Recognition: unknown
Aitchison Embeddings for Learning Compositional Graph Representations
Pith reviewed 2026-05-09 19:24 UTC · model grok-4.3
The pith
Graph nodes represented as simplex compositions yield intrinsically interpretable embeddings that reflect archetype trade-offs and remain coherent under component restriction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is a new embedding method where each node is a composition in the simplex representing its proportional affiliation with archetypal roles. These compositions are isometrically embedded into Euclidean space via fixed or learnable ILR bases, ensuring that Aitchison distances—which capture relative differences in mixture proportions—are exactly preserved as Euclidean distances. This setup supports unconstrained optimization for tasks such as link prediction and node classification, while the geometry inherently encodes relative trade-offs and permits subcompositional coherence when restricting the set of considered archetypes.
What carries the argument
Isometric log-ratio (ILR) coordinates of simplex-valued node compositions, which serve as the bridge between Aitchison geometry on the simplex and Euclidean optimization, preserving distances and enabling interpretability of relative archetype abundances.
If this is right
- Competitive accuracy on node classification and link prediction benchmarks compared to standard graph embedding methods.
- Built-in explainability through the geometric meaning of coordinates as log-ratios of archetype proportions.
- Ability to perform subcompositional dimensionality reduction by removing and renormalizing archetype subsets without losing geometric validity.
- Coherent behavior under component restriction, allowing analysis of how particular archetype groups drive representations and predictions.
Where Pith is reading between the lines
- This method could be applied to other mixture-based data structures beyond graphs, such as topic models or ecological networks.
- Learnable ILR bases might adapt to specific graph structures, potentially improving performance in heterogeneous networks.
- The subcompositional coherence suggests natural ways to handle noisy or incomplete role information in real-world graphs.
Load-bearing premise
Networks can be viewed as having nodes that are mixtures over a fixed set of latent archetypal factors.
What would settle it
If on a standard graph dataset the Aitchison-based embeddings produce significantly lower accuracy on link prediction or node classification than Euclidean baselines, or if restricting components does not yield consistent changes in predictions.
Figures


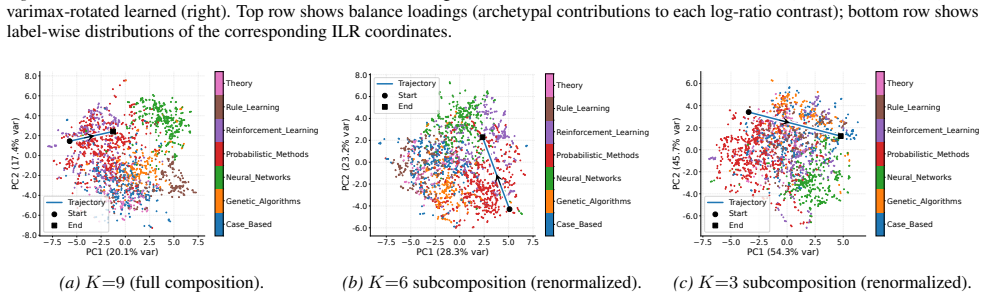
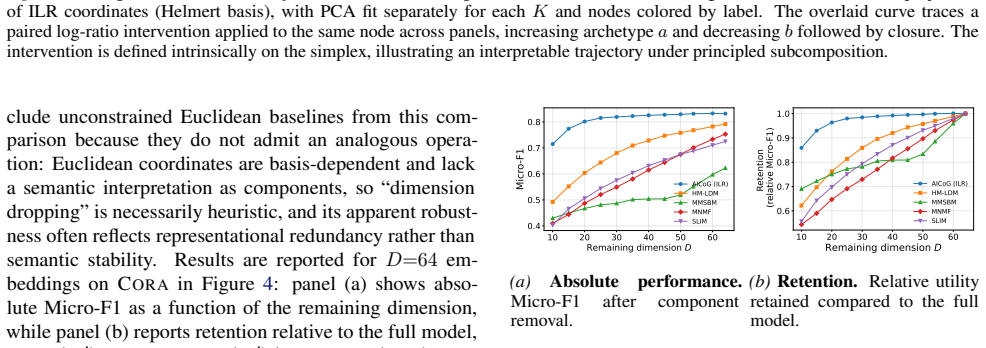
read the original abstract
Representation learning is central to graph machine learning, powering tasks such as link prediction and node classification. However, most graph embeddings are hard to interpret, offering limited insight into how learned features relate to graph structure. Many networks naturally admit a role-mixture view, where nodes are best described as mixtures over latent archetypal factors. Motivated by this structure, we propose a compositional graph embedding framework grounded in Aitchison geometry, the canonical geometry for comparing mixtures. Nodes are represented as simplex-valued compositions and embedded via isometric log-ratio (ILR) coordinates, which preserve Aitchison distances while enabling unconstrained optimization in Euclidean space. This yields intrinsically interpretable embeddings whose geometry reflects relative trade-offs among archetypes and supports coherent behavior under component restriction; we consider both fixed and learnable ILR bases. Across node classification and link prediction, our method achieves competitive performance with strong baselines while providing explainability by construction rather than post-hoc. Finally, subcompositional coherence enables principled component restriction: removing and renormalizing subsets preserves a well-defined geometry, which we exploit via subcompositional dimensionality removal to probe how archetype groups influence representations and predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Aitchison Embeddings for graph representations, where nodes are represented as simplex-valued compositions over latent archetypal factors. These compositions are embedded into Euclidean space using isometric log-ratio (ILR) coordinates, which preserve Aitchison distances. The framework supports both fixed and learnable bases, achieves competitive performance on node classification and link prediction, and provides intrinsic interpretability along with subcompositional coherence for component restriction.
Significance. Should the central claims hold, particularly the natural fit of the role-mixture model to graph nodes and the resulting interpretability, this work would offer a geometrically grounded alternative to standard graph embeddings with built-in explainability. It applies established tools from compositional data analysis (ILR isometry) to graphs, which could be valuable if the performance is indeed competitive without post-hoc explanations. The subcompositional property is a standard feature but its exploitation for dimensionality probing is a nice touch.
major comments (1)
- [Abstract] The assertion that 'many networks naturally admit a role-mixture view, where nodes are best described as mixtures over latent archetypal factors' is presented without derivation, validation, or references. This premise is central to the significance of the interpretability claims ('intrinsically interpretable embeddings whose geometry reflects relative trade-offs among archetypes'), as without it the simplex constraint and Aitchison geometry may represent an imposed modeling choice rather than a discovery from the data. The manuscript should include analysis showing that this view is appropriate for the evaluated graphs.
minor comments (1)
- The abstract is quite dense; separating the technical description of ILR embedding from the claims of interpretability and performance would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and outline planned revisions to strengthen the motivation and validation of the role-mixture modeling assumption.
read point-by-point responses
-
Referee: [Abstract] The assertion that 'many networks naturally admit a role-mixture view, where nodes are best described as mixtures over latent archetypal factors' is presented without derivation, validation, or references. This premise is central to the significance of the interpretability claims ('intrinsically interpretable embeddings whose geometry reflects relative trade-offs among archetypes'), as without it the simplex constraint and Aitchison geometry may represent an imposed modeling choice rather than a discovery from the data. The manuscript should include analysis showing that this view is appropriate for the evaluated graphs.
Authors: We agree that the role-mixture premise would benefit from explicit supporting references and targeted validation on the evaluated graphs. In the revised manuscript we will expand the introduction and related-work section with citations to the mixed-membership stochastic block model literature (e.g., Airoldi et al., 2008) and role-discovery papers that empirically document overlapping or mixed node roles in real networks. We will also add a concise analysis subsection in the experiments that examines the learned compositions on the node-classification and link-prediction benchmarks. This analysis will report simple statistics (entropy of the simplex vectors and fraction of nodes with non-negligible mass on multiple factors) to demonstrate that the model recovers non-degenerate mixtures rather than collapsing to pure archetypes. These additions will clarify that the simplex constraint is a deliberate modeling choice motivated by interpretability and subcompositional coherence, while showing that it is empirically reasonable for the graphs considered. revision: yes
Circularity Check
No significant circularity; new construction from standard compositional geometry
full rationale
The paper's derivation begins with the modeling assumption that nodes can be represented as simplex-valued compositions over latent archetypes (motivated but not derived from graph data), then applies the standard ILR isometry from Aitchison geometry to obtain Euclidean embeddings. This is a direct construction: the claimed interpretability and subcompositional coherence follow immediately from the properties of the ILR transform and simplex renormalization, without any fitted parameter being relabeled as a prediction, without self-citation chains justifying uniqueness, and without renaming an existing result. The method is presented as a new framework rather than a re-expression of its own outputs, and the technical steps (fixed vs. learnable bases, subcompositional restriction) remain independent of the target task performance.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Rank Is Not Capacity: Spectral Occupancy for Latent Graph Models
Spectra defines and controls effective capacity in graph embeddings via the Shannon effective rank of a trace-normalized kernel spectrum, making capacity a post-fit property rather than a pre-training hyperparameter.
Reference graph
Works this paper leans on
-
[1]
Learning role-based graph embeddings.arXiv preprint arXiv:1802.02896, 2018
Ahmed, N. K., Rossi, R., Lee, J. B., Willke, T. L., Zhou, R., Kong, X., and Eldardiry, H. Learning role-based graph embeddings.arXiv preprint arXiv:1802.02896,
-
[2]
Mixed membership stochastic blockmodels, 2007
URL https://arxiv.org/abs/0705.4485. Aitchison, J. The Statistical Analysis of Compositional Data.Journal of the Royal Statistical Society: Series B (Methodological), 44(2):139–160,
-
[3]
arXiv preprint arXiv:1905.13686 (2019)
Baldassarre, F. and Azizpour, H. Explainability tech- niques for graph convolutional networks.arXiv preprint arXiv:1905.13686,
-
[4]
doi: 10.1023/A:1023818214614. Epasto, A. and Perozzi, B. Is a Single Embedding Enough? Learning Node Representations that Capture Multiple 9 Submission and Formatting Instructions for ICML 2026 Social Contexts. InThe World Wide Web Conference, pp. 394–404,
-
[5]
URL https://arxiv. org/abs/2201.05197. Grover, A. and Leskovec, J. node2vec: Scalable Feature Learning for Networks. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Dis- covery and Data Mining, pp. 855–864,
-
[6]
Journal of the American Statistical Association , author =
doi: 10.1198/016214502388618906. URL https: //doi.org/10.1198/016214502388618906. Holland, P. W., Laskey, K. B., and Leinhardt, S. Stochastic blockmodels: First steps.Social Net- works, 5(2):109–137,
-
[7]
doi: https://doi.org/10.1016/0378-8733(83)90021-7
ISSN 0378-8733. doi: https://doi.org/10.1016/0378-8733(83)90021-7. URL https://www.sciencedirect.com/ science/article/pii/0378873383900217. Jin, J., Ke, Z. T., and Luo, S. Mixed membership estima- tion for social networks,
-
[8]
URL https://arxiv. org/abs/1708.07852. Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[9]
Semi-Supervised Classification with Graph Convolutional Networks
Kipf, T. Semi-supervised classification with graph con- volutional networks.arXiv preprint arXiv:1609.02907,
work page internal anchor Pith review arXiv
-
[10]
Lin, C., Sun, G. J., Bulusu, K. C., Dry, J. R., and Hernandez, M. Graph neural networks including sparse interpretabil- ity.arXiv preprint arXiv:2007.00119,
-
[11]
Hm-ldm: A hybrid-membership latent distance model, 2022
URL https://arxiv.org/abs/2206.03463. Nakis, N., Celikkanat, A., Boucherie, L., Djurhuus, C., Burmester, F., Holmelund, D. M., Frolcov ´a, M., and Mørup, M. Characterizing polarization in social networks using the signed relational latent distance model. In Ruiz, F., Dy, J., and van de Meent, J.-W. (eds.),Proceedings of The 26th International Conference o...
-
[12]
What do gnns actually learn? towards understanding their representations, 2024
URL https://arxiv.org/ abs/2304.10851. Perozzi, B., Al-Rfou, R., and Skiena, S. DeepWalk: On- line Learning of Social Representations. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 701–710,
-
[13]
Don’t walk, skip! online learning of multi-scale network em- beddings
Perozzi, B., Kulkarni, V ., Chen, H., and Skiena, S. Don’t walk, skip! online learning of multi-scale network em- beddings. InProceedings of the 2017 IEEE/ACM In- 10 Submission and Formatting Instructions for ICML 2026 ternational Conference on Advances in Social Networks Analysis and Mining, pp. 258–265,
2017
-
[14]
URL https://arxiv. org/abs/2005.07959. Rozemberczki, B., Kiss, O., and Sarkar, R. Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs. InProceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM ’20), pp. 3125–3132. ACM,
-
[15]
Ying, C., Cai, T., Luo, S., Zheng, S., Ke, G., He, D., Shen, Y ., and Liu, T.-Y
doi: 10.1086/226141. Ying, C., Cai, T., Luo, S., Zheng, S., Ke, G., He, D., Shen, Y ., and Liu, T.-Y . Do transformers really perform badly for graph representation?Advances in neural information processing systems, 34:28877–28888,
-
[16]
We include formal proofs and derivations, details on the ILR parameterization, complete experimental settings and hyperparameters, and additional empirical results
11 Submission and Formatting Instructions for ICML 2026 Appendix This appendix provides supplementary material supporting the main paper. We include formal proofs and derivations, details on the ILR parameterization, complete experimental settings and hyperparameters, and additional empirical results. These materials clarify the methodology and enable ful...
2026
-
[17]
Fix a subset S⊆ {1,
The ILR coordinates ofz i are the(k−1)-dimensional row vector ILR(zi)≜log(z i)⊤V∈R k−1. Fix a subset S⊆ {1, . . . , k} with |S|=k ′ ≥2 . Let RS ∈R k′×k be the coordinate-selection matrix that extracts the entries inS, so thatR Sz= (z r)r∈S ∈R k′ for anyz∈R k. Define the closure (re-normalization) mapC:R k′ >0 →∆ k′−1 ◦ by C(u)≜ u 1⊤ k′u . The reclosed sub...
2026
-
[18]
=σ(α−g(∥x i −x j∥2)), x i ∈R k−1. Proof. Since ILR is bijective, for any collection {xi}n i=1 ⊂R k−1 there exists a unique collection {zi}n i=1 ⊂∆ k−1 ◦ such thatx i = ILR(zi)for alli, and converselyz i = ILR−1(xi)exists for alli. BecauseILRis an isometry, for alli < j, ∥xi −x j∥2 =∥ILR(z i)−ILR(z j)∥2. Substituting this identity into the respective expre...
2026
-
[19]
Link prediction.For link prediction, we follow the widely adopted evaluation protocol of Perozzi et al
For SLIM-RAA, HM-LDM, MMSBM, and SIMPLEX-EUCLIDEAN, we optimized the negative Bernoulli log-likelihood (matching AICOG up to the model-specific log-odds parameterization) using learning rate 0.05 for 5,000 epochs, so differences are attributable only to the log-odds form. Link prediction.For link prediction, we follow the widely adopted evaluation protoco...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.