Recognition: unknown
Transformer-based End-to-End Control Filter Generation for Active Noise Control
Pith reviewed 2026-05-09 19:00 UTC · model grok-4.3
The pith
A Transformer directly generates active noise control filters end-to-end in an unsupervised system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
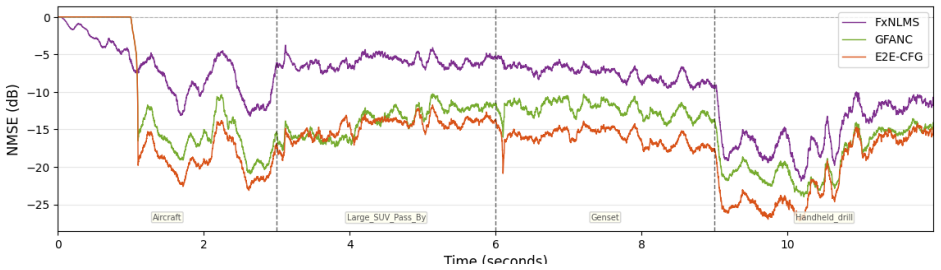
The E2E-CFG framework integrates the co-processor and real-time controller into a single differentiable ANC system so that a Transformer directly outputs control filters. Training uses only the accumulated error signal as the objective function, eliminating the decomposition-reconstruction process required by prior GFANC approaches and thereby avoiding error accumulation from that step. The attention mechanism captures global and dynamic noise features, and numerical tests on real-recorded noises show stronger reduction performance and greater adaptability than the original GFANC framework.
What carries the argument
The fully differentiable ANC pipeline that lets the Transformer generate entire control filters directly, trained unsupervised on accumulated error alone.
If this is right
- The control pipeline becomes simpler because decomposition and recombination steps are removed.
- Training requires no labeled data and uses only the error signal as objective.
- Global noise characteristics are captured through attention without hand-crafted sub-filter combinations.
- Performance gains appear on varied real-recorded noises in simulation.
Where Pith is reading between the lines
- The approach could support online adaptation in embedded devices where only error feedback is available.
- Similar end-to-end differentiable designs might apply to other adaptive filtering tasks that currently rely on decomposition.
- Real-time hardware implementation would need to confirm that the Transformer inference fits within latency budgets of current ANC systems.
Load-bearing premise
That the integrated differentiable system will produce effective filters when trained solely on the accumulated error signal without separate decomposition.
What would settle it
Numerical tests on the same real-recorded noises showing equal or worse noise reduction than the original GFANC method, or failure of the generated filters to reduce error in a physical ANC setup.
Figures


read the original abstract
To address the limitations of existing Generative Fixed-Filter Active Noise Control (GFANC) methods, which rely on filter decomposition and recombination and require supervised learning with labeled data, this paper proposes a Transformer-based End-to-End Control-Filter Generation (E2E-CFG) framework. Unlike previous approaches that predict combination weights of sub control filters, the proposed method directly generates control filters in an unsupervised manner by integrating the co-processor and real-time controller into a fully differentiable ANC system, where the accumulated error signal is used as the training objective. By abandoning the decomposition--reconstruction process, the proposed design simplifies the control pipeline and avoids error accumulation, while the Transformer architecture effectively captures global and dynamic noise characteristics through its attention mechanism. Numerical simulations on real-recorded noises demonstrate that the proposed method achieves improved noise reduction performance and adaptability to different types of noises compared with the original GFANC framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Transformer-based End-to-End Control-Filter Generation (E2E-CFG) framework for active noise control (ANC). Unlike prior Generative Fixed-Filter ANC (GFANC) methods that rely on supervised filter decomposition and recombination, E2E-CFG integrates the co-processor and real-time controller into a fully differentiable ANC system and trains the Transformer directly in an unsupervised manner using only the accumulated error signal as the objective. The approach claims to simplify the pipeline, avoid error accumulation from decomposition, capture global/dynamic noise features via attention, and achieve improved noise reduction and adaptability on real-recorded noises.
Significance. If the central claims hold, the work would offer a meaningful simplification of ANC control pipelines by removing the decomposition step and enabling unsupervised end-to-end training; the use of a fully differentiable system and Transformer attention for non-stationary noises could improve adaptability in practical settings. The absence of quantitative metrics in the abstract, however, leaves the magnitude of improvement and the robustness of the gradient flow unverified.
major comments (2)
- [Training objective and differentiability description (methods)] The central claim that unsupervised training on accumulated error alone suffices for effective filter generation rests on the assumption that gradients remain informative after back-propagation through the secondary-path convolution (and any primary-path model). No analysis of gradient magnitude, vanishing/exploding behavior, or stability under realistic acoustic-path transfer functions is provided; if the paths act as low-pass or attenuating filters, the claimed avoidance of decomposition error and improved adaptability would not necessarily follow.
- [Numerical simulations / results] The abstract asserts 'improved noise reduction performance and adaptability' relative to GFANC, yet supplies no quantitative metrics, error bars, statistical tests, or specific noise-type breakdowns. The results section must include explicit dB reductions, convergence curves, and cross-noise comparisons with the original GFANC baseline to substantiate the performance claim.
minor comments (2)
- [Methods] Notation for the accumulated error signal and the precise definition of the secondary-path convolution operator should be introduced with an equation early in the methods to avoid ambiguity when discussing differentiability.
- [Experimental setup] Dataset details (sampling rates, recording conditions, number of real-recorded noise types) are mentioned only generically; adding a table or explicit list would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Training objective and differentiability description (methods)] The central claim that unsupervised training on accumulated error alone suffices for effective filter generation rests on the assumption that gradients remain informative after back-propagation through the secondary-path convolution (and any primary-path model). No analysis of gradient magnitude, vanishing/exploding behavior, or stability under realistic acoustic-path transfer functions is provided; if the paths act as low-pass or attenuating filters, the claimed avoidance of decomposition error and improved adaptability would not necessarily follow.
Authors: We agree that providing an analysis of the gradient flow is valuable to support the claims regarding the differentiability and effectiveness of the unsupervised training. In the revised manuscript, we will include a new subsection in the Methods section dedicated to discussing the back-propagation through the secondary-path convolution. This will cover considerations of gradient magnitude, potential issues with vanishing or exploding gradients, and stability under the acoustic transfer functions employed in our simulations with real-recorded noises. Such analysis will strengthen the justification for the end-to-end approach and its advantages over decomposition-based methods. revision: yes
-
Referee: [Numerical simulations / results] The abstract asserts 'improved noise reduction performance and adaptability' relative to GFANC, yet supplies no quantitative metrics, error bars, statistical tests, or specific noise-type breakdowns. The results section must include explicit dB reductions, convergence curves, and cross-noise comparisons with the original GFANC baseline to substantiate the performance claim.
Authors: We acknowledge that the abstract and results section would benefit from more explicit quantitative evidence. We will revise the abstract to include specific performance metrics, such as the average noise reduction in dB for different noise types. Additionally, the results section will be expanded to include tables with dB reductions, standard deviations or error bars from repeated experiments, p-values from statistical tests comparing to GFANC, convergence plots over training epochs or time, and detailed cross-comparisons across various real-recorded noise types. These revisions will provide a clearer substantiation of the claimed improvements in noise reduction and adaptability. revision: yes
Circularity Check
No circularity: end-to-end differentiable training is independent of prior decomposition
full rationale
The paper's central derivation replaces GFANC's filter decomposition/recombination with direct Transformer generation inside a fully differentiable ANC loop whose loss is the accumulated error signal. No equation is shown to be equivalent to a fitted parameter or prior output by construction. The unsupervised objective and attention-based capture of noise dynamics are presented as new architectural choices, not renamings or self-referential fits. Performance claims rest on external numerical simulations against real-recorded noises, not on internal re-derivation of the same quantities used for training. No load-bearing self-citation or uniqueness theorem is invoked to force the result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The accumulated error signal serves as a sufficient unsupervised training objective for the end-to-end system.
- domain assumption Transformer attention mechanism effectively captures global and dynamic noise characteristics.
Reference graph
Works this paper leans on
-
[1]
J. C. Burgess. Active adaptive sound control in a duct: A computer simulation.The Journal of the Acoustical Society of America, 70(3):715–726, 1981
1981
-
[2]
P. A. Nelson and S. J. Elliott.Active Control of Sound. Academic Press, London, 1992
1992
-
[3]
Active control of sound transmission through a floor-level slit.The Journal of the Acoustical Society of America, 154(5):2746–2756, 2023
Ziyi Yang, Shuping Wang, Jiancheng Tao, and Xiaojun Qiu. Active control of sound transmission through a floor-level slit.The Journal of the Acoustical Society of America, 154(5):2746–2756, 2023
2023
-
[4]
Kuo and Dennis R
Sen M. Kuo and Dennis R. Morgan. Active noise control: A tutorial review.Proceedings of the IEEE, 87(6):943–973, 1999
1999
-
[5]
Mixed-gradients distributed filtered reference least mean square algorithm–a robust distributed multichannel active noise control algorithm
Junwei Ji, Dongyuan Shi, and Woon-Seng Gan. Mixed-gradients distributed filtered reference least mean square algorithm–a robust distributed multichannel active noise control algorithm. IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[6]
Yoshinobu Kajikawa, Woon-Seng Gan, and Sen M. Kuo. Recent advances on active noise control: Open issues and innovative applications.APSIPA Transactions on Signal and Information Processing, 1:e3, 2012
2012
-
[7]
Tianyou Li, Sipei Zhao, Li Rao, Haishan Zou, Kai Chen, Jing Lu, and Ian S Burnett. Experimental study of a distributed active noise control system with multi-device nodes based on augmented diffusion strategy.The Journal of the Acoustical Society of America, 156(5):3246– 3259, 2024
2024
-
[8]
Elliott.Signal Processing for Active Control
Stephen J. Elliott.Signal Processing for Active Control. Academic Press, London, 2001
2001
-
[9]
Computationally efficient fixed-filter ANC for speech based on long-term prediction for headphone applications
Yurii Iotov, Sidsel Marie Nørholm, Valiantsin Belyi, Mads Dyrholm, and Mads Græsbøll Christensen. Computationally efficient fixed-filter ANC for speech based on long-term prediction for headphone applications. InProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 906–910, 2022
2022
-
[10]
Non- stationary prediction for addressing the non-causality problem in fixed-filter ANC headphones for speech reduction
Yurii Iotov, Sidsel Marie Nørholm, Valiantsin Belyi, and Mads Græsbøll Christensen. Non- stationary prediction for addressing the non-causality problem in fixed-filter ANC headphones for speech reduction. InProc. European Signal Processing Conference (EUSIPCO), pages 1008– 1012, 2023
2023
-
[11]
Adaptive-gain algorithm on the fixed filters applied for active noise control headphone.Mechanical Systems and Signal Processing, 169:108641, 2022
Xiaoyi Shen, Dongyuan Shi, Woon-Seng Gan, and Santi Peksi. Adaptive-gain algorithm on the fixed filters applied for active noise control headphone.Mechanical Systems and Signal Processing, 169:108641, 2022
2022
-
[12]
Feedforward selective fixed-filter active noise control: Algorithm and implementation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:1479–1492, 2020
Dongyuan Shi, Woon-Seng Gan, Bhan Lam, and Shulin Wen. Feedforward selective fixed-filter active noise control: Algorithm and implementation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:1479–1492, 2020
2020
-
[13]
Selective fixed- filter active noise control based on convolutional neural network.Signal Processing, 190:108317, 2022
Dongyuan Shi, Bhan Lam, Kenneth Ooi, Xiaoyi Shen, and Woon-Seng Gan. Selective fixed- filter active noise control based on convolutional neural network.Signal Processing, 190:108317, 2022
2022
-
[14]
A hybrid SFANC-FxNLMS algorithm for active noise control based on deep learning.IEEE Signal Processing Letters, 29:1102–1106, 2022
Zhengding Luo, Dongyuan Shi, and Woon-Seng Gan. A hybrid SFANC-FxNLMS algorithm for active noise control based on deep learning.IEEE Signal Processing Letters, 29:1102–1106, 2022
2022
-
[15]
Zhengding Luo, Dongyuan Shi, Woon-Seng Gan, and Qirui Huang. Delayless generative fixed- filter active noise control based on deep learning and Bayesian filter.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:1048–1060, 2024
2024
-
[16]
GFANC-Kalman: Generative fixed-filter active noise control with CNN-Kalman filtering.IEEE Signal Processing Letters, 31:276–280, 2024
Zhengding Luo, Dongyuan Shi, Xiaoyi Shen, Junwei Ji, and Woon-Seng Gan. GFANC-Kalman: Generative fixed-filter active noise control with CNN-Kalman filtering.IEEE Signal Processing Letters, 31:276–280, 2024
2024
-
[17]
Unsupervised learning based end-to-end delayless generative fixed-filter active noise control
Zhengding Luo, Dongyuan Shi, Xiaoyi Shen, and Woon-Seng Gan. Unsupervised learning based end-to-end delayless generative fixed-filter active noise control. InProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1041–1045, 2024
2024
-
[18]
Deep ANC: A deep learning approach to active noise control
Hao Zhang and DeLiang Wang. Deep ANC: A deep learning approach to active noise control. Neural Networks, 141:1–10, 2021
2021
-
[19]
Low-latency active noise control using attentive recurrent network.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1114–1123, 2023
Hao Zhang, Ashutosh Pandey, and DeLiang Wang. Low-latency active noise control using attentive recurrent network.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1114–1123, 2023
2023
-
[20]
Wavenet-volterra neural network for active noise control: A fully causal approach
Lu Bai, Siyuan Lian, Mengtong Li, Yiming He, Li Rao, Xiaofeng Zeng, Ruquan Sun, Kai Chen, and Jing Lu. Wavenet-volterra neural network for active noise control: A fully causal approach. Mechanical Systems and Signal Processing, 224:111956, 2025
2025
-
[21]
Transferable selective virtual sensing active noise control technique based on metric learning
Boxiang Wang, Dongyuan Shi, Zhengding Luo, Xiaoyi Shen, Junwei Ji, and Woon-Seng Gan. Transferable selective virtual sensing active noise control technique based on metric learning. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[22]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[23]
Conformer: Convolution- augmented Transformer for Speech Recognition
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang. Conformer: Convolution- augmented Transformer for Speech Recognition. InProc. Interspeech, pages 5036–5040, 2020
2020
-
[24]
Attention is all you need in speech separation
Cem Subakan Subakan, Mirco Ravanelli, Samuele Cornell, Mirko Bronzi, and Jianyuan Zhong. Attention is all you need in speech separation. InProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 21–25, 2021
2021
-
[25]
Deep learning-based generative fixed-filter active noise control: Transferability and implementation.Mechanical Systems and Signal Processing, 238:113207, 2025
Zhengding Luo, Junwei Ji, Boxiang Wang, Dongyuan Shi, Haozhe Ma, and Woon-Seng Gan. Deep learning-based generative fixed-filter active noise control: Transferability and implementation.Mechanical Systems and Signal Processing, 238:113207, 2025
2025
-
[26]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.