Recognition: unknown
UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors
Pith reviewed 2026-05-09 19:59 UTC · model grok-4.3
The pith
A single video diffusion model can handle multiple pixel-aligned tasks like intrinsic decomposition and alpha matting by randomly assigning modalities as conditions or targets while preserving original priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
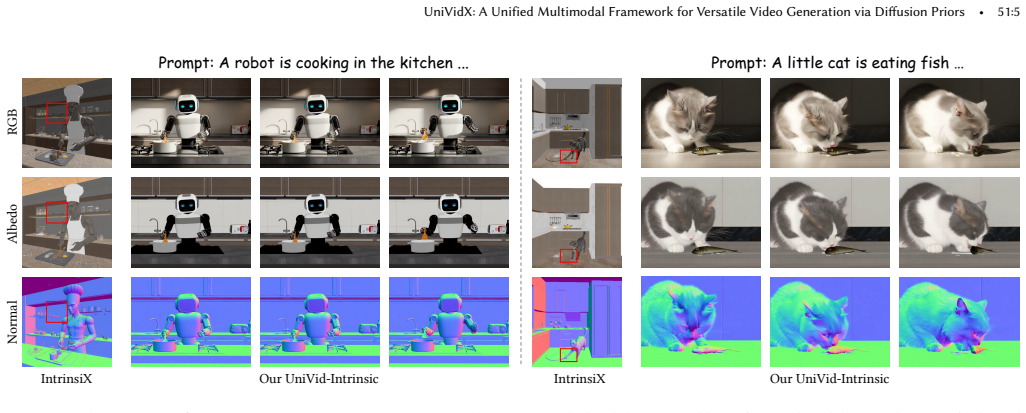
UniVidX formulates pixel-aligned tasks as conditional generation in a shared multimodal space, adapts to modality-specific distributions while preserving the backbone's native priors, and promotes cross-modal consistency during synthesis. It is built on three key designs: Stochastic Condition Masking randomly partitions modalities into clean conditions and noisy targets during training, enabling omni-directional conditional generation instead of fixed mappings; Decoupled Gated LoRA introduces per-modality LoRAs that are activated when a modality serves as the generation target, preserving the strong priors of the VDM; and Cross-Modal Self-Attention shares keys and values across modalities.
What carries the argument
Stochastic Condition Masking randomly partitions modalities into clean conditions and noisy targets; Decoupled Gated LoRA activates per-modality adapters only when the modality is the generation target; Cross-Modal Self-Attention shares keys and values across modalities while using modality-specific queries to enable information exchange and alignment.
If this is right
- The same trained model supports arbitrary input-output mappings across modalities without requiring new training runs.
- Cross-modal information exchange produces more consistent results when multiple related modalities are generated together.
- Strong performance is retained on in-the-wild videos despite using training sets smaller than 1,000 examples.
- The approach matches the accuracy of specialized state-of-the-art models on individual tasks such as intrinsic map prediction and alpha layer separation.
Where Pith is reading between the lines
- The same adapter-based approach could be extended to additional modalities such as depth or optical flow by introducing new per-modality LoRAs.
- Preserving the base diffusion priors may lower the data volume needed for future video-related conditional tasks in general.
- Omni-directional generation could enable iterative pipelines in which the output of one modality task is immediately reused as input for another within the same model.
Load-bearing premise
That the three designs of stochastic masking, gated per-modality adapters, and cross-modal attention together preserve the original video diffusion model's strong generative priors while still allowing effective cross-modal information exchange and flexible conditional generation.
What would settle it
Training the unified model on the same small dataset and observing that it produces markedly worse outputs than separately trained task-specific models on any single task, or that generated outputs become inconsistent when modalities are interchanged.
Figures
















read the original abstract
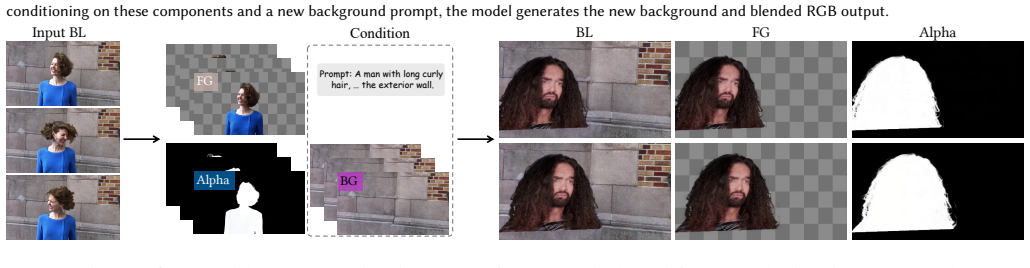
Recent progress has shown that video diffusion models (VDMs) can be repurposed for diverse multimodal graphics tasks. However, existing methods often train separate models for each problem setting, which fixes the input-output mapping and limits the modeling of correlations across modalities. We present UniVidX, a unified multimodal framework that leverages VDM priors for versatile video generation. UniVidX formulates pixel-aligned tasks as conditional generation in a shared multimodal space, adapts to modality-specific distributions while preserving the backbone's native priors, and promotes cross-modal consistency during synthesis. It is built on three key designs. Stochastic Condition Masking (SCM) randomly partitions modalities into clean conditions and noisy targets during training, enabling omni-directional conditional generation instead of fixed mappings. Decoupled Gated LoRA (DGL) introduces per-modality LoRAs that are activated when a modality serves as the generation target, preserving the strong priors of the VDM. Cross-Modal Self-Attention (CMSA) shares keys and values across modalities while keeping modality-specific queries, facilitating information exchange and inter-modal alignment. We instantiate UniVidX in two domains: UniVid-Intrinsic, for RGB videos and intrinsic maps including albedo, irradiance, and normal; and UniVid-Alpha, for blended RGB videos and their constituent RGBA layers. Experiments show that both models achieve performance competitive with state-of-the-art methods across distinct tasks and generalize robustly to in-the-wild scenarios, even when trained on fewer than 1,000 videos. Project page: https://houyuanchen111.github.io/UniVidX.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
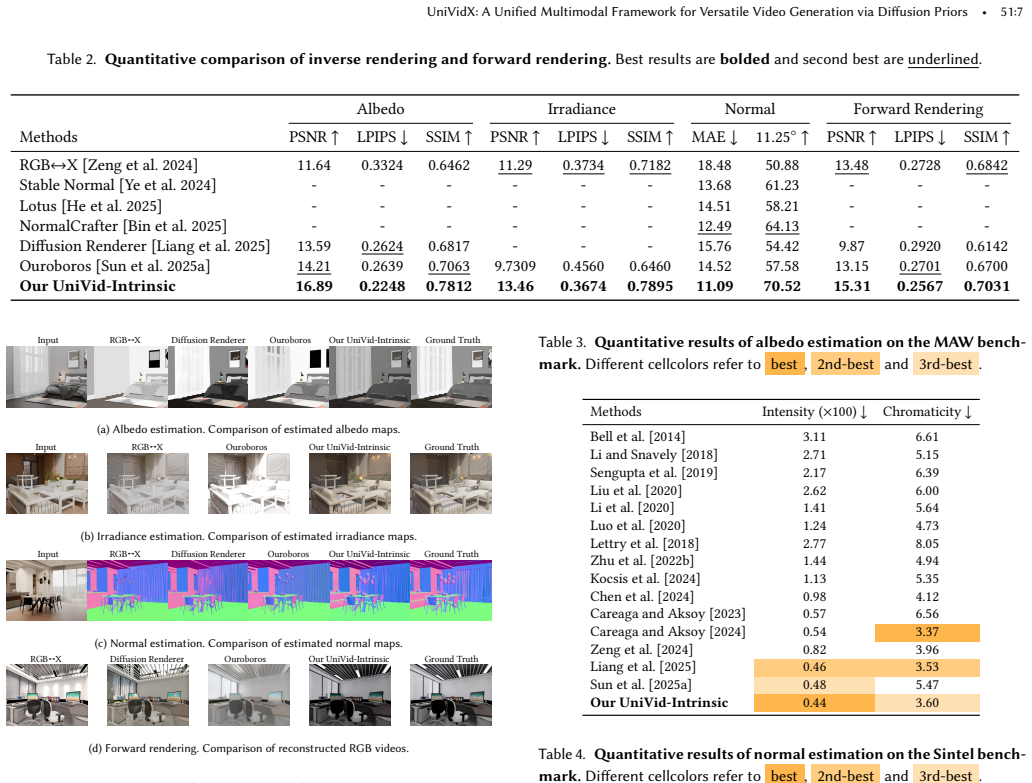
Summary. The manuscript introduces UniVidX, a unified multimodal framework for versatile video generation that builds upon video diffusion models (VDMs). It proposes three designs—Stochastic Condition Masking (SCM), Decoupled Gated LoRA (DGL), and Cross-Modal Self-Attention (CMSA)—to enable omni-directional conditional generation across modalities while adapting to specific distributions and maintaining cross-modal consistency. The approach is applied to intrinsic video decomposition (UniVid-Intrinsic) and alpha matting (UniVid-Alpha), with claims of competitive performance against state-of-the-art methods and robust generalization even when trained on limited data (<1000 videos).
Significance. If the results hold, this work could significantly impact the field by providing a single adaptable model for multiple pixel-aligned video tasks, efficiently utilizing existing VDM priors without requiring separate models per task. The emphasis on low-data generalization and cross-modal consistency addresses practical challenges in multimodal graphics and vision.
major comments (2)
- The central claim that the three designs (particularly Decoupled Gated LoRA) simultaneously preserve the backbone VDM's native priors while enabling effective cross-modal adaptation and omni-directional generation is load-bearing but lacks direct empirical isolation. No control experiments are described that re-run the frozen original VDM on its native distribution or quantify distribution shift after adaptation (e.g., via FID or negative log-likelihood on clean video frames). Competitive task performance alone does not confirm prior preservation versus task-specific override.
- The experiments section claims competitive performance and robust in-the-wild generalization with <1000 training videos, yet the provided abstract and summary supply no specific metrics, baselines, ablation results on the individual contributions of SCM/DGL/CMSA, or error analysis. This makes it impossible to verify the strength of the cross-modal consistency claims or the low-data advantage.
minor comments (2)
- The abstract would be strengthened by including at least one or two key quantitative results (e.g., PSNR, FID, or task-specific scores) alongside the qualitative claims of competitiveness.
- Clarify the exact training dataset sizes, video lengths, and resolution details for both UniVid-Intrinsic and UniVid-Alpha to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: The central claim that the three designs (particularly Decoupled Gated LoRA) simultaneously preserve the backbone VDM's native priors while enabling effective cross-modal adaptation and omni-directional generation is load-bearing but lacks direct empirical isolation. No control experiments are described that re-run the frozen original VDM on its native distribution or quantify distribution shift after adaptation (e.g., via FID or negative log-likelihood on clean video frames). Competitive task performance alone does not confirm prior preservation versus task-specific override.
Authors: We agree that direct empirical isolation of prior preservation is important for supporting the central claim. While DGL is architecturally designed to activate modality-specific adapters only when a modality is the generation target (leaving the backbone largely unchanged), the manuscript does not include explicit controls such as re-running the frozen original VDM on native video distributions or quantifying shift via FID/NLL on clean frames. We will add these experiments in the revision, including side-by-side comparisons of native video generation quality before and after adaptation. revision: yes
-
Referee: The experiments section claims competitive performance and robust in-the-wild generalization with <1000 training videos, yet the provided abstract and summary supply no specific metrics, baselines, ablation results on the individual contributions of SCM/DGL/CMSA, or error analysis. This makes it impossible to verify the strength of the cross-modal consistency claims or the low-data advantage.
Authors: The full manuscript's experiments section reports competitive results against SOTA baselines on both UniVid-Intrinsic and UniVid-Alpha, along with some component ablations and in-the-wild generalization examples using <1000 videos. However, we acknowledge that the abstract lacks specific numerical highlights and that more detailed per-component ablations plus error analysis on cross-modal consistency would improve verifiability. We will revise the abstract to summarize key metrics and expand the experiments with additional ablations isolating SCM/DGL/CMSA contributions as well as quantitative error breakdowns. revision: yes
Circularity Check
No circularity: architectural designs evaluated empirically on external benchmarks
full rationale
The paper presents UniVidX as an engineering framework that augments existing video diffusion models with three components (SCM, DGL, CMSA) to enable omni-directional conditional generation. Preservation of native priors is asserted via the per-modality gating in DGL, while cross-modal consistency is enabled by CMSA; both are tested through competitive task performance on intrinsic maps and RGBA layers, including in-the-wild generalization with <1000 training videos. No equations appear that reduce any claimed output (e.g., generation quality or consistency) to quantities defined by the authors' own fitted parameters or by self-citation. No uniqueness theorems, ansatzes, or renamings of known results are invoked. The derivation chain consists of architectural choices plus empirical validation against SOTA baselines and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video diffusion model priors can be preserved while adapting to new modality-specific distributions via gated LoRAs.
- domain assumption Randomly partitioning modalities into conditions and targets during training enables omni-directional conditional generation.
Reference graph
Works this paper leans on
-
[1]
The Computational Geometry Algorithms Library , author =
-
[2]
Menelaos Karavelas , subtitle =
-
[3]
The Computational Geometry Algorithms Library , subtitle =
Menelaos Karavelas , editor =. The Computational Geometry Algorithms Library , subtitle =
-
[4]
The Parmap library , author =
-
[5]
Christopher Anderson and Sophia Drossopoulou , title =
-
[6]
WACV , year=
Robust high-resolution video matting with temporal guidance , author=. WACV , year=
-
[7]
CVPR , year=
Matting anything , author=. CVPR , year=
-
[8]
Information Fusion , year=
ViTMatte: Boosting image matting with pre-trained plain vision transformers , author=. Information Fusion , year=
-
[9]
ECCV , year=
Diffusion for natural image matting , author=. ECCV , year=
-
[10]
WACV , year=
Vmformer: End-to-end video matting with transformer , author=. WACV , year=
-
[11]
Image and Vision Computing , year=
Matte anything: Interactive natural image matting with segment anything model , author=. Image and Vision Computing , year=
-
[12]
Yang, Peiqing and Zhou, Shangchen and Zhao, Jixin and Tao, Qingyi and Loy, Chen Change , booktitle =
-
[13]
AAAI , year =
DesignEdit: Unify Spatial-Aware Image Editing via Training-free Inpainting with a Multi-Layered Latent Diffusion Framework , author =. AAAI , year =
-
[14]
Zhou, Shangchen and Li, Chongyi and Chan, Kelvin C.K and Loy, Chen Change , booktitle=
-
[15]
2024 , booktitle=
A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting , author=. 2024 , booktitle=
2024
-
[16]
CVPR , year =
Erase Diffusion: Empowering Object Removal Through Calibrating Diffusion Pathways , author =. CVPR , year =
-
[17]
ICCV , year =
OmniPaint: Mastering Object-Oriented Editing via Disentangled Insertion-Removal Inpainting , author =. ICCV , year =
-
[18]
CVPR , year=
Generative Image Layer Decomposition with Visual Effects , author=. CVPR , year=
-
[19]
CVPR , year =
Lee, Yao-Chih and Lu, Erika and Rumbley, Sarah and Geyer, Michal and Huang, Jia-Bin and Dekel, Tali and Cole, Forrester , title =. CVPR , year =
-
[20]
arXiv preprint arXiv:2412.04460 , year =
LayerFusion: Harmonized Multi-Layer Text-to-Image Generation with Generative Priors , author =. arXiv preprint arXiv:2412.04460 , year =
-
[21]
TOG , year=
Transparent Image Layer Diffusion using Latent Transparency , author=. TOG , year=
-
[22]
CVPR , year =
ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation , author =. CVPR , year =
-
[23]
2025 , archivePrefix=
AlphaVAE: Unified End-to-End RGBA Image Reconstruction and Generation with Alpha-Aware Representation Learning , author=. 2025 , archivePrefix=
2025
-
[24]
ICCV , year =
DreamLayer: Simultaneous Multi-Layer Generation via Diffusion Model , author =. ICCV , year =
-
[25]
arXiv preprint arXiv:2509.24979 (2025)
Wan-Alpha: High-Quality Text-to-Video Generation with Alpha Channel , author =. arXiv preprint arXiv:2509.24979 , year =
-
[26]
OmniAlpha: Aligning Transparency-Aware Generation via Multi-Task Unified Reinforcement Learning
OmniAlpha: A Sequence-to-Sequence Framework for Unified Multi-Task RGBA Generation , author =. arXiv preprint arXiv:2511.20211 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets , author =. arXiv preprint arXiv:2311.15127 , year =
work page internal anchor Pith review arXiv
-
[28]
OpenAI Technical Report , year=
Video generation models as world simulators , author=. OpenAI Technical Report , year=
-
[29]
Open-Sora: Democratizing Efficient Video Production for All
Open-sora: Democratizing efficient video production for all , author=. arXiv preprint arXiv:2412.20404 , year=
work page internal anchor Pith review arXiv
-
[30]
2025 , journal=
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in 200k , author=. 2025 , journal=
2025
-
[31]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. arXiv preprint arXiv:2408.06072 , year=
work page internal anchor Pith review arXiv
-
[32]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers , author=. arXiv preprint arXiv:2205.15868 , year=
work page internal anchor Pith review arXiv
-
[33]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Hunyuanvideo: A systematic framework for large video generative models , author=. arXiv preprint arXiv:2412.03603 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Longcat-video technical report
LongCat-Video Technical Report , author =. arXiv preprint arXiv:2510.22200 , year =
-
[36]
Bin, Yanrui and Hu, Wenbo and Wang, Haoyuan and Chen, Xinya and Wang, Bing , title =
-
[37]
Ruofan Liang and Zan Gojcic and Huan Ling and Jacob Munkberg and Jon Hasselgren and Zhi-Hao Lin and Jun Gao and Alexander Keller and Nandita Vijaykumar and Sanja Fidler and Zian Wang , title =
-
[38]
UniRelight: Learning Joint Decomposition and Synthesis for Video Relighting , author=. arXiv preprint arXiv:2506.15673 , year=
-
[39]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[40]
ICLR , year=
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning , author=. ICLR , year=
-
[41]
CVPR , year =
Ke, Bingxin and Obukhov, Anton and Huang, Shengyu and Metzger, Nando and Daudt, Rodrigo Caye and Schindler, Konrad , title =. CVPR , year =
-
[42]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction
Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction , author =. arXiv preprint arXiv:2409.18124 , year =
-
[43]
arXiv preprint arXiv:2512.01030 , year =
Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model , author =. arXiv preprint arXiv:2512.01030 , year =
-
[44]
CVPR , year =
Hu, Wenbo and Gao, Xiangjun and Li, Xiaoyu and Zhao, Sijie and Cun, Xiaodong and Zhang, Yong and Quan, Long and Shan, Ying , title =. CVPR , year =
-
[45]
Depthfm: Fast monocular depth estimation with flow matching
DepthFM: Fast Monocular Depth Estimation with Flow Matching , author =. arXiv preprint arXiv:2403.13788 , year =
-
[46]
ICLR , year=
JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling , author=. ICLR , year=
-
[47]
NIPS , year=
More Than Generation: Unifying Generation and Depth Estimation via Text-to-Image Diffusion Models , author=. NIPS , year=
-
[48]
arXiv preprint arXiv:2511.18922 , year=
One4D: Unified 4D Generation and Reconstruction via Decoupled LoRA Control , author=. arXiv preprint arXiv:2511.18922 , year=
-
[49]
arXiv preprint arXiv:2504.01016 , year=
GeometryCrafter: Consistent Geometry Estimation for Open-world Videos with Diffusion Priors , author=. arXiv preprint arXiv:2504.01016 , year=
-
[50]
arXiv preprint arXiv:2410.10815 , year =
Honghui Yang and Di Huang and Wei Yin and Chunhua Shen and Haifeng Liu and Xiaofei He and Binbin Lin and Wanli Ouyang and Tong He , title =. arXiv preprint arXiv:2410.10815 , year =
-
[51]
Video Depth Anything: Consistent Depth Estimation for Super-Long Videos , author=. arXiv:2501.12375 , year=
-
[52]
ICCV , year=
Adding Conditional Control to Text-to-Image Diffusion Models , author=. ICCV , year=
-
[53]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models , author=. arXiv preprint arXiv:2302.08453 , year=
-
[54]
arXiv preprint arXiv:2305.11147 , year=
UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild , author=. arXiv preprint arXiv:2305.11147 , year=
-
[55]
arXiv preprint arXiv:2410.09400 , year=
CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation , author=. arXiv preprint arXiv:2410.09400 , year=
-
[56]
Jodi: Unification of Visual Generation and Understanding via Joint Modeling , author =. arXiv preprint arXiv:2505.19084 , year =
-
[57]
arXiv preprint arXiv:2504.10825 , year =
Xi, Dianbing and Wang, Jiepeng and Liang, Yuanzhi and Qi, Xi and Huo, Yuchi and Wang, Rui and Zhang, Chi and Li, Xuelong , title =. arXiv preprint arXiv:2504.10825 , year =
-
[58]
arXiv preprint arXiv:2511.21129 , year=
CtrlVDiff: Controllable Video Generation via Unified Multimodal Video Diffusion , author =. arXiv preprint arXiv:2511.21129 , year =
-
[59]
arXiv preprint arXiv:2411.16318 , year =
One Diffusion to Generate Them All , author =. arXiv preprint arXiv:2411.16318 , year =
-
[60]
arXiv preprint arXiv:2504.07961 , year =
Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction , author =. arXiv preprint arXiv:2504.07961 , year =
-
[61]
arXiv preprint arXiv:2502.17157 (2025)
Diception: A generalist diffusion model for visual perceptual tasks , author=. arXiv preprint arXiv:2502.17157 , year=
-
[62]
arXiv preprint arXiv:2505.24521 , year=
UniGeo: Taming Video Diffusion for Unified Consistent Geometry Estimation , author=. arXiv preprint arXiv:2505.24521 , year=
-
[63]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Revisiting deep intrinsic image decompositions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[64]
AAAI , year=
Estimating reflectance layer from a single image: Integrating reflectance guidance and shadow/specular aware learning , author=. AAAI , year=
-
[65]
TOG , year=
Colorful diffuse intrinsic image decomposition in the wild , author=. TOG , year=
-
[66]
TOG , year=
Intrinsic image decomposition via ordinal shading , author=. TOG , year=
-
[67]
CVPR , year=
Shape, albedo, and illumination from a single image of an unknown object , author=. CVPR , year=
-
[68]
NIPS , year=
Recovering intrinsic images with a global sparsity prior on reflectance , author=. NIPS , year=
-
[69]
CVPR , year=
Intrinsic scene properties from a single rgb-d image , author=. CVPR , year=
-
[70]
CVPR , year=
Non-parametric filtering for geometric detail extraction and material representation , author=. CVPR , year=
-
[71]
ECCV , year=
Unified depth prediction and intrinsic image decomposition from a single image via joint convolutional neural fields , author=. ECCV , year=
-
[72]
WACV , year=
DARN: a deep adversarial residual network for intrinsic image decomposition , author=. WACV , year=
-
[73]
SIGGRAPH Conference Papers , year =
Luo, Jundan and Ceylan, Duygu and Yoon, Jae Shin and Zhao, Nanxuan and Philip, Julien and Fr. SIGGRAPH Conference Papers , year =
-
[74]
PRISM: A Unified Framework for Photorealistic Reconstruction and Intrinsic Scene Modeling , author =. arXiv preprint arXiv:2504.14219 , year =
-
[75]
Intrinsic Image Diffusion for Indoor Single-view Material Estimation , journal =
Kocsis, Peter and Sitzmann, Vincent and Nie. Intrinsic Image Diffusion for Indoor Single-view Material Estimation , journal =
-
[76]
SIGGRAPH Conference Papers , year =
RGB X: Image decomposition and synthesis using material- and lighting-aware diffusion models , author =. SIGGRAPH Conference Papers , year =
-
[77]
Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering
Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering , author=. arXiv preprint arXiv:2508.14461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
arXiv preprint arXiv:2512.02781 , year =
LumiX: Structured and Coherent Text-to-Intrinsic Generation , author =. arXiv preprint arXiv:2512.02781 , year =
-
[79]
NIPS , year =
Kocsis, Peter and H\". NIPS , year =
-
[80]
Sparsectrl: Adding sparse controls to text-to-video diffusion models
SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models , author=. arXiv preprint arXiv:2311.16933 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.