Recognition: unknown
Inductive Latent Context Persistence: Closing the Post-Handover Cold Start in 6G Radio Access Networks
Pith reviewed 2026-05-09 18:39 UTC · model grok-4.3
The pith
Compressing and transferring the recurrent state across handovers lets graph models retain mobility history instead of rebuilding from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
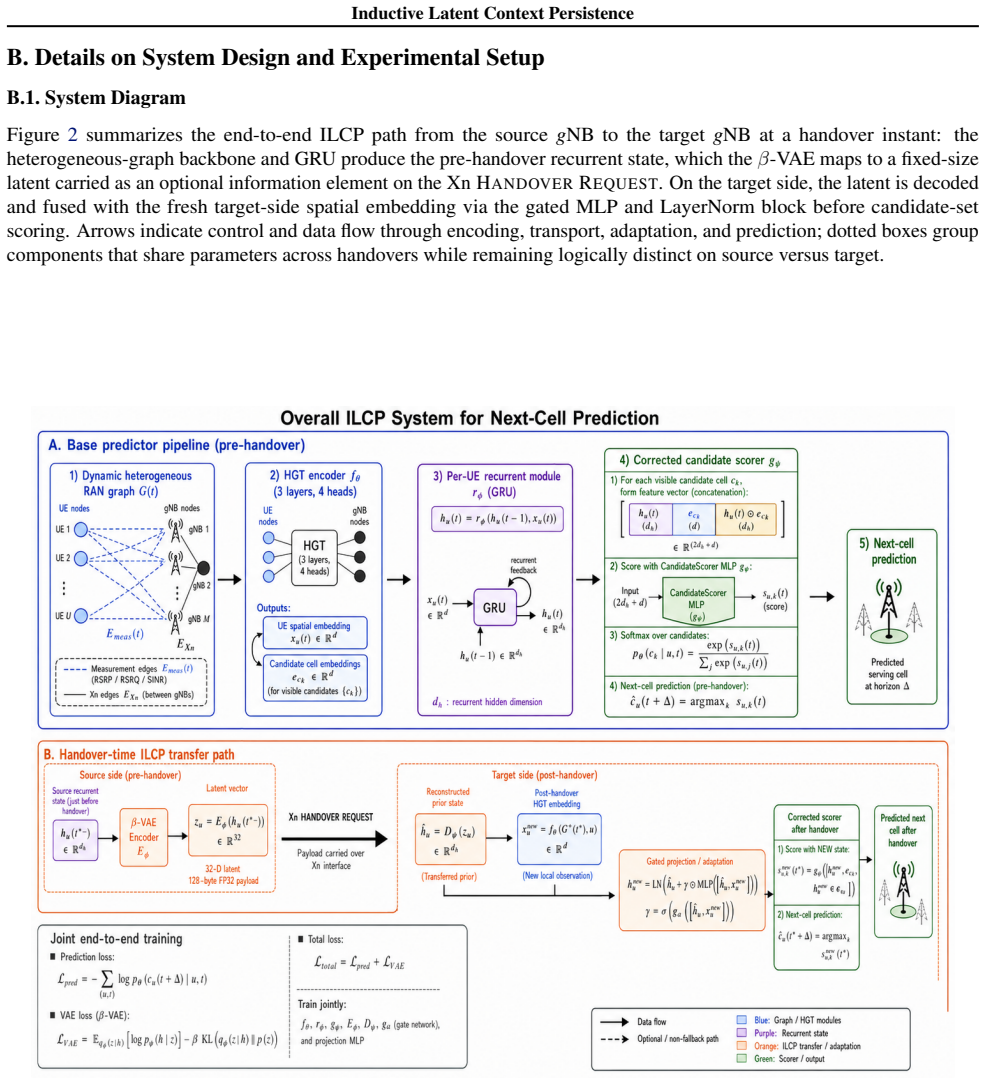
The authors model the radio access network as a dynamic heterogeneous graph with user equipment nodes, base station nodes, measurement edges, and Xn edges. They introduce Inductive Latent Context Persistence to compress the source recurrent state, transport it as a 128-byte payload on the 3GPP Xn interface, and adapt the compressed state at the target base station so that mobility history is retained rather than discarded at each handover.
What carries the argument
Inductive Latent Context Persistence (ILCP): a compression-and-adaptation step that carries the source recurrent state across the Xn interface inside a 128-byte payload so the target graph model can continue without cold-start reinitialization.
If this is right
- Ping-pong handovers drop to 0 percent while the no-transfer baseline shows 6.5 percent and a Transformer baseline shows 22.6 percent.
- Post-handover prediction accuracy rises by 5.1 percentage points on average, with peaks of 13.3 points in the first 250 milliseconds.
- End-to-end decision latency stays at 7.7 milliseconds at the 99th percentile on consumer hardware.
- Handover failure rates remain between 10 and 13 percent even when shadow fading, NLOS blockage, and SSB-burst sparsity are introduced.
- Rule-based A3/A5 decisions, which rely only on raw measurements, see handover failure climb from 1.1 percent to 57-65 percent under the same perturbations.
Where Pith is reading between the lines
- The same compression-and-transfer pattern could be applied to other recurrent components inside the network, such as traffic predictors or beam managers, to reduce reinitialization overhead in distributed 6G control loops.
- Because the payload is only 128 bytes, the method stays compatible with existing Xn capacity even when many users hand over simultaneously in dense urban cells.
- If the adaptation step proves stable across different graph architectures, operators could mix and match source and target model versions without forcing full state resets.
- The robustness numbers under measurement perturbations suggest that ILCP might also mitigate the effects of temporary sensor outages or calibration drift in real deployments.
Load-bearing premise
The source recurrent state can be compressed to 128 bytes and then successfully adapted at the target base station without losing the mobility patterns that matter for handover decisions.
What would settle it
A drive-test run in which the same model with the transferred 128-byte state produces the same post-handover accuracy and ping-pong rate as the identical model that discards the state at every handover.
Figures

read the original abstract
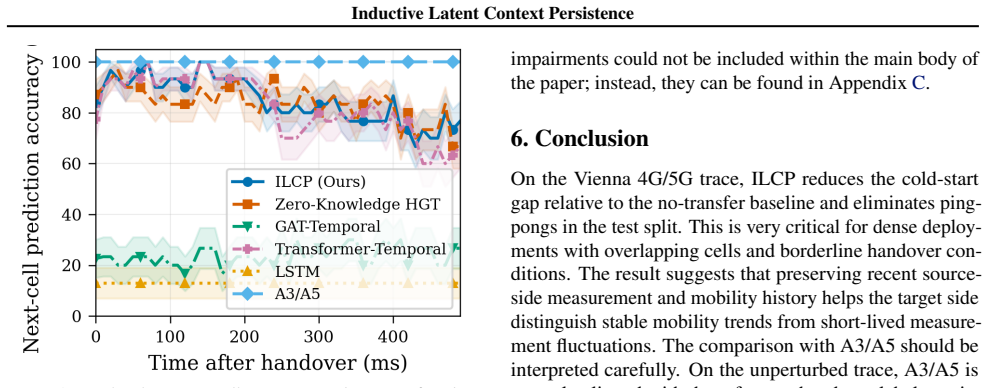
In modern radio access networks (RANs), rule-based handover (HO) decisions (e.g., A3/A5) depend on user equipment (UE) measurements only, so UEs at the same location can receive inconsistent HO outcomes. GNN-based methods improve HO KPIs using richer context than measurements alone. However, recurrent or graph models discard the per-UE recurrent state at HO and reinitialize at the target next-generation Node B (gNB), losing mobility history and forcing the target model to rebuild from post-HO measurements only. We address this post-HO cold start with Inductive Latent Context Persistence (ILCP), compressing the source recurrent state, transporting it on the 3GPP Xn as a 128-byte payload, and adapting it at the target gNB. We model the RAN as a dynamic heterogeneous graph over UE nodes, gNB nodes, measurement edges, and Xn edges. On a Vienna 4G/5G drive-test, ILCP achieves 0.0% ping-pong HOs versus 6.5% for an identical no-transfer baseline and 22.6% for a Transformer baseline; post-HO accuracy improves by +5.1 pp on average (peak +13.3 pp) in the 50-250 ms window. On one NVIDIA GTX 1080 (8 GB), ILCP runs end-to-end at 7.7 ms p99 per handover decision. Under perturbations (shadow fading, NLOS blockage, SSB-burst sparsity), robustly trained ILCP keeps handover failure (HOF) in the 10-13% range. Under the same fixed-reference-label setting, A3/A5 rises from 1.1% to 57-65% HOF when measurements are perturbed, exposing limits of measurement-only rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Inductive Latent Context Persistence (ILCP) to address the post-handover cold-start problem in GNN-based radio access network models. It compresses the source recurrent state into a 128-byte payload transferred over the 3GPP Xn interface and adapts it at the target gNB, modeling the RAN as a dynamic heterogeneous graph. On Vienna 4G/5G drive-test data, ILCP reports 0.0% ping-pong handovers (vs. 6.5% no-transfer and 22.6% Transformer baselines), +5.1 pp average post-HO accuracy gain (peak +13.3 pp) in the 50-250 ms window, 7.7 ms p99 inference on GTX 1080, and robustness under perturbations where rule-based A3/A5 degrades sharply.
Significance. If the central claims hold, the work would be significant for 6G RAN mobility management by enabling persistent per-UE context across handovers without full reinitialization, potentially lowering handover failures in dense deployments. Strengths include real-world drive-test evaluation with explicit baselines, concrete quantitative KPIs, reported runtime, and perturbation robustness tests that highlight limits of measurement-only rules.
major comments (3)
- [Abstract / ILCP description] Abstract and methods description of ILCP: the central claim that the 128-byte compressed recurrent state 'retains useful mobility history' without significant loss is load-bearing for the 0.0% ping-pong and +5.1 pp accuracy results, yet no details are provided on the compression technique (e.g., dimensionality reduction, autoencoder, or projection), adaptation procedure at the target gNB, or any information-theoretic analysis of retained context. This leaves open whether gains arise from the transfer itself or from the heterogeneous GNN architecture and training regime alone.
- [Abstract / Evaluation] Abstract and evaluation section: the reported improvements (0.0% vs 6.5% ping-pong; +5.1 pp accuracy) are presented without error bars, confidence intervals, or statistical significance tests (e.g., paired t-test or bootstrap p-values across drive-test runs or UE trajectories). Given the low number of implied events for ping-pong rates, this undermines confidence that the difference is not due to sampling variability or specific data splits.
- [Perturbation experiments] Evaluation under perturbations: while ILCP keeps HOF in 10-13%, the no-transfer baseline comparison does not include an ablation varying payload size (e.g., 64-byte vs 256-byte) or comparing to full-state transfer. Without this, it is impossible to confirm that the fixed 128-byte encoding is information-preserving rather than the gains stemming from other model components.
minor comments (3)
- [Abstract] The abstract introduces 'Inductive Latent Context Persistence (ILCP)' and the 128-byte payload without a concise one-sentence definition of the compression and adaptation steps before stating results.
- [Baselines] The Transformer baseline is described only as 'Transformer baseline' with no architecture details (layers, attention heads, input features) to allow reproduction or fair comparison.
- [Evaluation] No mention of data exclusion criteria, number of drive-test runs, or UE trajectory count, which affects reproducibility of the Vienna dataset results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / ILCP description] Abstract and methods description of ILCP: the central claim that the 128-byte compressed recurrent state 'retains useful mobility history' without significant loss is load-bearing for the 0.0% ping-pong and +5.1 pp accuracy results, yet no details are provided on the compression technique (e.g., dimensionality reduction, autoencoder, or projection), adaptation procedure at the target gNB, or any information-theoretic analysis of retained context. This leaves open whether gains arise from the transfer itself or from the heterogeneous GNN architecture and training regime alone.
Authors: We agree that explicit details on the compression and adaptation mechanisms are essential to substantiate the central claims. The ILCP compression employs a learned linear projection followed by quantization to produce the 128-byte payload, with target-side adaptation performed by a small feed-forward network that maps the received latent vector into the initial recurrent state of the target GNN. In the revised manuscript we will expand the Methods section with a precise algorithmic description of both steps, pseudocode for the transfer and adaptation, and an empirical information-retention analysis (reconstruction MSE on held-out states plus downstream accuracy sensitivity). These additions will isolate the contribution of context persistence from the underlying GNN architecture. revision: yes
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the reported improvements (0.0% vs 6.5% ping-pong; +5.1 pp accuracy) are presented without error bars, confidence intervals, or statistical significance tests (e.g., paired t-test or bootstrap p-values across drive-test runs or UE trajectories). Given the low number of implied events for ping-pong rates, this undermines confidence that the difference is not due to sampling variability or specific data splits.
Authors: We acknowledge the need for statistical rigor. Although the primary results derive from a single large-scale Vienna drive-test campaign, we will recompute all key KPIs with bootstrap confidence intervals (1,000 resamples over UE trajectories) and apply appropriate significance tests (McNemar’s test for accuracy, binomial tests for rare ping-pong events) in the revised Evaluation section. We will also report results stratified by trajectory segments to address potential data-split sensitivity. revision: yes
-
Referee: [Perturbation experiments] Evaluation under perturbations: while ILCP keeps HOF in 10-13%, the no-transfer baseline comparison does not include an ablation varying payload size (e.g., 64-byte vs 256-byte) or comparing to full-state transfer. Without this, it is impossible to confirm that the fixed 128-byte encoding is information-preserving rather than the gains stemming from other model components.
Authors: This observation is fair. The 128-byte size was chosen to respect practical 3GPP Xn signaling constraints for low-latency handovers. In the revision we will add a dedicated ablation subsection that evaluates ILCP performance at 64-byte, 128-byte, and 256-byte payloads under the same perturbation conditions, together with a brief theoretical comparison to full-state transfer (which incurs prohibitive bandwidth and latency). These results will directly demonstrate the information-efficiency of the chosen encoding. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent drive-test evaluations
full rationale
The paper's central claims rest on real-world Vienna 4G/5G drive-test results (0.0% ping-pong HOs vs. 6.5% no-transfer baseline and 22.6% Transformer baseline; +5.1 pp post-HO accuracy lift) obtained by direct comparison of the proposed ILCP method against explicit baselines. The modeling step (RAN as dynamic heterogeneous graph with UE/gNB nodes, measurement/Xn edges) and the 128-byte state compression/adaptation procedure are presented as engineering choices whose value is measured externally rather than derived from quantities defined in terms of themselves. No equations, fitted parameters, or self-citations are shown to reduce the reported KPIs to inputs by construction. The derivation chain is therefore self-contained against the stated empirical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- payload size for state transfer =
128 bytes
axioms (2)
- domain assumption The RAN can be modeled as a dynamic heterogeneous graph with UE nodes, gNB nodes, measurement edges, and Xn edges.
- domain assumption Recurrent states from the source gNB contain transferable mobility history that can be compressed and adapted at the target without critical loss.
invented entities (1)
-
Inductive Latent Context Persistence (ILCP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Network and Service Management , volume=
Trust and performance in future AI-enabled, open, multi-vendor network management automation , author=. IEEE Transactions on Network and Service Management , volume=. 2022 , publisher=
2022
-
[2]
IEEE Transactions on Network and Service Management , volume=
Toward control and coordination in cognitive autonomous networks , author=. IEEE Transactions on Network and Service Management , volume=. 2021 , publisher=
2021
-
[3]
2020 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS) , pages=
Game theoretic conflict resolution mechanism for cognitive autonomous networks , author=. 2020 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS) , pages=. 2020 , organization=
2020
-
[4]
Neurocomputing , volume=
A novel deep learning driven, low-cost mobility prediction approach for 5G cellular networks: The case of the Control/Data Separation Architecture (CDSA) , author=. Neurocomputing , volume=. 2019 , publisher=
2019
-
[5]
2017 IEEE 18th Wireless and Microwave Technology Conference (WAMICON) , pages =
Base station prediction and proactive mobility management in virtual cells using recurrent neural networks , author =. 2017 IEEE 18th Wireless and Microwave Technology Conference (WAMICON) , pages =
2017
-
[6]
Mobile Information Systems , volume=
Data-Driven Handover Optimization in Next Generation Mobile Communication Networks , author=. Mobile Information Systems , volume=. 2016 , publisher=
2016
-
[7]
Proceedings of The Web Conference 2020 (WWW) , pages =
Heterogeneous graph transformer , author =. Proceedings of The Web Conference 2020 (WWW) , pages =
2020
-
[8]
International Conference on Learning Representations (ICLR) , year =
Graph attention networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[9]
International Conference on Learning Representations (ICLR) , year =
Semi-supervised classification with graph convolutional networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Inductive representation learning on large graphs , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[11]
Neural Computation , volume =
Long short-term memory , author =. Neural Computation , volume =
-
[12]
Learning phrase representations using
Cho, Kyunghyun and van Merri. Learning phrase representations using. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2014
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention is all you need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[14]
and Welling, Max , booktitle =
Kingma, Diederik P. and Welling, Max , booktitle =. Auto-encoding variational
-
[15]
Higgins, Irina and Matthey, Loic and Pal, Arka and Burgess, Christopher and Glorot, Xavier and Botvinick, Matthew and Mohamed, Shakir and Lerchner, Alexander , booktitle =. beta-
-
[16]
NIPS Workshop on Bayesian Deep Learning , year =
Variational graph auto-encoders , author =. NIPS Workshop on Bayesian Deep Learning , year =
-
[17]
2015 IEEE Information Theory Workshop (ITW) , pages =
Deep learning and the information bottleneck principle , author =. 2015 IEEE Information Theory Workshop (ITW) , pages =
2015
-
[18]
Sun, Baochen and Saenko, Kate , booktitle =. Deep
-
[19]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
Unsupervised visual domain adaptation using subspace alignment , author =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
-
[20]
and Zoph, Barret and Gilmer, Justin and Lakshminarayanan, Balaji , booktitle =
Hendrycks, Dan and Mu, Norman and Cubuk, Ekin D. and Zoph, Barret and Gilmer, Justin and Lakshminarayanan, Balaji , booktitle =
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Unsupervised data augmentation for consistency training , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[22]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , year =
Virtual adversarial training: A regularization method for supervised and semi-supervised learning , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , year =
-
[23]
Artificial Intelligence and Statistics (AISTATS) , pages =
Communication-efficient learning of deep networks from decentralized data , author =. Artificial Intelligence and Statistics (AISTATS) , pages =
-
[24]
Foundations and Trends in Machine Learning , volume =
Advances and open problems in federated learning , author =. Foundations and Trends in Machine Learning , volume =
-
[25]
Proceedings of the National Academy of Sciences , volume =
Overcoming catastrophic forgetting in neural networks , author =. Proceedings of the National Academy of Sciences , volume =
-
[26]
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and others , booktitle =
-
[27]
, journal =
Fey, Matthias and Lenssen, Jan E. , journal =. Fast graph representation learning with
-
[28]
Sionna: An Open-Source Library for Next-Generation Physical Layer Research,
Sionna: An open-source library for next-generation physical layer research , author =. arXiv preprint arXiv:2203.11854 , year =
-
[29]
Data in Brief| Data Article Template , volume=
Drive-Test-Based LTE Handover Dataset for Cellular Mobility Studies in Urban Bangladesh , author=. Data in Brief| Data Article Template , volume=
-
[30]
McInnes, Leland and Healy, John and Melville, James , journal =
-
[31]
Monographs on statistics and applied probability , volume=
An introduction to the bootstrap , author=. Monographs on statistics and applied probability , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.