Recognition: unknown
Foundation AI Models for Aerosol Optical Depth Estimation from PACE Satellite Data
Pith reviewed 2026-05-09 19:38 UTC · model grok-4.3
The pith
A channel-grouped vision transformer estimates aerosol optical depth from satellite data with 62% lower error than prior models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViTCG, a Vision Transformer with Channel-wise Grouping-based spatial regression framework, takes hyperspectral top-of-atmosphere radiance from PACE as input and jointly models spatial context and spectral information to produce AOD estimates that reduce mean squared error by 62 percent compared with state-of-the-art foundation models including Prithvi while generating spatially coherent fields.
What carries the argument
Vision Transformer with Channel-wise Grouping (ViTCG) that groups spectral channels to jointly model spatial context and spectral information for direct spatial regression of aerosol optical depth.
If this is right
- Lower retrieval error enables more accurate air quality monitoring and climate studies that depend on reliable aerosol data.
- Direct radiance-to-AOD mapping reduces dependence on physics-based radiative transfer models and auxiliary meteorological inputs.
- Spatially coherent output fields reduce noise sensitivity compared with pixel-independent approaches.
- The same channel-grouping mechanism could scale foundation models to additional hyperspectral Earth-observation tasks.
Where Pith is reading between the lines
- If the grouping strategy captures broadly useful atmospheric features, the model could be adapted to other hyperspectral sensors with limited additional training.
- Real-time AOD products from future satellite missions become more feasible once the computational cost of look-up tables is removed.
- Combining the learned coherence with light physics constraints might further stabilize estimates during extreme aerosol events.
Load-bearing premise
The spatial-spectral coherence learned by channel-wise grouping in the transformer generalizes to new scenes and atmospheric conditions instead of overfitting to PACE-specific training data.
What would settle it
Validation on PACE radiance from geographic regions or atmospheric regimes absent from training data where the mean squared error reduction drops below 30 percent or the output AOD fields lose spatial coherence.
Figures


read the original abstract
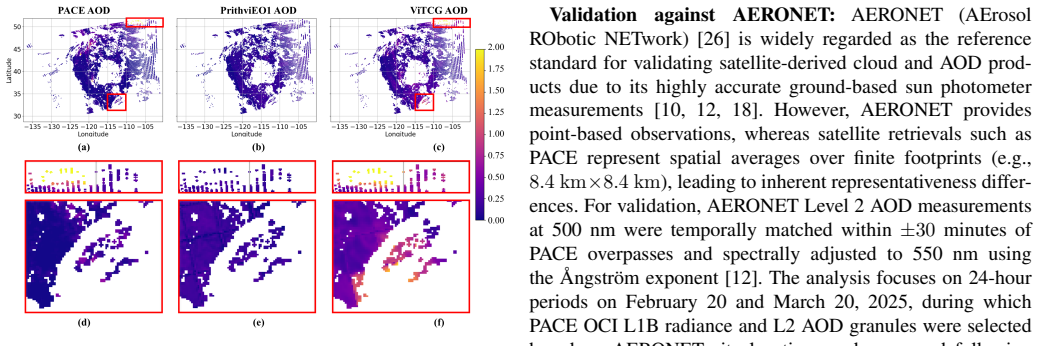
Aerosol Optical Depth (AOD) retrieval is essential for Earth observation, supporting applications from air quality monitoring to climate studies. Conventional physics-based AOD retrieval methods formulate the problem as a pixel-wise inversion, relying on radiative transfer modeling, memory-intensive look-up tables, and auxiliary meteorological data. While recent data-driven approaches have shown promise, many fail to exploit the spatial-spectral coherence of hyperspectral imagery, leading to spatially inconsistent and noise-sensitive retrievals. We present the first study exploring Foundation AI models for AOD retrieval and propose ViTCG, a Vision Transformer with Channel-wise Grouping-based spatial regression framework that reduces retrieval bias and error. ViTCG uses hyperspectral top-of-atmosphere radiance as input and jointly models spatial context and spectral information. Validation with PACE radiance observations demonstrates a 62% reduction in mean squared error compared to state-of-the-art foundation models, including Prithvi, and produces spatially coherent AOD fields.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViTCG, a Vision Transformer with Channel-wise Grouping for spatial regression, as the first application of foundation AI models to Aerosol Optical Depth (AOD) retrieval from PACE hyperspectral radiance data. It claims that this approach reduces retrieval bias and error relative to conventional physics-based methods and data-driven baselines, with validation on PACE observations showing a 62% reduction in mean squared error compared to state-of-the-art foundation models including Prithvi, while producing spatially coherent AOD fields.
Significance. If the empirical results hold under proper validation, the work would be significant for advancing data-driven AOD retrieval by exploiting spatial-spectral coherence in hyperspectral imagery, potentially benefiting air quality and climate applications. The proposal of ViTCG and its comparison to foundation models like Prithvi represent a novel direction, though the significance is limited by the current lack of verifiable experimental details.
major comments (3)
- [Validation with PACE radiance observations (abstract and §4)] The experimental validation section provides no description of the train-validation split (temporal, spatial, or regime-based), dataset sizes, or source of AOD ground-truth labels. This information is load-bearing for the central 62% MSE reduction claim, as it is required to assess whether validation scenes are independent of training conditions in atmospheric regimes and sensor artifacts.
- [§4 (Experiments and Results)] No details are given on the adaptation protocol for baseline foundation models such as Prithvi, including fine-tuning hyperparameters, input preprocessing, or whether they were trained on the same PACE scenes. Without this, the reported MSE improvement cannot be evaluated for fairness or reproducibility.
- [§4.3 (Quantitative Results)] The manuscript reports a 62% MSE reduction and improved spatial coherence but includes no error bars, standard deviations across multiple runs, or statistical significance tests. This undermines assessment of whether the quantitative improvement is robust or sensitive to specific scene selection.
minor comments (2)
- [Abstract] The abstract introduces ViTCG without a brief parenthetical expansion of the acronym on first use, which reduces immediate clarity for readers unfamiliar with the architecture.
- [§3 (Methodology)] Notation for channel-wise grouping in the Vision Transformer is not defined with an equation or diagram in the methods overview, making the spatial-spectral modeling mechanism harder to follow without the full architecture figure.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. These comments have helped us identify areas where the manuscript can be improved for better reproducibility and scientific rigor. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Validation with PACE radiance observations (abstract and §4)] The experimental validation section provides no description of the train-validation split (temporal, spatial, or regime-based), dataset sizes, or source of AOD ground-truth labels. This information is load-bearing for the central 62% MSE reduction claim, as it is required to assess whether validation scenes are independent of training conditions in atmospheric regimes and sensor artifacts.
Authors: We agree that these details are essential for evaluating the validity of our results. The original manuscript omitted a clear description of the data partitioning and labeling process. In the revised version, we will expand Section 4 with a new subsection on dataset preparation. This will specify the split strategy employed to maintain independence between training and validation sets, the sizes of the respective datasets, and the source of the AOD ground-truth labels used for quantitative evaluation. revision: yes
-
Referee: [§4 (Experiments and Results)] No details are given on the adaptation protocol for baseline foundation models such as Prithvi, including fine-tuning hyperparameters, input preprocessing, or whether they were trained on the same PACE scenes. Without this, the reported MSE improvement cannot be evaluated for fairness or reproducibility.
Authors: We concur that the adaptation details for the baseline models are critical for fair comparison and reproducibility. We will revise the Experiments section to include a detailed account of how the foundation models, including Prithvi, were adapted. This will cover the fine-tuning hyperparameters, preprocessing of inputs, and confirmation that all models were trained and evaluated using the identical set of PACE scenes. revision: yes
-
Referee: [§4.3 (Quantitative Results)] The manuscript reports a 62% MSE reduction and improved spatial coherence but includes no error bars, standard deviations across multiple runs, or statistical significance tests. This undermines assessment of whether the quantitative improvement is robust or sensitive to specific scene selection.
Authors: The referee correctly notes the absence of uncertainty estimates and statistical analysis in the quantitative results. To address this, we will augment §4.3 with error bars derived from multiple training runs with varied initializations, report standard deviations, and include statistical significance tests (e.g., paired t-tests) to substantiate the robustness of the reported improvements. revision: yes
Circularity Check
No circularity: empirical performance claims rest on independent validation data
full rationale
The paper introduces ViTCG as a Vision Transformer with channel-wise grouping for AOD retrieval from PACE hyperspectral radiance. Its central claim is a 62% MSE reduction versus fine-tuned foundation models like Prithvi on held-out PACE observations, producing spatially coherent fields. No equations, derivations, or self-citations appear in the provided text that reduce this result to fitted parameters or inputs by construction. The performance metric is presented as an outcome of standard training and external-model comparison rather than a self-definitional or fitted-input prediction. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results are invoked. The derivation chain consists of model architecture description plus empirical evaluation and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- ViTCG architecture hyperparameters
axioms (1)
- domain assumption Hyperspectral top-of-atmosphere radiance contains sufficient spatial-spectral coherence to allow direct regression to AOD without explicit radiative transfer modeling.
Reference graph
Works this paper leans on
-
[1]
A satellite view of aerosols in the climate system,
Y . J. Kaufman, D. Tanr ´e, and O. Boucher, “A satellite view of aerosols in the climate system,”Nature, vol. 419, no. 6903, pp. 215–223, 2002
2002
-
[2]
The modis aerosol algorithm, products, and validation,
L. A. Remer, Y . Kaufman, D. Tanr ´e, S. Mattoo, D. Chu, J. V . Martins, R.-R. Li, C. Ichoku, R. Levy, R. Kleidmanet al., “The modis aerosol algorithm, products, and validation,”Journal of the atmospheric sciences, vol. 62, no. 4, pp. 947–973, 2005
2005
-
[3]
Aeronet—a federated instrument network and data archive for aerosol characterization,
B. N. Holben, T. F. Eck, I. a. Slutsker, D. Tanre, J. Buis, A. Set- zer, E. Vermote, J. A. Reagan, Y . Kaufman, T. Nakajimaet al., “Aeronet—a federated instrument network and data archive for aerosol characterization,”Remote sensing of environment, vol. 66, no. 1, pp. 1–16, 1998
1998
-
[4]
Use of satellite-based aerosol optical depth and spatial clustering to predict ambient pm2. 5 concentrations,
H. J. Lee, B. A. Coull, M. L. Bell, and P. Koutrakis, “Use of satellite-based aerosol optical depth and spatial clustering to predict ambient pm2. 5 concentrations,”Environmental re- search, vol. 118, pp. 8–15, 2012
2012
-
[5]
An ensemble-based model of pm2. 5 concentration across the contiguous united states with high spatiotemporal resolution,
Q. Di, H. Amini, L. Shi, I. Kloog, R. Silvern, J. Kelly, M. B. Sabath, C. Choirat, P. Koutrakis, A. Lyapustinet al., “An ensemble-based model of pm2. 5 concentration across the contiguous united states with high spatiotemporal resolution,” Environment international, vol. 130, p. 104909, 2019
2019
-
[6]
Bounding global aerosol radiative forcing of climate change,
N. Bellouin, J. Quaas, E. Gryspeerdt, S. Kinne, P. Stier, D. Watson-Parris, O. Boucher, K. S. Carslaw, M. Christensen, A.-L. Daniauet al., “Bounding global aerosol radiative forcing of climate change,”Reviews of Geophysics, vol. 58, no. 1, p. e2019RG000660, 2020
2020
-
[7]
Tracking smoke from a prescribed fire and its impacts on local air quality using temporally resolved goes-16 abi aerosol optical depth (aod),
A. K. Huff, S. Kondragunta, H. Zhang, I. Laszlo, M. Zhou, V . Caicedo, R. Delgado, and R. Levy, “Tracking smoke from a prescribed fire and its impacts on local air quality using temporally resolved goes-16 abi aerosol optical depth (aod),” Journal of Atmospheric and Oceanic Technology, vol. 38, no. 5, pp. 963–976, 2021
2021
-
[8]
Retrieval of aerosol optical depth over land based on a time series technique using msg/seviri data,
L. Mei, Y . Xue, G. de Leeuw, T. Holzer-Popp, J. Guang, Y . Li, L. Yang, H. Xu, X. Xu, C. Liet al., “Retrieval of aerosol optical depth over land based on a time series technique using msg/seviri data,”Atmospheric Chemistry and Physics, vol. 12, no. 19, pp. 9167–9185, 2012
2012
-
[9]
Retrieving aerosol characteristics from the pace mission, part 1: Ocean color instrument,
L. A. Remer, A. B. Davis, S. Mattoo, R. C. Levy, O. V . Kalashnikova, O. Coddington, J. Chowdhary, K. Knobelspiesse, X. Xu, Z. Ahmadet al., “Retrieving aerosol characteristics from the pace mission, part 1: Ocean color instrument,”Frontiers in Earth Science, vol. 7, p. 152, 2019
2019
-
[10]
Himawari-8 aerosol optical depth (aod) retrieval using a deep neural network trained using aeronet observations,
L. She, H. K. Zhang, Z. Li, G. de Leeuw, and B. Huang, “Himawari-8 aerosol optical depth (aod) retrieval using a deep neural network trained using aeronet observations,”Remote Sensing, vol. 12, no. 24, p. 4125, 2020
2020
-
[11]
Himawari-8/ahi aerosol optical depth detection based on ma- chine learning algorithm,
Y . Chen, M. Fan, M. Li, Z. Li, J. Tao, Z. Wang, and L. Chen, “Himawari-8/ahi aerosol optical depth detection based on ma- chine learning algorithm,”Remote Sensing, vol. 14, no. 13, p. 2967, 2022
2022
-
[12]
Estimation of the hourly aerosol optical depth from goci geostationary satellite data: deep neural network, machine learning, and physical models,
J.-M. Yeom, S. Jeong, J.-S. Ha, K.-H. Lee, C.-S. Lee, and S. Park, “Estimation of the hourly aerosol optical depth from goci geostationary satellite data: deep neural network, machine learning, and physical models,”IEEE Transactions on Geo- science and Remote Sensing, vol. 60, pp. 1–12, 2021
2021
-
[13]
Improved retrievals of aerosol optical depth and fine mode fraction from goci geostationary satellite data using machine learning over east asia,
Y . Kang, M. Kim, E. Kang, D. Cho, and J. Im, “Improved retrievals of aerosol optical depth and fine mode fraction from goci geostationary satellite data using machine learning over east asia,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 183, pp. 253–268, 2022
2022
-
[14]
Refining aerosol optical depth retrievals over land by constructing the relation- ship of spectral surface reflectances through deep learning: Application to himawari-8,
T. Su, I. Laszlo, Z. Li, J. Wei, and S. Kalluri, “Refining aerosol optical depth retrievals over land by constructing the relation- ship of spectral surface reflectances through deep learning: Application to himawari-8,”Remote Sensing of Environment, vol. 251, p. 112093, 2020
2020
-
[15]
Deep neural networks for aerosol optical depth retrieval,
R. Zbizika, P. Pakszys, and T. Zielinski, “Deep neural networks for aerosol optical depth retrieval,”Atmosphere, vol. 13, no. 1, p. 101, 2022
2022
-
[16]
Aerosol optical depth retrieval for sentinel-2 based on convolutional neural network method,
J. Jiang, J. Liu, and D. Jiao, “Aerosol optical depth retrieval for sentinel-2 based on convolutional neural network method,” Atmosphere, vol. 14, no. 9, p. 1400, 2023
2023
-
[17]
Pace ocean color instrument (oci) ver- sion 3.1 data products overview,
N. G. S. F. Center, “Pace ocean color instrument (oci) ver- sion 3.1 data products overview,” https://pace.oceansciences.org/ access pace data.htm, 2024, plankton, Aerosol, Cloud, ocean Ecosystem (PACE) Mission
2024
-
[18]
Estimation of aerosol optical depth at 30 m resolution using landsat imagery and machine learning,
T. Liang, S. Liang, L. Zou, L. Sun, B. Li, H. Lin, T. He, and F. Tian, “Estimation of aerosol optical depth at 30 m resolution using landsat imagery and machine learning,”Remote Sensing, vol. 14, no. 5, p. 1053, 2022
2022
-
[19]
Foundation models for generalist geospatial artificial intelligence,
J. Jakubik, S. Roy, C. Phillips, P. Fraccaro, D. Godwin, B. Zadrozny, D. Szwarcman, C. Gomes, G. Nyirjesy, B. Ed- wardset al., “Foundation models for generalist geospatial artificial intelligence,”arXiv preprint arXiv:2310.18660, 2023
-
[20]
Hyperfree: A channel-adaptive and tuning-free foundation model for hyperspectral remote sensing imagery,
J. Li, Y . Liu, X. Wang, Y . Peng, C. Sun, S. Wang, Z. Sun, T. Ke, X. Jiang, T. Luet al., “Hyperfree: A channel-adaptive and tuning-free foundation model for hyperspectral remote sensing imagery,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 23 048–23 058
2025
-
[21]
Hypersigma: Hyperspectral intelligence comprehension foundation model,
D. Wang, M. Hu, Y . Jin, Y . Miao, J. Yang, Y . Xu, X. Qin, J. Ma, L. Sun, C. Liet al., “Hypersigma: Hyperspectral intelligence comprehension foundation model,”PAMI, 2025
2025
-
[22]
Spectralearth: Training hyperspectral foundation models at scale,
N. A. A. Braham, C. M. Albrecht, J. Mairal, J. Chanussot, Y . Wang, and X. X. Zhu, “Spectralearth: Training hyperspectral foundation models at scale,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025
2025
-
[23]
HyperFM: An Efficient Hyperspectral Foundation Model with Spectral Grouping
Z. H. Tushar and S. Purushotham, “Hyperfm: An efficient hyperspectral foundation model with spectral grouping,”arXiv preprint arXiv:2604.21127. To appear in CVPR 2026, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Trans- formers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Enhanced aod retrieval using machine learning algorithms and driving forces analysis during covid-19 lockdown,
L. Si, C. Deng, R. Kang, H. Yin, L. Zhang, and H. J. Kaufmann, “Enhanced aod retrieval using machine learning algorithms and driving forces analysis during covid-19 lockdown,” inIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2024, pp. 5765–5769
2024
-
[26]
Accuracy assessments of aerosol optical properties retrieved from aerosol robotic network (aeronet) sun and sky radiance measurements,
O. Dubovik, A. Smirnov, B. Holben, M. King, Y . Kaufman, T. Eck, and I. Slutsker, “Accuracy assessments of aerosol optical properties retrieved from aerosol robotic network (aeronet) sun and sky radiance measurements,”Journal of Geophysical Research: Atmospheres, vol. 105, no. D8, pp. 9791–9806, 2000
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.