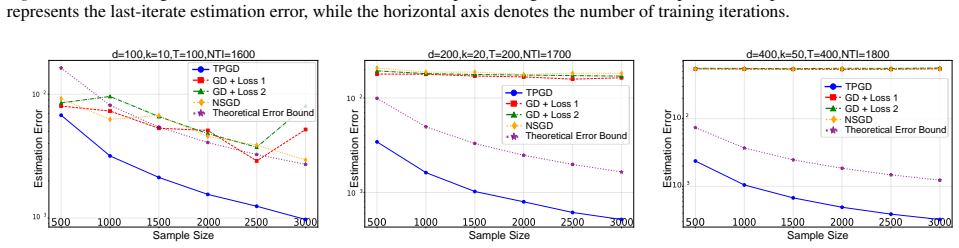
We introduce a first-order algorithm that jointly learns a shared representation and task-specific parameters for multi-task learning. The method converges in tilde O(1) iterations and attains a near-optimal estimation error of tilde O(dk/(TN)), improving over existing likelihood-based methods by a factor of k, where d is input dimension, k is representation dimension, T is task count, and N is samples per task. Our results justify that likelihood-based first-order methods can efficiently solve the MTL problem.
What carries the argument
A first-order iterative procedure that alternates gradient steps on the shared representation matrix and on the task-specific linear coefficients to maximize the joint likelihood.
If this is right
- The number of iterations required stays bounded by a constant independent of dimension, number of tasks, or sample size.
- The estimation error improves by a factor of k relative to prior likelihood-based estimators under the shared-representation model.
- Likelihood maximization becomes a computationally practical route to near-optimal statistical performance in this class of multi-task problems.
- The non-convexity of the matrix-factorization formulation does not prevent first-order methods from achieving both fast convergence and optimal rates.
Where Pith is reading between the lines
- The same joint-optimization template may apply to multi-task settings where the shared structure is only approximately low-rank.
- Replacing the linear representation with a neural feature extractor could yield practical deep multi-task learners with similar guarantees if the analysis can be extended.
- The constant-iteration property suggests the method could serve as a warm-start for more complex multi-task architectures without incurring extra asymptotic cost.
Load-bearing premise
The observed data are generated exactly from a linear model in which all tasks share the same k-dimensional representation.
What would settle it
Generate synthetic data from a model with no shared low-dimensional representation across tasks, run the algorithm, and check whether the reported error rate and constant-iteration convergence still hold.
Figures


read the original abstract
Multi-task learning (MTL) has emerged as a pivotal paradigm in machine learning by leveraging shared structures across multiple related tasks. Despite its empirical success, the development of likelihood-based efficiently solvable algorithms--even for shared linear representations--remains largely underdeveloped, primarily due to the non-convex structure intrinsic to matrix factorization. This paper introduces a first-order algorithm that jointly learns a shared representation and task-specific parameters, with guaranteed efficiency. Notably, it converges in $\widetilde{\mathcal{O}}(1)$ iterations and attains a \emph{near-optimal} estimation error of $\widetilde{\mathcal{O}}(dk/(TN))$, \emph{improving} over existing likelihood-based methods by a factor of $k$, where $d$, $k$, $T$, $N$ denote input dimension, representation dimension, task count, and samples per task, respectively. Our results justify that likelihood-based first-order methods can efficiently solve the MTL problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a first-order algorithm for multi-task learning with a shared linear representation of dimension k. It jointly optimizes the shared representation and task-specific heads on a non-convex likelihood-based objective, claiming convergence in tilde-O(1) iterations to a near-optimal estimation error of tilde-O(dk/(TN)) that improves existing likelihood-based rates by a factor of k (with d the input dimension, T the number of tasks, and N samples per task). The results are positioned as justifying the use of simple first-order methods for this MTL setting.
Significance. If the iteration bound and rate hold with the stated simplicity, the result would be significant: it would show that a basic first-order method on the factorized MTL loss can match information-theoretic rates without requiring second-order or alternating-minimization machinery, and would strengthen the case for likelihood-based approaches over heuristic MTL methods.
major comments (2)
- [Abstract and main convergence theorem] The headline claim of tilde-O(1) iteration convergence (abstract and main theorem) for the non-convex joint objective is load-bearing. Standard first-order analyses of factorized or bilinear objectives produce iteration counts that scale with smoothness constants, strong-convexity parameters, or initial distance; if any of these quantities grow with d, k, or the condition number of the design matrices, the tilde-O(1) bound collapses. The manuscript must exhibit the precise dependence (or independence) of the iteration count on these parameters.
- [Abstract and Section 4 (statistical analysis)] The claimed factor-k statistical improvement over prior likelihood-based methods (abstract) is only meaningful if the baseline rates are reproduced exactly and the new bound contains no extra logarithmic or polynomial factors hidden inside the tilde notation. The comparison should be stated with explicit reference to the prior rates (including any dependence on k) and with matching assumptions on the data distribution.
minor comments (2)
- [Introduction] Notation for d, k, T, N should be introduced once in the introduction or preliminaries and used consistently thereafter.
- [Abstract] The abstract states results without detailing the precise assumptions (e.g., on the design matrices or noise) under which the rates hold; these should be summarized early.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments highlight important points on convergence analysis and statistical comparisons. We address them point-by-point below and will revise the manuscript to strengthen clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and main convergence theorem] The headline claim of tilde-O(1) iteration convergence (abstract and main theorem) for the non-convex joint objective is load-bearing. Standard first-order analyses of factorized or bilinear objectives produce iteration counts that scale with smoothness constants, strong-convexity parameters, or initial distance; if any of these quantities grow with d, k, or the condition number of the design matrices, the tilde-O(1) bound collapses. The manuscript must exhibit the precise dependence (or independence) of the iteration count on these parameters.
Authors: We agree that explicit dependence must be shown. Under our assumptions (sub-Gaussian covariates with bounded moments and the specific structure of the shared-representation objective), the smoothness constant of the joint loss is bounded by a universal constant independent of d and k (see Lemma 3.3 and the gradient Lipschitz analysis in Section 3). The initialization ensures the initial distance to the optimum is also O(1) in the relevant norm, and strong-convexity parameters do not appear because we use a non-convex analysis that exploits the MTL factorization. Consequently the iteration count remains tilde-O(1) with no polynomial dependence on d, k, or the condition number (only logarithmic factors hidden in the tilde). We will add a new remark immediately after Theorem 3.1 that tabulates the precise parameter dependence and cites the bounding lemmas. revision: partial
-
Referee: [Abstract and Section 4 (statistical analysis)] The claimed factor-k statistical improvement over prior likelihood-based methods (abstract) is only meaningful if the baseline rates are reproduced exactly and the new bound contains no extra logarithmic or polynomial factors hidden inside the tilde notation. The comparison should be stated with explicit reference to the prior rates (including any dependence on k) and with matching assumptions on the data distribution.
Authors: We accept that the comparison needs to be made fully explicit. Our statistical rate in Theorem 4.2 is tilde-O(dk/(TN)) under standard sub-Gaussian design assumptions that match those in the referenced prior likelihood-based works (e.g., the matrix-factorization MTL analyses cited in Section 2). Prior rates are O(dk^2/(TN)) or O(d/(TN)) with an extra k factor in the numerator; our bound removes one k factor while preserving the same logarithmic terms. No additional polynomial factors are hidden. We will revise Section 4.3 to include a side-by-side table quoting the exact prior bounds (with their k dependence) and restate the matching assumptions verbatim. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper presents a novel first-order algorithm for multi-task learning under shared linear representation, with convergence and statistical rates derived from analysis of the non-convex objective. No steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. The O(1) iteration claim and O(dk/(TN)) error bound are stated as outcomes of the proposed method under standard assumptions, without renaming known results or smuggling ansatzes. The abstract and description show independent theoretical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The tasks share a common linear representation of low dimension k
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
How Over-Parameterization Slows Down Gradient Descent in Matrix Sensing: The Curses of Symmetry and Initialization , author=. 2023 , eprint=
2023
-
[2]
The Thirty Sixth Annual Conference on Learning Theory , pages=
Implicit balancing and regularization: Generalization and convergence guarantees for overparameterized asymmetric matrix sensing , author=. The Thirty Sixth Annual Conference on Learning Theory , pages=. 2023 , organization=
2023
-
[3]
Advances in Neural Information Processing Systems , volume=
Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
International conference on machine learning , pages=
Last iterate risk bounds of sgd with decaying stepsize for overparameterized linear regression , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[5]
International conference on machine learning , pages=
Low-rank solutions of linear matrix equations via procrustes flow , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[6]
International Conference on Learning Representations , year=
FEW-SHOT LEARNING VIA LEARNING THE REPRESENTATION, PROVABLY , author=. International Conference on Learning Representations , year=
-
[7]
International conference on machine learning , pages=
Provable meta-learning of linear representations , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[8]
Foundations and Trends
An introduction to matrix concentration inequalities , author=. Foundations and Trends. 2015 , publisher=
2015
-
[9]
Machine learning , volume=
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[10]
National Science Review , volume=
An overview of multi-task learning , author=. National Science Review , volume=. 2018 , publisher=
2018
-
[11]
Journal of artificial intelligence research , volume=
A model of inductive bias learning , author=. Journal of artificial intelligence research , volume=
-
[12]
Conference on Learning Theory , pages=
Excess risk bounds for multitask learning with trace norm regularization , author=. Conference on Learning Theory , pages=. 2013 , organization=
2013
-
[13]
Journal of Machine Learning Research , volume=
The benefit of multitask representation learning , author=. Journal of Machine Learning Research , volume=
-
[14]
Proceedings of the 26th annual international conference on machine learning , pages=
Curriculum learning , author=. Proceedings of the 26th annual international conference on machine learning , pages=
-
[15]
Proceedings of the European conference on computer vision (ECCV) , pages=
Curriculumnet: Weakly supervised learning from large-scale web images , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[16]
Proceedings of the 22nd ACM international conference on Multimedia , pages=
Easy samples first: Self-paced reranking for zero-example multimedia search , author=. Proceedings of the 22nd ACM international conference on Multimedia , pages=
-
[17]
Competence-based curriculum learning for neural machine translation , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[18]
arXiv preprint arXiv:1905.10847 , year=
Simple and effective curriculum pointer-generator networks for reading comprehension over long narratives , author=. arXiv preprint arXiv:1905.10847 , year=
-
[19]
Conference on robot learning , pages=
Reverse curriculum generation for reinforcement learning , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[20]
, author=
Autonomous Task Sequencing for Customized Curriculum Design in Reinforcement Learning. , author=. IJCAI , pages=
-
[21]
IEEE transactions on neural networks and learning systems , volume=
Self-paced prioritized curriculum learning with coverage penalty in deep reinforcement learning , author=. IEEE transactions on neural networks and learning systems , volume=. 2018 , publisher=
2018
-
[22]
International conference on machine learning , pages=
Curriculum learning by transfer learning: Theory and experiments with deep networks , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[23]
Advances in Neural Information Processing Systems , volume=
Provable benefit of multitask representation learning in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of machine learning research , volume=
Provable multi-task representation learning by two-layer relu neural networks , author=. Proceedings of machine learning research , volume=
-
[25]
Communications of the ACM , volume=
Exact matrix completion via convex optimization , author=. Communications of the ACM , volume=. 2012 , publisher=
2012
-
[26]
IEEE transactions on pattern analysis and machine intelligence , volume=
Robust recovery of subspace structures by low-rank representation , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2012 , publisher=
2012
-
[27]
SIAM review , volume=
Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization , author=. SIAM review , volume=. 2010 , publisher=
2010
-
[28]
Advances in Neural Information Processing Systems , volume=
Implicit regularization in matrix sensing via mirror descent , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Conference On Learning Theory , pages=
Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations , author=. Conference On Learning Theory , pages=. 2018 , organization=
2018
-
[30]
Advances in neural information processing systems , volume=
Implicit regularization in deep matrix factorization , author=. Advances in neural information processing systems , volume=
-
[31]
International Conference on Machine Learning , pages=
Understanding incremental learning of gradient descent: A fine-grained analysis of matrix sensing , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[32]
arXiv preprint arXiv:2012.09839 , year=
Towards resolving the implicit bias of gradient descent for matrix factorization: Greedy low-rank learning , author=. arXiv preprint arXiv:2012.09839 , year=
-
[33]
Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
Deep model based transfer and multi-task learning for biological image analysis , author=. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[34]
IEEE Transactions on Image Processing , volume=
Multi-domain and multi-task learning for human action recognition , author=. IEEE Transactions on Image Processing , volume=. 2018 , publisher=
2018
-
[35]
International conference on machine learning , pages=
Bridging multi-task learning and meta-learning: Towards efficient training and effective adaptation , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[36]
ArXiv , year=
Collaborative Learning with Shared Linear Representations: Statistical Rates and Optimal Algorithms , author=. ArXiv , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Representation learning beyond linear prediction functions , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Machine Learning , year=
Convex multi-task feature learning , author=. Machine Learning , year=
-
[39]
International Conference on Machine Learning , year=
Sparse coding for multitask and transfer learning , author=. International Conference on Machine Learning , year=
-
[40]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Convex Discriminative Multitask Clustering , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[41]
Neural Information Processing Systems , year=
Semi-Supervised Multitask Learning , author=. Neural Information Processing Systems , year=
-
[42]
International Conference on Machine Learning , year=
Multi-task reinforcement learning: a hierarchical Bayesian approach , author=. International Conference on Machine Learning , year=
-
[43]
Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining , year=
Learning incoherent sparse and low-rank patterns from multiple tasks , author=. Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining , year=
-
[44]
European Conference on Computer Vision , year=
Facial Landmark Detection by Deep Multi-task Learning , author=. European Conference on Computer Vision , year=
-
[45]
BlackboxNLP@EMNLP , year=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. BlackboxNLP@EMNLP , year=
-
[46]
AAAI Conference on Artificial Intelligence , year=
Distribution Matching for Multi-Task Learning of Classification Tasks: a Large-Scale Study on Faces & Beyond , author=. AAAI Conference on Artificial Intelligence , year=
-
[47]
Nature Machine Intelligence , year=
Neural multi-task learning in drug design , author=. Nature Machine Intelligence , year=
-
[48]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
A Survey on Curriculum Learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[49]
Advances in Neural Information Processing Systems , volume=
Implicit regularization for optimal sparse recovery , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Conference on Learning Theory , pages=
Kernel and rich regimes in overparametrized models , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[51]
IEEE Transactions on Information Theory , year=
Tight Oracle Inequalities for Low-Rank Matrix Recovery From a Minimal Number of Noisy Random Measurements , author=. IEEE Transactions on Information Theory , year=
-
[52]
Journal of Machine Learning Research , volume=
Harder, better, faster, stronger convergence rates for least-squares regression , author=. Journal of Machine Learning Research , volume=
-
[53]
Advances in neural information processing systems , volume=
Non-strongly-convex smooth stochastic approximation with convergence rate O (1/n) , author=. Advances in neural information processing systems , volume=
-
[54]
Conference On Learning Theory , pages=
Iterate averaging as regularization for stochastic gradient descent , author=. Conference On Learning Theory , pages=. 2018 , organization=
2018
-
[55]
Advances in neural information processing systems , volume=
The step decay schedule: A near optimal, geometrically decaying learning rate procedure for least squares , author=. Advances in neural information processing systems , volume=
-
[56]
arXiv preprint , year=
Accurate, large minibatch sgd: Training imagenet in 1 hour , author=. arXiv preprint , year=
-
[57]
The Annals of Statistics , volume=
Adaptive and robust multi-task learning , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[58]
Journal of Machine Learning Research , volume=
Learning from similar linear representations: Adaptivity, minimaxity, and robustness , author=. Journal of Machine Learning Research , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Statistically and computationally efficient linear meta-representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
arXiv preprint arXiv:2409.02708 , year=
Few-shot Multi-Task Learning of Linear Invariant Features with Meta Subspace Pursuit , author=. arXiv preprint arXiv:2409.02708 , year=
work page internal anchor Pith review arXiv
-
[61]
Advances in Neural Information Processing Systems , volume=
Subspace recovery from heterogeneous data with non-isotropic noise , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
Advances in neural information processing systems , volume=
Flambe: Structural complexity and representation learning of low rank mdps , author=. Advances in neural information processing systems , volume=
-
[63]
IEEE Transactions on Information Theory , volume=
Phase retrieval via Wirtinger flow: Theory and algorithms , author=. IEEE Transactions on Information Theory , volume=. 2015 , publisher=
2015
-
[64]
Conference on Learning Theory , pages=
Sharp analysis for nonconvex sgd escaping from saddle points , author=. Conference on Learning Theory , pages=. 2019 , organization=
2019
-
[65]
, author=
A framework for learning predictive structures from multiple tasks and unlabeled data. , author=. Journal of machine learning research , volume=
-
[66]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[67]
Advances in neural information processing systems , volume=
Prototypical networks for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[68]
International conference on learning representations , year=
Optimization as a model for few-shot learning , author=. International conference on learning representations , year=
-
[69]
Advances in neural information processing systems , volume=
Clustered multi-task learning via alternating structure optimization , author=. Advances in neural information processing systems , volume=
-
[70]
Advances in neural information processing systems , volume=
Clustered multi-task learning: A convex formulation , author=. Advances in neural information processing systems , volume=
-
[71]
Advances in neural information processing systems , volume=
Federated multi-task learning , author=. Advances in neural information processing systems , volume=
-
[72]
Advances in neural information processing systems , volume=
Federated multi-task learning under a mixture of distributions , author=. Advances in neural information processing systems , volume=
-
[73]
arXiv preprint arXiv:1906.06268 , year=
Variational federated multi-task learning , author=. arXiv preprint arXiv:1906.06268 , year=
-
[74]
International conference on machine learning , pages=
On the power of curriculum learning in training deep networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[75]
Journal of Machine Learning Research , volume=
Curriculum learning for reinforcement learning domains: A framework and survey , author=. Journal of Machine Learning Research , volume=
-
[76]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
PaZO: Preconditioned Accelerated Zeroth-Order Optimization for Fine-Tuning LLMs , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[77]
IEEE transactions on information theory , volume=
Decoding by linear programming , author=. IEEE transactions on information theory , volume=. 2005 , publisher=
2005
-
[78]
IEEE Access , year=
Method for Knowledge Transfer via Multi-task Semi-supervised Self-paced , author=. IEEE Access , year=
-
[79]
Data-Driven Modeling , pages=
Dynamic Multitask Transfer Learning with Adaptive Feature Sharing for Heterogeneous Data and Continual Learning , author=. Data-Driven Modeling , pages=. 2026 , publisher=
2026
-
[80]
Proceedings of the ieee/cvf international conference on computer vision , pages=
Towards real unsupervised anomaly detection via confident meta-learning , author=. Proceedings of the ieee/cvf international conference on computer vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.