Recognition: unknown
Map2World: Segment Map Conditioned Text to 3D World Generation
Pith reviewed 2026-05-09 19:05 UTC · model grok-4.3
The pith
Map2World generates 3D worlds from text guided by user-defined segment maps of arbitrary shapes while preserving global scale consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conditioning 3D world generation on segment maps of arbitrary shapes and scales produces outputs that maintain consistent object sizes throughout expansive environments and allow finer user control than grid-based predecessors. The detail enhancer network achieves this by injecting global structure information during refinement, while the overall architecture exploits strong priors from asset generators to generalize with limited scene training data.
What carries the argument
The segment-map conditioning pipeline inside Map2World, which directly translates user-specified region boundaries and scales into the 3D layout, paired with a detail enhancer network that refines local appearance while preserving global coherence.
If this is right
- Users gain the ability to dictate non-rectangular and multi-scale layouts for entire 3D worlds through simple segment maps.
- Object scales remain consistent across large generated environments instead of drifting with distance or grid boundaries.
- Fine details can be added after the coarse layout is fixed without destroying global coherence.
- The same trained model works across multiple visual domains because it reuses priors from separate asset generators.
- Generation remains feasible even when only modest amounts of full-scene training data are available.
Where Pith is reading between the lines
- The approach could support iterative editing workflows in which a user adjusts the segment map and regenerates only the changed regions.
- It may reduce the data-collection burden for specialized simulators such as autonomous-driving environments by allowing map-based customization.
- Scaling the method to city-sized outputs would require verifying that coherence and scale consistency continue to hold at larger distances.
- Integration with physics engines or procedural content tools could turn the generated worlds into immediately usable simulation assets.
Load-bearing premise
That a detail enhancer network can add fine-grained elements without breaking overall scene coherence when it receives global structure information, and that priors from asset generators remain effective even with limited scene-specific training data.
What would settle it
Run the system on a segment map containing objects of deliberately varying intended scales across distant regions; measure whether the final 3D output shows measurable size drift or layout violations relative to the input map.
Figures



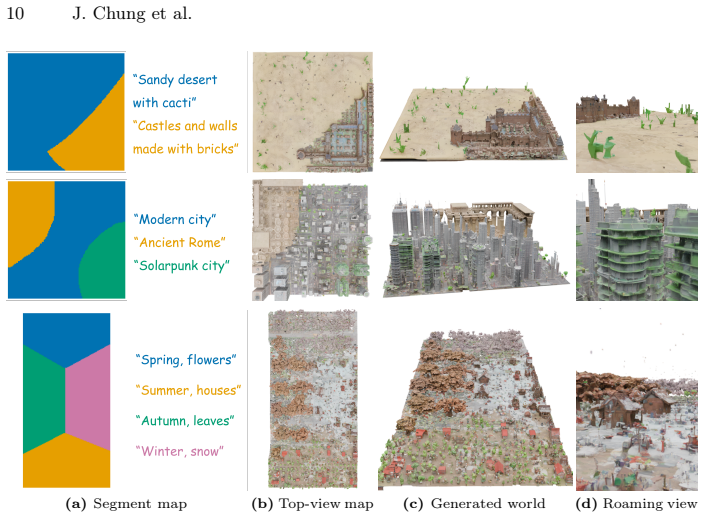

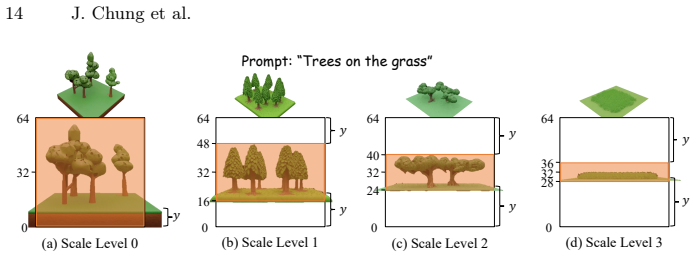

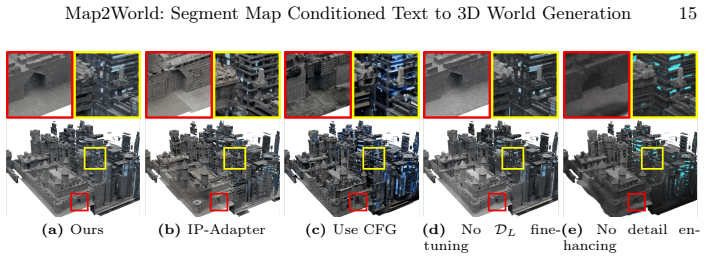
read the original abstract
3D world generation is essential for applications such as immersive content creation or autonomous driving simulation. Recent advances in 3D world generation have shown promising results; however, these methods are constrained by grid layouts and suffer from inconsistencies in object scale throughout the entire world. In this work, we introduce a novel framework, Map2World, that first enables 3D world generation conditioned on user-defined segment maps of arbitrary shapes and scales, ensuring global-scale consistency and flexibility across expansive environments. To further enhance the quality, we propose a detail enhancer network that generates fine details of the world. The detail enhancer enables the addition of fine-grained details without compromising overall scene coherence by incorporating global structure information. We design the entire pipeline to leverage strong priors from asset generators, achieving robust generalization across diverse domains, even under limited training data for scene generation. Extensive experiments demonstrate that our method significantly outperforms existing approaches in user-controllability, scale consistency, and content coherence, enabling users to generate 3D worlds under more complex conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Map2World, a framework for 3D world generation conditioned on arbitrary user-defined segment maps (rather than grid layouts). The pipeline first generates a coarse world from the segment map and text prompt, then applies a detail enhancer network that conditions on global structure information to add fine-grained details without breaking coherence, and leverages strong priors from pre-trained asset generators to enable data-efficient generalization. Experiments claim significant gains over prior methods in user-controllability, scale consistency, and content coherence for complex, large-scale scenes.
Significance. If the quantitative and qualitative claims hold, the work would meaningfully advance controllable 3D scene synthesis for applications such as simulation and immersive content. The combination of arbitrary-shape map conditioning, structure-aware detail enhancement, and asset-prior transfer addresses two recurring failure modes (scale drift and data hunger) in current text-to-3D pipelines; successful validation would therefore be of clear practical value.
major comments (2)
- [§3.2] §3.2 (Detail Enhancer Network): the claim that global structure information is injected to preserve coherence is central to the coherence result, yet the manuscript provides only a high-level diagram and no explicit equations for the conditioning mechanism, the auxiliary loss, or the feature-fusion operator; without these, the reader cannot verify that the enhancer does not re-introduce the very inconsistencies it is meant to avoid.
- [§4.2, Table 3] §4.2 and Table 3 (Quantitative Metrics): scale-consistency and coherence are reported as improved, but the precise definitions of the metrics (e.g., how inter-object scale variance is computed across an entire world, or the coherence score formula) are not stated; this makes it impossible to judge whether the reported gains are substantive or merely reflect a different evaluation protocol.
minor comments (3)
- [§2] The related-work section should explicitly contrast the proposed segment-map conditioning with recent layout-conditioned or sketch-conditioned 3D generation methods (e.g., those using bounding-box or semantic-layout inputs) to clarify novelty.
- [Figure 5] Figure 5 (qualitative results) would be more informative if each row also displayed the input segment map alongside the generated world and the competing baselines.
- [§3.1] A few sentences in §3.1 use the term “global structure” without defining whether it refers to the full segment map, a downsampled version, or an implicit latent code; a short clarifying sentence would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below and will incorporate the requested clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Detail Enhancer Network): the claim that global structure information is injected to preserve coherence is central to the coherence result, yet the manuscript provides only a high-level diagram and no explicit equations for the conditioning mechanism, the auxiliary loss, or the feature-fusion operator; without these, the reader cannot verify that the enhancer does not re-introduce the very inconsistencies it is meant to avoid.
Authors: We agree that §3.2 would benefit from greater mathematical precision. In the revised manuscript we will add explicit equations describing (i) the conditioning mechanism that injects global structure features into the enhancer, (ii) the auxiliary loss used to enforce coherence, and (iii) the feature-fusion operator. These additions will allow readers to verify that the design does not re-introduce scale or content inconsistencies. revision: yes
-
Referee: [§4.2, Table 3] §4.2 and Table 3 (Quantitative Metrics): scale-consistency and coherence are reported as improved, but the precise definitions of the metrics (e.g., how inter-object scale variance is computed across an entire world, or the coherence score formula) are not stated; this makes it impossible to judge whether the reported gains are substantive or merely reflect a different evaluation protocol.
Authors: We acknowledge that the exact formulations of the scale-consistency and coherence metrics are not stated in the current text. In the revision we will provide the precise definitions, including the formula for inter-object scale variance across the full scene and the coherence score computation, so that the quantitative claims can be fully evaluated and reproduced. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an engineering pipeline for segment-map-conditioned 3D world generation, including a detail enhancer network and use of asset-generator priors for generalization. No equations, derivations, fitted parameters presented as predictions, or self-referential definitions appear in the provided text. The central claims rest on experimental comparisons rather than any reduction to inputs by construction, self-citation chains, or ansatz smuggling. The method is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.19985 (2025)
Baek, S., Dong, E., Namazifard, S., Matthews, M.J., Yi, K.M.: Sonic: Spectral op- timization of noise for inpainting with consistency. arXiv preprint arXiv:2511.19985 (2025)
-
[2]
International Conference on Machine Learning (2023)
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: Multidiffusion: Fusing diffusion paths for controlled image generation. International Conference on Machine Learning (2023)
2023
-
[3]
arXiv preprint arXiv:2409.01055 (2024)
Chen, Q., Ma, Y., Wang, H., Yuan, J., Zhao, W., Tian, Q., Wang, H., Min, S., Chen, Q., Liu, W.: Follow-your-canvas: Higher-resolution video outpainting with extensive content generation. arXiv preprint arXiv:2409.01055 (2024)
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Chen, R., Chen, Y., Jiao, N., Jia, K.: Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22246–22256 (2023)
2023
-
[5]
Lu- ciddreamer: Domain-free generation of 3d gaussian splatting scenes, 2023
Chung, J., Lee, S., Nam, H., Lee, J., Lee, K.M.: Luciddreamer: Domain-free gener- ation of 3d gaussian splatting scenes. arXiv preprint arXiv:2311.13384 (2023)
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[7]
In: The twelfth international conference on learning representations (2023)
Ding, Z., Zhang, M., Wu, J., Tu, Z.: Patched denoising diffusion models for high- resolution image synthesis. In: The twelfth international conference on learning representations (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
Du, R., Chang, D., Hospedales, T., Song, Y.Z., Ma, Z.: Demofusion: Democratising high-resolution image generation with no $$$. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
2024
-
[9]
Engstler, P., Shtedritski, A., Laina, I., Rupprecht, C., Vedaldi, A.: Syncity: Training- free generation of 3d worlds. arXiv preprint arXiv:2503.16420 (2025) Map2World: Segment Map Conditioned Text to 3D World Generation 17
-
[10]
In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Fu, J., Ng, S.K., Jiang, Z., Liu, P.: Gptscore: Evaluate as you desire. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6556–6576 (2024)
2024
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao, Q., Xu, Q., Su, H., Neumann, U., Xu, Z.: Strivec: Sparse tri-vector radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17569–17579 (2023)
2023
-
[12]
In: NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021)
2021
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Höllein, L., Cao, A., Owens, A., Johnson, J., Nießner, M.: Text2room: Extracting textured 3d meshes from 2d text-to-image models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 7909–7920 (October 2023)
2023
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
Jiang, W., Jangid, D.K., Lee, S.J., Sheikh, H.R.: Latent patched efficient diffusion model for high resolution image synthesis. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025)
2025
-
[15]
arXiv preprint arXiv:2302.02412 , year=
Jiménez, Á.B.: Mixture of diffusers for scene composition and high resolution image generation. arXiv preprint arXiv:2302.02412 (2023)
-
[16]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[17]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision (2021)
Kim, K., Yun, Y., Kang, K.W., Kong, K., Lee, S., Kang, S.J.: Painting outside as inside: Edge guided image outpainting via bidirectional rearrangement with progressive step learning. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision (2021)
2021
-
[18]
arXiv preprint arXiv:2503.16375 (2025)
Lee, H.H., Han, Q., Chang, A.X.: Nuiscene: Exploring efficient generation of unbounded outdoor scenes. arXiv preprint arXiv:2503.16375 (2025)
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2025)
Lee, J., Jung, D.S., Lee, K., Lee, K.M.: Streammultidiffusion: real-time interactive generation with region-based semantic control. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2025)
2025
-
[20]
Advances in Neural Information Processing Systems (2023)
Lee, Y., Kim, K., Kim, H., Sung, M.: Syncdiffusion: Coherent montage via syn- chronized joint diffusions. Advances in Neural Information Processing Systems (2023)
2023
-
[21]
In: European Conference on Computer Vision
Li, H., Shi, H., Zhang, W., Wu, W., Liao, Y., Wang, L., Lee, L.h., Zhou, P.Y.: Dreamscene: 3d gaussian-based text-to-3d scene generation via formation pattern sampling. In: European Conference on Computer Vision. pp. 214–230. Springer (2024)
2024
-
[22]
arXiv preprint arXiv:2510.21682 (2025)
Li, S., Yang, C., Fang, J., Yi, T., Lu, J., Cen, J., Xie, L., Shen, W., Tian, Q.: Worldgrow: Generating infinite 3d world. arXiv preprint arXiv:2510.21682 (2025)
-
[23]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[24]
In: International Conference on Learning Representations (2023)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: International Conference on Learning Representations (2023)
2023
-
[25]
Advances in Neural Information Processing Systems37, 133305–133327 (2024)
Liu, X., Zhou, C., Huang, S.: 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors. Advances in Neural Information Processing Systems37, 133305–133327 (2024)
2024
-
[26]
Lu, Y., Ren, X., Yang, J., Shen, T., Wu, Z., Gao, J., Wang, Y., Chen, S., Chen, M., Fidler, S., Huang, J.: Infinicube: Unbounded and controllable dynamic 3d driving scene generation with world-guided video models (2024),https://arxiv.org/abs/ 2412.03934 18 J. Chung et al
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Meng, Q., Li, L., Nießner, M., Dai, A.: Lt3sd: Latent trees for 3d scene diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 650–660 (2025)
2025
-
[28]
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y., Qie, X.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453 (2023)
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Ren, X., Huang, J., Zeng, X., Museth, K., Fidler, S., Williams, F.: Xcube: Large- scale 3d generative modeling using sparse voxel hierarchies. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[30]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
Ren, X., Lu, Y., Liang, H., Wu, J.Z., Ling, H., Chen, M., Fidler, S., Williams, F., Huang, J.: Scube: Instant large-scale scene reconstruction using voxsplats. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022)
2022
-
[32]
Advances in neural information processing systems35(2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35(2022)
2022
-
[33]
ACM Transactions on Graphics (TOG)42(4), 1–16 (2023)
Shen, T., Munkberg, J., Hasselgren, J., Yin, K., Wang, Z., Chen, W., Gojcic, Z., Fidler, S., Sharp, N., Gao, J.: Flexible isosurface extraction for gradient-based mesh optimization. ACM Transactions on Graphics (TOG)42(4), 1–16 (2023)
2023
-
[34]
In: International Conference on 3D Vision (3DV) (2025)
Shriram, J., Trevithick, A., Liu, L., Ramamoorthi, R.: Realmdreamer: Text-driven 3d scene generation with inpainting and depth diffusion. In: International Conference on 3D Vision (3DV) (2025)
2025
-
[35]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Song, D.Y., Yu, J.J., Cho, D.: Progressive artwork outpainting via latent diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[36]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, H., Liu, F., Chi, J., Duan, Y.: Videoscene: Distilling video diffusion model to generate 3d scenes in one step. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16475–16485. IEEE (2025)
2025
-
[37]
arXiv preprint arXiv:2307.03177 (2023)
Wu, T., Zheng, C., Cham, T.J.: Panodiffusion: 360-degree panorama outpainting via diffusion. arXiv preprint arXiv:2307.03177 (2023)
-
[38]
ACM TOG (2024)
Wu, Z., Li, Y., Yan, H., Shang, T., Sun, W., Wang, S., Cui, R., Liu, W., Sato, H., Li, H., Ji, P.: Blockfusion: Expandable 3d scene generation using latent tri-plane extrapolation. ACM TOG (2024)
2024
-
[39]
In: CVPR
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: CVPR. pp. 21469–21480 (2025)
2025
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yan, Y., Xu, Z., Lin, H., Jin, H., Guo, H., Wang, Y., Zhan, K., Lang, X., Bao, H., Zhou, X., et al.: Streetcrafter: Street view synthesis with controllable video diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 822–832 (2025)
2025
-
[41]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint arxiv:2308.06721 (2023)
work page internal anchor Pith review arXiv 2023
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yu, H.X., Duan, H., Herrmann, C., Freeman, W.T., Wu, J.: Wonderworld: Inter- active 3d scene generation from a single image. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5916–5926 (2025) Map2World: Segment Map Conditioned Text to 3D World Generation 19
2025
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, H.X., Duan, H., Hur, J., Sargent, K., Rubinstein, M., Freeman, W.T., Cole, F., Sun, D., Snavely, N., Wu, J., et al.: Wonderjourney: Going from anywhere to everywhere. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6658–6667 (2024)
2024
-
[44]
NeurIPS (2024)
Zhang, B., Cheng, Y., Yang, J., Wang, C., Zhao, F., Tang, Y., Chen, D., Guo, B.: Gaussiancube: A structured and explicit radiance representation for 3d generative modeling. NeurIPS (2024)
2024
-
[45]
ACM Transactions on Graphics (TOG)43(4), 1–20 (2024)
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3d assets. ACM Transactions on Graphics (TOG)43(4), 1–20 (2024)
2024
-
[46]
In: Proceedings of the IEEE/CVF international conference on computer vision (2023)
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision (2023)
2023
-
[47]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Q., Zhai, S., Martin, M.A.B., Miao, K., Toshev, A., Susskind, J., Gu, J.: World-consistent video diffusion with explicit 3d modeling. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21685–21695 (2025)
2025
-
[48]
Spring village with wildflower meadows, cherry blossoms, clear sky
Zheng, K., Zhang, R., Gu, J., Yang, J., Wang, X.E.: Constructing a 3d town from a single image. arXiv preprint arXiv:2505.15765 (2025) Supplementary Materials for Map2World: Segment Map Conditioned Text to 3D World Generation S1 Implementation Details S1.1 Details on Network Architectures Feature interpolation for structured latent flow Transformer (GL).T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.