Recognition: unknown
Decouple before Integration: Test-time Synthesis of SFT and RLVR Task Vectors
Pith reviewed 2026-05-09 19:00 UTC · model grok-4.3
The pith
SFT and RLVR task vectors can be synthesized at test time to match joint-training performance without parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Task vector analysis reveals three properties behind integration failures: a 30-fold magnitude disparity, 45-fold sign interference, and heterogeneous module-wise updates. These properties show SFT and RLVR modify partly complementary components. Therefore, independent training followed by test-time synthesis via selective sparsification with norm-preserving rescaling and Bayesian optimization of combination coefficients recovers joint-training performance without updating any parameters.
What carries the argument
Decoupled test-time synthesis of task vectors using selective sparsification with norm-preserving rescaling and Bayesian optimization to select coefficients on the Pareto frontier of consistency and perplexity.
If this is right
- Matches or exceeds the performance of training-based SFT-RLVR integration methods across multiple mathematical reasoning benchmarks.
- Incurs only about 3 percent of the computational cost of training-based integration methods.
- Surpasses state-of-the-art models when applied to stronger post-trained checkpoints.
- Generalizes to out-of-domain benchmarks without requiring any re-tuning.
Where Pith is reading between the lines
- Task vectors from different post-training regimes may behave as modular components that can be mixed at deployment rather than during training.
- The same decoupling approach could apply to other pairs of conflicting objectives, such as instruction tuning combined with preference optimization.
- Reducing reliance on large joint training runs might allow more efficient exploration of many specialized checkpoints before final combination.
Load-bearing premise
The three structural properties of the task vectors mean that SFT and RLVR affect sufficiently complementary parts of the model for their combination through sparsified addition to recover joint-training results.
What would settle it
A side-by-side evaluation where the test-time synthesized model performs worse than a jointly trained SFT-RLVR model on the mathematical reasoning benchmarks, or fails to match performance on out-of-domain tests, would show the claim is incorrect.
Figures



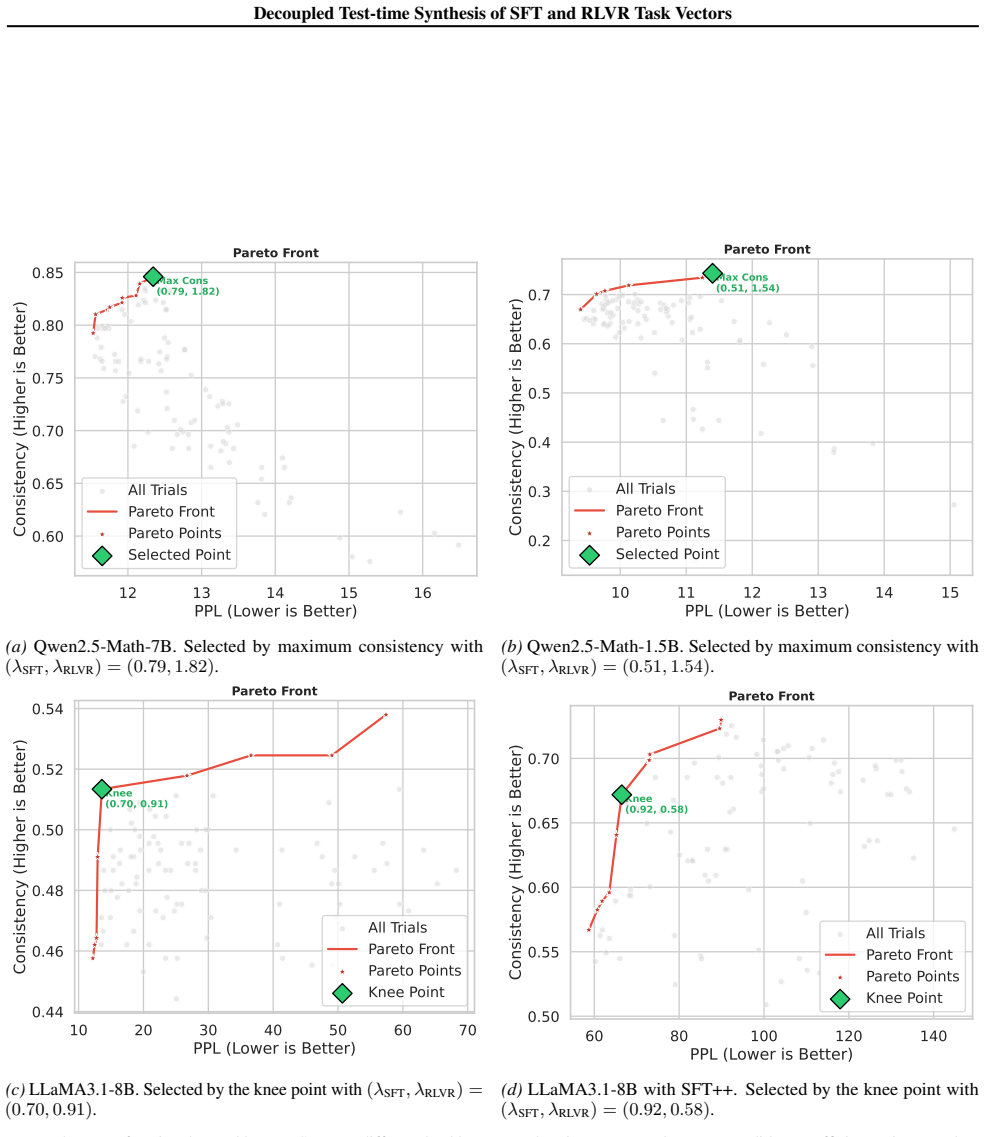
read the original abstract
SFT and RLVR represent two fundamental yet distinct paradigms for LLM post-training, each excelling in distinct dimensions. SFT expands knowledge breadth while RLVR enhances reasoning depth. Yet integrating these complementary strengths remains a formidable challenge. Sequential training can cause catastrophic forgetting, and joint optimization often suffers from severe gradient conflicts. We analyze SFT and RLVR through the lens of task vectors and reveal three structural properties behind these failures: a 30* magnitude disparity, 45* sign interference, and heterogeneous module-wise update distributions. These findings show SFT and RLVR are difficult to integrate directly, but they also suggest that the two paradigms modify partly complementary components of the model. Motivated by these observations, we propose Decoupled Test-time Synthesis (DoTS), a post-hoc framework allows SFT and RLVR checkpoints to be trained independently and synthesizes their capabilities only at inference time via task vector arithmetic, without updating model parameters. To reduce interference, DOTS applies selective sparsification with norm-preserving rescaling. It then uses Bayesian optimization on a small set of unlabeled queries to search for combination coefficients on the Pareto frontier of consistency and perplexity. Empirically, \ours matches or exceeds the performance of training-based SFT--RLVR integration methods across multiple mathematical reasoning benchmarks, incurring only $\sim$3\% of the computational cost. When applied to stronger post-trained checkpoints, DOTS surpasses SOTA models and generalizes to out-of-domain benchmarks without re-tuning. Code is available at https://github.com/chaohaoyuan/DoTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Decoupled Test-time Synthesis (DoTS), a framework for integrating SFT and RLVR capabilities in LLMs at test time without parameter updates. Through analysis of task vectors, it identifies three structural properties—30× magnitude disparity, 45× sign interference, and heterogeneous module-wise updates—that hinder direct integration. DoTS applies selective sparsification with norm-preserving rescaling to task vectors and uses Bayesian optimization on a small set of unlabeled queries to determine combination coefficients optimizing consistency and perplexity. The paper claims that DoTS matches or exceeds training-based integration methods on mathematical reasoning benchmarks at approximately 3% of the computational cost, surpasses SOTA on stronger checkpoints, and generalizes to out-of-domain tasks.
Significance. If the empirical claims hold, the work provides a low-cost, post-hoc alternative to joint training or sequential fine-tuning for combining the breadth of SFT with the depth of RLVR. The release of code at the provided GitHub link is a strength that facilitates reproducibility and further investigation. This approach could have practical implications for efficient LLM post-training pipelines by avoiding catastrophic forgetting and gradient conflicts.
major comments (2)
- [Task vector analysis and motivation] The inference that the three structural properties (magnitude disparity, sign interference, heterogeneous updates) imply complementary components modifiable via sparsified addition is load-bearing for the central claim. However, no ablation is presented that isolates the effect of sparsification and rescaling from the Bayesian optimization step (e.g., comparing direct addition of full task vectors using the same coefficient search procedure). Without this control, it remains possible that the performance gains are primarily driven by the external Bayesian search rather than mitigation of the identified interferences.
- [Empirical evaluation] The reported benchmark improvements and ~3% cost claim lack error bars, multiple runs, or statistical tests. Additionally, details on the choice of sparsification threshold, the specific unlabeled queries used for Bayesian optimization, and controls for query selection bias are not provided, which undermines assessment of the robustness of the central empirical result.
minor comments (2)
- [Abstract] The abstract mentions '∼3% of the computational cost' but does not specify the baseline computation being compared (e.g., full joint training FLOPs).
- [Introduction] The use of 'RLVR' should be defined at first use if it is not standard (presumably Reinforcement Learning with Verifiable Rewards).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the motivation from task vector analysis and the robustness of the empirical results. We address each major comment below and will revise the manuscript to incorporate additional ablations, statistical details, and implementation clarifications.
read point-by-point responses
-
Referee: [Task vector analysis and motivation] The inference that the three structural properties (magnitude disparity, sign interference, heterogeneous updates) imply complementary components modifiable via sparsified addition is load-bearing for the central claim. However, no ablation is presented that isolates the effect of sparsification and rescaling from the Bayesian optimization step (e.g., comparing direct addition of full task vectors using the same coefficient search procedure). Without this control, it remains possible that the performance gains are primarily driven by the external Bayesian search rather than mitigation of the identified interferences.
Authors: We agree that isolating the contribution of sparsification and rescaling is important to substantiate the motivation. The three properties were identified via direct comparison of SFT and RLVR task vectors (Section 3), demonstrating that full-vector addition incurs interference. Sparsification with norm-preserving rescaling is intended to retain complementary updates while attenuating conflicts. To address the concern directly, we will add an ablation in the revised manuscript that applies the identical Bayesian optimization procedure to (i) full task vectors, (ii) sparsified vectors without rescaling, and (iii) the complete DoTS pipeline. This control will quantify the incremental benefit of the sparsification step beyond coefficient search alone. revision: yes
-
Referee: [Empirical evaluation] The reported benchmark improvements and ~3% cost claim lack error bars, multiple runs, or statistical tests. Additionally, details on the choice of sparsification threshold, the specific unlabeled queries used for Bayesian optimization, and controls for query selection bias are not provided, which undermines assessment of the robustness of the central empirical result.
Authors: We acknowledge that the current presentation lacks sufficient statistical detail and implementation transparency. In the revision we will (1) report all main results as means and standard deviations over five independent runs of Bayesian optimization with varied random seeds, including error bars and basic statistical comparisons; (2) explicitly document the sparsification threshold (top-5% norm components selected to align with the observed 30× magnitude disparity, with a sensitivity plot added); (3) specify the unlabeled query set (50 held-out GSM8K-style problems with the exact prompt template provided in the appendix); and (4) include a control varying the query set to demonstrate stability against selection bias. These additions will be placed in the main text and appendix. revision: yes
Circularity Check
No significant circularity; empirical validation remains external to inputs
full rationale
The paper observes three task-vector properties (magnitude disparity, sign interference, module heterogeneity) from SFT/RLVR checkpoints, uses them motivationally to justify selective sparsification plus norm-preserving rescaling, then applies Bayesian optimization over combination coefficients on a small unlabeled query set using consistency/perplexity objectives. Performance is subsequently measured on separate mathematical reasoning benchmarks. No equation or claim reduces the reported benchmark gains to the optimization inputs by construction; the coefficient search is an external, falsifiable procedure whose outputs are tested out-of-domain without re-tuning. No self-definitional loops, fitted-input-as-prediction, or load-bearing self-citations appear in the derivation. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- sparsification ratio
- Bayesian objective weights
axioms (1)
- domain assumption SFT and RLVR produce task vectors whose linear combination can recover joint-training performance when interference is reduced by sparsification.
Reference graph
Works this paper leans on
-
[1]
Hugging Face repository , volume=
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author=. Hugging Face repository , volume=
-
[2]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[4]
The Eleventh International Conference on Learning Representations , year=
Editing models with task arithmetic , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
When Scaling Meets
Biao Zhang and Zhongtao Liu and Colin Cherry and Orhan Firat , booktitle=. When Scaling Meets. 2024 , url=
2024
-
[6]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[7]
2025 , url=
Tianzhe Chu and Yuexiang Zhai and Jihan Yang and Shengbang Tong and Saining Xie and Dale Schuurmans and Quoc V Le and Sergey Levine and Yi Ma , booktitle=. 2025 , url=
2025
-
[8]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review arXiv
-
[12]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Learning to Reason under Off-Policy Guidance , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[13]
2025 , publisher=
Open r1: A fully open reproduction of deepseek-r1 , author=. 2025 , publisher=
2025
-
[14]
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions , author=. arXiv preprint arXiv:2506.07527 , year=
-
[15]
2023 , url=
Prateek Yadav and Derek Tam and Leshem Choshen and Colin Raffel and Mohit Bansal , booktitle=. 2023 , url=
2023
-
[16]
On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
On the generalization of sft: A reinforcement learning perspective with reward rectification , author=. arXiv preprint arXiv:2508.05629 , year=
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Efficient Model Editing with Task-Localized Sparse Fine-tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
Weihao Zeng and Yuzhen Huang and Qian Liu and Wei Liu and Keqing He and Zejun MA and Junxian He , booktitle=. Simple. 2025 , url=
2025
-
[19]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[20]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
work page internal anchor Pith review arXiv
-
[21]
Conference on Language Modeling (COLM) , year=
Understanding r1-zero-like training: A critical perspective , author=. Conference on Language Modeling (COLM) , year=
-
[22]
Supervised fine tuning on curated data is reinforcement learning (and can be improved), 2025
Supervised fine tuning on curated data is reinforcement learning (and can be improved) , author=. arXiv preprint arXiv:2507.12856 , year=
-
[23]
The Thirteenth International Conference on Learning Representations , year=
When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
-
[25]
Right Question is Already Half the Answer: Fully Unsupervised
Qingyang Zhang and Haitao Wu and Changqing Zhang and Peilin Zhao and Yatao Bian , booktitle=. Right Question is Already Half the Answer: Fully Unsupervised. 2025 , url=
2025
-
[26]
Visual generation without guidance.Forty-second international conference on machine learning, 2025a
Bridging supervised learning and reinforcement learning in math reasoning , author=. arXiv preprint arXiv:2505.18116 , year=
-
[27]
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning , author=. arXiv preprint arXiv:2506.19767 , year=
-
[28]
Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori , booktitle=
-
[29]
Transactions on Machine Learning Research , issn=
Localize-and-Stitch: Efficient Model Merging via Sparse Task Arithmetic , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[30]
European Conference on Computer Vision , pages=
Model breadcrumbs: Scaling multi-task model merging with sparse masks , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[31]
PopulAtion Parameter Averaging (
Alexia Jolicoeur-Martineau and Emy Gervais and Kilian FATRAS and Yan Zhang and Simon Lacoste-Julien , journal=. PopulAtion Parameter Averaging (. 2024 , url=
2024
-
[32]
Advances in Neural Information Processing Systems , volume=
Model fusion via optimal transport , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in neural information processing systems , volume=
Algorithms for hyper-parameter optimization , author=. Advances in neural information processing systems , volume=
-
[34]
2025 , url=
Xuechen Zhang and Zijian Huang and Yingcong Li and Chenshun Ni and Jiasi Chen and Samet Oymak , booktitle=. 2025 , url=
2025
-
[35]
Hammer: GRPO Amplifies Existing Capabilities, SFT Replaces Them , author=
Scalpel vs. Hammer: GRPO Amplifies Existing Capabilities, SFT Replaces Them , author=. arXiv preprint arXiv:2507.10616 , year=
-
[36]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Forty-first International Conference on Machine Learning , year=
Language models are super mario: Absorbing abilities from homologous models as a free lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[38]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[39]
The Twelfth International Conference on Learning Representations , year=
The False Promise of Imitating Proprietary Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2511.08567 , year=
The path not taken: Rlvr provably learns off the principals , author=. arXiv preprint arXiv:2511.08567 , year=
-
[44]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[45]
arXiv preprint arXiv:2509.21128 , year=
Rl squeezes, sft expands: A comparative study of reasoning llms , author=. arXiv preprint arXiv:2509.21128 , year=
-
[46]
Thought-augmented policy optimization: Bridging external guidance and internal capabilities , author=. arXiv preprint arXiv:2505.15692 , volume=
-
[47]
Forty-second International Conference on Machine Learning , year=
Whoever Started the interference Should End It: Guiding Data-Free Model Merging via Task Vectors , author=. Forty-second International Conference on Machine Learning , year=
-
[48]
The Twelfth International Conference on Learning Representations , year=
AdaMerging: Adaptive Model Merging for Multi-Task Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[49]
ACM Computing Surveys , year=
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications, and Opportunities , author=. ACM Computing Surveys , year=
-
[50]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Mitigating the alignment tax of rlhf , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[51]
arXiv preprint arXiv:2406.16768 , year=
Warp: On the benefits of weight averaged rewarded policies , author=. arXiv preprint arXiv:2406.16768 , year=
-
[52]
2024 , url=
Alexandre Rame and Nino Vieillard and Leonard Hussenot and Robert Dadashi and Geoffrey Cideron and Olivier Bachem and Johan Ferret , booktitle=. 2024 , url=
2024
-
[53]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[55]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[56]
Wong and Yu Cheng , booktitle=
Runzhe Zhan and Yafu Li and Zhi Wang and Xiaoye Qu and Dongrui Liu and Jing Shao and Derek F. Wong and Yu Cheng , booktitle=. Ex. 2026 , url=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.