Recognition: unknown
A Replicability Study of XTR
Pith reviewed 2026-05-09 18:23 UTC · model grok-4.3
The pith
XTR training flattens ColBERT token scores to yield more efficient IVF retrieval in engines like PLAID and WARP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
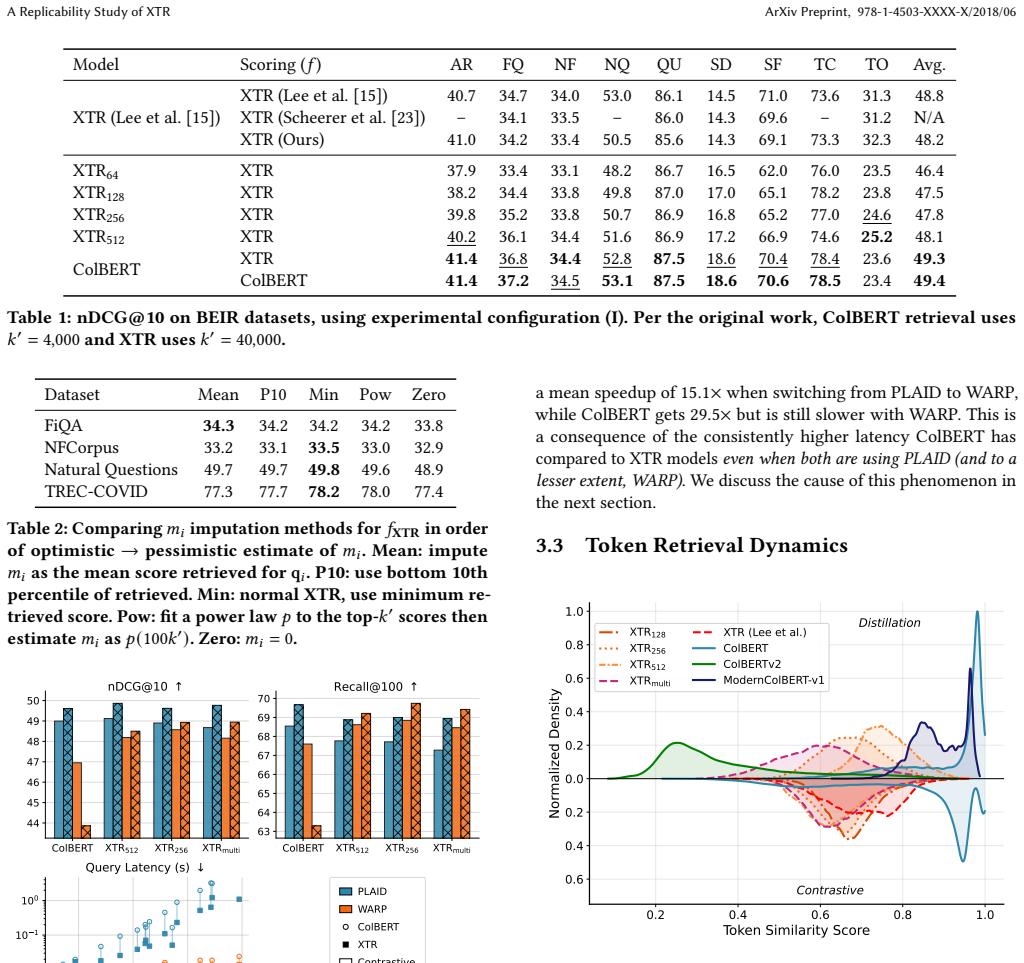
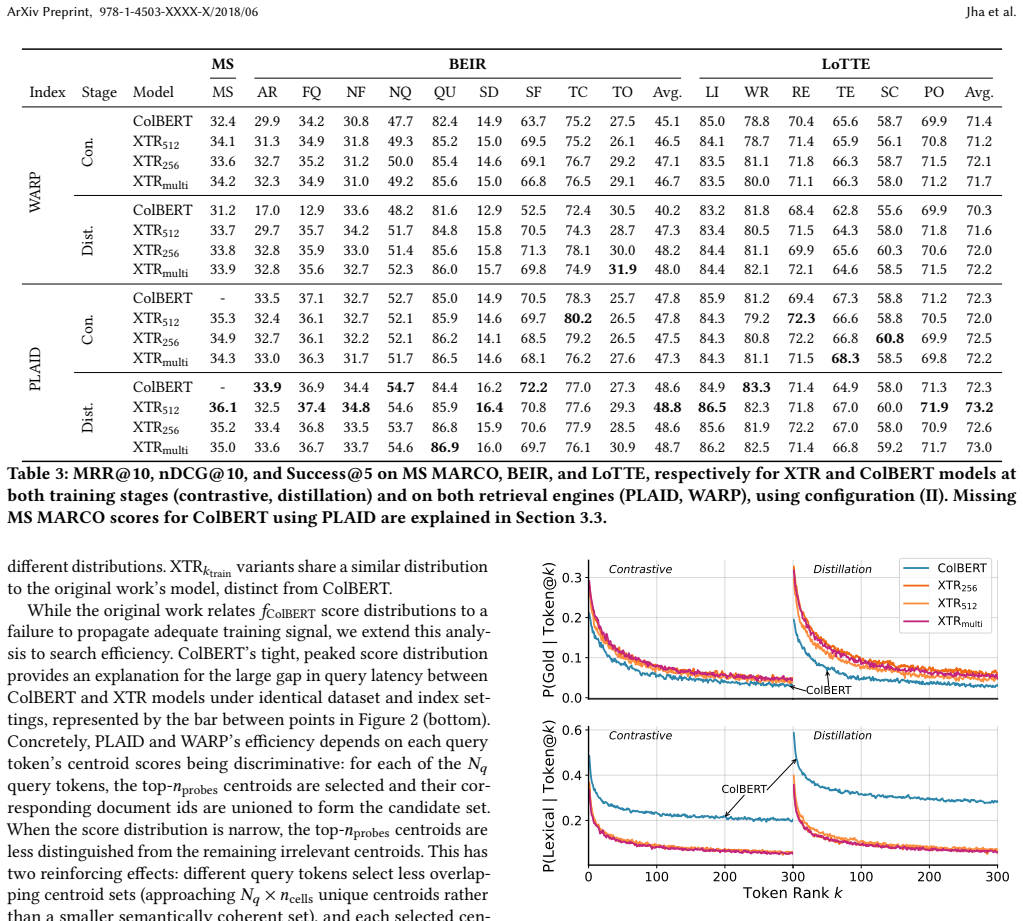
XTR's modified training objective produces a flatter distribution of token similarity scores than standard ColBERT training. These flatter scores translate into more discriminative centroid scores, which improve the efficiency of inverted-file (IVF) candidate retrieval in systems such as PLAID and WARP. The efficiency benefit therefore applies to any IVF-based deployment setting rather than being limited to the low-k' regime originally examined.
What carries the argument
The modified training objective that flattens ColBERT's characteristically peaked token score distribution and thereby improves centroid discriminativeness for IVF indexes.
If this is right
- XTR training produces more efficient candidate retrieval under PLAID and WARP engines.
- The utility of XTR extends to any deployment that relies on IVF-based approximate retrieval.
- Practitioners obtain direct guidance on when to apply XTR training as their multi-vector retriever.
Where Pith is reading between the lines
- The inability to replicate effectiveness gains may reflect subtle differences in training dynamics or evaluation protocols.
- Flattening token score distributions may serve as a general lever for improving efficiency across other late-interaction retrieval models.
- Testing the same training change inside additional approximate nearest-neighbor frameworks would reveal how broadly the efficiency gain applies.
Load-bearing premise
The replication of both XTR and ColBERT was performed without implementation differences that could explain the absence of effectiveness gains.
What would settle it
Re-measuring token score distributions on the original XTR checkpoint and re-running end-to-end effectiveness comparisons with the exact original code, data splits, and hyperparameters.
Figures

read the original abstract
The XTR (conteXtual Token Retrieval) algorithm is a modification to ColBERT retrieval that avoids the costly step of fully gathering and reranking the candidates' embeddings by imputing their missing similarity scores from the initial token retrieval step. The original work proposes a modified training objective as necessary for effective XTR retrieval, arguing that standard ColBERT token scoring is unsuitable for imputation. In this paper, we replicate both the XTR retrieval algorithm and its modified training objective, and extend the evaluation to knowledge-distillation (KD) training and efficient retrieval engines (PLAID and WARP). We confirm the token-level matching characteristics claimed in the original work, but fail to replicate XTR's overall effectiveness advantage over ColBERT under a controlled comparison. We further show that XTR's training modification has a concrete mechanistic consequence for modern retrieval engines: by flattening ColBERT's characteristically peaked token score distribution, XTR training yields more discriminative centroid scores and thus more efficient IVF-based retrieval under PLAID and WARP. The utility of XTR training is therefore not limited to the low-$k'$ regime originally studied, but extends to any deployment setting where IVF-based engines are used. These findings offer practitioners concrete guidance on how and when to use XTR as their multi-vector retriever.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a replicability study of the XTR algorithm for contextual token retrieval. It confirms the claimed token-level properties of XTR but fails to replicate its effectiveness gains over ColBERT under controlled conditions. The study extends the original evaluation to knowledge distillation training and efficient retrieval engines such as PLAID and WARP. It identifies a mechanistic effect where XTR training flattens ColBERT's peaked token score distribution, yielding more discriminative centroid scores and improved efficiency in IVF-based retrieval.
Significance. If the findings hold, this work has significant implications for the deployment of multi-vector retrieval models. The failure to replicate effectiveness serves as an important cautionary result, while the demonstrated efficiency benefits in modern engines like PLAID and WARP broaden the practical value of the XTR training modification. This offers practitioners guidance on when to adopt XTR and highlights how training objectives influence index efficiency, contributing to more informed design choices in information retrieval systems.
major comments (1)
- [§4.3] §4.3 (efficiency analysis): The central mechanistic claim that XTR training produces more discriminative centroid scores via flattening of the token score distribution is supported only by correlational evidence (distribution plots and end-to-end metrics). No ablation is presented to isolate this effect from other changes induced by the XTR objective, such as modifications to negative sampling or loss weighting. This is load-bearing for the extension of XTR's utility to general IVF-based settings.
minor comments (3)
- [Abstract] Abstract: The phrase 'low-$k'$ regime' is used without a brief definition or reference to the original paper's k' parameter, which could hinder accessibility for readers new to the topic.
- [§3.2] §3.2: The experimental setup description would benefit from more explicit details on how implementation differences were minimized between the replicated ColBERT and XTR models to strengthen the controlled comparison claim.
- [Figure 4] Figure 4: The figure legends should more clearly distinguish between the different training regimes and retrieval engines for easier interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our replicability study. We appreciate the acknowledgment of both the cautionary replication result and the practical efficiency implications for modern IVF engines. We respond to the single major comment below.
read point-by-point responses
-
Referee: [§4.3] §4.3 (efficiency analysis): The central mechanistic claim that XTR training produces more discriminative centroid scores via flattening of the token score distribution is supported only by correlational evidence (distribution plots and end-to-end metrics). No ablation is presented to isolate this effect from other changes induced by the XTR objective, such as modifications to negative sampling or loss weighting. This is load-bearing for the extension of XTR's utility to general IVF-based settings.
Authors: We agree that the support for the proposed mechanism is correlational: the manuscript shows that XTR training produces flatter token-score distributions than standard ColBERT training, that these flatter distributions yield more discriminative centroids, and that the resulting indexes are more efficient under PLAID and WARP. Because the XTR objective also alters negative sampling and loss weighting, we cannot claim to have isolated flattening as the sole causal factor. In a replicability study our focus was on verifying the original token-level claims and measuring end-to-end efficiency rather than on exhaustive ablation of the training recipe. We have added a short paragraph in the revised §4.3 that explicitly labels the evidence as correlational and states that targeted ablations (e.g., loss-component-only variants) would be required to strengthen the causal link. We nevertheless maintain that the observed distributional change is a direct, reproducible consequence of the XTR objective and supplies a plausible explanation for the efficiency gains that hold across the engines we tested. revision: partial
Circularity Check
No significant circularity: purely empirical replication study
full rationale
This paper is a replicability and extension study of the XTR algorithm. Its claims rest entirely on experimental outcomes, including token-level matching characteristics, effectiveness metrics under controlled comparisons, distribution plots of token scores, and retrieval efficiency results under PLAID and WARP. No mathematical derivations, first-principles predictions, or equations are presented that could reduce to fitted parameters or inputs by construction. The mechanistic observations about score distribution flattening are supported by side-by-side empirical data rather than any self-definitional, fitted-input, or self-citation load-bearing steps. The analysis is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior work in a circular manner.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions underlying IR metrics such as recall and nDCG for effectiveness comparison.
Reference graph
Works this paper leans on
-
[1]
Riyaz Ahmad Bhat and Jaydeep Sen. 2025. XTR meets ColBERTv2: Adding ColBERTv2 Optimizations to XTR. InProceedings of the 31st International Con- ference on Computational Linguistics, COLING 2025 - Industry Track, Abu Dhabi, UAE, January 19-24, 2025, Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, Steven Schockaert, Karee...
2025
-
[2]
Sebastian Bruch, Franco Maria Nardini, Cosimo Rulli, and Rossano Venturini
-
[3]
Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). ACM, 152–162. doi:10.1145/3626772.3657769
-
[4]
Antoine Chaffin, Luca Arnaboldi, Amélie Chatelain, and Florent Krzakala
-
[5]
arXiv:2602.16609 [cs.CL] https://arxiv.org/abs/2602.16609
ColBERT-Zero: To Pre-train Or Not To Pre-train ColBERT models. arXiv:2602.16609 [cs.CL] https://arxiv.org/abs/2602.16609
-
[6]
Antoine Chaffin and Raphaël Sourty. 2025. PyLate: Flexible Training and Re- trieval for Late Interaction Models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM 2025, Seoul, Repub- lic of Korea, November 10-14, 2025, Meeyoung Cha, Chanyoung Park, Noseong Park, Carl Yang, Senjuti Basu Roy, Jessie Li, Jaa...
- [7]
- [8]
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy...
2019
-
[10]
Shuai Ding and Torsten Suel. 2011. Faster top-k document retrieval using block- max indexes. InProceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval(Beijing, China)(SIGIR ’11). Association for Computing Machinery, New York, NY, USA, 993–1002. doi:10. 1145/2009916.2010048
-
[11]
Yan Fang, Jingtao Zhan, Yiqun Liu, Jiaxin Mao, Min Zhang, and Shaoping Ma. 2022. Joint Optimization of Multi-vector Representation with Product Quantization. InNatural Language Processing and Chinese Computing: 11th CCF International Conference, NLPCC 2022, Guilin, China, September 24–25, 2022, Proceedings, Part I (Guilin, China). Springer-Verlag, Berlin,...
-
[12]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, Canada)(SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 2288–2292. doi:1...
-
[13]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic ArXiv Preprint, 978-1-4503-XXXX-X/2018/06 Jha et al. Vector Quantization. InInternational Conference on Machine Learning. https: //arxiv.org/abs/1908.10396
-
[14]
Rohan Jha, Bo Wang, Michael Günther, Georgios Mastrapas, Saba Sturua, Isabelle Mohr, Andreas Koukounas, Mohammad Kalim Akram, Nan Wang, and Han Xiao. 2024. Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever. InProceedings of the Fourth Workshop on Multilingual Representation Learning (MRL 2024), Jonne Sälevä and Abraham Owodunni (E...
-
[15]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 6769–6781. doi:10.18653/v1/...
-
[16]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, China)(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 39–48. doi:10.1145/3...
-
[17]
Jinhyuk Lee, Zhuyun Dai, Sai Meher Karthik Duddu, Tao Lei, Iftekhar Naim, Ming-Wei Chang, and Vincent Zhao. 2023. Rethinking the Role of Token Retrieval in Multi-Vector Retrieval. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 15384–15405. h...
2023
-
[18]
Sean MacAvaney, Antonio Mallia, and Nicola Tonellotto. 2025. Efficient Constant- Space Multi-vector Retrieval. InAdvances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6–10, 2025, Proceedings, Part III(Lucca, Italy). Springer-Verlag, Berlin, Heidelberg, 237–245. doi:10.1007/978-3-031-88714-7_22
-
[19]
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (April 2020), 824–836. doi:10.1109/ TPAMI.2018.2889473
-
[20]
2025.W ARP: The Multi-Vector Search Engine To Rule Them All
Pau Montserrat. 2025.W ARP: The Multi-Vector Search Engine To Rule Them All. https://github.com/pau-mensa/xtr-warp-rs
2025
-
[21]
Rodrigo Nogueira and Kyunghyun Cho. 2020. Passage Re-ranking with BERT. arXiv:1901.04085 [cs.IR] https://arxiv.org/abs/1901.04085
work page internal anchor Pith review arXiv 2020
-
[22]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/1908.10084
work page internal anchor Pith review arXiv 2019
-
[23]
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. 2022. PLAID: An Efficient Engine for Late Interaction Retrieval. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (Atlanta, GA, USA)(CIKM ’22). Association for Computing Machinery, New York, NY, USA, 1747–1756. doi:10.1145/3511808.3557325
-
[24]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Marine Carpuat, Marie-Catherine de Marn...
2022
-
[25]
doi:10.18653/v1/2022.naacl-main.272
-
[26]
Jan Luca Scheerer, Matei Zaharia, Christopher Potts, Gustavo Alonso, and Omar Khattab. 2025. WARP: An Efficient Engine for Multi-Vector Retrieval. InProceed- ings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 2504–2512. d...
-
[27]
Raphaël Sourty. 2025. FastPlaid: A High-Performance Engine for Multi-Vector Search. https://github.com/lightonai/fast-plaid
2025
- [28]
-
[29]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). https://openreview. net/forum?id=wCu6T5xFjeJ
2021
-
[30]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2019. Representation Learning with Contrastive Predictive Coding. arXiv:1807.03748 [cs.LG] https://arxiv.org/ abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv:2309.07597 [cs.CL]
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.