Recognition: unknown
When More Reformulations Hurt: Avoiding Drift using Ranker Feedback
Pith reviewed 2026-05-09 18:37 UTC · model grok-4.3
The pith
ReformIR uses a lightweight surrogate and selective teacher reranker feedback to prioritize reformulations and documents, preventing drift even as their number increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReformIR treats query reformulations as first-class features and performs online relevance estimation using a strong reranker as a teacher. Given multiple reformulated queries, it constructs a large candidate pool and learns a lightweight surrogate model that estimates document utility from reformulation-specific retrieval signals. Under a fixed reranking budget, the surrogate adaptively prioritizes both reformulations and documents by selectively querying the teacher reranker anchored to the original query. This increases recall while actively suppressing drift through online feature selection over reformulations. Experiments on MSMARCO passage corpora and TREC Deep Learning benchmarks (DL
What carries the argument
ReformIR, the budget-aware framework that learns a lightweight surrogate from reformulation-specific retrieval signals to guide selective queries to a teacher reranker anchored to the original query.
If this is right
- Recall rises with additional reformulations while quality remains stable instead of degrading.
- The same reranking budget yields higher effectiveness than exhaustive or naive merging approaches.
- Large language model capacity is better allocated to reformulation generation with feedback than to exhaustive reranking.
- Retrieval pipelines should treat reformulation selection as an online optimization problem rather than a post-generation merge.
Where Pith is reading between the lines
- Drift is shown to be a downstream selection issue rather than an inherent limit of reformulation generation.
- The surrogate-plus-teacher pattern could transfer to conversational or multi-turn retrieval where context drift is a similar concern.
- If the surrogate approximates the teacher well, systems might safely reduce how often the full reranker is invoked.
Load-bearing premise
A lightweight surrogate model can reliably estimate document utility from reformulation-specific retrieval signals and selective querying of the teacher reranker will not miss critical relevant documents under the budget constraint.
What would settle it
On the TREC DL19-DL22 benchmarks, compare ReformIR against baselines using 15 or more reformulations; if ReformIR's effectiveness scores fall to or below the baselines that suffer drift, the central claim is falsified.
Figures
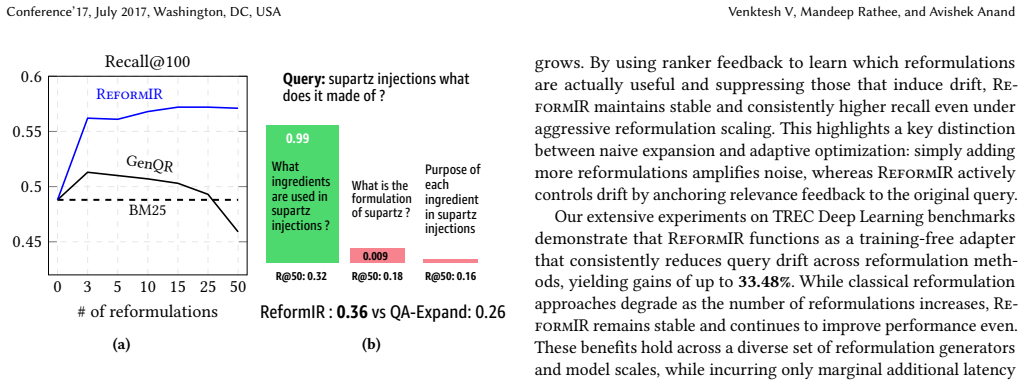



read the original abstract
Modern retrieval pipelines increasingly rely on query reformulation and neural reranking to improve effectiveness, but this comes at a significant computational cost and introduces a fundamental tradeoff between recall and query drift. Generating many reformulated queries can substantially increase recall, yet naively merging or exhaustively reranking their results is prohibitively expensive. In this work, we argue that the core challenge is not reformulation generation itself, but the adaptive selection of reformulations and their retrieved documents under a strict inference budget. We propose ReformIR, a budget-aware retrieval framework that treats query reformulations as first-class features and performs online relevance estimation using a strong reranker as a teacher. Given multiple reformulated queries, ReformIR constructs a large candidate pool and learns a lightweight surrogate model that estimates document utility from reformulation-specific retrieval signals. Under a fixed reranking budget, the surrogate adaptively prioritizes both reformulations and documents, selectively querying a teacher reranker anchored to the original query. This process increases recall while actively suppressing drift through online feature selection over reformulations. We conduct extensive experiments on the MSMARCO passage corpora and TREC Deep Learning benchmarks (DL19-DL22). Our results show that ReformIR consistently outperforms existing reformulation strategies, particularly as the number of reformulations increases, where prior methods suffer from severe quality degradation due to drift. Our findings also suggest a shift in retrieval system design, rather than using large language models as rerankers, their capacity is more effectively leveraged in the reformulation stage with feedback-driven optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReformIR, a budget-aware retrieval framework that treats query reformulations as first-class features and employs a lightweight surrogate model to estimate document utility from reformulation-specific retrieval signals. Under a fixed reranking budget, it selectively queries a teacher reranker (anchored to the original query) to increase recall while suppressing drift via online feature selection over reformulations. Experiments on MSMARCO passage corpora and TREC Deep Learning benchmarks (DL19-DL22) claim consistent outperformance over existing reformulation strategies, especially as the number of reformulations grows and prior methods degrade due to drift. The work suggests shifting LLM usage toward reformulation with feedback-driven optimization rather than reranking.
Significance. If the central claims hold, the paper addresses a practical tradeoff in modern retrieval pipelines between recall gains from multiple reformulations and the risks of query drift and computational cost. It offers a concrete mechanism for adaptive selection under budget constraints and provides evidence on public benchmarks that could inform system design. The approach credits the use of a strong teacher reranker for supervision while keeping inference lightweight, and the emphasis on online relevance estimation is a positive step toward falsifiable, budget-aware methods.
major comments (2)
- [Abstract / Experimental evaluation] Abstract and experimental evaluation: the headline claim that ReformIR 'consistently outperforms existing reformulation strategies, particularly as the number of reformulations increases' rests on high-level assertions without reported details on experimental controls, statistical significance testing, exact baseline implementations, or the quantitative definition and measurement of drift. These omissions are load-bearing because the central result is an empirical comparison whose validity cannot be assessed from the provided information.
- [Method] Method description (surrogate model): the framework's ability to preserve recall while suppressing drift depends on the lightweight surrogate producing accurate enough utility estimates from reformulation-specific signals (e.g., retrieval scores and similarity features) to decide which documents merit teacher reranker queries. No quantitative evidence is supplied on surrogate-teacher correlation, on how many reranker calls are consumed by surrogate training itself, or on recall@K behavior as the candidate pool scales with reformulation count. This directly affects whether the selective querying mechanism works as claimed.
minor comments (2)
- [Method] The abstract states that the surrogate 'learns' online but does not clarify whether the surrogate is updated per query or across queries, or what loss is used; this notation and training detail should be made explicit for reproducibility.
- [Introduction / Related Work] The suggestion to 'shift in retrieval system design' toward LLMs for reformulation rather than reranking is interesting but would benefit from a short discussion of related work on LLM-based query expansion to situate the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional details are required to fully substantiate the central empirical claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Experimental evaluation] Abstract and experimental evaluation: the headline claim that ReformIR 'consistently outperforms existing reformulation strategies, particularly as the number of reformulations increases' rests on high-level assertions without reported details on experimental controls, statistical significance testing, exact baseline implementations, or the quantitative definition and measurement of drift. These omissions are load-bearing because the central result is an empirical comparison whose validity cannot be assessed from the provided information.
Authors: We acknowledge the need for greater transparency. The revised manuscript will expand the experimental section with: exact baseline re-implementations (including hyperparameter settings and code pointers), statistical significance via paired t-tests over five runs with p-values, and fixed controls (seeds, hardware, evaluation protocol). Drift will be formally defined as the relative drop in nDCG@10 on the original query's judged documents when reformulations are added, with accompanying tables and plots. The abstract will be updated to include key quantitative deltas and confidence intervals. revision: yes
-
Referee: [Method] Method description (surrogate model): the framework's ability to preserve recall while suppressing drift depends on the lightweight surrogate producing accurate enough utility estimates from reformulation-specific signals (e.g., retrieval scores and similarity features) to decide which documents merit teacher reranker queries. No quantitative evidence is supplied on surrogate-teacher correlation, on how many reranker calls are consumed by surrogate training itself, or on recall@K behavior as the candidate pool scales with reformulation count. This directly affects whether the selective querying mechanism works as claimed.
Authors: We agree that intermediate validation of the surrogate is necessary. The revision will add: (i) Pearson and Spearman correlations between surrogate utility scores and teacher reranker scores on a held-out validation set, (ii) a budget breakdown showing surrogate training consumes <5% of the total reranker calls, and (iii) scaling curves for recall@K (K=100,1000) as the number of reformulations grows from 1 to 10. These additions will directly demonstrate the surrogate's reliability for selective querying. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper introduces ReformIR as a budget-aware retrieval method that trains a lightweight surrogate on reformulation-specific signals to selectively query a teacher reranker. Performance claims rest on experiments over public MSMARCO and TREC DL19-DL22 corpora, with no equations, derivations, or self-referential definitions that reduce the reported gains to fitted parameters or prior self-citations. The surrogate and teacher components are described as external to the evaluation, and no load-bearing uniqueness theorems or ansatzes are invoked. The derivation chain is therefore self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A strong reranker provides reliable relevance labels for training the surrogate model.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Claudio Carpineto and Giovanni Romano. 2012. A survey of automatic query expansion in information retrieval.Acm Computing Surveys (CSUR)44, 1 (2012), 1–50
2012
-
[4]
Xinran Chen, Ben He, Xuanang Chen, and Le Sun. 2025. Not All Terms Matter: Recall-Oriented Adaptive Learning for PLM-aided Query Expansion in Open- Domain Question Answering. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher ...
2025
-
[5]
Cormack, Charles L A Clarke, and Stefan Buettcher
Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval(Boston, MA, USA)(SIGIR ’09). Association for Computing Machinery, New York, NY, USA, 758–759...
-
[6]
In: Diaz, F., Shah, C., Suel, T., Castells, P., Jones, R., Sakai, T
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, Ellen M. Voorhees, and Ian Soboroff. 2021. TREC Deep Learning Track: Reusable Test Collections in the Large Data Regime. InSIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Sha...
-
[7]
In: Computer Vision – ECCV 2022 Workshops, pp
Kaustubh D. Dhole and Eugene Agichtein. 2024. GenQREnsemble: Zero-Shot LLM Ensemble Prompting for Generative Query Reformulation. InAdvances in Information Retrieval: 46th European Conference on Information Retrieval, ECIR 2024, Glasgow, UK, March 24–28, 2024, Proceedings, Part III(Glasgow, United Kingdom). Springer-Verlag, Berlin, Heidelberg, 326–335. do...
-
[8]
Dhole, Ramraj Chandradevan, and Eugene Agichtein
Kaustubh D. Dhole, Ramraj Chandradevan, and Eugene Agichtein. 2024. Genera- tive Query Reformulation Using Ensemble Prompting, Document Fusion, and Relevance Feedback. arXiv:2405.17658 [cs.IR] https://arxiv.org/abs/2405.17658
-
[9]
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise Zero-Shot Dense Retrieval without Relevance Labels. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 1762...
-
[10]
Rolf Jagerman, Honglei Zhuang, Zhen Qin, Xuanhui Wang, and Michael Ben- dersky. 2023. Query Expansion by Prompting Large Language Models.CoRR abs/2305.03653 (2023). doi:10.48550/ARXIV.2305.03653 arXiv:2305.03653
-
[11]
Bruce Croft, Fernando Diaz, Leah S
Nasreen Abdul Jaleel, James Allan, W. Bruce Croft, Fernando Diaz, Leah S. Larkey, Xiaoyan Li, Mark D. Smucker, and Courtney Wade. 2004. UMass at TREC 2004: Novelty and HARD. InProceedings of the Thirteenth Text REtrieval Conference, TREC 2004, Gaithersburg, Maryland, USA, November 16-19, 2004 (NIST Special Publication, Vol. 500-261), Ellen M. Voorhees and...
2004
-
[12]
Pengyue Jia, Yiding Liu, Xiangyu Zhao, Xiaopeng Li, Changying Hao, Shuaiqiang Wang, and Dawei Yin. 2024. MILL: Mutual Verification with Large Language Models for Zero-Shot Query Expansion. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
-
[13]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. 2025. DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning. CoRRabs/2503.00223 (2025). doi:10.48550/ARXIV.2503.00223 arXiv:2503.00223
-
[14]
Hye-young Kim, Minjin Choi, Sunkyung Lee, Eunseong Choi, Young-In Song, and Jongwuk Lee. 2023. ConQueR: Contextualized Query Reduction using Search Logs. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 1899–...
-
[15]
Melda Korkut and Andrew Li. 2021. Disposable Linear Bandits for Online Rec- ommendations.Proceedings of the AAAI Conference on Artificial Intelligence35, 5 (May 2021), 4172–4180. doi:10.1609/aaai.v35i5.16540
-
[16]
Victor Lavrenko and W. Bruce Croft. 2001. Relevance based language models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(New Orleans, Louisiana, USA)(SIGIR ’01). Association for Computing Machinery, New York, NY, USA, 120–127. doi:10. 1145/383952.383972
-
[17]
Minghan Li, Honglei Zhuang, Kai Hui, Zhen Qin, Jimmy Lin, Rolf Jagerman, Xuanhui Wang, and Michael Bendersky. 2024. Can Query Expansion Improve Generalization of Strong Cross-Encoder Rankers?. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Informa- tion Retrieval(Washington DC, USA)(SIGIR ’24). Association for ...
-
[18]
Lijun Lyu and Avishek Anand. 2023. Listwise Explanations for Ranking Models Using Multiple Explainers. InAdvances in Information Retrieval, Jaap Kamps, Lorraine Goeuriot, Fabio Crestani, Maria Maistro, Hideo Joho, Brian Davis, Cathal Gurrin, Udo Kruschwitz, and Annalina Caputo (Eds.). Springer Nature Switzer- land, Cham, 653–668
2023
-
[19]
Sean MacAvaney and Nicola Tonellotto. 2024. A Reproducibility Study of PLAID. InProceedings of the 47th International ACM SIGIR Conference on Research and When More Reformulations Hurt: Avoiding Drift using Ranker Feedback Conference’17, July 2017, Washington, DC, USA Development in Information Retrieval (SIGIR 2024). ACM, 1411–1419. doi:10.1145/ 3626772.3657856
-
[20]
Sean MacAvaney and Xi Wang. 2023. Online Distillation for Pseudo-Relevance Feedback.CoRRabs/2306.09657 (2023). doi:10.48550/ARXIV.2306.09657 arXiv:2306.09657
-
[21]
Craig Macdonald, Nicola Tonellotto, Sean MacAvaney, and Iadh Ounis. 2021. PyTerrier: Declarative Experimentation in Python from BM25 to Dense Re- trieval. InProceedings of the 30th ACM International Conference on Informa- tion & Knowledge Management(Virtual Event, Queensland, Australia)(CIKM ’21). Association for Computing Machinery, New York, NY, USA, 45...
-
[22]
Iain Mackie, Shubham Chatterjee, and Jeffrey Dalton. 2023. Generative and Pseudo-Relevant Feedback for Sparse, Dense and Learned Sparse Retrieval.CoRR abs/2305.07477 (2023). doi:10.48550/ARXIV.2305.07477 arXiv:2305.07477
-
[23]
Iain Mackie, Shubham Chatterjee, and Jeffrey Dalton. 2023. Generative relevance feedback with large language models. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2026–2031
2023
-
[24]
Iain Mackie, Ivan Sekulic, Shubham Chatterjee, Jeffrey Dalton, and Fabio Crestani
- [25]
-
[26]
Yuning Mao, Pengcheng He, Xiaodong Liu, Yelong Shen, Jianfeng Gao, Jiawei Han, and Weizhu Chen. 2021. Generation-Augmented Retrieval for Open-Domain Question Answering. InProceedings of the 59th Annual Meeting of the Associa- tion for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Paper...
-
[27]
Donald Metzler and W. Bruce Croft. 2007. Latent concept expansion using markov random fields. InProceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(Amsterdam, The Netherlands)(SIGIR ’07). Association for Computing Machinery, New York, NY, USA, 311–318. doi:10.1145/1277741.1277796
-
[28]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. InProceedings of the Workshop on Cogni- tive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Syste...
2016
-
[29]
Iadh Ounis, Gianni Amati, Vassilis Plachouras, Ben He, Craig Macdonald, and Douglas Johnson. 2005. Terrier information retrieval platform. InAdvances in Information Retrieval: 27th European Conference on IR Research, ECIR 2005, Santiago de Compostela, Spain, March 21-23, 2005. Proceedings 27. Springer, 517–519
2005
-
[30]
Kiran Purohit, V Venktesh, Sourangshu Bhattacharya, and Avishek Anand. 2025. Sample Efficient Demonstration Selection for In-Context Learning. InInterna- tional Conference on Machine Learning. PMLR, 49959–49982
2025
-
[31]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Mandeep Rathee, Sean MacAvaney, and Avishek Anand. 2025. Quam: Adaptive Retrieval through Query Affinity Modelling. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining(Hannover, Germany) (WSDM ’25). Association for Computing Machinery, New York, NY, USA, 954–962. doi:10.1145/3701551.3703584
-
[33]
Mandeep Rathee, Venktesh V, Sean MacAvaney, and Avishek Anand. 2025. Breaking the Lens of the Telescope: Online Relevance Estimation over Large Retrieval Sets. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 2...
-
[34]
Clémence Réda, Emilie Kaufmann, and Andrée Delahaye-Duriez. 2021. Top-m identification for linear bandits. InThe 24th International Conference on Artificial Intelligence and Statistics, AISTATS 2021, April 13-15, 2021, Virtual Event (Proceed- ings of Machine Learning Research, Vol. 130), Arindam Banerjee and Kenji Fuku- mizu (Eds.). PMLR, 1108–1116. http:...
2021
-
[35]
JJ Rocchio. 1971. Relevance feedback in information retrieval.The SMART Retrieval System-Experiments in Automatic Document Processing/Prentice Hall (1971)
1971
-
[36]
2008.Intro- duction to information retrieval
Hinrich Schütze, Christopher D Manning, and Prabhakar Raghavan. 2008.Intro- duction to information retrieval. Vol. 39. Cambridge University Press Cambridge
2008
-
[37]
Wonduk Seo and Seunghyun Lee. 2025. QA-Expand: Multi-Question Answer Generation for Enhanced Query Expansion in Information Retrieval.CoRR abs/2502.08557 (2025). doi:10.48550/ARXIV.2502.08557 arXiv:2502.08557
-
[38]
Tao Shen, Guodong Long, Xiubo Geng, Chongyang Tao, Yibin Lei, Tianyi Zhou, Michael Blumenstein, and Daxin Jiang. 2024. Retrieval-Augmented Retrieval: Large Language Models are Strong Zero-Shot Retriever. InFindings of the As- sociation for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computatio...
-
[39]
Jaspreet Singh and Avishek Anand. 2020. Model agnostic interpretability of rankers via intent modelling. InFAT* ’20: Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, January 27-30, 2020, Mireille Hildebrandt, Carlos Castillo, L. Elisa Celis, Salvatore Ruggieri, Linnet Taylor, and Gabriela Zanfir-Fortuna (Eds.). ACM, 618–628. doi...
-
[40]
Mingyang Song and Mao Zheng. 2024. A Survey of Query Optimization in Large Language Models.CoRRabs/2412.17558 (2024). doi:10.48550/ARXIV.2412.17558 arXiv:2412.17558
-
[41]
Howard R. Turtle and James Flood. 1995. Query Evaluation: Strategies and Optimizations.Inf. Process. Manag.31, 6 (1995), 831–850. doi:10.1016/0306- 4573(95)00020-H
-
[42]
Haoyu Wang, Ruirui Li, Haoming Jiang, Jinjin Tian, Zhengyang Wang, Chen Luo, Xianfeng Tang, Monica Xiao Cheng, Tuo Zhao, and Jing Gao. 2024. BlendFilter: Advancing Retrieval-Augmented Large Language Models via Query Generation Blending and Knowledge Filtering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser ...
-
[43]
Liang Wang, Nan Yang, and Furu Wei. 2023. Query2doc: Query Expansion with Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 9414–9423. doi:10.18653/v1/2023.emnlp-main.585
-
[44]
Xiao Wang, Sean MacAvaney, Craig Macdonald, and Iadh Ounis. 2023. Generative Query Reformulation for Effective Adhoc Search.CoRRabs/2308.00415 (2023). doi:10.48550/ARXIV.2308.00415 arXiv:2308.00415
-
[45]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 248...
2022
-
[46]
Jinxi Xu and W. Bruce Croft. 1996. Query expansion using local and global document analysis. InProceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(Zurich, Switzer- land)(SIGIR ’96). Association for Computing Machinery, New York, NY, USA, 4–11. doi:10.1145/243199.243202
-
[47]
Chengxiang Zhai and John Lafferty. 2001. Model-based feedback in the language modeling approach to information retrieval. InProceedings of the Tenth Interna- tional Conference on Information and Knowledge Management(Atlanta, Georgia, USA)(CIKM ’01). Association for Computing Machinery, New York, NY, USA, 403–410. doi:10.1145/502585.502654
-
[48]
Le Zhang, Yihong Wu, Qian Yang, and Jian-Yun Nie. 2024. Exploring the Best Practices of Query Expansion with Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 1872–1883. doi:10.18653/v1/202...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.