Recognition: unknown
Statistical mechanics for Scrabble predicts strategy, entropy and language
Pith reviewed 2026-05-09 14:35 UTC · model grok-4.3
The pith
A pairwise maximum-entropy model on Scrabble graphs reproduces observed data and distinguishes languages without reading the letters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adapting a maximum entropy approach to connected graphs yields the most structureless description reproducing means and covariances observed in real Scrabble games. This pairwise model captures the data well and predicts word-length statistics and geometric features of the Scrabble graphs correctly. In addition the parameters of this model are interpretable and allow us to understand Scrabble playing strategies. Using this pairwise model we calculate entropy differences and distinguishability of Scrabble graphs across languages without having access to the letters on the tiles. Notably we find that the entropy is predicted better by strategic gameplay such as word length on the board than by
What carries the argument
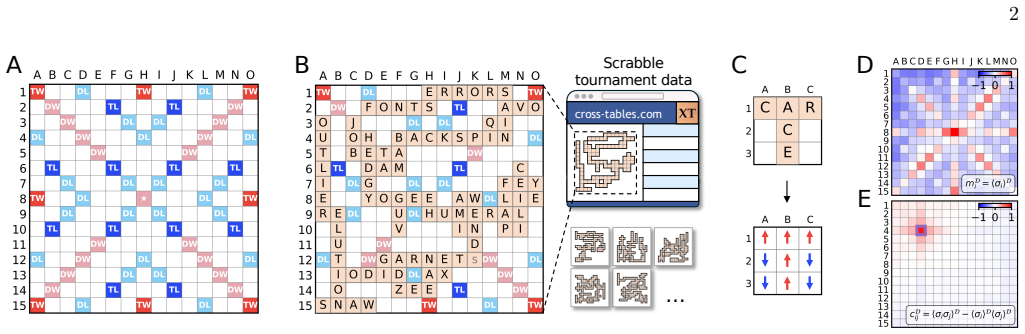
A maximum-entropy pairwise interaction model on connected square-lattice graphs of occupied Scrabble tiles.
If this is right
- The parameters directly quantify strategic preferences such as choices of word length on the board.
- Entropy calculated from the model serves as a metric that separates languages according to strategic gameplay rather than lexicon size.
- Language assignment becomes possible from graph structure alone without explicit features or knowledge of the tile letters.
- The model correctly forecasts word-length statistics and geometric properties of the tile arrangements.
Where Pith is reading between the lines
- The same graph-based approach could be tested on placement data from other board games to extract strategy signatures.
- Entropy differences might reveal how play habits encode language usage patterns beyond simple vocabulary differences.
- Anonymous game records could be grouped by language using only their spatial statistics.
Load-bearing premise
That a maximum-entropy model limited to pairwise interactions on connected lattice graphs is sufficient to reproduce all relevant structure in real Scrabble data and that the observed means and covariances provide enough constraints to determine a unique predictive model.
What would settle it
Computing three-body or higher correlation functions from real Scrabble games and finding significant deviations from the predictions generated by the fitted pairwise model would show that additional interaction terms are required.
Figures







read the original abstract
The crossword-like patterns of tiles in Scrabble form connected graphs of occupied sites on a square lattice. We find the most structureless description that reproduces means and covariances observed in real Scrabble games by adapting a maximum entropy approach to connected graphs. This pairwise model captures the data well, and predicts word-length statistics and geometric features of the Scrabble graphs correctly; in addition, the parameters of this model are interpretable and allow us to understand Scrabble playing strategies. Using this pairwise model, we calculate entropy differences and distinguishability of Scrabble graphs across languages, without having access to the letters on the tiles. Notably, we find that the entropy is predicted better by strategic gameplay -- such as word length on the board -- than lexicon size. Finally, we find that we can use the pairwise model to correctly assign Scrabble graphs to languages, avoiding explicit feature selection and at relatively low computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a maximum-entropy model with pairwise interactions constrained to connected graphs on a square lattice to describe the patterns of occupied sites in Scrabble games. It reports that this model reproduces the observed means and covariances from real games, predicts word-length statistics and geometric features, yields interpretable parameters reflecting playing strategies, computes entropy differences across languages that correlate more with strategic elements like word length than with lexicon size, and enables correct assignment of Scrabble graphs to their languages without access to tile letters.
Significance. This work applies tools from statistical mechanics to analyze strategic gameplay and linguistic structures in a novel way. If the higher-order predictions hold without circularity, it provides a parameter-efficient framework for understanding game data and cross-language distinguishability, potentially generalizable to other board games or spatial language patterns. The avoidance of explicit feature selection in classification is a strength.
major comments (2)
- [Model construction and validation] The pairwise max-ent model is defined to match the first and second moments exactly via Lagrange multipliers (as is standard). The claim that it 'captures the data well' and correctly predicts word-length statistics therefore hinges on whether these higher-order observables emerge from the connectivity constraint and fitted couplings. The manuscript should report specific quantitative comparisons (e.g., in a dedicated results section or figure) between model-generated distributions and empirical data for word lengths and geometric features, including error bars or statistical tests to confirm the emergence is not an artifact.
- [Entropy and language assignment] The finding that entropy is better predicted by strategic gameplay than lexicon size is interesting, but requires clarification on how entropy is computed from the model and what controls are used to separate gameplay from lexicon effects. For the language assignment, details on the classification procedure, accuracy metrics, and whether it was tested on independent games are needed to assess if it truly avoids feature selection at low cost.
minor comments (2)
- [Abstract] The abstract states the model 'captures the data well' without specifying the metrics used; this should be expanded or referenced to the main text.
- [Notation] Ensure consistent notation for the lattice graphs and interaction parameters throughout the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight opportunities to strengthen the quantitative validation and methodological transparency. We will revise the manuscript accordingly and address each point below.
read point-by-point responses
-
Referee: [Model construction and validation] The pairwise max-ent model is defined to match the first and second moments exactly via Lagrange multipliers (as is standard). The claim that it 'captures the data well' and correctly predicts word-length statistics therefore hinges on whether these higher-order observables emerge from the connectivity constraint and fitted couplings. The manuscript should report specific quantitative comparisons (e.g., in a dedicated results section or figure) between model-generated distributions and empirical data for word lengths and geometric features, including error bars or statistical tests to confirm the emergence is not an artifact.
Authors: We agree that explicit quantitative comparisons with uncertainty estimates would improve the presentation. The current manuscript shows that the model reproduces the fitted moments by construction and illustrates higher-order agreement via example samples and summary statistics, but does not include formal distribution-level metrics. In the revised version we will add a dedicated subsection (and accompanying figure) that reports: (i) the empirical versus model-generated word-length histograms with bootstrap-derived error bars on bin frequencies, (ii) mean absolute deviation and Kolmogorov-Smirnov statistics between the two distributions, and (iii) analogous quantitative comparisons for geometric observables such as the number of isolated clusters and the convex-hull area. These additions will be placed after the moment-matching results to demonstrate that the connectivity constraint plus pairwise couplings suffice to generate the observed higher-order structure. revision: yes
-
Referee: [Entropy and language assignment] The finding that entropy is better predicted by strategic gameplay than lexicon size is interesting, but requires clarification on how entropy is computed from the model and what controls are used to separate gameplay from lexicon effects. For the language assignment, details on the classification procedure, accuracy metrics, and whether it was tested on independent games are needed to assess if it truly avoids feature selection at low cost.
Authors: We will expand the Methods and Results sections to provide the requested details. Entropy is obtained from the closed-form expression for the maximum-entropy distribution: S = ln Z + sum lambda_mu <O_mu>, where Z is evaluated by Monte Carlo sampling on the lattice. To isolate strategic effects from lexicon size we will add two controls: (1) models fitted to position-shuffled boards that preserve word-length statistics but destroy spatial correlations, and (2) synthetic lexicons with matched size but randomized letter frequencies. For classification we will describe the procedure explicitly: each held-out graph is scored by its log-likelihood under each language-specific fitted model (using only the pairwise observables) and assigned to the highest-scoring language. We will report overall accuracy together with per-language confusion matrices on a cross-validated set of games drawn from independent matches not used in parameter estimation, thereby confirming that the assignment relies solely on the learned spatial statistics rather than hand-crafted features. revision: yes
Circularity Check
No significant circularity; max-ent model matches constraints by design but higher-order predictions test independent emergence.
full rationale
The paper defines a maximum-entropy pairwise model on connected lattice graphs whose Lagrange multipliers are chosen to exactly reproduce observed site-occupation means and pairwise covariances. This guarantees that the fitted model matches those input moments by construction, yet the reported predictions—word-length statistics, geometric features of the graphs, entropy differences driven by strategic word length rather than lexicon size, and language assignment from graph structure alone—are higher-order observables not included among the fitting constraints. These quantities can only match the data if the connectivity enforcement plus pairwise couplings induce the requisite multi-site correlations, which is a non-trivial test rather than a definitional reduction. No equations or self-citations are shown that would make the central claims equivalent to the fitted inputs; the derivation therefore remains self-contained against external Scrabble-game benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- pairwise interaction strengths
axioms (2)
- standard math Maximum entropy principle selects the least structured distribution consistent with given constraints
- domain assumption Pairwise interactions are sufficient to describe the structure of connected Scrabble graphs on a square lattice
Reference graph
Works this paper leans on
-
[1]
pdEllmlNGlqhHy444ODyljqy4/o=
compared to human games. This suggests that the effective lexicon practically accessible to human play- ers is smaller than the full English dictionary accessible to Quackle, and likely increasingly depleted for longer words. Humans tend to play shorter words but still ac- tively optimize for bingos (Fig. 2G); yet, playing longer words requires solving an...
-
[2]
Allen, F
K. Allen, F. Br¨ andle, M. Botvinick, J. E. Fan, S. J. Ger- shman, A. Gopnik, T. L. Griffiths, J. K. Hartshorne, T. U. Hauser, M. K. Ho,et al., Using games to un- derstand the mind, Nature Human Behaviour8, 1035 (2024)
2024
-
[3]
G. N. Yannakakis and J. Togelius,Artificial intelligence and games, 1st ed. (Springer, 2018)
2018
-
[4]
Lichtenstein and M
D. Lichtenstein and M. Sipser, Go is polynomial-space hard, Journal of the ACM27, 393 (1980)
1980
-
[5]
A. S. Fraenkel and D. Lichtenstein, Computing a per- fect strategy forn×nchess requires time exponential inn, Journal of Combinatorial Theory, Series A31, 199 (1981)
1981
-
[6]
Silver, A
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, Mastering the game of Go with deep neural networks and tree search, Nature529, 484 (2016)
2016
-
[7]
K. M. Collins, C. E. Zhang, G. Todd, L. Ying, M. B. da Costa, R. Liu, P. Sharma, A. Weller, I. Kuperwajs, L. Wong, J. B. Tenenbaum, and T. L. Griffiths, Eval- uating language models’ evaluations of games (2025), arXiv:2510.10930 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
C. E. Shannon, A mathematical theory of communica- tion, The Bell System Technical Journal27, 379 (1948), conference Name: The Bell System Technical Journal
1948
-
[9]
D. J. C. MacKay,Information theory, inference, and learning algorithms(Cambridge University Press, Cam- bridge, 2003)
2003
-
[10]
G. J. Stephens and W. Bialek, Statistical mechanics of letters in words, Physical Review E81, 066119 (2010)
2010
-
[11]
Takahira, K
R. Takahira, K. Tanaka-Ishii, and L. Debowski, Entropy rate estimates for natural language—a new extrapola- tion of compressed large-scale corpora, Entropy18, 364 (2016)
2016
-
[12]
Bentz, D
C. Bentz, D. Alikaniotis, M. Cysouw, and R. Ferrer-i Cancho, The entropy of words—learnability and expres- sivity across more than 1000 languages, Entropy19, 275 (2017)
2017
-
[13]
Koplenig, S
A. Koplenig, S. Wolfer, and P. Meyer, A large quantita- tive analysis of written language challenges the idea that all languages are equally complex, Scientific Reports13, 15351 (2023)
2023
-
[14]
C. Scheibner, L. M. Smith, and W. Bialek, Large language models and the entropy of English (2025), arXiv:2512.24969 [cond-mat.stat-mech]
-
[15]
McCarthy, Shakespeare and Arden of Faversham, Notes & Queries60, 391–397 (2013)
D. McCarthy, Shakespeare and Arden of Faversham, Notes & Queries60, 391–397 (2013)
2013
-
[16]
Basu and J
A. Basu and J. Loewenstein, Spenser’s Spell: Archaism and historical stylometrics, Spenser Studies33, 63–102 (2019)
2019
-
[17]
Misson and D
J. Misson and D. Singh, Computing book parts with EEBO-TCP, Book History25, 503 (2022)
2022
-
[18]
Richards and E
M. Richards and E. Amir, Opponent modeling in Scrab- ble, inProceedings of the 20th International Joint Con- ference on Artifical Intelligence, IJCAI’07 (Morgan Kauf- mann Publishers Inc., San Francisco, 2007) p. 1482–1487
2007
-
[19]
S. J. Russell and P. Norvig,Artificial intelligence: a mod- ern approach, 4th ed., Prentice Hall series in artificial intelligence (Pearson, Boston, 2022)
2022
-
[20]
New York Times, Crossplay (2026)
2026
-
[21]
Smith and S
K. Smith and S. Lipkin, cross-tables.com (2005)
2005
-
[24]
Jensen and A
I. Jensen and A. J. Guttmann, Statistics of lattice ani- mals (polyominoes) and polygons, Journal of Physics A: Mathematical and General33, L257 (2000)
2000
-
[25]
Jensen, Enumerations of lattice animals and trees, Journal of Statistical Physics102, 865 (2001)
I. Jensen, Enumerations of lattice animals and trees, Journal of Statistical Physics102, 865 (2001)
2001
-
[26]
E. T. Jaynes, Information Theory and Statistical Me- chanics, Physical Review106, 620 (1957)
1957
-
[27]
Ackley, G
D. Ackley, G. Hinton, and T. Sejnowski, A learning algo- rithm for Boltzmann machines, Cognitive Science9, 147 (1985)
1985
-
[28]
H. C. Nguyen, R. Zecchina, and J. Berg, Inverse statis- tical problems: from the inverse Ising problem to data science, Advances in Physics66, 197 (2017)
2017
-
[29]
C. W. Lynn, Q. Yu, R. Pang, S. E. Palmer, and W. Bialek, Exact minimax entropy models of large-scale neuronal activity, Physical Review E111, 054411 (2025)
2025
-
[30]
Aurell and M
E. Aurell and M. Ekeberg, Inverse Ising inference using all the data, Physical Review Letters108, 090201 (2012)
2012
-
[31]
Witteveen, S
O. Witteveen, S. J. Rosen, R. S. Lach, M. Z. Wilson, and M. Bauer, Optimizing information transmission in optogenetic Wnt signaling, Physical Review Research8, 10 013296 (2026)
2026
-
[32]
M. D. Petkova, G. Tkaˇ cik, W. Bialek, E. F. Wieschaus, and T. Gregor, Optimal decoding of cellular identities in a genetic network, Cell176, 844 (2019)
2019
-
[33]
Bauer, M
M. Bauer, M. D. Petkova, T. Gregor, E. F. Wieschaus, and W. Bialek, Trading bits in the readout from a ge- netic network, Proceedings of the National Academy of Sciences118, e2109011118 (2021)
2021
-
[35]
Roudi, S
Y. Roudi, S. Nirenberg, and P. E. Latham, Pairwise max- imum entropy models for studying large biological sys- tems: When they can work and when they can’t, PLoS Computational Biology5, e1000380 (2009)
2009
-
[36]
Merchan and I
L. Merchan and I. Nemenman, On the sufficiency of pair- wise interactions in maximum entropy models of net- works, Journal of Statistical Physics162, 1294 (2016)
2016
-
[37]
Cocco, C
S. Cocco, C. Feinauer, M. Figliuzzi, R. Monasson, and M. Weigt, Inverse statistical physics of protein sequences: a key issues review, Reports on Progress in Physics81, 032601 (2018)
2018
-
[38]
D. P. Carcamo and C. W. Lynn, Statistical physics of large-scale neural activity with loops, Proceedings of the National Academy of Sciences122, e2426926122 (2025)
2025
- [39]
-
[40]
Harju, J
J. Harju, J. J. B. Messelink, and C. P. Broedersz, Multi- contact statistics distinguish models of chromosome or- ganization, Physical Review E111, 014403 (2025)
2025
-
[41]
Loonen, L
S. Loonen, L. Van Steenis, M. Bauer, and N. ˇSoˇ stari´ c, Phosphorylation changes SARS-CoV-2 nucleocapsid pro- tein’s structural dynamics and its interaction with RNA, Proteins: Structure, Function, and Bioinformatics93, 1701 (2025)
2025
-
[42]
Bialek, A
W. Bialek, A. Cavagna, I. Giardina, T. Mora, E. Sil- vestri, M. Viale, and A. M. Walczak, Statistical mechan- ics for natural flocks of birds, Proceedings of the National Academy of Sciences109, 4786 (2012)
2012
-
[43]
Ahamed, A
T. Ahamed, A. C. Costa, and G. J. Stephens, Capturing the continuous complexity of behaviour in Caenorhabdi- tis elegans, Nature Physics17, 275 (2021)
2021
-
[44]
T. D. Pereira, N. Tabris, A. Matsliah, D. M. Turner, J. Li, S. Ravindranath, E. S. Papadoyannis, E. Normand, D. S. Deutsch, Z. Y. Wang, G. C. McKenzie-Smith, C. C. Mitelut, M. D. Castro, J. D’Uva, M. Kislin, D. H. Sanes, S. D. Kocher, S. S.-H. Wang, A. L. Falkner, J. W. Shae- vitz, and M. Murthy, SLEAP: A deep learning system for multi-animal pose trackin...
2022
-
[45]
Nguyen, I
C. Nguyen, I. Dromi, A. Kempinski, G. E. C. Gall, O. Pe- leg, and Y. Meroz, Noisy circumnutations facilitate self- organized shade avoidance in sunflowers, Physical Review X14, 031027 (2024)
2024
-
[46]
Valverde-Mendez, A
D. Valverde-Mendez, A. M. Sunol, B. P. Bratton, M. De- larue, J. L. Hofmann, J. P. Sheehan, Z. Gitai, L. J. Holt, J. W. Shaevitz, and R. N. Zia, Macromolecular interac- tions and geometrical confinement determine the 3D dif- fusion of ribosome-sized particles in liveEscherichia coli cells, Proceedings of the National Academy of Sciences 122, e2406340121 (2025)
2025
-
[47]
Klibaite, T
U. Klibaite, T. Li, D. Aldarondo, J. F. Akoad, B. P. ¨Olveczky, and T. W. Dunn, Mapping the landscape of social behavior, Cell188, 2249 (2025)
2025
-
[48]
J. D. Marshall, D. E. Aldarondo, T. W. Dunn, W. L. Wang, G. J. Berman, and B. P. ¨Olveczky, Continuous whole-body 3d kinematic recordings across the rodent behavioral repertoire, Neuron109, 420 (2021)
2021
-
[49]
O’Shaughnessy, T
L. O’Shaughnessy, T. Izawa, I. Masai, J. W. Shaevitz, and G. J. Stephens, Dynamics of dominance in interact- ing zebrafish, PRX Life2, 043006 (2024)
2024
-
[50]
Thompson, B
B. Thompson, B. Van Opheusden, T. Sumers, and T. Griffiths, Complex cognitive algorithms preserved by selective social learning in experimental populations, Sci- ence376, 95 (2022)
2022
-
[51]
C. R. Twomey, G. Roberts, D. H. Brainard, and J. B. Plotkin, What we talk about when we talk about colors, Proceedings of the National Academy of Sciences118, e2109237118 (2021). Supplementary Information: Statistical mechanics for Scrabble predicts strategy, entropy and language Olivier Witteveen 1 and Marianne Bauer 1,∗ 1Department of Bionanoscience, Ka...
2021
-
[52]
Metropolis, A
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller, Equation of state calculations by fast computing machines, The Journal of Chemical Physics21, 1087 (1953)
1953
-
[53]
pdEllmlNGlqhHy444ODyljqy4/o=
W. K. Hastings, Monte Carlo sampling methods using Markov chains and their applications, Biometrika57, 97 (1970). 6 decoding using 𝑝(1)decoding using no. of words Scrabble graph <latexit sha1_base64="pdEllmlNGlqhHy444ODyljqy4/o=">AAACTnicbVDPSxtBFJ6NVtNtq6kevQwGwV7CbhH1Ugh66TGCUSETwuzsSzI4M7vMvBXDsv9gTwVP/heehAqiszGFVn0wzDff+96P+ZJcSYdRdBs0lpY/rKw2P4afPn9...
1970
-
[54]
Schneidman, M
E. Schneidman, M. J. Berry, R. Segev, and W. Bialek, Weak pairwise correlations imply strongly correlated network states in a neural population, Nature440, 1007 (2006)
2006
-
[55]
Meshulam and W
L. Meshulam and W. Bialek, Statistical mechanics for networks of real neurons, Reviews of Modern Physics97, 045002 (2025)
2025
-
[56]
Lin, Divergence measures based on the shannon entropy, IEEE Transactions on Information Theory37, 145 (1991)
J. Lin, Divergence measures based on the shannon entropy, IEEE Transactions on Information Theory37, 145 (1991)
1991
-
[57]
T. M. Cover and J. A. Thomas,Elements of information theory(Wiley, New York, 1991)
1991
-
[58]
O’Laughlin and J
J. O’Laughlin and J. Katz-Brown, Quackle (2019)
2019
-
[59]
North American Scrabble Players Association, NASPA Word List 2023 Edition (2023)
2023
-
[60]
(HarperCollins Pub- lishers, London, 2024)
Collins Scrabble,Official Scrabble words: The official, comprehensive word list for Scrabble, 7th ed. (HarperCollins Pub- lishers, London, 2024)
2024
-
[61]
Wikipedia, Scrabble letter distributions (2026), accessed: 2026-03-28
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.