Recognition: unknown
Static and Dynamic Graph Alignment Network for Temporal Video Grounding
Pith reviewed 2026-05-09 19:34 UTC · model grok-4.3
The pith
SDGAN improves temporal video grounding by jointly aligning static and dynamic graph features with queries through contrastive learning and progressive multi-granularity training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
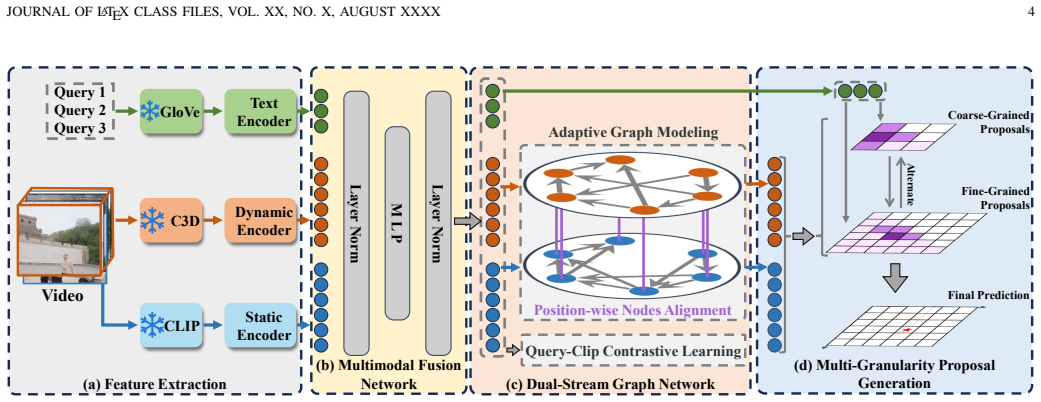
SDGAN jointly exploits static and dynamic visual features to construct two complementary temporal graphs and performs position-wise nodes alignment for more expressive representations. It introduces query-clip contrastive learning and adaptive graph modeling to explicitly align visual clips with textual queries for query-aware representations. It incorporates multi-granularity temporal proposals within a progressive easy-to-hard training strategy to bridge coarse-grained semantic localization and fine-grained boundary refinement, addressing the bottlenecks of incomplete representations, query-agnostic graphs, and single-granularity matching in prior GCN-based temporal video grounding methods
What carries the argument
Position-wise Nodes Alignment on complementary static-dynamic temporal graphs, together with Query-Clip Contrastive Learning, Adaptive Graph Modeling, and Progressive Easy-to-Hard Training Strategy using multi-granularity proposals
If this is right
- Complementary static and dynamic features yield more complete visual semantics inside the temporal graphs.
- Query-aware modeling through contrastive learning and adaptive graphs produces more efficient clip-query interaction.
- Progressive training from coarse to fine proposals improves convergence speed and final boundary precision.
- The combined approach delivers higher performance on complex temporal video grounding tasks than prior single-granularity or query-agnostic graphs.
Where Pith is reading between the lines
- The same alignment and progressive strategy could transfer to other video-language tasks that rely on graph structures, such as dense video captioning.
- If query-aware contrastive terms reduce the need for explicit query fusion modules, similar components might simplify architectures in related multimodal retrieval problems.
- The staged training schedule offers a testable way to handle very long videos where direct fine-grained supervision is scarce.
Load-bearing premise
That the three listed bottlenecks in earlier GCN methods are the main limitations and that the proposed alignment, contrastive, and progressive components will overcome them without creating new overfitting or generalization problems.
What would settle it
A head-to-head test on the same three benchmark datasets where SDGAN fails to exceed the localization accuracy of the strongest prior GCN-based method would show the components do not reliably overcome the stated bottlenecks.
Figures




read the original abstract
Temporal Video Grounding (TVG) aims to localize temporal moments in an untrimmed video that semantically correspond to given natural language queries. Recently, Graph Convolutional Networks (GCN) have been widely adopted in TVG to model temporal relations among video clips and enhance contextual reasoning by constructing clip-level graphs. Despite their effectiveness, existing GCN-based TVG methods encounter three critical bottlenecks: 1) Most methods construct graph nodes using either static or dynamic features alone, resulting in incomplete visual representation and overlooking complementary semantics, 2) Most methods construct temporal graphs in a query-agnostic manner, leading to inefficient feature interaction within the temporal graph representation, and 3) Most methods often suffer from a single-granularity semantic matching, while direct training on complex temporal localization task may lead to slow convergence and suboptimal precision. To address these challenges, we propose Static and Dynamic Graph Alignment Network (SDGAN). First, SDGAN jointly exploits static and dynamic visual features to construct two complementary temporal graphs and performs Position-wise Nodes Alignment, enabling more expressive and robust visual representation. Second, SDGAN introduces Query-Clip Contrastive Learning and Adaptive Graph Modeling to explicitly align visual clips with their corresponding textual queries, yielding query-aware visual representations. Third, SDGAN incorporates multi-granularity temporal proposals within Progressive Easy-to-Hard Training Strategy, effectively bridging coarse-grained semantic localization and fine-grained temporal boundary refinement. Extensive experiments on three benchmark datasets demonstrate that SDGAN achieves superior performance across complex TVG scenarios. Codes and datasets are available at https://github.com/ZhanJieHu/SDGAN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Static and Dynamic Graph Alignment Network (SDGAN) for temporal video grounding (TVG). It identifies three bottlenecks in prior GCN-based TVG approaches: (1) use of static or dynamic visual features in isolation, (2) query-agnostic temporal graph construction, and (3) single-granularity semantic matching that hinders convergence. SDGAN addresses these via complementary static/dynamic graphs with position-wise node alignment, query-clip contrastive learning plus adaptive graph modeling for query-aware features, and multi-granularity proposals under a progressive easy-to-hard training regime. Experiments on three benchmarks report superior performance, with code and data released.
Significance. If the reported gains are causally attributable to the alignment, contrastive, and progressive components rather than capacity or optimization differences, the work would strengthen multi-modal temporal reasoning in TVG by demonstrating how static/dynamic complementarity and explicit query-visual alignment can be jointly modeled. The public release of code and datasets at https://github.com/ZhanJieHu/SDGAN is a clear strength that supports reproducibility and follow-up research.
major comments (3)
- [Section 3 (Method) and Section 4 (Experiments)] The central claim attributes performance gains to the three proposed modules overcoming the identified bottlenecks, yet no ablation studies isolate their individual contributions (e.g., static+dynamic alignment vs. dynamic-only, contrastive loss vs. standard cross-entropy, or progressive vs. direct fine-grained training). Without such controls, it remains possible that gains arise from higher effective capacity or longer optimization rather than the claimed mechanisms. This directly affects the soundness of the causal attribution in the abstract and Section 3.
- [Section 4 (Experiments), Table 1 and Table 2] Baseline comparisons do not report whether prior GCN methods were re-implemented with identical backbone features, proposal generation, or training schedules. If feature extractors or hyperparameters differ, the superiority cannot be confidently ascribed to the position-wise alignment or adaptive graph modeling. A controlled re-implementation table is needed to rule out implementation confounds.
- [Section 3.3 (Progressive Training) and Section 4.3 (Ablation)] The progressive easy-to-hard strategy is described as bridging coarse-to-fine localization, but no analysis shows that it improves boundary precision beyond simply increasing the number of training steps or proposal diversity. An ablation varying only the granularity schedule while holding total epochs fixed would be required to support the claim.
minor comments (2)
- [Abstract] The abstract states results on 'three benchmark datasets' without naming them; the datasets (presumably Charades-STA, ActivityNet Captions, etc.) should be identified in the abstract for immediate context.
- [Section 3.1 and 3.2] Notation for the position-wise alignment operation and the adaptive graph modeling is introduced without an explicit equation reference in the main text; adding numbered equations for these operations would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, agreeing that additional controls will strengthen the causal claims regarding our proposed modules. We will incorporate the suggested experiments and clarifications in the revised version.
read point-by-point responses
-
Referee: [Section 3 (Method) and Section 4 (Experiments)] The central claim attributes performance gains to the three proposed modules overcoming the identified bottlenecks, yet no ablation studies isolate their individual contributions (e.g., static+dynamic alignment vs. dynamic-only, contrastive loss vs. standard cross-entropy, or progressive vs. direct fine-grained training). Without such controls, it remains possible that gains arise from higher effective capacity or longer optimization rather than the claimed mechanisms. This directly affects the soundness of the causal attribution in the abstract and Section 3.
Authors: We agree that more granular ablations are necessary to rigorously attribute gains to the specific mechanisms rather than capacity or optimization differences. While our existing experiments in Section 4 demonstrate the overall effectiveness of SDGAN, we will add targeted ablation studies in the revision: comparing the full static+dynamic alignment against dynamic-only; query-clip contrastive learning against standard cross-entropy; and progressive training against direct fine-grained training. These will support the claims in the abstract and Section 3. revision: yes
-
Referee: [Section 4 (Experiments), Table 1 and Table 2] Baseline comparisons do not report whether prior GCN methods were re-implemented with identical backbone features, proposal generation, or training schedules. If feature extractors or hyperparameters differ, the superiority cannot be confidently ascribed to the position-wise alignment or adaptive graph modeling. A controlled re-implementation table is needed to rule out implementation confounds.
Authors: We acknowledge the importance of ruling out implementation confounds for fair comparison. Our baseline results followed the original papers' reported settings for backbones and proposals, but to address this explicitly, we will revise the experimental section and tables to detail the exact backbone features, proposal generation, and training schedules used for each prior GCN method. Where needed, we will re-implement under identical conditions. revision: yes
-
Referee: [Section 3.3 (Progressive Training) and Section 4.3 (Ablation)] The progressive easy-to-hard strategy is described as bridging coarse-to-fine localization, but no analysis shows that it improves boundary precision beyond simply increasing the number of training steps or proposal diversity. An ablation varying only the granularity schedule while holding total epochs fixed would be required to support the claim.
Authors: We agree that isolating the progressive schedule's benefit is important. We will add a controlled ablation in the revised manuscript that holds total epochs and proposal diversity fixed while comparing the progressive granularity schedule against a constant fine-grained schedule. This will demonstrate the specific contribution to boundary precision beyond additional training steps. revision: yes
Circularity Check
No circularity; empirical architecture claims rest on experiments, not derivations
full rationale
The paper introduces SDGAN as an architectural solution to three stated bottlenecks in prior GCN-based TVG work, describing its components (static/dynamic graph alignment, query-clip contrastive learning, adaptive modeling, and progressive training) in prose without any equations, fitted parameters, or mathematical derivations. Claims of superiority are grounded in experimental results on benchmark datasets rather than any self-referential prediction or construction that reduces to inputs. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text. The derivation chain is therefore self-contained as a standard empirical proposal of neural network modules, with performance evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on video temporal grounding with multimodal large language model,
J. Wu, W. Liu, Y . Liu, M. Liu, L. Nie, Z. Lin, and C. W. Chen, “A survey on video temporal grounding with multimodal large language model,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 48, no. 2, pp. 1521–1541, 2026
2026
-
[2]
Video- Seer: A hierarchical scene selection and multi-view analysis approach for zero-shot video question answering,
C. Huang, J. Zhu, Z. Li, H. Guo, J. Liu, P. De Meo, and W. Shi, “Video- Seer: A hierarchical scene selection and multi-view analysis approach for zero-shot video question answering,”IEEE Transactions on Multimedia, pp. 1–11, 2026
2026
-
[3]
Global-shared text representation based multi-stage fusion Transformer network for multi-modal dense video captioning,
Y . Xie, J. Niu, Y . Zhang, and F. Ren, “Global-shared text representation based multi-stage fusion Transformer network for multi-modal dense video captioning,”IEEE Transactions on Multimedia, vol. 26, pp. 3164– 3179, 2024
2024
-
[4]
A novel action saliency and context-aware network for weakly-supervised temporal action localization,
Y . Zhao, H. Zhang, Z. Gao, W. Gao, M. Wang, and S. Chen, “A novel action saliency and context-aware network for weakly-supervised temporal action localization,”IEEE Transactions on Multimedia, vol. 25, pp. 8253–8266, 2023
2023
-
[5]
TALL: Temporal Activity Localization via Language query,
J. Gao, C. Sun, Z. Yang, and R. Nevatia, “TALL: Temporal Activity Localization via Language query,” inProceedings of the 16th IEEE International Conference on Computer Vision, 2017, pp. 5277–5285
2017
-
[6]
Localizing moments in video with natural language,
L. A. Hendricks, O. Wang, E. Shechtman, J. Sivic, T. Darrell, and B. Russell, “Localizing moments in video with natural language,” in Proceedings of the 16th IEEE International Conference on Computer Vision, 2017, pp. 5804–5813
2017
-
[7]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inProceedings of the 5th International Con- ference on Learning Representations, 2017, pp. 1–14
2017
-
[8]
Towards graph contrastive learning: A survey and beyond,
W. Ju, Y . Wang, Y . Qin, Z. Mao, Z. Xiao, J. Luo, J. Yang, Y . Gu, D. Wang, Q. Longet al., “Towards graph contrastive learning: A survey and beyond,”Computing Research Repository, arXiv Preprint, arXiv:2405.11868, 2024
-
[9]
Multi-order Chebyshev-based composite relation graph matching network for temporal sentence grounding in videos,
G. Wu, X. Bi, and J. Zhang, “Multi-order Chebyshev-based composite relation graph matching network for temporal sentence grounding in videos,”Expert Systems with Applications, vol. 288, no. 127901, pp. 1–13, 2025
2025
-
[10]
Unified static and dynamic network: Efficient temporal filtering for video grounding,
J. Hu, D. Guo, K. Li, Z. Si, X. Yang, X. Chang, and M. Wang, “Unified static and dynamic network: Efficient temporal filtering for video grounding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 8, pp. 6445–6462, 2025
2025
-
[11]
Fine-grained video–text re- trieval with hierarchical graph reasoning,
S. Chen, Y . Zhao, Q. Jin, and Q. Wu, “Fine-grained video–text re- trieval with hierarchical graph reasoning,” inProceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 635–10 644
2020
-
[12]
Cross-modal interaction networks for query-based moment retrieval in videos,
Z. Zhang, Z. Lin, Z. Zhao, and Z. Xiao, “Cross-modal interaction networks for query-based moment retrieval in videos,” inProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2019, pp. 655–664
2019
-
[13]
MKER: Multi-modal Knowledge Extraction and Reasoning for future event prediction,
C. Lai and S. Qiu, “MKER: Multi-modal Knowledge Extraction and Reasoning for future event prediction,”Complex & Intelligent Systems, vol. 11, no. 2, pp. 138–153, 2025. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. X, AUGUST XXXX 10
2025
-
[14]
DORi: Discovering Object Relationships for moment lo- calization of a natural language query in a video,
C. Rodriguez-Opazo, E. Marrese-Taylor, B. Fernando, H. Li, and S. Gould, “DORi: Discovering Object Relationships for moment lo- calization of a natural language query in a video,” inProceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision, 2021, pp. 1078–1087
2021
-
[15]
Relation-aware video reading comprehension for temporal language grounding,
J. Gao, X. Sun, M. Xu, X. Zhou, and B. Ghanem, “Relation-aware video reading comprehension for temporal language grounding,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 3978–3988
2021
-
[16]
Learning spatiotemporal features with 3D convolutional networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3D convolutional networks,” inProceedings of the 15th IEEE International Conference on Computer Vision, 2015, pp. 4489–4497
2015
-
[17]
Quo vadis, action recognition? A new model and the Kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the Kinetics dataset,” inProceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4724–4733
2017
-
[18]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning, vol. 139, 2021, pp. 8748–8763
2021
-
[19]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” inProceedings of the 3rd International Conference on Learning Representations, 2015, pp. 1–14
2015
-
[20]
Curriculum learning,
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” inProceedings of the 26th Annual International Conference on Machine Learning, 2009, pp. 41–48
2009
-
[21]
Dense- captioning events in videos,
R. Krishna, K. Hata, F. Ren, L. Fei-Fei, and J. C. Niebles, “Dense- captioning events in videos,” inProceedings of the 16th IEEE Interna- tional Conference on Computer Vision, 2017, pp. 706–715
2017
-
[22]
Grounding action descriptions in videos,
M. Regneri, M. Rohrbach, D. Wetzel, S. Thater, B. Schiele, and M. Pinkal, “Grounding action descriptions in videos,”Transactions of the Association for Computational Linguistics, vol. 1, pp. 25–36, 2013
2013
-
[23]
Temporal sentence grounding in videos: A survey and future directions,
H. Zhang, A. Sun, W. Jing, and J. T. Zhou, “Temporal sentence grounding in videos: A survey and future directions,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 10 443– 10 465, 2023
2023
-
[24]
Weakly supervised temporal sentence grounding with Gaussian-based contrastive proposal learning,
M. Zheng, Y . Huang, Q. Chen, Y . Peng, and Y . Liu, “Weakly supervised temporal sentence grounding with Gaussian-based contrastive proposal learning,” inProceedings of the 2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2022, pp. 15 534–15 543
2022
-
[25]
Learning 2D temporal adjacent networks for moment localization with natural language,
S. Zhang, H. Peng, J. Fu, and J. Luo, “Learning 2D temporal adjacent networks for moment localization with natural language,” inProceedings of the 34th AAAI Conference on Artificial Intelligence, no. 7, 2020, pp. 12 870–12 877
2020
-
[26]
Reproducibility companion paper: Maskable retentive network for video moment retrieval,
J. Hu, D. Guo, M. Wang, J. Li, and F. Liu, “Reproducibility companion paper: Maskable retentive network for video moment retrieval,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 13 669–13 672
2025
-
[27]
Turing patterns for multime- dia: Reaction-diffusion multi-modal fusion for language-guided video moment retrieval,
X. Fang, W. Fang, W. Ji, and T.-S. Chua, “Turing patterns for multime- dia: Reaction-diffusion multi-modal fusion for language-guided video moment retrieval,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 12 509–12 518
2025
-
[28]
Revi- sionLLM: Recursive vision–language model for temporal grounding in hour-long videos,
T. Hannan, M. M. Islam, J. Gu, T. Seidl, and G. Bertasius, “Revi- sionLLM: Recursive vision–language model for temporal grounding in hour-long videos,” inProceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 19 012–19 022
2025
-
[29]
Graph convolutional networks for temporal action localization,
R. Zeng, W. Huang, C. Gan, M. Tan, Y . Rong, P. Zhao, and J. Huang, “Graph convolutional networks for temporal action localization,” inPro- ceedings of the 17th IEEE/CVF International Conference on Computer Vision, 2019, pp. 7093–7102
2019
-
[30]
Dimensionality reduction by learning an invariant mapping,
R. Hadsell, S. Chopra, and Y . LeCun, “Dimensionality reduction by learning an invariant mapping,” inProceedings of the 2006 IEEE Com- puter Society Conference on Computer Vision and Pattern Recognition, vol. 2, 2006, pp. 1735–1742
2006
-
[31]
Self-organization in a perceptual network,
R. Linsker, “Self-organization in a perceptual network,”Computer, vol. 21, no. 3, pp. 105–117, 1988
1988
-
[32]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,”The Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948
1948
-
[33]
Graph contrastive learning with adaptive augmentation,
Y . Zhu, Y . Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Graph contrastive learning with adaptive augmentation,” inProceedings of the Web Con- ference 2021, 2021, pp. 2069–2080
2021
-
[34]
Learning representations by maximizing mutual information across views,
P. Bachman, R. D. Hjelm, and W. Buchwalter, “Learning representations by maximizing mutual information across views,”Advances in Neural Information Processing Systems, vol. 32, pp. 15 509–15 519, 2019
2019
-
[35]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”Computing Research Repository, arXiv Preprint,arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,
M. Gutmann and A. Hyvärinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,” inProceedings of the 13th International Conference on Artificial Intelligence and Statistics, vol. 9, 2010, pp. 297–304
2010
-
[37]
An empirical study of graph contrastive learning,
Y . Zhu, Y . Xu, Q. Liu, and S. Wu, “An empirical study of graph contrastive learning,” inProceedings of the 35th Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[38]
ProGCL: Rethinking hard negative mining in Graph Contrastive Learning,
J. Xia, L. Wu, G. Wang, J. Chen, and S. Z. Li, “ProGCL: Rethinking hard negative mining in Graph Contrastive Learning,” inProceedings of the 39th International Conference on Machine Learning, 2022, pp. 24 332–24 346
2022
-
[39]
A new mechanism for eliminating implicit conflict in graph contrastive learning,
D. He, J. Zhao, C. Huo, Y . Huang, Y . Huang, and Z. Feng, “A new mechanism for eliminating implicit conflict in graph contrastive learning,” inProceedings of the 38th AAAI Conference on Artificial Intelligence, vol. 38, no. 11, 2024, pp. 12 340–12 348
2024
-
[40]
Divergence measures based on the Shannon entropy,
J. Lin, “Divergence measures based on the Shannon entropy,”IEEE Transactions on Information Theory, vol. 37, no. 1, pp. 145–151, 1991
1991
-
[41]
Learning deep representations by mutual information estimation and maximization,
R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, and Y . Bengio, “Learning deep representations by mutual information estimation and maximization,” inProceedings of the 7th International Conference on Learning Representations, 2019
2019
-
[42]
Deep Graph Infomax,
P. Veli ˇckovi´c, W. Fedus, W. L. Hamilton, P. Liò, Y . Bengio, and R. D. Hjelm, “Deep Graph Infomax,” inProceedings of the 7th International Conference on Learning Representations, 2019, pp. 1–17
2019
-
[43]
HyperGCL: Multi-modal Graph Contrastive Learning via learnable Hypergraph views,
K. M. Saifuddin, S. Ji, and E. Akbas, “HyperGCL: Multi-modal Graph Contrastive Learning via learnable Hypergraph views,” inProceedings of the International Joint Conference on Neural Networks 2025, 2025, pp. 1–8
2025
-
[44]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[45]
VideoMamba: State space model for efficient video understanding,
K. Li, X. Li, Y . Wang, Y . He, Y . Wang, L. Wang, and Y . Qiao, “VideoMamba: State space model for efficient video understanding,” inProceedings of the 18th European Conference on Computer Vision, Part XXVI, 2024, pp. 237–255
2024
-
[46]
GloVe: Global Vectors for word representation,
J. Pennington, R. Socher, and C. Manning, “GloVe: Global Vectors for word representation,” inProceedings of the 19th Conference on Empirical Methods in Natural Language Processing, 2014, pp. 1532– 1543
2014
-
[47]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”Com- puting Research Repository, arXiv Preprint,arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[49]
Video corpus moment retrieval with contrastive learning,
H. Zhang, A. Sun, W. Jing, G. Nan, L. Zhen, J. T. Zhou, and R. S. M. Goh, “Video corpus moment retrieval with contrastive learning,” in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2021, p. 685–695
2021
-
[50]
Multivariable functional interpolation and adaptive networks,
D. Lowe and D. Broomhead, “Multivariable functional interpolation and adaptive networks,”Complex Systems, vol. 2, no. 3, pp. 321–355, 1988
1988
-
[51]
Cross-modal dynamic networks for video moment retrieval with text query,
G. Wang, X. Xu, F. Shen, H. Lu, Y . Ji, and H. T. Shen, “Cross-modal dynamic networks for video moment retrieval with text query,”IEEE Transactions on Multimedia, vol. 24, pp. 1221–1232, 2022
2022
-
[52]
Memory-efficient temporal moment localization in long videos,
C. Rodriguez-Opazo, E. Marrese-Taylor, B. Fernando, H. Takamura, and Q. Wu, “Memory-efficient temporal moment localization in long videos,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, 2023, pp. 1909–1924
2023
-
[53]
Progressive localization networks for language-based moment localization,
Q. Zheng, J. Dong, X. Qu, X. Yang, Y . Wang, P. Zhou, B. Liu, and X. Wang, “Progressive localization networks for language-based moment localization,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 19, no. 2, pp. 1–21, 2023
2023
-
[54]
R2-tuning: Efficient image-to-video transfer learning for video tem- poral grounding,
Y . Liu, J. He, W. Li, J. Kim, D. Wei, H. Pfister, and C. W. Chen, “R2-tuning: Efficient image-to-video transfer learning for video tem- poral grounding,” inProceedings of the 18th European Conference on Computer Vision, Part XLI, 2024, pp. 421–438
2024
-
[55]
Number It: Temporal grounding videos like flipping manga,
Y . Wu, X. Hu, Y . Sun, Y . Zhou, W. Zhu, F. Rao, B. Schiele, and X. Yang, “Number It: Temporal grounding videos like flipping manga,” inProceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 13 754–13 765
2025
-
[56]
Context-enhanced video moment retrieval with large language models,
W. Liu, B. Miao, J. Cao, X. Zhu, J. Ge, B. Liu, M. Nasim, and A. Mian, “Context-enhanced video moment retrieval with large language models,” IEEE Transactions on Multimedia, vol. 27, pp. 6296–6306, 2025. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. X, AUGUST XXXX 11
2025
-
[57]
Efficient pre-trained semantics re- finement for video temporal grounding,
A. Li, H. Liu, Y . Zhu, and Y . Ge, “Efficient pre-trained semantics re- finement for video temporal grounding,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 2, pp. 1406–1418, 2026
2026
-
[58]
Progressive dynamic interaction network with audio supplement for video moment localization,
G. Wu, Z. Yang, and J. Zhang, “Progressive dynamic interaction network with audio supplement for video moment localization,”IEEE Internet of Things Journal, vol. 12, no. 24, pp. 53 108–53 120, 2025
2025
-
[59]
Adam: A method for stochastic optimiza- tion,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,” inProceedings of the 3rd International Conference on Learning Representations, 2015, pp. 1–15
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.