Recognition: unknown
Eliminating Hidden Serialization in Multi-Node Megakernel Communication
Pith reviewed 2026-05-09 18:32 UTC · model grok-4.3
The pith
Hidden serialization from per-tile fences in proxy RDMA regresses multi-node megakernel MoE performance by up to 10x; Perseus removes it via decoupled signaling and NIC-side ordering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
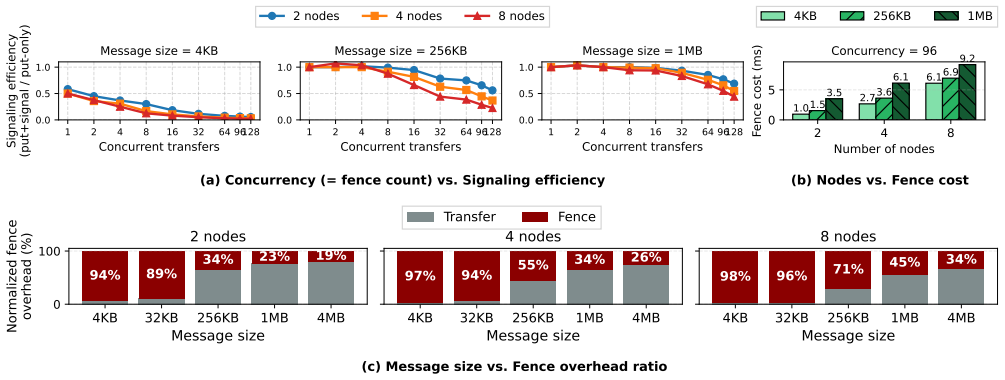
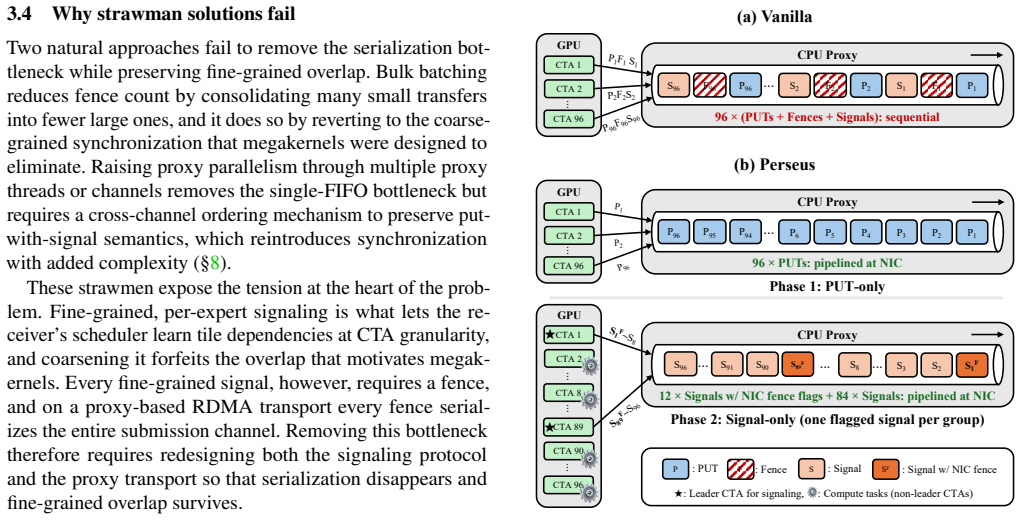
The paper establishes that the strict ordering between each tile's data transfer and its completion signal in proxy RDMA forces a fence that serializes concurrent transfers and grows costly with their number. Perseus counters this through decoupled signaling, which batches fences per destination, and NIC-side ordering, which moves enforcement to hardware fence flags on the NIC. As a result, communication-bound MoE models no longer place inflated network latency on the critical path, restoring the tile-granularity overlap benefit across nodes.
What carries the argument
Decoupled signaling (batching fences at per-destination granularity) combined with NIC-side ordering (replacing proxy stalls with hardware fence flags).
If this is right
- Communication-bound MoE models regain the ability to hide tile transfers behind compute even when experts span multiple nodes.
- Proxy-based RDMA transports become competitive with GPU-direct methods without requiring specialized hardware.
- Performance no longer degrades with increasing node count for models whose per-expert compute cannot absorb extra latency.
- The transport choice is no longer the primary limiter; software handling of ordering determines whether megakernel overlap succeeds at scale.
Where Pith is reading between the lines
- The same fence-induced serialization may constrain other fine-grained GPU communication patterns that rely on proxy RDMA and per-operation signals.
- NIC hardware support for fence flags could be extended to additional ordering primitives to benefit a wider set of distributed GPU workloads.
- Applying the batching and hardware-flag techniques to non-MoE megakernels or other fused compute-communication kernels could improve multi-node scaling in additional domains.
Load-bearing premise
The assumption that hidden serialization from per-tile completion fences is the dominant general cause of the observed regression across models and node counts rather than interactions with specific network topologies or unmeasured overheads.
What would settle it
An experiment that varies the number of concurrent tile transfers on the same hardware and shows whether end-to-end latency scales directly with fence count before Perseus but not after would confirm or refute that serialization is the binding constraint.
Figures











read the original abstract
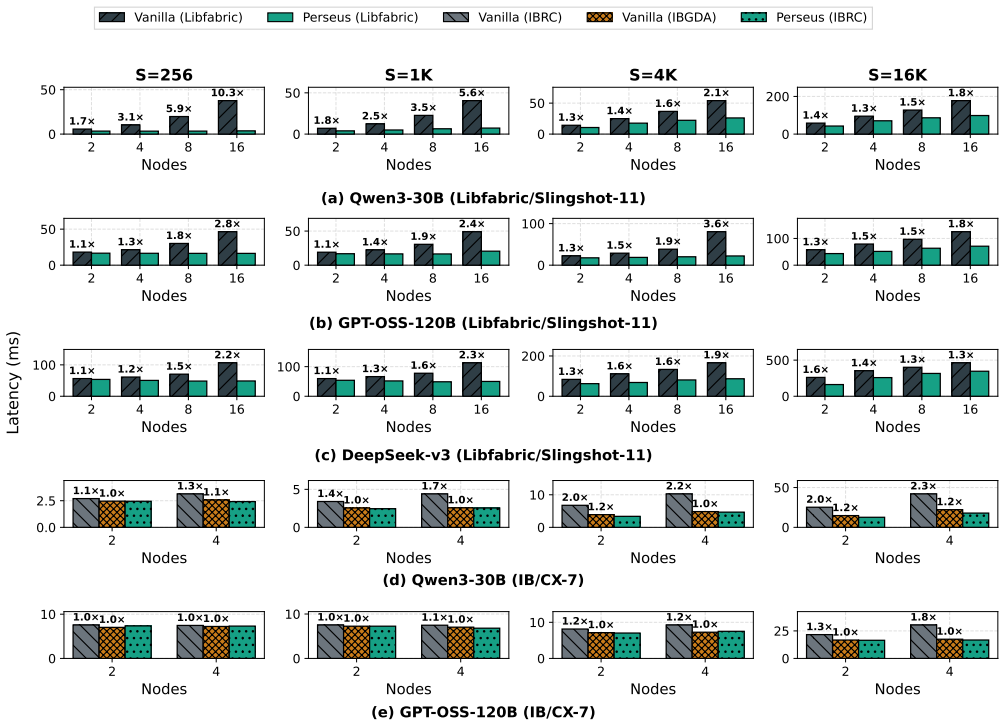
Recent megakernel designs for Mixture-of-Experts (MoE) inference fuse expert computation with fine-grained, GPU-initiated communication into a single persistent GPU kernel, and outperform collective-based MoE on a single node by overlapping data transfer with compute at tile granularity. This benefit does not carry over cleanly to multi-node inference, where experts span many nodes connected by an RDMA fabric. Communication-bound MoE models regress by up to $10\times$ on 8 nodes, and the regression worsens with node count. We trace this regression to hidden serialization in proxy-based RDMA transports. The ordering requirement between each tile transfer and its completion signal forces a fence that drains the NIC pipeline, and its cost grows with the number of concurrent transfers. As a result, models whose per-expert compute is too small to absorb this inflated network latency expose communication on the critical path. We present \emph{Perseus}, which eliminates this serialization through two techniques. \emph{Decoupled signaling} batches fences at per-destination granularity, reducing fence count by $8\times$. \emph{NIC-side ordering} replaces proxy stalls with hardware fence flags, so the proxy never blocks. On proxy-based transports, Perseus achieves up to 10.3$\times$ end-to-end speedup. Perseus on IBRC matches or exceeds IBGDA GPU-direct by up to 1.2$\times$, which shows that serialization, rather than the choice between proxy-based and GPU-direct transport, is what bounds multi-node megakernel performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-node megakernel communication for MoE inference suffers from up to 10× regression due to hidden serialization in proxy-based RDMA transports, specifically from fence operations that drain the NIC pipeline as the number of concurrent transfers increases. Perseus addresses this with decoupled signaling, which batches fences at per-destination granularity reducing their count by 8×, and NIC-side ordering that uses hardware fence flags to avoid proxy blocking. This results in up to 10.3× end-to-end speedup on proxy-based transports, and Perseus on IBRC matching or exceeding IBGDA GPU-direct by up to 1.2×, indicating that serialization is the primary bottleneck rather than the transport choice itself.
Significance. Should the central claims hold after addressing the comments below, the work would be significant for the field of distributed systems and high-performance computing. It offers a practical solution to a performance issue in emerging megakernel designs for large-scale inference, with potential to improve efficiency of MoE models on RDMA-connected clusters. The explicit comparison between proxy and GPU-direct transports, along with the proposed optimizations, provides valuable insights into communication bottlenecks and could influence future designs of GPU-initiated communication primitives.
major comments (2)
- [Abstract] Abstract: The claim that 'serialization, rather than the choice between proxy-based and GPU-direct transport, is what bounds multi-node megakernel performance' is load-bearing for the central thesis. It is supported by the reported 10.3× speedup and 1.2× match/exceed over IBGDA, but the manuscript does not provide ablations or controls that isolate fence-induced serialization from potential confounders such as network topology, concurrent transfer scaling, or megakernel-specific overheads that worsen with node count.
- [Abstract] Abstract: The mechanistic tracing of the regression to per-tile ordering requirements forcing NIC-pipeline-draining fences is plausible, but lacks a quantitative microbenchmark or breakdown (e.g., in the evaluation) showing how fence cost scales with concurrent transfers and accounts for the full 10× regression across models. Without this, the generality of the diagnosis remains under-supported.
minor comments (1)
- The abstract would be clearer if it briefly noted the specific models, node counts, and hardware configurations used for the 10.3× and 1.2× results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback identifies opportunities to better isolate the contribution of serialization and to provide quantitative support for our mechanistic diagnosis. We address each major comment below and will revise the manuscript to incorporate additional evidence where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'serialization, rather than the choice between proxy-based and GPU-direct transport, is what bounds multi-node megakernel performance' is load-bearing for the central thesis. It is supported by the reported 10.3× speedup and 1.2× match/exceed over IBGDA, but the manuscript does not provide ablations or controls that isolate fence-induced serialization from potential confounders such as network topology, concurrent transfer scaling, or megakernel-specific overheads that worsen with node count.
Authors: We agree that additional controls would strengthen isolation of fence-induced serialization from other factors. The existing end-to-end results (10.3× on proxy transports and matching/exceeding IBGDA) already indicate that transport choice is not the primary limiter, but we will add targeted ablations in the revised evaluation. These will fix network topology while varying concurrent transfer count, and separately measure megakernel overheads at different node scales. This will more directly attribute the regression to serialization. revision: partial
-
Referee: [Abstract] Abstract: The mechanistic tracing of the regression to per-tile ordering requirements forcing NIC-pipeline-draining fences is plausible, but lacks a quantitative microbenchmark or breakdown (e.g., in the evaluation) showing how fence cost scales with concurrent transfers and accounts for the full 10× regression across models. Without this, the generality of the diagnosis remains under-supported.
Authors: We concur that a dedicated microbenchmark would better quantify the scaling behavior. In the revised manuscript we will add a microbenchmark in the evaluation section that measures fence latency as a function of concurrent transfers. The new data will show the growth rate and demonstrate its contribution to the observed 10× regression across the evaluated MoE models, thereby supporting the generality of the diagnosis. revision: yes
Circularity Check
No significant circularity; claims rest on implementation and measurements
full rationale
The paper derives its central claim—that hidden serialization from fence drains bounds multi-node megakernel performance—through concrete implementation of Perseus (decoupled signaling and NIC-side ordering) followed by direct end-to-end timing measurements on proxy transports and comparisons to IBGDA. No equations or parameters are defined in terms of the target result and then reused as predictions; no load-bearing uniqueness theorem or ansatz is imported via self-citation; the speedup numbers (10.3×, 1.2×) are reported outcomes rather than fitted inputs renamed as forecasts. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proxy-based RDMA transports enforce per-transfer ordering via fences that drain the NIC pipeline.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt- oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Mooncake EP & Mooncake Back- end
KVCache AI. Mooncake EP & Mooncake Back- end. https://kvcache-ai.github.io/Mooncake/ python-api-reference/ep-backend.html
-
[3]
FlashMoE: Fast Distributed MoE in a Single Ker- nel
Osayamen Jonathan Aimuyo, Byungsoo Oh, and Rachee Singh. FlashMoE: Fast Distributed MoE in a Single Ker- nel. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[4]
ROCm DeepEP
AMD. ROCm DeepEP. https://github.com/ROCm/ DeepEP
-
[5]
ROCm OpenSHMEM (rocSHMEM)
AMD. ROCm OpenSHMEM (rocSHMEM). https: //github.com/ROCm/rocm-systems
-
[6]
Elastic Fabric Adapter
AWS. Elastic Fabric Adapter. https://aws.amazon. com/hpc/efa/
-
[7]
Li-Wen Chang, Wenlei Bao, Qi Hou, Chengquan Jiang, Ningxin Zheng, Yinmin Zhong, Xuanrun Zhang, Zuquan Song, Chengji Yao, Ziheng Jiang, et al. Flux: Fast software-based communication overlap on gpus through kernel fusion.arXiv preprint arXiv:2406.06858, 2024
-
[8]
Introducing openshmem: Shmem for the pgas community
Barbara Chapman, Tony Curtis, Swaroop Pophale, Stephen Poole, Jeff Kuehn, Chuck Koelbel, and Lau- ren Smith. Introducing openshmem: Shmem for the pgas community. InProceedings of the fourth confer- ence on partitioned global address space programming model, pages 1–3, 2010
2010
- [9]
-
[10]
NVIDIA Collective Communica- tions Library (NCCL)
NVIDIA Corporation. NVIDIA Collective Communica- tions Library (NCCL). https://developer.nvidia. com/nccl
-
[11]
Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems (NeurIPS 22), 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems (NeurIPS 22), 35:16344–16359, 2022
2022
-
[12]
An in-depth analysis of the slingshot interconnect
Daniele De Sensi, Salvatore Di Girolamo, Kim H McMa- hon, Duncan Roweth, and Torsten Hoefler. An in-depth analysis of the slingshot interconnect. InInternational Conference for High Performance Computing, Network- ing, Storage and Analysis (SC 20), pages 1–14, 2020
2020
-
[13]
Amos Goldman, Nimrod Boker, Maayan Sheraizin, Nim- rod Admoni, Artem Polyakov, Subhadeep Bhattacharya, Fan Yu, Kai Sun, Georgios Theodorakis, Hsin-Chun Yin, et al. NCCL EP: Towards a Unified Expert Par- allel Communication API for NCCL.arXiv preprint arXiv:2603.13606, 2026
-
[14]
A brief introduction to the openfabrics interfaces-a new network api for maximizing high per- formance application efficiency
Paul Grun, Sean Hefty, Sayantan Sur, David Goodell, Robert D Russell, Howard Pritchard, and Jeffrey M Squyres. A brief introduction to the openfabrics interfaces-a new network api for maximizing high per- formance application efficiency. In2015 IEEE 23rd Annual Symposium on High-Performance Interconnects (HOTI 15), pages 34–39, 2015
2015
-
[15]
GPU-Initiated Networking for NCCL.arXiv preprint arXiv:2511.15076, 2025
Khaled Hamidouche, John Bachan, Pak Markthub, Peter- Jan Gootzen, Elena Agostini, Sylvain Jeaugey, Aamir Shafi, Georgios Theodorakis, and Manjunath Gorentla Venkata. GPU-Initiated Networking for NCCL.arXiv preprint arXiv:2511.15076, 2025
-
[16]
Fastermoe: modeling and optimizing training of large-scale dy- namic pre-trained models
Jiaao He, Jidong Zhai, Tiago Antunes, Haojie Wang, Fuwen Luo, Shangfeng Shi, and Qin Li. Fastermoe: modeling and optimizing training of large-scale dy- namic pre-trained models. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 22), pages 120–134, 2022
2022
-
[17]
The communication challenge for MPP: Intel Paragon and Meiko CS-2.Parallel comput- ing, 20(3):389–398, 1994
Roger W Hockney. The communication challenge for MPP: Intel Paragon and Meiko CS-2.Parallel comput- ing, 20(3):389–398, 1994
1994
-
[18]
Flashoverlap: A lightweight design for efficiently over- lapping communication and computation
Ke Hong, Xiuhong Li, Minxu Liu, Qiuli Mao, Tianqi Wu, Zixiao Huang, Lufang Chen, Zhong Wang, Yi- chong Zhang, Zhenhua Zhu, Guohao Dai, and Yu Wang. Flashoverlap: A lightweight design for efficiently over- lapping communication and computation. InProceed- ings of the Twenty-First European Conference on Com- puter Systems (EuroSys ’26), 2026
2026
-
[19]
Msccl++: Rethinking gpu communication abstractions for ai inference
Changho Hwang, Peng Cheng, Roshan Dathathri, Ab- hinav Jangda, Saeed Maleki, Madan Musuvathi, Olli Saarikivi, Aashaka Shah, Ziyue Yang, Binyang Li, et al. Msccl++: Rethinking gpu communication abstractions for ai inference. InProceedings of the 31st ACM Inter- national Conference on Architectural Support for Pro- gramming Languages and Operating Systems (...
2026
-
[20]
Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems (MLSys 23), 5:269–287, 2023
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al. Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems (MLSys 23), 5:269–287, 2023
2023
-
[21]
Lancet: Accelerating mixture- of-experts training via whole graph computation- communication overlapping.Proceedings of Machine Learning and Systems (MLSys 24), 6:74–86, 2024
Chenyu Jiang, Ye Tian, Zhen Jia, Shuai Zheng, Chuan Wu, and Yida Wang. Lancet: Accelerating mixture- of-experts training via whole graph computation- communication overlapping.Proceedings of Machine Learning and Systems (MLSys 24), 6:74–86, 2024
2024
-
[22]
Chao Jin, Ziheng Jiang, Zhihao Bai, Zheng Zhong, Jun- cai Liu, Xiang Li, Ningxin Zheng, Xi Wang, Cong Xie, Qi Huang, et al. Megascale-moe: Large-scale communication-efficient training of mixture-of-experts models in production.arXiv preprint arXiv:2505.11432, 2025
-
[23]
Efficient memory man- agement for large language model serving with page- dattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP 23), pages 611– 626, 2023
2023
-
[24]
GShard: Scaling gi- ant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling gi- ant models with conditional computation and automatic sharding. InInternational Conference on Learning Rep- resentations (ICLR), 2021
2021
-
[25]
Eval- uating modern gpu interconnect: Pcie, nvlink, nv-sli, nvswitch and gpudirect.IEEE Transactions on Parallel and Distributed Systems, 31(1):94–110, 2019
Ang Li, Shuaiwen Leon Song, Jieyang Chen, Jiajia Li, Xu Liu, Nathan R Tallent, and Kevin J Barker. Eval- uating modern gpu interconnect: Pcie, nvlink, nv-sli, nvswitch and gpudirect.IEEE Transactions on Parallel and Distributed Systems, 31(1):94–110, 2019
2019
-
[26]
Accelerating distributed {MoE} training and inference with lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Accelerating distributed {MoE} training and inference with lina. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 945–959, 2023
2023
-
[27]
fabric-lib: RDMA Point-to-Point Communication for LLM Systems
Nandor Licker, Kevin Hu, Vladimir Zaytsev, and Lequn Chen. RDMA Point-to-Point Communication for LLM Systems.arXiv preprint arXiv:2510.27656, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 tech- nical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Janus: A unified distributed training framework for sparse mixture-of-experts models
Juncai Liu, Jessie Hui Wang, and Yimin Jiang. Janus: A unified distributed training framework for sparse mixture-of-experts models. InProceedings of the ACM SIGCOMM 2023 Conference, pages 486–498, 2023
2023
-
[30]
ibv_wr_rdma_write_imm (IBV_WR API)
Linux manual. ibv_wr_rdma_write_imm (IBV_WR API). https://man7.org/linux/man-pages/man3/ ibv_wr_rdma_write_imm.3.html
-
[31]
UCCL-EP: Portable Expert-Parallel Communication.arXiv preprint arXiv:2512.19849, 2025
Ziming Mao, Yihan Zhang, Chihan Cui, Zhen Huang, Kaichao You, Zhongjie Chen, Zhiying Xu, Zhenyu Gu, Scott Shenker, Costin Raiciu, et al. UCCL-EP: Portable Expert-Parallel Communication.arXiv preprint arXiv:2512.19849, 2025
-
[32]
Improving Network Perfor- mance of HPC Systems Using NVIDIA Mag- num IO NVSHMEM and GPUDirect Async
Pak Markthub, Jim Dinan, Sreeram Potluri, and Seth Howell. Improving Network Perfor- mance of HPC Systems Using NVIDIA Mag- num IO NVSHMEM and GPUDirect Async. https://developer.nvidia.com/blog/improving-network- performance-of-hpc-systems-using-nvidia-magnum-io- nvshmem-and-gpudirect-async/, 2022
2022
-
[33]
Hugging Face model card: Llama-4-Scout- 17B-16E
Meta. Hugging Face model card: Llama-4-Scout- 17B-16E. https://huggingface.co/meta-llama/ Llama-4-Scout-17B-16E, 2025
2025
-
[34]
Perlmutter
National Energy Research Scientific Computing Cen- ter. Perlmutter. https://docs.nersc.gov/systems/ perlmutter/architecture/
-
[35]
ConnectX NICs
NVIDIA. ConnectX NICs. https://www.nvidia. com/en-us/networking/ethernet-adapters/
-
[36]
GPUDirect RDMA
NVIDIA. GPUDirect RDMA. https://docs.nvidia. com/cuda/gpudirect-rdma/, 2024
2024
-
[37]
Scaling Large MoE Models with Wide Expert Parallelism on NVL72 Rack Scale Systems
NVIDIA. Scaling Large MoE Models with Wide Expert Parallelism on NVL72 Rack Scale Systems. https://developer.nvidia.com/blog/scaling-large-moe- models-with-wide-expert-parallelism-on-nvl72-rack- scale-systems/, 2025
2025
-
[38]
NVIDIA OpenSHMEM Li- brary (NVSHMEM)
NVIDIA Corporation. NVIDIA OpenSHMEM Li- brary (NVSHMEM). https://github.com/NVIDIA/ nvshmem
-
[39]
PyTorch: An imperative style, high- performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Al- ban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high- ...
2019
-
[40]
T3: Transparent tracking & triggering for fine-grained overlap of com- pute & collectives
Suchita Pati, Shaizeen Aga, Mahzabeen Islam, Nuwan Jayasena, and Matthew D Sinclair. T3: Transparent tracking & triggering for fine-grained overlap of com- pute & collectives. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol- ume 2, pages 1146–1164, 2024. 14
2024
-
[41]
Optimizing distributed ml communi- cation with fused computation-collective operations
Kishore Punniyamurthy, Khaled Hamidouche, and Brad- ford M Beckmann. Optimizing distributed ml communi- cation with fused computation-collective operations. In International Conference for High Performance Com- puting, Networking, Storage and Analysis (SC 24), pages 1–17, 2024
2024
-
[42]
PyTorch Symmetric Memory
PyTorch. PyTorch Symmetric Memory. https://docs.pytorch.org/docs/stable/ symmetric_memory.html
-
[43]
Chimera: Communication fusion for hybrid parallelism in large language models
Le Qin, Junwei Cui, Weilin Cai, and Jiayi Huang. Chimera: Communication fusion for hybrid parallelism in large language models. InProceedings of the 52nd Annual International Symposium on Computer Architec- ture (ISCA 25), pages 498–513, 2025
2025
-
[44]
DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Min- jia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale. InInternational Confer- ence on Machine Learning (ICML), pages 18332–18346, 2022
2022
-
[45]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Schemoe: An extensible mixture-of-experts distributed training system with tasks scheduling
Shaohuai Shi, Xinglin Pan, Qiang Wang, Chengjian Liu, Xiaozhe Ren, Zhongzhe Hu, Yu Yang, Bo Li, and Xi- aowen Chu. Schemoe: An extensible mixture-of-experts distributed training system with tasks scheduling. In Proceedings of the Nineteenth European Conference on Computer Systems (EuroSys 24), pages 236–249, 2024
2024
-
[47]
Collective Communication for 100k+ GPUs
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, et al. Collec- tive communication for 100k+ GPUs.arXiv preprint arXiv:2510.20171, 2025
-
[48]
Designing a Low-Latency Megakernel for Llama- 1B
Benjamin Spector, Jordan Juravsky, Stuart Sul, Owen Dugan, Dylan Lim, Dan Fu, Simran Arora, and Chris Ré. Designing a Low-Latency Megakernel for Llama- 1B. https://hazyresearch.stanford.edu/blog/ 2025-05-27-no-bubbles, 2025
2025
-
[49]
Stuart H Sul, Simran Arora, Benjamin F Spector, and Christopher Ré. ParallelKittens: Systematic and Prac- tical Simplification of Multi-GPU AI Kernels.arXiv preprint arXiv:2511.13940, 2025
-
[50]
The Landscape of GPU-Centric Communication
Didem Unat, Ilyas Turimbetov, Mohammed Kefah Taha Issa, Do˘gan Sa˘gbili, Flavio Vella, Daniele De Sensi, and Ismayil Ismayilov. The landscape of gpu-centric com- munication.arXiv preprint arXiv:2409.09874, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[52]
Scalable training of mixture-of-experts models with megatron core.arXiv preprint arXiv:2603.07685,
Zijie Yan, Hongxiao Bai, Xin Yao, Dennis Liu, Tong Liu, Hongbin Liu, Pingtian Li, Evan Wu, Shiqing Fan, Li Tao, et al. Scalable training of mixture-of-experts models with megatron core.arXiv preprint arXiv:2603.07685, 2026
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Optimizing Communica- tion for Mixture-of-Experts Training with Hybrid Expert Parallel
Fan Yu, Tong Liu, and Kai Sun. Optimizing Communica- tion for Mixture-of-Experts Training with Hybrid Expert Parallel. https://developer.nvidia.com/blog/optimizing- communication-for-mixture-of-experts-training-with- hybrid-expert-parallel/, 2026
2026
-
[55]
Comet: Fine-grained computation-communication overlapping for mixture- of-experts.Proceedings of Machine Learning and Sys- tems (MLSys 25), 7, 2025
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wenlei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li-Wen Chang, et al. Comet: Fine-grained computation-communication overlapping for mixture- of-experts.Proceedings of Machine Learning and Sys- tems (MLSys 25), 7, 2025
2025
-
[56]
DeepEP: an efficient expert- parallel communication library
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Ji- ashi Li, and Liang Zhao. DeepEP: an efficient expert- parallel communication library. https://github. com/deepseek-ai/DeepEP, 2025
2025
-
[57]
Sglang: Efficient execution of structured language model pro- grams.Advances in Neural Information Processing Systems (NeurIPS 24), 37:62557–62583, 2024
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model pro- grams.Advances in Neural Information Processing Systems (NeurIPS 24), 37:62557–62583, 2024
2024
-
[58]
Size Zheng, Wenlei Bao, Qi Hou, Xuegui Zheng, Jin Fang, Chenhui Huang, Tianqi Li, Haojie Duanmu, Renze Chen, Ruifan Xu, et al. Triton-distributed: Programming overlapping kernels on distributed ai systems with the triton compiler.arXiv preprint arXiv:2504.19442, 2025
-
[59]
Tilelink: Generating effi- cient compute-communication overlapping kernels us- ing tile-centric primitives.Proceedings of Machine Learning and Systems (MLSys 25), 7, 2025
Size Zheng, Jin Fang, Xuegui Zheng, Qi Hou, Wenlei Bao, Ningxin Zheng, Ziheng Jiang, Dongyang Wang, Jianxi Ye, Haibin Lin, et al. Tilelink: Generating effi- cient compute-communication overlapping kernels us- ing tile-centric primitives.Proceedings of Machine Learning and Systems (MLSys 25), 7, 2025. 15
2025
-
[60]
Megascale-infer: Efficient mixture-of-experts model serving with disag- gregated expert parallelism
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Ce- sar A Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, et al. Megascale-infer: Efficient mixture-of-experts model serving with disag- gregated expert parallelism. InProceedings of the ACM SIGCOMM 2025 Conference, pages 592–608, 2025
2025
-
[61]
Ravenio books, 2016
George Kingsley Zipf.Human behavior and the prin- ciple of least effort: An introduction to human ecology. Ravenio books, 2016. Appendix Aα-βanalysis: latency decomposition 0 20 Overhead (ms) 20 40 Transfer Cost (ms/MB) 2 4 8 16 Nodes 20 40 2 4 8 16 Nodes 20 30 (a) Qwen3-30B (b) GPT-OSS-120B Vanilla Perseus Figure 15: Latency decomposition into overhead (...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.