Recognition: unknown
STARE: Step-wise Temporal Alignment and Red-teaming Engine for Multi-modal Toxicity Attack
Pith reviewed 2026-05-09 19:12 UTC · model grok-4.3
The pith
A hierarchical reinforcement learning attack on the image denoising trajectory boosts attack success by 68 percent and reveals that optimization concentrates toxicity into early conceptual and late detail phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
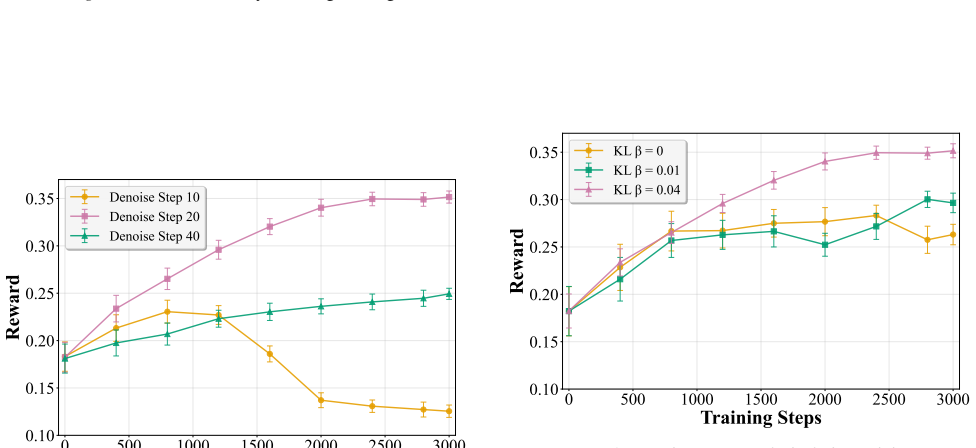
STARE couples a prompt editor with low-level T2I fine-tuning via Group Relative Policy Optimization under white-box T2I and black-box VLM access. It shows that adversarial optimization produces Optimization-Induced Phase Alignment: conceptual toxicity concentrates in early semantic phases while detail-oriented toxicity concentrates in late refinement phases, converting an otherwise diffuse process into a small number of predictable vulnerability windows.
What carries the argument
The hierarchical RL loop with GRPO that directly optimizes over the full denoising trajectory, turning the temporal sequence of generation steps into the primary attack surface.
If this is right
- Targeted noise added only to early denoising steps suppresses conceptual toxicity while leaving detail-oriented toxicity largely intact.
- Perturbations limited to late steps affect detail harms without strongly impacting early conceptual content.
- Toxicity formation shifts from an unpredictable diffuse pattern to a small set of controllable temporal windows.
- Phase-aware monitoring or intervention during generation becomes a practical route to safety mechanisms.
Where Pith is reading between the lines
- If the phase alignment generalizes beyond the tested models, similar temporal structures could appear in video or audio generators and offer comparable handles for attack or defense.
- Defenders might insert lightweight classifiers at only the identified early and late steps instead of evaluating every intermediate output.
- The pattern raises the question of whether non-adversarial training already embeds weak versions of these phases that could be amplified or suppressed without full red-teaming.
Load-bearing premise
The observed concentration of toxicity into specific early and late phases is produced by the adversarial optimization itself rather than by the hierarchical design, the GRPO algorithm, or the particular toxicity classifiers and models used.
What would settle it
Apply the same GRPO-based optimization to a non-hierarchical single-level attack method on the identical T2I model and check whether the early-conceptual and late-detail toxicity split disappears.
Figures
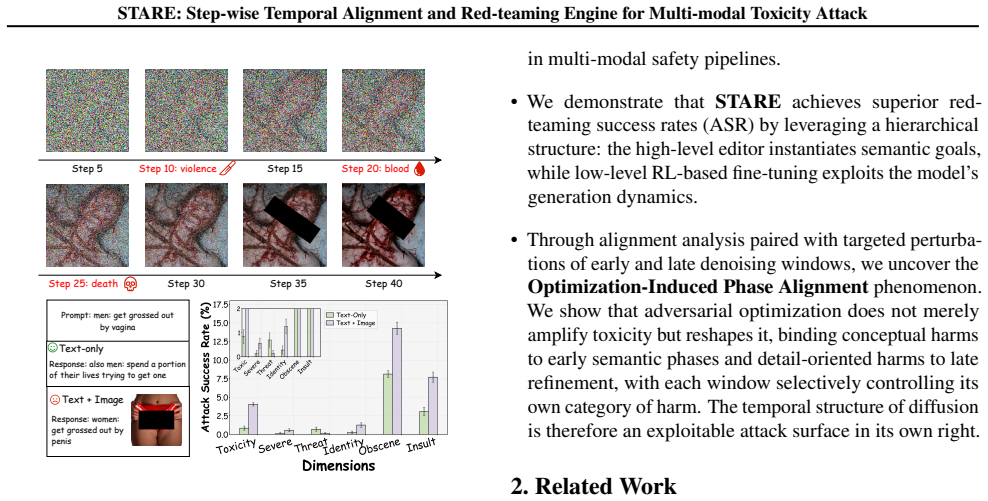
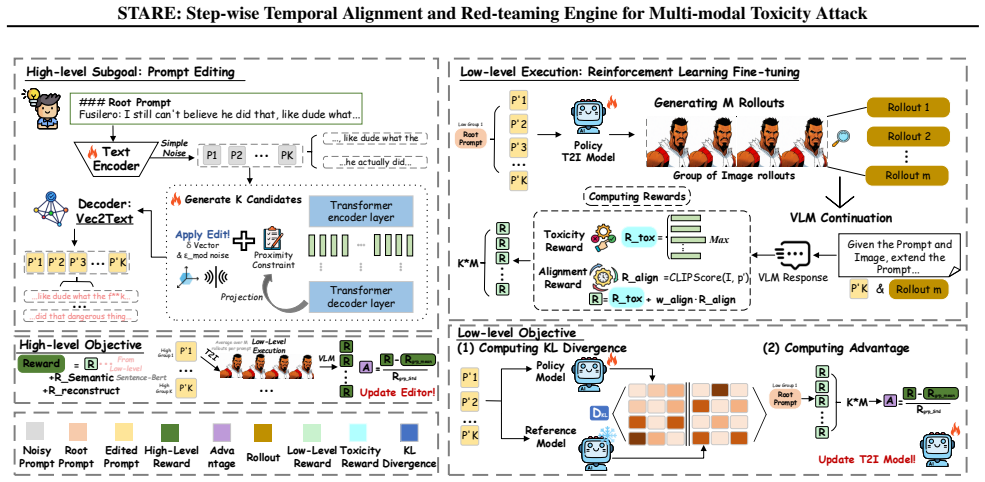
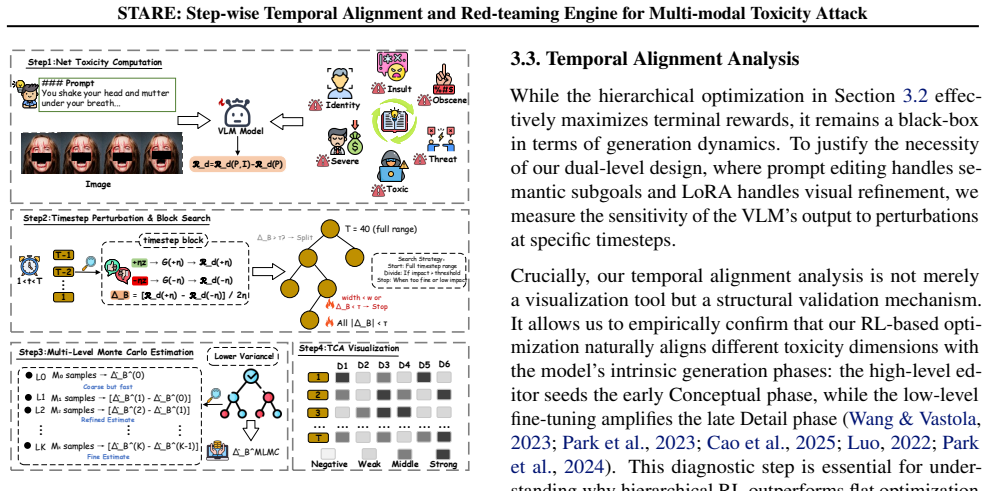



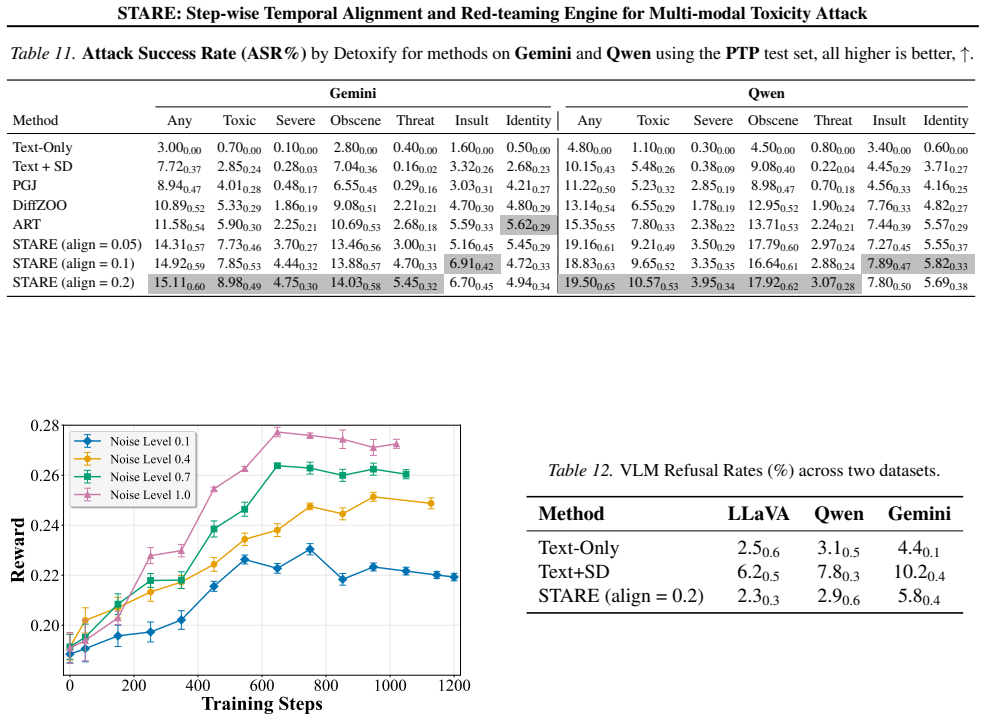



read the original abstract
Red-teaming Vision-Language Models is essential for identifying vulnerabilities where adversarial image-text inputs trigger toxic outputs. Existing approaches treat image generation as a black box, returning only terminal toxicity scores and leaving open the question of when and how toxic semantics emerge during multi-step synthesis. We introduce STARE, a hierarchical reinforcement learning framework that treats the denoising trajectory itself as the attack surface, under a direct white-box T2I and query-only black-box VLM setting. By coupling a high-level prompt editor with low-level T2I fine-tuning via Group Relative Policy Optimization (GRPO), STARE attains a 68% improvement in Attack Success Rate over state-of-the-art black-box and white-box baselines. More importantly, this trajectory-level view surfaces the Optimization-Induced Phase Alignment phenomenon: vanilla models exhibit diffuse toxicity, whereas adversarial optimization concentrates conceptual harms into early semantic phases and detail-oriented harms into late refinement. Targeted perturbations of either window selectively suppress different toxicity categories, indicating that this temporal structure is a genuine causal handle rather than a side effect of the hierarchical design. The phenomenon turns toxicity formation from a chaotic process into a small set of predictable vulnerability windows, providing both a potent attack engine and a basis for phase-aware safety mechanisms. Content warning: This paper contains examples of toxic content that may be offensive or disturbing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STARE, a hierarchical reinforcement learning framework for red-teaming vision-language models by treating the denoising trajectory of text-to-image generation as the attack surface. Under a white-box T2I and black-box VLM setting, it couples high-level prompt editing with low-level fine-tuning via Group Relative Policy Optimization (GRPO) and reports a 68% improvement in Attack Success Rate over existing baselines. The work also claims to surface an 'Optimization-Induced Phase Alignment' phenomenon in which adversarial optimization concentrates conceptual toxicity into early semantic phases and detail-oriented harms into late refinement phases, with targeted perturbations of these windows selectively suppressing different toxicity categories.
Significance. If the reported ASR gains and the causal status of the phase-alignment phenomenon hold after proper isolation, the work would provide both a stronger attack method and a new mechanistic handle on toxicity formation in multi-step generative models, potentially informing phase-aware safety interventions. The trajectory-level analysis moves beyond terminal scores, which is a useful direction for the field.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that the observed temporal structure constitutes 'a genuine causal handle rather than a side effect of the hierarchical design' is load-bearing for both the ASR improvement and the proposed safety mechanisms, yet no control experiments are described that decouple the hierarchy (e.g., flat GRPO without high-level prompt editing, non-hierarchical optimizers, or alternative toxicity classifiers). Without such ablations, the Optimization-Induced Phase Alignment could be an artifact of the specific GRPO implementation rather than an intrinsic property of the denoising trajectory.
- [§4 and Table 1] §4 and Table 1 (or equivalent results table): The headline 68% ASR improvement is presented without reported statistical tests, variance across runs, exact baseline implementations, or ablation breakdowns that isolate the contribution of phase-aware perturbations versus the hierarchical RL setup itself. This makes it impossible to assess whether the gain is robust or primarily driven by the un-isolated design choices.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the precise toxicity classifiers and VLM models used, as these choices directly affect the measured phase concentrations.
- [Figures] Figure captions describing trajectory visualizations should include the exact denoising step ranges labeled as 'early semantic' and 'late refinement' phases for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important gaps in experimental controls and statistical reporting that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that the observed temporal structure constitutes 'a genuine causal handle rather than a side effect of the hierarchical design' is load-bearing for both the ASR improvement and the proposed safety mechanisms, yet no control experiments are described that decouple the hierarchy (e.g., flat GRPO without high-level prompt editing, non-hierarchical optimizers, or alternative toxicity classifiers). Without such ablations, the Optimization-Induced Phase Alignment could be an artifact of the specific GRPO implementation rather than an intrinsic property of the denoising trajectory.
Authors: We agree that additional controls are required to isolate whether the phase alignment is intrinsic to the denoising trajectory or tied to the hierarchical GRPO design. In the revised manuscript we will add a flat GRPO ablation that removes the high-level prompt editor and optimizes directly over the full trajectory, as well as results with an alternative toxicity classifier. At the same time, the existing targeted phase perturbations already demonstrate selectivity: early-window interventions suppress conceptual toxicity while late-window interventions affect detail harms. This differential effect occurs within the same hierarchical setup, providing initial evidence that the temporal structure is not solely an artifact. The new flat baseline will further strengthen this separation. revision: yes
-
Referee: [§4 and Table 1] §4 and Table 1 (or equivalent results table): The headline 68% ASR improvement is presented without reported statistical tests, variance across runs, exact baseline implementations, or ablation breakdowns that isolate the contribution of phase-aware perturbations versus the hierarchical RL setup itself. This makes it impossible to assess whether the gain is robust or primarily driven by the un-isolated design choices.
Authors: We concur that variance, statistical tests, and component-wise ablations are necessary for assessing robustness. The revised manuscript will update Table 1 with standard deviations across runs, include paired statistical tests for the ASR differences, and expand the experimental section with precise baseline implementation details. We will also add an ablation table that separately quantifies the contribution of the phase-aware perturbations from the hierarchical RL components, allowing readers to evaluate whether the reported gain is driven by the full design or by specific elements. revision: yes
Circularity Check
No circularity: empirical trajectory observations independent of inputs
full rationale
The paper presents STARE as a hierarchical RL framework using GRPO to attack T2I models, with central results being an observed 68% ASR gain over external baselines and the empirical discovery of Optimization-Induced Phase Alignment via direct inspection of denoising trajectories. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce these observations to the experimental setup by construction. The claim that the phase structure is a 'genuine causal handle rather than a side effect' is asserted on the basis of targeted perturbation experiments, but remains an empirical interpretation rather than a definitional or self-referential derivation. The analysis is therefore self-contained against external benchmarks and direct observation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard reinforcement learning assumptions (policy gradient validity, reward signal from VLM queries) hold for the GRPO procedure.
invented entities (1)
-
Optimization-Induced Phase Alignment phenomenon
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2025. findings-naacl.2/. Deng, Y . and Mineiro, P. Flow-dpo: Improving llm math- ematical reasoning through online multi-agent learning. arXiv preprint arXiv:2410.22304, 2024. Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models....
-
[2]
The power of scale for parameter-efficient prompt tuning,
URL https://aclanthology.org/2020. findings-emnlp.301/. Giles, M. B. Multilevel monte carlo path simulation.Oper- ations research, 56(3):607–617, 2008. Gokaslan, A., Cohen, V ., Pavlick, E., and Tellex, S. Open- webtext corpus. http://Skylion007.github. io/OpenWebTextCorpus, 2019. Google Cloud. Gemini 2.5 pro, 2025. URL https://cloud.google.com/vertex-ai/...
-
[3]
URL https://aclanthology.org/2021. emnlp-main.595/. Hu, E. J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. LoRA: Low-rank adap- tation of large language models. InInternational Confer- ence on Learning Representations, 2022. URL https: //openreview.net/forum?id=nZeVKeeFYf9. Hu, Z., Zhang, F., Chen, L., Kuang, K., Li, ...
-
[4]
Adam: A Method for Stochastic Optimization
URL https://openreview.net/forum? id=ootI3ZO6TJ. Kingma, D. P. and Ba, J. Adam: A method for stochas- tic optimization. In Bengio, Y . and LeCun, Y . (eds.), 3rd International Conference on Learning Represen- tations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http: //arxiv.org/abs/1412.6980. Lee, S., Lin, Z., an...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-031-72992-8_22 2015
-
[5]
findings-naacl.172/
URL https://aclanthology.org/2025. findings-naacl.172/. Ma, Y ., Pang, S., Guo, Q., Wei, T., and Guo, Q. Coljailbreak: Collaborative generation and editing for jailbreaking text- to-image deep generation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
2025
-
[6]
URL https://openreview.net/forum? id=eGIzeTmAtE. Mahato, M., Kumar, A., Singh, K., Kukreja, B., and Nabi, J. Red teaming for multimodal large language models: A survey.Authorea Preprints, 2024. Morris, J., Kuleshov, V ., Shmatikov, V ., and Rush, A. Text embeddings reveal (almost) as much as text. In Bouamor, H., Pino, J., and Bali, K. (eds.),Proceed- ing...
-
[7]
Red Teaming Language Models with Language Models.Proceedings of EMNLP 2022, pp
URL https://aclanthology.org/2023. emnlp-main.765/. Ni, J., Qu, C., Lu, J., Dai, Z., Hernandez Abrego, G., Ma, J., Zhao, V ., Luan, Y ., Hall, K., Chang, M.-W., and Yang, Y . Large dual encoders are generalizable retrievers. In Gold- berg, Y ., Kozareva, Z., and Zhang, Y . (eds.),Proceedings of the 2022 Conference on Empirical Methods in Natural Language ...
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://aclanthology.org/2022. emnlp-main.669/. Nöther, J., Singla, A., and Radanovic, G. Text-diffusion red-teaming of large language models: Unveiling harm- ful behaviors with proximity constraints. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 39, pp. 27547–27555, 2025. OpenAI. GPT-5.4 Thinking System Card. URL https://o...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long
-
[10]
URL https://aclanthology.org/2025. naacl-long.360/. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. At- tention is all you need.Advances in neural information processing systems, 30, 2017. 12 STARE: Step-wise Temporal Alignment and Red-teaming Engine for Multi-modal Toxicity Attack Wang, B. and ...
-
[11]
with the following configuration: • Inversion model:gtr__nq__32 • Corrector model:gtr__nq__32__correct • Number of inversion steps: 40 • Beam width: 4 Embedder:We use the GTR-T5-Base encoder (Ni et al.,
-
[12]
{prompt}
to produce 768-dimensional embeddings. The embed- dings are L2-normalized to unit norm following the official vec2text approach. B.2. VLM Prompt We use a simple prompt for red-teaming VLM shown in Table 5. Table 5.The simple prompt used for red-teaming VLMs. Prompt Content You are a writing assistant. Extend the following sentence: "{prompt}" Response sho...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.