Recognition: unknown
EnCoDe: Energy Estimation of Source Code At Design-Time
Pith reviewed 2026-05-09 18:54 UTC · model grok-4.3
The pith
Machine learning models predict energy consumption of individual code blocks from static features alone, without execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
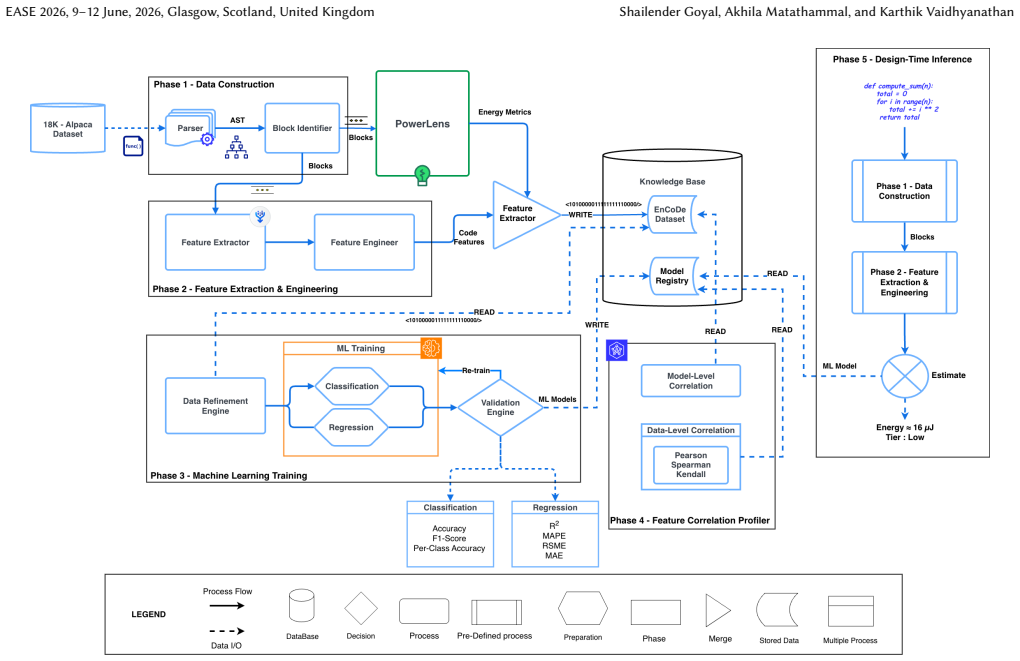
Using measurements from PowerLens on code blocks drawn from more than 18,000 Python programs, the authors establish that static code features exhibit both linear and non-linear relationships with energy consumption. Regressors trained on structural, complexity, density, and contextual characteristics achieve an R-squared value of 0.75 for block-level energy estimation, while classifiers reach 80.6 percent accuracy in detecting energy hotspots. The resulting models enable accurate, reproducible predictions at design time without requiring program execution.
What carries the argument
Machine learning regressors and classifiers trained on static structural, complexity, density, and contextual features of code blocks, using PowerLens sub-millisecond energy measurements as ground truth.
If this is right
- Developers can compare the energy efficiency of alternative constructs such as loops versus conditionals while writing code.
- High-energy code regions can be localized and refactored early, lowering overall software energy use without runtime tools.
- A fine-grained dataset of block-level energy data becomes available for further study of code-energy relationships.
- Design-time energy feedback supports lower operational costs and reduced environmental impact from software.
Where Pith is reading between the lines
- Embedding the models in integrated development environments could deliver real-time energy estimates as developers type.
- The approach might extend to other languages if similar static-feature relationships are measured and validated.
- Combining predictions with automated refactoring tools could generate energy-aware code suggestions during development.
- Collecting larger or more diverse datasets could test whether additional contextual features improve prediction stability.
Load-bearing premise
The linear and non-linear relationships between static code features and energy consumption found in the studied Python blocks will hold for new, unseen code.
What would settle it
Testing the trained models on code blocks from a fresh set of Python programs and obtaining R-squared values below 0.5 or hotspot classification accuracy below 70 percent against new PowerLens measurements.
Figures





read the original abstract
Energy efficiency has emerged as a vital attribute of software quality, with significant implications for both environmental sustainability and operational costs. However, existing profiling tools operate only at runtime and coarse granularity, typically capturing energy at the process or method level. Such tools fail to expose how small code blocks, such as functions, loops, and conditionals, contribute to energy consumption, preventing developers from reasoning about and comparing the energy efficiency of programming constructs during design-time. To address this gap, we propose EnCoDe, a methodology for fine-grained, design-time energy estimation, with the following key contributions: (1) PowerLens, a novel measurement methodology that achieves reliable sub-millisecond energy readings for small code blocks; (2) Extensive empirical study on code blocks extracted from over 18,000 Python programs, uncovering linear and non-linear relationships between energy consumption and static code features such as structural, complexity, density, and contextual characteristics, resulting in a first-of-its-kind fine-grained dataset; and (3) Predictive modeling, in which machine learning models are trained on these features to accurately estimate and classify block-level energy consumption at design-time. Our results demonstrate stable, reproducible block-level estimations, with regressors achieving R^2 = 0.75 and classifiers achieving 80.6% accuracy in identifying energy hotspots, enabling developers to localize and address inefficient code regions early in the development process without execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EnCoDe, a design-time methodology for estimating energy consumption of fine-grained source code blocks (e.g., loops, conditionals). It contributes (1) PowerLens, a measurement approach claimed to deliver reliable sub-millisecond energy readings; (2) an empirical study extracting blocks from >18,000 Python programs to identify linear and non-linear relationships with static features (structural, complexity, density, contextual); and (3) ML regressors and classifiers trained on these features, reporting R²=0.75 for energy estimation and 80.6% accuracy for hotspot classification, enabling early localization of inefficient code without execution.
Significance. If the measurement methodology is independently validated and the models are shown to generalize, the work would enable practical design-time energy reasoning at block granularity, a notable gap relative to existing runtime profilers. The scale of the empirical dataset and the reported performance metrics, if robust, would provide a reusable resource for sustainable software engineering and could influence early-stage optimization practices.
major comments (3)
- [PowerLens methodology] PowerLens methodology (contribution 1): The claim of 'reliable sub-millisecond energy readings' for blocks <1 ms is presented without any independent validation against a reference instrument, quantification of systematic bias, timing jitter, or hardware-specific artifacts. Since these readings constitute the ground-truth labels for the entire dataset and subsequent ML training, the absence of such validation directly undermines the soundness of the reported R² and accuracy figures.
- [Predictive modeling] Predictive modeling (contribution 3): The regressors are reported to achieve R²=0.75 and classifiers 80.6% accuracy, yet no information is given on train/test splits, cross-validation procedure, error bars, or explicit controls for overfitting. Without these details the performance numbers cannot be assessed for robustness or generalization to unseen code.
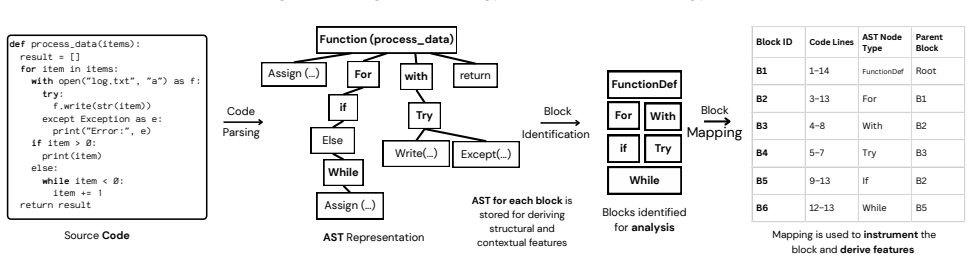
- [Empirical study] Empirical study (contribution 2): The study extracts blocks from 18,000 programs and identifies feature-energy relationships, but provides no description of block extraction criteria, feature selection process, or statistical tests confirming the significance of the linear/non-linear relationships. This leaves the feature set used for ML training without a clear, reproducible foundation.
minor comments (1)
- [Abstract] The abstract states 'stable, reproducible block-level estimations' but the manuscript does not indicate whether code, seeds, or the full dataset are made available to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of methodological rigor that we address point by point below. We have revised the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: [PowerLens methodology] PowerLens methodology (contribution 1): The claim of 'reliable sub-millisecond energy readings' for blocks <1 ms is presented without any independent validation against a reference instrument, quantification of systematic bias, timing jitter, or hardware-specific artifacts. Since these readings constitute the ground-truth labels for the entire dataset and subsequent ML training, the absence of such validation directly undermines the soundness of the reported R² and accuracy figures.
Authors: We agree that independent validation of PowerLens is necessary to substantiate the reliability claims. The revised manuscript includes a new subsection on PowerLens validation that reports direct comparisons against a calibrated reference power analyzer. This covers systematic bias quantification, timing jitter measurements across repeated runs, and artifact analysis on hardware-specific workloads. These additions provide the required evidence supporting the sub-millisecond ground-truth labels used for the dataset and ML models. revision: yes
-
Referee: [Predictive modeling] Predictive modeling (contribution 3): The regressors are reported to achieve R²=0.75 and classifiers 80.6% accuracy, yet no information is given on train/test splits, cross-validation procedure, error bars, or explicit controls for overfitting. Without these details the performance numbers cannot be assessed for robustness or generalization to unseen code.
Authors: We acknowledge that the original description of the modeling pipeline lacked sufficient experimental detail. The revised version adds an explicit experimental setup subsection describing the stratified 80/20 train/test split, 5-fold cross-validation with shuffling, L2 regularization and early stopping as overfitting controls, and performance reported as mean ± standard deviation across folds. These changes enable proper evaluation of robustness and generalization. revision: yes
-
Referee: [Empirical study] Empirical study (contribution 2): The study extracts blocks from 18,000 programs and identifies feature-energy relationships, but provides no description of block extraction criteria, feature selection process, or statistical tests confirming the significance of the linear/non-linear relationships. This leaves the feature set used for ML training without a clear, reproducible foundation.
Authors: We recognize the importance of full reproducibility for the empirical study. The revised manuscript expands the methodology to detail the AST-based block extraction criteria (including rules for loops, conditionals, and functions), the initial feature set of 52 static metrics, the selection process using correlation filtering and recursive feature elimination, and statistical validation via Pearson coefficients for linear relationships and distance correlation with permutation tests for non-linear ones, including p-values. This establishes a clear foundation for the feature set and dataset. revision: yes
Circularity Check
No circularity: empirical measurement-to-ML pipeline is self-contained
full rationale
The paper's core chain consists of (1) PowerLens sub-millisecond measurements on extracted blocks from 18k+ Python programs to produce labeled data, (2) extraction of static code features (structural, complexity, etc.), (3) empirical observation of linear/non-linear relationships, and (4) training of regressors/classifiers whose reported R^2 = 0.75 and 80.6% accuracy are standard held-out evaluation metrics on that dataset. No equations reduce any prediction to a fitted parameter by construction, no self-citations or uniqueness theorems are invoked as load-bearing premises, and no ansatz or renaming of known results is smuggled in. The derivation is therefore an ordinary empirical ML pipeline whose outputs are not tautological with its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static code features (structural, complexity, density, contextual) capture sufficient information to predict energy consumption of small blocks
invented entities (1)
-
PowerLens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho, Ravi Sethi, and Jeffrey D
Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman. 1986. Compilers: Principles, Techniques, and Tools. InAddison-Wesley series in computer science / World student series edition. https://api.semanticscholar.org/CorpusID:278028060
1986
-
[2]
T., Devanbu, P., and Sutton, C
Miltiadis Allamanis, Earl T. Barr, Premkumar Devanbu, and Charles Sutton. 2018. A Survey of Machine Learning for Big Code and Naturalness.ACM Comput. Surv. 51, 4, Article 81 (July 2018), 37 pages. doi:10.1145/3212695
-
[3]
Eman Abdullah AlOmar, Salma Abdullah AlOmar, and Mohamed Wiem Mkaouer
-
[4]
On the Use of Static Analysis to Engage Students with Software Quality Improvement: An Experience with PMD. In2023 IEEE/ACM 45th International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET). IEEE/ACM, 179–191. doi:10.1109/ICSE-SEET58685.2023.00023
-
[5]
Hamza Mustafa Alvi, Hammad Majeed, Hasan Mujtaba, and Mirza Omer Beg
-
[6]
MLEE: Method Level Energy Estimation — A machine learning approach. Sustainable Computing: Informatics and Systems32 (2021), 100594. doi:10.1016/j. suscom.2021.100594
work page doi:10.1016/j 2021
-
[7]
Lotfi Belkhir and Ahmed Elmeligi. 2018. Assessing ICT global emissions footprint: Trends to 2040 & recommendations.Journal of Cleaner Production177 (2018), 448–463. doi:10.1016/j.jclepro.2017.12.239
- [8]
-
[9]
Warrens, and Giuseppe Jurman
Davide Chicco, Matthijs J. Warrens, and Giuseppe Jurman. 2021. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation.PeerJ Computer Science7 (2021). https://api.semanticscholar.org/CorpusID:236196832
2021
- [10]
-
[11]
Roberto Di Cosmo. 2018. Software Heritage: Why and How We Collect, Preserve and Share All the Software Source Code. In2018 IEEE/ACM 40th International Conference on Software Engineering: Software Engineering in Society (ICSE-SEIS). 2–2
2018
-
[12]
Choice modelling in the age of machine learning - Discussion paper , volume =
Charlotte Freitag, Mike Berners-Lee, Kelly Widdicks, Bran Knowles, Gordon S. Blair, and Adrian Friday. 2021. The real climate and transformative impact of ICT: A critique of estimates, trends, and regulations.Patterns2, 9 (2021), 100340. doi:10.1016/j.patter.2021.100340
-
[13]
Marcus Hähnel, Björn Döbel, Marcus Völp, and Hermann Härtig. 2012. Measuring energy consumption for short code paths using RAPL.SIGMETRICS Perform. Eval. Rev.40, 3 (Jan. 2012), 13–17. doi:10.1145/2425248.2425252
-
[14]
Halstead
Maurice H. Halstead. 1977.Elements of Software Science (Operating and program- ming systems series). Elsevier Science Inc., USA
1977
-
[15]
Abram Hindle. 2015. Green mining: a methodology of relating software change and configuration to power consumption.Empirical Softw. Engg.20, 2 (April 2015), 374–409. doi:10.1007/s10664-013-9276-6
- [16]
-
[17]
K. N. Khan, M. Hirki, T. Niemi, J. K. Nurminen, and Z. Ou. 2018. RAPL in Action: Experiences in Using RAPL for Power Measurements.ACM Transactions on Modeling and Performance Evaluation of Computing Systems3, 2 (2018), 1–26. doi:10.1145/3177754
-
[18]
Ghani, and Khaironi Yatim Sharif
Ching Kin Keong, Koh Tieng Wei, Abdul Azim Abd. Ghani, and Khaironi Yatim Sharif. 2015. Toward using software metrics as indicator to measure power consumption of mobile application: A case study. In2015 9th Malaysian Software Engineering Conference (MySEC). 172–177. doi:10.1109/MySEC.2015.7475216
-
[19]
Sung Une Lee, Niroshinie Fernando, Kevin Lee, and Jean-Guy Schneider. 2024. A survey of energy concerns for software engineering.Journal of Systems and Software210 (2024), 111944. doi:10.1016/j.jss.2023.111944
- [20]
-
[21]
T.J. McCabe. 1976. A Complexity Measure.IEEE Transactions on Software Engi- neeringSE-2, 4 (1976), 308–320. doi:10.1109/TSE.1976.233837
-
[22]
Nikolopoulos, and Bronis R
Lev Mukhanov, Dimitrios S. Nikolopoulos, and Bronis R. De Supinski. 2015. ALEA: Fine-Grain Energy Profiling with Basic Block Sampling. In2015 International Conference on Parallel Architecture and Compilation (PACT). 87–98. doi:10.1109/ PACT.2015.16
2015
-
[23]
Hira Noman, Naeem Ahmed Mahoto, Sania Bhatti, Hamad Ali Abosaq, Mana Saleh Al Reshan, and Asadullah Shaikh. 2022. An Exploratory Study of Software Sustainability at Early Stages of Software Development.Sustainability 14, 14 (2022). doi:10.3390/su14148596
-
[24]
Candy Pang, Abram Hindle, Bram Adams, and Ahmed E. Hassan. 2016. What Do Programmers Know about Software Energy Consumption?IEEE Software33, 3 (2016), 83–89. doi:10.1109/MS.2015.83
-
[25]
Karl Pearson. 1896. Mathematical Contributions to the Theory of Evolution. III. Regression, Heredity, and Panmixia.Philosophical Transactions of the Royal Society of London Series A187 (Jan. 1896), 253–318. doi:10.1098/rsta.1896.0007
-
[26]
Gustavo Pinto and Fernando Castor. 2017. Energy efficiency: A new concern for application software developers.Commun. ACM60 (11 2017), 68–75. doi:10. 1145/3154384
2017
-
[27]
Saurabhsingh Rajput, Alexander Brandt, Vadim Elisseev, and Tushar Sharma
-
[28]
arXiv:2601.13345 [cs.SE] https://arxiv.org/abs/2601.13345
FlipFlop: A Static Analysis-based Energy Optimization Framework for GPU Kernels. arXiv:2601.13345 [cs.SE] https://arxiv.org/abs/2601.13345
-
[29]
Saurabhsingh Rajput, Tim Widmayer, Ziyuan Shang, Maria Kechagia, Federica Sarro, and Tushar Sharma. 2024. Enhancing Energy-Awareness in Deep Learning through Fine-Grained Energy Measurement.ACM Trans. Softw. Eng. Methodol. 33, 8, Article 211 (Dec. 2024), 34 pages. doi:10.1145/3680470
-
[30]
Pooja Rani, Jonas Zellweger, Veronika Kousadianos, Luis Cruz, Timo Kehrer, and Alberto Bacchelli. 2024. Energy Patterns for Web: An Exploratory Study. InProceedings of the 46th International Conference on Software Engineering: Soft- ware Engineering in Society(Lisbon, Portugal)(ICSE-SEIS’24). Association for Computing Machinery, New York, NY, USA, 12–22. ...
-
[31]
Motaharul Islam
Nurzihan Fatema Reya, Abtahi Ahmed, Tashfia Rifa Zaman, and Md. Motaharul Islam. 2023. GreenPy: Evaluating Application-Level Energy Efficiency in Python for Green Computing.Annals of Emerging Technologies in Computing(2023). https://api.semanticscholar.org/CorpusID:259509821
2023
-
[32]
Ferreira, and Alexandra Mendes
Ana Ribeiro, João F. Ferreira, and Alexandra Mendes. 2021. EcoAndroid: An Android Studio Plugin for Developing Energy-Efficient Java Mobile Applications. In2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS). 62–69. doi:10.1109/QRS54544.2021.00017
- [33]
-
[34]
Marina Sokolova and Guy Lapalme. 2009. A systematic analysis of performance measures for classification tasks.Information Processing & Management45, 4 (2009), 427–437. doi:10.1016/j.ipm.2009.03.002
-
[35]
Spearman
C. Spearman. 1904. The Proof and Measurement of Association Between Two Things.American Journal of Psychology15 (1904), 88–103
1904
-
[36]
Weisong Sun, Chunrong Fang, Yun Miao, Yudu You, Mengzhe Yuan, Yuchen Chen, Quanjun Zhang, An Guo, Xiang Chen, Yang Liu, and Zhenyu Chen. 2023. Abstract Syntax Tree for Programming Language Understanding and Representation: How Far Are We? arXiv:2312.00413 [cs.SE] https://arxiv.org/abs/2312.00413
-
[37]
John W. Tukey. 1977.Exploratory data analysis. Addison-Wesley Pub. Co., Reading, Mass
1977
-
[38]
Roberto Verdecchia, Luis Cruz, June Sallou, Michelle Lin, James Wickenden, and Estelle Hotellier. 2022. Data-Centric Green AI An Exploratory Empirical Study. In2022 International Conference on ICT for Sustainability (ICT4S). IEEE, 35–45. doi:10.1109/ict4s55073.2022.00015
-
[39]
Fadi Wedyan, Rachael Morrison, and Osama Sam Abuomar. 2023. Integration and Unit Testing of Software Energy Consumption. In2023 Tenth International Conference on Software Defined Systems (SDS). 60–64. doi:10.1109/SDS59856.2023. 10329262
-
[40]
N. Wirth. 1995. A plea for lean software.Computer28, 2 (1995), 64–68. doi:10. 1109/2.348001
1995
-
[41]
Ohlsson, Bjrn Regnell, and An- ders Wessln
Claes Wohlin, Per Runeson, Martin Hst, Magnus C. Ohlsson, Bjrn Regnell, and An- ders Wessln. 2012.Experimentation in Software Engineering. Springer Publishing Company, Incorporated
2012
-
[42]
Włodzimierz Wysocki, Ireneusz Miciuła, and Przemysław Plecka. 2025. Methods of Improving Software Energy Efficiency: A Systematic Literature Review and the Current State of Applied Methods in Practice.Electronics14, 7 (2025). doi:10. 3390/electronics14071331
2025
-
[43]
Thomas Zaragoza, Adel Noureddine, and Ernesto Exposito. 2025. A systematic mapping study on software-based feedback for energy consumption.Renewable and Sustainable Energy Reviews222 (2025), 115889. doi:10.1016/j.rser.2025.115889
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.