Recognition: unknown
Depth-Guided Privacy-Preserving Visual Localization Using 3D Sphere Clouds
Pith reviewed 2026-05-09 19:19 UTC · model grok-4.3
The pith
Sphere clouds neutralize density-based attacks on private maps for visual localization by lifting points to lines through the map centroid, with ToF depth fixing the translation scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing the scene map as a sphere cloud where every point is lifted to a line passing through the map centroid, the approach misleads density-based attackers into recovering points at the centroid rather than the actual structure. This, together with a simple strategy to prevent direct image recovery and depth guidance from ToF sensors for scale, supports effective privacy-preserving localization with competitive accuracy and runtime.
What carries the argument
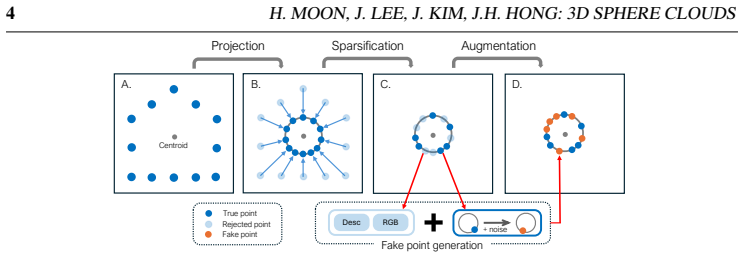
The sphere cloud, a scene representation that lifts all map points to 3D lines crossing the map centroid to create maximum line density at the center and thereby mislead density-based recovery algorithms.
If this is right
- Density-based attacks are neutralized because lines concentrate at the centroid, so attackers output points there instead of the true map geometry.
- A simple cloud construction strategy prevents direct recovery of images from the sphere representation.
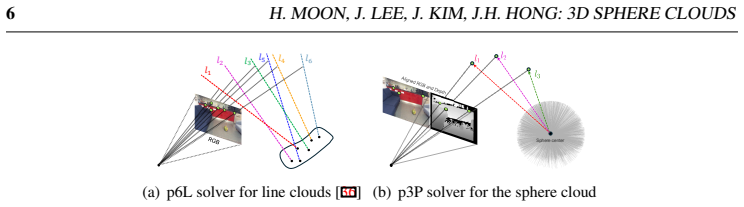
- On-device ToF depth maps provide the absolute translation scale that the line-based representation lacks.
- Pose estimation accuracy stays competitive with other depth-guided localization methods.
- Localization runtime remains efficient while privacy protection holds.
Where Pith is reading between the lines
- The centroid-lifting tactic could extend to other 3D representations to add privacy in tasks like object detection or mapping.
- This representation might enable safer map sharing in collaborative AR or robotics settings where environments must stay private.
- The need to counter a new attack vector after introducing the sphere cloud suggests a general pattern for privacy methods: each obfuscation can create fresh vulnerabilities that require targeted fixes.
- If ToF sensors are unavailable, alternative scale-recovery techniques would need testing to maintain the method's utility.
Load-bearing premise
That a simple construction strategy fully blocks the new direct image-recovery attack introduced by the sphere representation itself, and that absolute depth maps from on-device ToF sensors reliably supply accurate translation scale.
What would settle it
An attacker recovering high-fidelity scene images or accurate point-cloud geometry from the sphere cloud despite the construction strategy, or localization errors rising substantially above baselines on RGB-D datasets that include ToF depth.
Figures













read the original abstract
The emergence of deep neural networks capable of revealing high-fidelity scene details from sparse 3D point clouds has raised significant privacy concerns in visual localization involving private maps. Lifting map points to randomly oriented 3D lines is a well-known approach for obstructing undesired recovery of the scene images, but these lines are vulnerable to a density-based attack that can recover the point cloud geometry by observing the neighborhood statistics of lines. With the aim of nullifying this attack, we present a new privacy-preserving scene representation called \emph{sphere cloud}, which is constructed by lifting all points to 3D lines crossing the centroid of the map, resembling points on the unit sphere. Since lines are most dense at the map centroid, the sphere cloud mislead the density-based attack algorithm to incorrectly yield points at the centroid, effectively neutralizing the attack. Nevertheless, this advantage comes at the cost of i) a new type of attack that may directly recover images from this cloud representation and ii) unresolved translation scale for camera pose estimation. To address these issues, we introduce a simple yet effective cloud construction strategy to thwart new attack and propose an efficient localization framework to guide the translation scale by utilizing absolute depth maps acquired from on-device time-of-flight (ToF) sensors. Experimental results on public RGB-D datasets demonstrate sphere cloud achieves competitive privacy-preserving ability and localization runtime while not excessively compensating the pose estimation accuracy compared to other depth-guided localization methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a 'sphere cloud' scene representation for privacy-preserving visual localization. Map points are lifted to 3D lines passing through the map centroid (resembling points on the unit sphere) to obstruct density-based attacks that recover geometry from line neighborhood statistics. A 'simple yet effective' construction strategy is introduced to block a new direct image-recovery attack created by this all-lines-through-centroid geometry, while on-device ToF absolute depth maps resolve the missing translation scale for pose estimation. Experiments on public RGB-D datasets are claimed to demonstrate competitive privacy preservation, localization runtime, and pose accuracy relative to other depth-guided methods.
Significance. If the privacy guarantees are substantiated, the geometric construction offers a lightweight, parameter-free alternative to existing privacy mechanisms in visual localization, potentially enabling safer sharing of private 3D maps in AR, robotics, and mapping applications. The integration of commodity ToF sensors for scale recovery is a pragmatic engineering contribution that avoids reliance on additional infrastructure.
major comments (2)
- [Abstract] Abstract and method description: the central privacy claim rests on the assertion that a 'simple yet effective cloud construction strategy' fully neutralizes the new direct image-recovery attack introduced by the sphere-cloud geometry itself. No attack model (e.g., adversary optimization or image features exploited), no precise modification rule (jitter, masking, re-orientation), and no derivation or ablation demonstrating effectiveness are supplied. This mechanism is load-bearing for the privacy guarantee and cannot be evaluated from the given description.
- [Abstract] Abstract and experimental claims: the manuscript states that sphere clouds achieve 'competitive privacy-preserving ability and localization runtime while not excessively compromising pose estimation accuracy,' yet supplies no quantitative numbers, error bars, baseline tables, or statistical comparisons. Without these data the performance claims cannot be assessed and the 'not excessively compensating' assertion remains unsupported.
minor comments (1)
- [Abstract] The abstract introduces the sphere cloud as 'resembling points on the unit sphere' but does not clarify whether the lines are normalized to unit length or how this affects downstream localization pipelines; a short clarifying sentence or diagram would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and insightful comments on our work. We address each of the major comments in detail below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central privacy claim rests on the assertion that a 'simple yet effective cloud construction strategy' fully neutralizes the new direct image-recovery attack introduced by the sphere-cloud geometry itself. No attack model (e.g., adversary optimization or image features exploited), no precise modification rule (jitter, masking, re-orientation), and no derivation or ablation demonstrating effectiveness are supplied. This mechanism is load-bearing for the privacy guarantee and cannot be evaluated from the given description.
Authors: We appreciate this observation regarding the level of detail in the abstract. The full manuscript in Section 3 provides the construction strategy for the sphere cloud, which involves lifting points to lines through the centroid and applying specific perturbations to prevent direct image recovery. However, to ensure the privacy mechanism can be fully evaluated, we will revise the abstract to briefly outline the attack model (including the optimization objective and exploited features such as line density and orientation statistics) and the modification rules (e.g., controlled jitter in line orientations and selective masking). Furthermore, we will add a dedicated ablation study in the experimental section demonstrating the strategy's effectiveness, including quantitative results on attack success rates before and after the modifications. This addresses the load-bearing nature of the claim. revision: yes
-
Referee: [Abstract] Abstract and experimental claims: the manuscript states that sphere clouds achieve 'competitive privacy-preserving ability and localization runtime while not excessively compromising pose estimation accuracy,' yet supplies no quantitative numbers, error bars, baseline tables, or statistical comparisons. Without these data the performance claims cannot be assessed and the 'not excessively compensating' assertion remains unsupported.
Authors: We acknowledge that the abstract, as a concise summary, does not include specific numerical results. The manuscript's experimental section (Section 4) presents comprehensive quantitative evaluations on public RGB-D datasets, including tables with pose estimation errors (translation and rotation), runtime measurements, and privacy metrics (e.g., attack success rates) compared to baseline methods, along with error bars from repeated trials and statistical analysis. To better support the claims in the abstract, we will incorporate key quantitative highlights, such as average accuracy metrics and runtime comparisons, into the revised abstract. This will allow readers to assess the 'competitive' and 'not excessively compromising' aspects directly from the abstract while referring to the full tables for details. revision: yes
Circularity Check
No circularity: geometric construction yields privacy property directly from definition
full rationale
The paper's core privacy claim follows immediately from the explicit geometric definition of the sphere cloud (all lines through the map centroid), which by construction produces maximum line density at that centroid and thereby misleads the density-based attack. This is a direct consequence of the lifting operation rather than a fitted parameter, self-referential definition, or load-bearing self-citation. The additional 'simple yet effective' construction strategy and ToF scale recovery are presented as separate engineering steps without any reduction of the central result to its own inputs or outputs. No equations or data-driven predictions are shown that would collapse the claimed outcome back onto the construction itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lines are most dense at the map centroid, misleading density-based attacks to place points at the centroid
- domain assumption On-device ToF sensors supply reliable absolute depth maps for translation scale
invented entities (1)
-
sphere cloud
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wide area localization on mobile phones
Clemens Arth, Daniel Wagner, Manfred Klopschitz, Arnold Irschara, and Dieter Schmalstieg. Wide area localization on mobile phones. In2009 8th IEEE Interna- tional Symposium on Mixed and Augmented Reality, pages 73–82. IEEE, 2009
2009
-
[2]
Depth-guided privacy-preserving visual localization using 3d sphere clouds, BMVC 2024 submission #267, 2024
Authors. Depth-guided privacy-preserving visual localization using 3d sphere clouds, BMVC 2024 submission #267, 2024
2024
-
[3]
Visual camera re-localization from RGB and RGB-D images using DSAC.TPAMI, 2021
Eric Brachmann and Carsten Rother. Visual camera re-localization from RGB and RGB-D images using DSAC.TPAMI, 2021
2021
-
[4]
On the limits of pseudo ground truth in visual camera re-localisation
Eric Brachmann, Martin Humenberger, Carsten Rother, and Torsten Sattler. On the limits of pseudo ground truth in visual camera re-localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6218–6228, October 2021
2021
-
[5]
Video-rate localization in multiple maps for wearable augmented reality
Robert Castle, Georg Klein, and David W Murray. Video-rate localization in multiple maps for wearable augmented reality. In2008 12th IEEE International Symposium on Wearable Computers, pages 15–22. IEEE, 2008
2008
-
[6]
How privacy-preserving are line clouds? Recovering scene details from 3D lines
Kunal Chelani, Fredrik Kahl, and Torsten Sattler. How privacy-preserving are line clouds? Recovering scene details from 3D lines. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15663–15673,
-
[7]
doi: 10.1109/CVPR46437.2021.01541
-
[8]
Privacy-preserving representations are not enough: Recovering scene content from camera poses
Kunal Chelani, Torsten Sattler, Fredrik Kahl, and Zuzana Kukelova. Privacy-preserving representations are not enough: Recovering scene content from camera poses. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13132–13141, 2023
2023
-
[9]
Locally optimized ransac
Ondrej Chum, Jirí Matas, and Josef Kittler. Locally optimized ransac. InPattern Recognition: 25th DAGM Symposium, Magdeburg, Germany, September 10-12, 2003. Proceedings 25, pages 236–243. Springer, 2003
2003
-
[10]
Mitigating reverse engineering attacks on local feature descriptors
Deeksha Dangwal, Vincent T Lee, Hyo Jin Kim, Tianwei Shen, Meghan Cowan, Rajvi Shah, Caroline Trippel, Brandon Reagen, Timothy Sherwood, Vasileios Balntas, et al. Mitigating reverse engineering attacks on local feature descriptors. InProceeding of the British Machine Vision Conference (BMVC), 2021
2021
-
[11]
Revisiting the p3p problem
Yaqing Ding, Jian Yang, Viktor Larsson, Carl Olsson, and Kalle Åström. Revisiting the p3p problem. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4872–4880, 2023
2023
-
[12]
Mihai Dusmanu, Johannes L. Schönberger, Sudipta N. Sinha, and Marc Pollefeys. Privacy-preserving image features via adversarial affine subspace embeddings. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14262–14272, 2021. doi: 10.1109/CVPR46437.2021.01404. 22H. MOON, J. LEE, J. KIM, J.H. HONG: 3D SPHERE CLOUDS
-
[13]
Pri- vacy preserving partial localization
Marcel Geppert, Viktor Larsson, Johannes L Schönberger, and Marc Pollefeys. Pri- vacy preserving partial localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17337–17347, 2022
2022
-
[14]
Cheirality.International journal of computer vision, 26(1):41–61, 1998
Richard Hartley. Cheirality.International journal of computer vision, 26(1):41–61, 1998
1998
-
[15]
Martin Humenberger, Yohann Cabon, Nicolas Guerin, Julien Morat, Vincent Leroy, Jérôme Revaud, Philippe Rerole, Noé Pion, Cesar de Souza, and Gabriela Csurka. Robust image retrieval-based visual localization using kapture.arXiv preprint arXiv:2007.13867, 2020
-
[16]
An efficient algebraic solution to the perspective- three-point problem
Tong Ke and Stergios I Roumeliotis. An efficient algebraic solution to the perspective- three-point problem. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7225–7233, 2017
2017
-
[17]
PoseLib - Minimal Solvers for Camera Pose Estimation.https: //github.com/vlarsson/PoseLib, 2020
Viktor Larsson. PoseLib - Minimal Solvers for Camera Pose Estimation.https: //github.com/vlarsson/PoseLib, 2020. Accessed: 2022-10-30
2020
-
[18]
Paired-point lifting for enhanced privacy-preserving visual localization
Chunghwan Lee, Jaihoon Kim, Chanhyuk Yun, and Je Hyeong Hong. Paired-point lifting for enhanced privacy-preserving visual localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17266–17275, 2023
2023
-
[19]
David G. Lowe. Distinctive image features from scale-invariant keypoints.Inter- national Journal of Computer Vision, 60(2):91–110, November 2004. ISSN 0920-
2004
-
[20]
doi: 10.1023/B:VISI.0000029664.99615.94. URLhttps://doi.org/10. 1023/B:VISI.0000029664.99615.94
-
[21]
Get out of my lab: Large-scale, real-time visual-inertial localiza- tion
Simon Lynen, Torsten Sattler, Michael Bosse, Joel A Hesch, Marc Pollefeys, and Roland Siegwart. Get out of my lab: Large-scale, real-time visual-inertial localiza- tion. InRobotics: Science and Systems, volume 1, page 1, 2015
2015
-
[22]
Working hard to know your neighbor’s margins: Local descriptor learning loss.Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
Anastasiia Mishchuk, Dmytro Mishkin, Filip Radenovic, and Jiri Matas. Working hard to know your neighbor’s margins: Local descriptor learning loss.Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[23]
Efficient privacy-preserving visual localization using 3d ray clouds
Heejoon Moon, Chunghwan Lee, and Je Hyeong Hong. Efficient privacy-preserving visual localization using 3d ray clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9773–9783, June 2024
2024
-
[24]
Supplemen- tary document of depth-guided privacy-preserving visual localization using 3d sphere clouds, 2024
Heejoon Moon, Jongwoo Lee, Jeonggon Kim, and Je Hyeong Hong. Supplemen- tary document of depth-guided privacy-preserving visual localization using 3d sphere clouds, 2024
2024
-
[25]
ORB-SLAM: A versatile and accurate monocular SLAM system.IEEE Transactions on Robotics, 31 (5):1147–1163, 2015
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. ORB-SLAM: A versatile and accurate monocular SLAM system.IEEE Transactions on Robotics, 31 (5):1147–1163, 2015
2015
-
[26]
An efficient solution to the five-point relative pose problem.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 26(6):756–770, 2004
David Nistér. An efficient solution to the five-point relative pose problem.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 26(6):756–770, 2004. H. MOON, J. LEE, J. KIM, J.H. HONG: 3D SPHERE CLOUDS23
2004
-
[27]
Privacy Preserving Localization via Coordinate Permutations
Linfei Pan, Johannes Lutz Schönberger, Viktor Larsson, and Marc Pollefeys. Privacy Preserving Localization via Coordinate Permutations. InProceedings of the IEEE In- ternational Conference on Computer Vision (ICCV), 2023
2023
-
[28]
Lambda twist: An accurate fast robust perspective three point (p3P) solver
Mikael Persson and Klas Nordberg. Lambda twist: An accurate fast robust perspective three point (p3P) solver. InProceedings of the European conference on computer vision (ECCV), pages 318–332, 2018
2018
-
[29]
Se- gloc: Learning segmentation-based representations for privacy-preserving visual local- ization
Maxime Pietrantoni, Martin Humenberger, Torsten Sattler, and Gabriela Csurka. Se- gloc: Learning segmentation-based representations for privacy-preserving visual local- ization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15380–15391, 2023
2023
-
[30]
Learning privacy pre- serving encodings through adversarial training
Francesco Pittaluga, Sanjeev Koppal, and Ayan Chakrabarti. Learning privacy pre- serving encodings through adversarial training. InProceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pages 791–799. IEEE, 2019
2019
-
[31]
Reveal- ing scenes by inverting structure from motion reconstructions
Francesco Pittaluga, Sanjeev J Koppal, Sing Bing Kang, and Sudipta N Sinha. Reveal- ing scenes by inverting structure from motion reconstructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 145–154, 2019
2019
-
[32]
R2d2: Reliable and repeatable detector and descriptor.Advances in neural informa- tion processing systems, 32, 2019
Jerome Revaud, Cesar De Souza, Martin Humenberger, and Philippe Weinzaepfel. R2d2: Reliable and repeatable detector and descriptor.Advances in neural informa- tion processing systems, 32, 2019
2019
-
[33]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InProceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pages 234–241. Springer, 2015
2015
-
[34]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2016
2016
-
[35]
Privacy preserving visual SLAM
Mikiya Shibuya, Shinya Sumikura, and Ken Sakurada. Privacy preserving visual SLAM. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, pages 102–118. Springer, 2020
2020
-
[36]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2930–2937, 2013
2013
-
[37]
Deep novel view synthesis from colored 3d point clouds
Zhenbo Song, Wayne Chen, Dylan Campbell, and Hongdong Li. Deep novel view synthesis from colored 3d point clouds. InComputer Vision–ECCV 2020: 16th Eu- ropean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIV 16, pages 1–17. Springer, 2020
2020
-
[38]
Privacy preserving image-based localization
Pablo Speciale, Johannes L Schonberger, Sing Bing Kang, Sudipta N Sinha, and Marc Pollefeys. Privacy preserving image-based localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5493–5503, 2019. 24H. MOON, J. LEE, J. KIM, J.H. HONG: 3D SPHERE CLOUDS
2019
-
[39]
Solutions to minimal generalized relative pose problems, 2005
Henrik Stewénius, Magnus Oskarsson, Kalle Aström, and David Nistér. Solutions to minimal generalized relative pose problems, 2005
2005
-
[40]
24/7 place recognition by view synthesis
Akihiko Torii, Relja Arandjelovic, Josef Sivic, Masatoshi Okutomi, and Tomas Pajdla. 24/7 place recognition by view synthesis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1808–1817, 2015
2015
-
[41]
Learning to navigate the energy landscape
Julien Valentin, Angela Dai, Matthias Niessner, Pushmeet Kohli, Philip Torr, Shahram Izadi, and Cem Keskin. Learning to navigate the energy landscape. In2016 Fourth International Conference on 3D Vision (3DV), pages 323–332, 2016. doi: 10.1109/ 3DV .2016.41
2016
-
[42]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.