Recognition: unknown
Sim-FA: A GPGPU Simulator Framework for Fine-Grained FlashAttention Pipeline Analysis
Pith reviewed 2026-05-09 18:40 UTC · model grok-4.3
The pith
A cycle-accurate simulator for FlashAttention-3 kernels reaches 5.7 percent average error by modeling new GPU features and explaining analytical model failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By instrumenting FlashAttention-3 kernels and routing the resulting traces through a cycle-accurate simulator that includes the Tensor Memory Accelerator and warp specialization, the framework produces performance predictions whose mean absolute percentage error is 5.7 percent and maximum absolute percentage error is 12.7 percent against H800 measurements. The same pipeline yields a theoretical analysis showing that existing analytical models underestimate DRAM traffic because they omit the specific producer-consumer and matrix-activation overlaps that occur in the FlashAttention-3 schedule.
What carries the argument
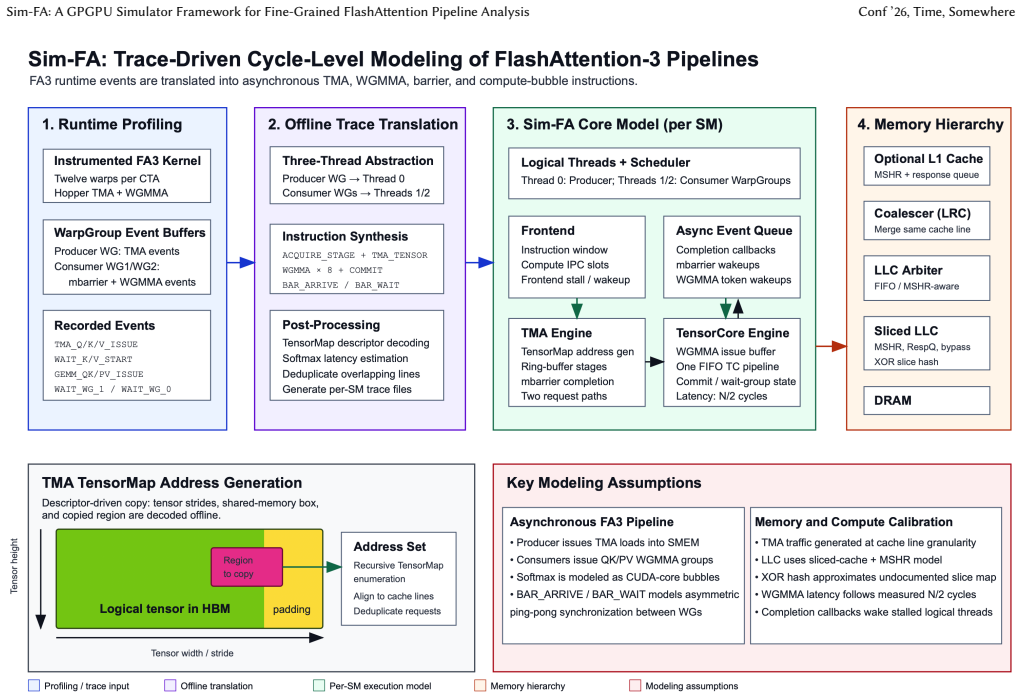
The end-to-end simulation pipeline that starts with FlashAttention-3 kernel instrumentation and ends in cycle-accurate execution, thereby capturing warp-level temporal overlap and TMA-driven memory movement.
If this is right
- Designers can test FlashAttention-3 variants and new attention schedules in simulation before silicon is available.
- The theoretical analysis supplies concrete adjustments that any analytical model must incorporate to avoid traffic underestimation.
- Architecture studies of LLM inference can now include fine-grained producer-consumer and matrix-activation pipelining without relying solely on hardware measurements.
- Future GPU feature additions can be evaluated by extending the same instrumentation-to-simulation path.
Where Pith is reading between the lines
- The same instrumentation technique could be applied to other attention or linear-algebra kernels that use warp specialization.
- Hybrid analytical-simulator flows might reduce the need for full cycle-accurate runs while still correcting the traffic misestimates identified here.
- Accurate early simulation of these pipelines could shorten the iteration loop for custom AI accelerator designs.
Load-bearing premise
The cycle-accurate simulator and kernel instrumentation faithfully reproduce the timing and behavior of new NVIDIA GPU features such as the Tensor Memory Accelerator and warp specialization.
What would settle it
Measure the actual cycle counts or DRAM traffic of the same FlashAttention-3 kernel on an H800 GPU and compare them directly to the simulator outputs; sustained errors above 12.7 percent would falsify the reported accuracy.
Figures






read the original abstract
To efficiently support Large Language Models (LLMs), modern GPGPU architectures have introduced new features and programming paradigms, such as warp specialization. These features enable temporal overlap between the producer and consumer, as well as between matrix multiplication and activation function operations, substantially improving performance. To conduct effective AI infrastructure and computer architecture research, cycle-accurate simulators that support these new features, together with analytical models that faithfully capture workload characteristics, are essential. However, existing academic tools provide limited support for these emerging requirements. Existing cycle-accurate simulators do not incorporate new NVIDIA GPU features, such as the Tensor Memory Accelerator (TMA), in a timely manner. Moreover, existing analytical models can misestimate DRAM traffic under certain configurations. In this paper, we build a simulation pipeline from FlashAttention-3 kernel instrumentation to cycle-accurate simulation. The simulator achieves a mean absolute percentage error (MAPE) of 5.7\% and a maximum absolute percentage error of 12.7\% against H800. We also provide a theoretical analysis of FlashAttention-3 and explain why existing analytical models can produce inaccurate traffic estimates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sim-FA, a simulation pipeline that instruments FlashAttention-3 kernels on modern GPGPUs and feeds the extracted traces into a cycle-accurate simulator to analyze fine-grained pipeline behavior, including support for new NVIDIA features such as the Tensor Memory Accelerator (TMA) and warp specialization. It reports validation results against an H800 GPU showing a mean absolute percentage error (MAPE) of 5.7% and a maximum absolute percentage error of 12.7%, and provides a theoretical analysis of FlashAttention-3 that identifies why prior analytical models can underestimate or misestimate DRAM traffic under certain configurations.
Significance. If the reported validation holds, the work would be significant for computer-architecture research on LLM accelerators because it supplies a missing tool for modeling temporal overlap between producer/consumer warps and matrix-multiplication/activation pipelines. The hardware-validation effort and the independent theoretical traffic analysis are clear strengths; the former demonstrates empirical grounding while the latter offers a parameter-free explanation for model inaccuracies that existing simulators and analytical tools do not address.
major comments (1)
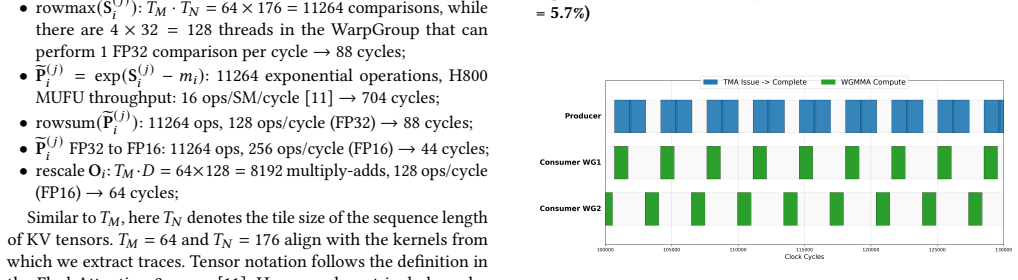
- [§4] §4 (Validation experiments): The central claim that the simulator reproduces H800 execution with 5.7% MAPE and 12.7% max APE is load-bearing, yet the manuscript provides insufficient detail on how kernel instrumentation captures and how the cycle-accurate model implements the timing, issue rates, and scheduling of TMA asynchronous tensor copies and warp-specialized producer-consumer overlap. Without an explicit error breakdown or latency tables for these features, it is impossible to determine whether the reported error reflects faithful modeling or unstated approximations.
minor comments (2)
- [Abstract] Abstract: the phrase 'existing cycle-accurate simulators do not incorporate new NVIDIA GPU features' would be strengthened by naming the specific prior tools (e.g., GPGPU-Sim, Accel-Sim) and the exact version cutoff.
- [Theoretical analysis] Theoretical-analysis section: a small table comparing the analytical traffic estimate versus measured traffic for the configurations where existing models diverge would make the explanation more concrete and falsifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our validation experiments. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [§4] §4 (Validation experiments): The central claim that the simulator reproduces H800 execution with 5.7% MAPE and 12.7% max APE is load-bearing, yet the manuscript provides insufficient detail on how kernel instrumentation captures and how the cycle-accurate model implements the timing, issue rates, and scheduling of TMA asynchronous tensor copies and warp-specialized producer-consumer overlap. Without an explicit error breakdown or latency tables for these features, it is impossible to determine whether the reported error reflects faithful modeling or unstated approximations.
Authors: We agree that the current presentation of §4 would benefit from greater detail on these aspects to allow readers to fully assess the modeling fidelity. In the revised manuscript we will expand the instrumentation description to specify exactly how traces are extracted from the instrumented FlashAttention-3 kernels (including TMA launch and completion events) and how the cycle-accurate simulator models TMA asynchronous copy timing, issue rates, and the warp-specialized producer-consumer scheduling policy. We will also add an error breakdown table by pipeline stage (GEMM, activation, TMA, etc.) together with latency tables for the key TMA and overlap mechanisms. These additions will make explicit that the reported 5.7 % MAPE is obtained from faithful modeling rather than hidden approximations. revision: yes
Circularity Check
No circularity: simulator built and validated against external hardware measurements
full rationale
The paper's core contribution is the construction of an instrumentation-to-simulation pipeline for FlashAttention-3 on modern NVIDIA GPUs, followed by direct empirical validation against H800 execution traces (MAPE 5.7%, max 12.7%). This is an engineering measurement exercise, not a closed mathematical derivation. The separate theoretical traffic analysis identifies discrepancies in prior analytical models without relying on self-fitted parameters or self-citations as load-bearing premises. No equations, predictions, or uniqueness claims reduce by construction to the paper's own inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abhimanyu Bambhaniya, Ritik Raj, Geonhwa Jeong, Souvik Kundu, Sudarshan Srinivasan, Suvinay Subramanian, Midhilesh Elavazhagan, Madhu Kumar, and Tushar Krishna. 2025. Demystifying AI Platform Design for Distributed Inference of Next-Generation LLM models. arXiv:2406.01698 [cs.AR] https://arxiv.org/abs/ 2406.01698
-
[2]
Michael Bauer, Henry Cook, and Brucek Khailany. 2011. CudaDMA: Optimizing GPU memory bandwidth via warp specialization. InSC ’11: Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis. 1–11. doi:10.1145/2063384.2063400
- [3]
-
[4]
Sheng-Chun Kao, Suvinay Subramanian, Gaurav Agrawal, Amir Yazdanbakhsh, and Tushar Krishna. 2023. FLAT: An Optimized Dataflow for Mitigating At- tention Bottlenecks. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada)(ASPLOS 2023). Association for ...
-
[5]
Mahmoud Khairy, Zhesheng Shen, Tor M Aamodt, and Timothy G Rogers. 2020. Accel-Sim: An extensible simulation framework for validated GPU modeling. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 473–486
2020
-
[6]
Chengtao Lai, Zhongchun Zhou, Akash Poptani, and Wei Zhang. 2024. LCM: LLM-focused Hybrid SPM-cache Architecture with Cache Management for Multi- Core AI Accelerators. InProceedings of the 38th ACM International Conference on Supercomputing(Kyoto, Japan)(ICS ’24). Association for Computing Machinery, New York, NY, USA, 62–73. doi:10.1145/3650200.3656592
-
[7]
Seonho Lee, Amar Phanishayee, and Divya Mahajan. 2025. Forecasting GPU Performance for Deep Learning Training and Inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1(Rotterdam, Netherlands)(ASPLOS ’25). Association for Computing Machinery, New York, NY, USA, 4...
-
[8]
Nisa Bostancı, Ataberk Olgun, A
Haocong Luo, Yahya Can Tuğrul, F. Nisa Bostancı, Ataberk Olgun, A. Giray Yağlıkçı, and Onur Mutlu. 2023. Ramulator 2.0: A Modern, Modular, and Extensi- ble DRAM Simulator. arXiv:2308.11030 [cs.AR] https://arxiv.org/abs/2308.11030 Sim-FA: A GPGPU Simulator Framework for Fine-Grained FlashAttention Pipeline Analysis Conf ’26, Time, Somewhere
- [9]
-
[10]
Minkin, Alan Kaatz, Olivier Giroux, Jack Choquette, Shirish Gadre, Manan Patel, John Tran, Ronny Krashinsky, and Jeff Schottmiller
Alexander L. Minkin, Alan Kaatz, Olivier Giroux, Jack Choquette, Shirish Gadre, Manan Patel, John Tran, Ronny Krashinsky, and Jeff Schottmiller. 2023. Method and Apparatus for Efficient Access to Multidimensional Data Structures and/or Other Large Data Blocks. https://patents.google.com/patent/US20230289292A1/ en US Patent Application US20230289292A1, ass...
2023
- [11]
-
[12]
Yifan Sun, Trinayan Baruah, Saiful A. Mojumder, Shi Dong, Xiang Gong, Shane Treadway, Yuhui Bao, Spencer Hance, Carter McCardwell, Vincent Zhao, Harrison Barclay, Amir Kavyan Ziabari, Zhongliang Chen, Rafael Ubal, José L. Abellán, John Kim, Ajay Joshi, and David Kaeli. 2019. MGPUSim: Enabling Multi-GPU Performance Modeling and Optimization. InProceedings ...
-
[13]
Zhihang Yuan, Yuzhang Shang, Yang Zhou, Zhen Dong, Zhe Zhou, Chenhao Xue, Bingzhe Wu, Zhikai Li, Qingyi Gu, Yong Jae Lee, Yan Yan, Beidi Chen, Guangyu Sun, and Kurt Keutzer. 2024. LLM Inference Unveiled: Survey and Roofline Model Insights. arXiv:2402.16363 [cs.CL] https://arxiv.org/abs/2402.16363
- [14]
-
[15]
Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Huazuo Gao, Jiashi Li, Liyue Zhang, Panpan Huang, Shangyan Zhou, Shirong Ma, Wenfeng Liang, Ying He, Yuqing Wang, Yuxuan Liu, and Y.X. Wei. 2025. Insights into DeepSeek- V3: Scaling Challenges and Reflections on Hardware for AI Architectures. In Proceedings of the 52nd Annual International Symposium on ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.