Intrinsic Gradient Suppression for Label-Noise Prompt Tuning in Vision-Language Models
Pith reviewed 2026-05-09 19:01 UTC · model grok-4.3
The pith
Double-Softmax Prompt Tuning applies sequential normalization to suppress gradients from noisy labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Double-Softmax Prompt Tuning performs sequential probabilistic normalization on the output probabilities. This produces a self-adaptive saturation zone in the gradient flow that automatically reduces the magnitude of updates coming from high-error noisy samples while preserving updates from lower-error samples.
What carries the argument
Double-Softmax Prompt Tuning, which uses sequential probabilistic normalization to induce a self-adaptive saturation zone that filters noisy gradients during prompt adaptation.
If this is right
- Prompt tuning for vision-language models becomes robust to label noise without any additional hyperparameters or architectural changes.
- The method reaches state-of-the-art accuracy on multiple noisy benchmarks while remaining a simple drop-in replacement.
- Gradient vanishing is converted from a training obstacle into a built-in mechanism that shields against noisy samples.
- Both theoretical analysis and experiments demonstrate that the saturation zone adapts to the error level of each sample.
Where Pith is reading between the lines
- The same sequential normalization idea could be tested in other fine-tuning regimes where strong pre-trained models meet noisy supervision.
- If the saturation effect scales with model size, larger vision-language models might show even stronger automatic noise resistance.
- Applying the double-softmax layer to the loss rather than only the output probabilities might extend the protection to other training objectives.
Load-bearing premise
CLIP already provides a near-optimal initialization, so adaptation must remain conservative and avoid extreme gradient steps triggered by noisy labels.
What would settle it
A direct comparison on a standard noisy-label benchmark in which ordinary prompt tuning reaches equal or higher accuracy than DSPT would show that the claimed saturation-based suppression does not deliver the stated robustness gain.
Figures



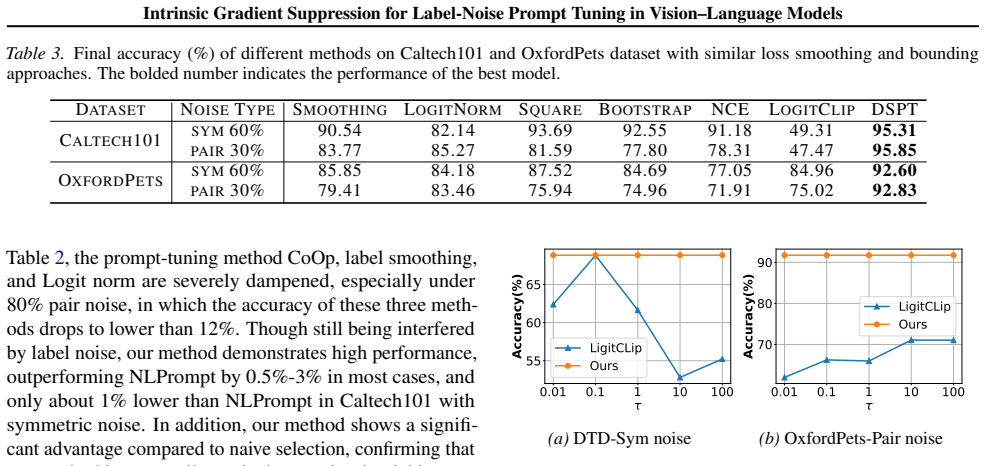
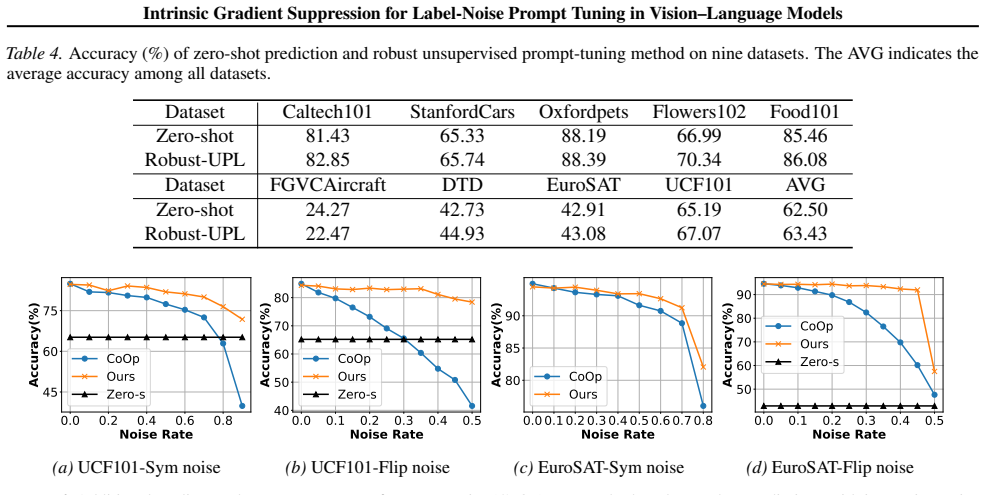


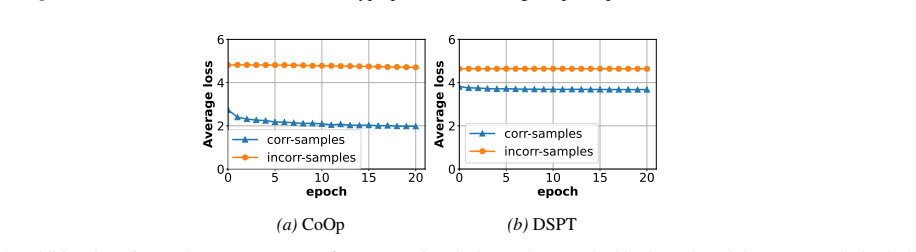
read the original abstract
Contrastive vision-language models like CLIP exhibit remarkable zero-shot generalization. However, prompt tuning remains highly sensitive to label noise, as mislabeled samples generate disproportionately large gradients that can overwhelm pre-trained priors. We argue that because CLIP already provides a near-optimal initialization, adaptation should be inherently conservative, particularly against the extreme gradient updates common in noisy settings. To this end, we propose Double-Softmax Prompt Tuning (DSPT), a hyperparameter-free method for intrinsic gradient suppression. By applying a sequential probabilistic normalization, DSPT induces a self-adaptive saturation zone that suppresses gradients from high-error noisy samples while maintaining informative updates. We also provide both theoretical analysis and empirical evidence about how this mechanism achieves adaptive suppression. This design transforms ``gradient vanishing'', traditionally a training bottleneck, into a principled noise-filtering shield for label-noise prompt tuning. Extensive experiments confirm that this simple, drop-in design achieves state-of-the-art robustness across various noisy benchmarks, outperforming methods with complex architectures and handcrafted hyperparameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prompt tuning in contrastive vision-language models like CLIP is highly sensitive to label noise, as mislabeled samples generate large gradients that overwhelm pre-trained priors. It proposes Double-Softmax Prompt Tuning (DSPT), a hyperparameter-free method using sequential probabilistic normalization to induce a self-adaptive saturation zone that suppresses gradients from high-error noisy samples while maintaining informative updates from clean ones. The authors provide theoretical analysis and empirical evidence that this mechanism achieves adaptive suppression, repurposing gradient vanishing as a noise-filtering shield, and report state-of-the-art robustness across noisy benchmarks.
Significance. If validated, the result would be significant as a simple, intrinsic, hyperparameter-free baseline for robust prompt tuning that directly leverages CLIP's zero-shot initialization without added architectures or tuning. The conceptual reframing of gradient vanishing as a principled filter could influence practical noisy-label adaptation in vision-language models, provided the mechanism reliably separates noise from informative high-loss clean samples.
major comments (3)
- [Abstract] Abstract: The load-bearing claim that the saturation zone 'suppresses gradients from high-error noisy samples while maintaining informative updates' assumes loss magnitude is a reliable proxy for label noise. This may not hold for clean samples poorly aligned with CLIP priors (high loss despite correct labels), violating the 'maintains informative updates' guarantee. The manuscript must address this scenario explicitly, e.g., via targeted experiments on distribution-shifted clean data.
- [Theoretical analysis section] Theoretical analysis section: The abstract asserts 'both theoretical analysis and empirical evidence' on adaptive suppression, yet no equations, proof sketches, or definitions of the sequential probabilistic normalization and saturation zone are visible. Without these, it cannot be verified whether the suppression effect follows directly from the normalization or reduces to a fitted scaling factor, undermining the 'hyperparameter-free' and 'intrinsic' claims.
- [Experiments section] Experiments section: The SOTA robustness claim across 'various noisy benchmarks' is central but lacks detail on controls for the skeptic's concern (clean high-loss samples suppressed). If benchmarks only include in-distribution clean data, the results do not falsify the failure mode where the mechanism harms informative updates.
minor comments (1)
- [Abstract] The abstract could briefly name the specific benchmarks and noise rates used to substantiate the SOTA claim and allow immediate assessment of scope.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important considerations regarding the assumptions underlying our method and the strength of our validation. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that the saturation zone 'suppresses gradients from high-error noisy samples while maintaining informative updates' assumes loss magnitude is a reliable proxy for label noise. This may not hold for clean samples poorly aligned with CLIP priors (high loss despite correct labels), violating the 'maintains informative updates' guarantee. The manuscript must address this scenario explicitly, e.g., via targeted experiments on distribution-shifted clean data.
Authors: We agree that loss magnitude is not a perfect proxy and that clean samples with high loss due to misalignment with CLIP priors represent a valid edge case. In the revised manuscript we will add targeted experiments on distribution-shifted clean data (e.g., ImageNet variants with controlled shifts) to quantify the behavior of the saturation zone on such samples. These results will demonstrate that the self-adaptive mechanism primarily saturates extreme outliers while still permitting informative gradient updates from high-loss but correctly labeled examples. revision: yes
-
Referee: [Theoretical analysis section] Theoretical analysis section: The abstract asserts 'both theoretical analysis and empirical evidence' on adaptive suppression, yet no equations, proof sketches, or definitions of the sequential probabilistic normalization and saturation zone are visible. Without these, it cannot be verified whether the suppression effect follows directly from the normalization or reduces to a fitted scaling factor, undermining the 'hyperparameter-free' and 'intrinsic' claims.
Authors: The theoretical analysis appears in Section 3, where we define sequential probabilistic normalization and derive the resulting saturation zone. To address the concern that these elements may not be sufficiently prominent, we will expand the section with explicit equations for the double-softmax gradient, a concise proof sketch showing the adaptive saturation property, and a direct comparison to simple scaling to confirm the effect is intrinsic to the normalization rather than an added hyperparameter. revision: partial
-
Referee: [Experiments section] Experiments section: The SOTA robustness claim across 'various noisy benchmarks' is central but lacks detail on controls for the skeptic's concern (clean high-loss samples suppressed). If benchmarks only include in-distribution clean data, the results do not falsify the failure mode where the mechanism harms informative updates.
Authors: We acknowledge the need for explicit controls against the failure mode of suppressing informative high-loss clean samples. In addition to the existing noisy-label benchmarks, the revised experiments section will include ablations and controls on clean but distribution-shifted data to verify that DSPT preserves useful updates. These additions will directly test the skeptic's concern and strengthen the empirical support for the adaptive suppression claim. revision: yes
Circularity Check
No significant circularity; DSPT mechanism derived from explicit normalization design
full rationale
The paper defines DSPT via a concrete sequential probabilistic normalization (double-softmax) and then derives its saturation-zone suppression effect from the resulting gradient magnitudes. This is a standard forward derivation from the chosen functional form rather than a self-referential loop. The CLIP near-optimality premise is stated as an explicit modeling assumption, not obtained by fitting or by self-citation. No equations reduce the claimed noise-filtering property to a fitted hyperparameter or to a prior result whose only support is the present work. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLIP already provides a near-optimal initialization for prompt tuning
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories , booktitle =
Li Fei. Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories , booktitle =
-
[7]
3D Object Representations for Fine-Grained Categorization , booktitle =
Jonathan Krause and Michael Stark and Jia Deng and Li Fei. 3D Object Representations for Fine-Grained Categorization , booktitle =
-
[8]
Parkhi and Andrea Vedaldi and Andrew Zisserman and C
Omkar M. Parkhi and Andrea Vedaldi and Andrew Zisserman and C. V. Jawahar , title =. 2012
2012
-
[9]
Automated Flower Classification over a Large Number of Classes , booktitle =
Maria. Automated Flower Classification over a Large Number of Classes , booktitle =
-
[10]
Food-101 - Mining Discriminative Components with Random Forests , booktitle =
Lukas Bossard and Matthieu Guillaumin and Luc Van Gool , editor =. Food-101 - Mining Discriminative Components with Random Forests , booktitle =
-
[11]
Blaschko and Andrea Vedaldi , title =
Subhransu Maji and Esa Rahtu and Juho Kannala and Matthew B. Blaschko and Andrea Vedaldi , title =. CoRR , volume =. 2013 , eprinttype =
2013
-
[12]
Mircea Cimpoi and Subhransu Maji and Iasonas Kokkinos and Sammy Mohamed and Andrea Vedaldi , title =. 2014
2014
-
[13]
Patrick Helber and Benjamin Bischke and Andreas Dengel and Damian Borth , title =
-
[14]
CoRR , volume =
Khurram Soomro and Amir Roshan Zamir and Mubarak Shah , title =. CoRR , volume =. 2012 , eprinttype =
2012
-
[15]
Kaiyang Zhou and Jingkang Yang and Chen Change Loy and Ziwei Liu , title =. Int. J. Comput. Vis. , volume =
-
[16]
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels? , booktitle =
Cheng. Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels? , booktitle =
-
[17]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , booktitle =
Adam Paszke and Sam Gross and Francisco Massa and Adam Lerer and James Bradbury and Gregory Chanan and Trevor Killeen and Zeming Lin and Natalia Gimelshein and Luca Antiga and Alban Desmaison and Andreas K. PyTorch: An Imperative Style, High-Performance Deep Learning Library , booktitle =
-
[18]
Learning Transferable Visual Models From Natural Language Supervision , booktitle =
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , editor =. Learning Transferable Visual Models From Natural Language Supervision , booktitle =
-
[19]
Kaiyang Zhou and Jingkang Yang and Chen Change Loy and Ziwei Liu , title =
-
[20]
Junnan Li and Dongxu Li and Caiming Xiong and Steven C. H. Hoi , editor =. International Conference on Machine Learning,
-
[21]
CoRR , volume =
Tony Huang and Jack Chu and Fangyun Wei , title =. CoRR , volume =. 2022 , doi =
2022
-
[22]
Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models , booktitle =
Manli Shu and Weili Nie and De. Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models , booktitle =
-
[23]
Mitigating Memorization of Noisy Labels by Clipping the Model Prediction , booktitle =
Hongxin Wei and Huiping Zhuang and Renchunzi Xie and Lei Feng and Gang Niu and Bo An and Yixuan Li , editor =. Mitigating Memorization of Noisy Labels by Clipping the Model Prediction , booktitle =
-
[24]
Mitigating Neural Network Overconfidence with Logit Normalization , booktitle =
Hongxin Wei and Renchunzi Xie and Hao Cheng and Lei Feng and Bo An and Yixuan Li , editor =. Mitigating Neural Network Overconfidence with Logit Normalization , booktitle =
-
[25]
2024 , doi =
Yuncheng Guo and Xiaodong Gu , title =. 2024 , doi =
2024
-
[26]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Chaowei Fang and Hangfei Ma and Zhihao Li and De Cheng and Yue Zhang and Guanbin Li , title =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , doi =
2025
-
[27]
Bikang Pan and Qun Li and Xiaoying Tang and Wei Huang and Zhen Fang and Feng Liu and Jingya Wang and Jingyi Yu and Ye Shi , title =
-
[28]
Junnan Li and Richard Socher and Steven C. H. Hoi , title =. 8th International Conference on Learning Representations,
-
[29]
Deep Patel and P. S. Sastry , title =
-
[30]
Haobo Wang and Ruixuan Xiao and Yixuan Li and Lei Feng and Gang Niu and Gang Chen and Junbo Zhao , title =
-
[31]
Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting , booktitle =
Jun Shu and Qi Xie and Lixuan Yi and Qian Zhao and Sanping Zhou and Zongben Xu and Deyu Meng , editor =. Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting , booktitle =
-
[32]
Aritra Ghosh and Himanshu Kumar and P. S. Sastry , editor =. Robust Loss Functions under Label Noise for Deep Neural Networks , booktitle =
-
[33]
Erfani and James Bailey , title =
Xingjun Ma and Hanxun Huang and Yisen Wang and Simone Romano and Sarah M. Erfani and James Bailey , title =. Proceedings of the 37th International Conference on Machine Learning,
-
[34]
Proceedings of the 37th International Conference on Machine Learning,
Michal Lukasik and Srinadh Bhojanapalli and Aditya Krishna Menon and Sanjiv Kumar , title =. Proceedings of the 37th International Conference on Machine Learning,
-
[35]
Reed and Honglak Lee and Dragomir Anguelov and Christian Szegedy and Dumitru Erhan and Andrew Rabinovich , editor =
Scott E. Reed and Honglak Lee and Dragomir Anguelov and Christian Szegedy and Dumitru Erhan and Andrew Rabinovich , editor =. Training Deep Neural Networks on Noisy Labels with Bootstrapping , booktitle =
-
[36]
9th International Conference on Learning Representations,
Xiaobo Xia and Tongliang Liu and Bo Han and Chen Gong and Nannan Wang and Zongyuan Ge and Yi Chang , title =. 9th International Conference on Learning Representations,
-
[37]
Asymmetric Loss Functions for Learning with Noisy Labels , booktitle =
Xiong Zhou and Xianming Liu and Junjun Jiang and Xin Gao and Xiangyang Ji , editor =. Asymmetric Loss Functions for Learning with Noisy Labels , booktitle =
-
[38]
Sabuncu , editor =
Zhilu Zhang and Mert R. Sabuncu , editor =. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels , booktitle =
-
[39]
Metaxas and Chao Chen , title =
Songzhu Zheng and Pengxiang Wu and Aman Goswami and Mayank Goswami and Dimitris N. Metaxas and Chao Chen , title =. Proceedings of the 37th International Conference on Machine Learning,
-
[40]
Yu Yao and Tongliang Liu and Bo Han and Mingming Gong and Jiankang Deng and Gang Niu and Masashi Sugiyama , editor =. Dual. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[41]
Dumais , title =
Guoqing Zheng and Ahmed Hassan Awadallah and Susan T. Dumais , title =. Thirty-Fifth
-
[42]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,
-
[43]
Beyond Class-Conditional Assumption:
Pengfei Chen and Junjie Ye and Guangyong Chen and Jingwei Zhao and Pheng. Beyond Class-Conditional Assumption:. Thirty-Fifth
-
[44]
Are Anchor Points Really Indispensable in Label-Noise Learning? , booktitle =
Xiaobo Xia and Tongliang Liu and Nannan Wang and Bo Han and Chen Gong and Gang Niu and Masashi Sugiyama , editor =. Are Anchor Points Really Indispensable in Label-Noise Learning? , booktitle =
-
[45]
Khan and Fahad Shahbaz Khan , title =
Muhammad Uzair Khattak and Hanoona Abdul Rasheed and Muhammad Maaz and Salman H. Khan and Fahad Shahbaz Khan , title =
-
[46]
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. 2016
2016
-
[47]
Handbook of Systemic Autoimmune Diseases , volume=
Learning multiple layers of features from tiny images , author=. Handbook of Systemic Autoimmune Diseases , volume=
-
[48]
mixup: Beyond Empirical Risk Minimization , booktitle =
Hongyi Zhang and Moustapha Ciss. mixup: Beyond Empirical Risk Minimization , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.