Recognition: unknown
GAZE: Grounded Agentic Zero-shot Evaluation with Viewer-Level Tools and Literature Retrieval on Rare Brain MRI
Pith reviewed 2026-05-09 20:51 UTC · model grok-4.3
The pith
GAZE framework enables zero-shot medical VLMs to use tools for better rare brain MRI diagnosis and localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
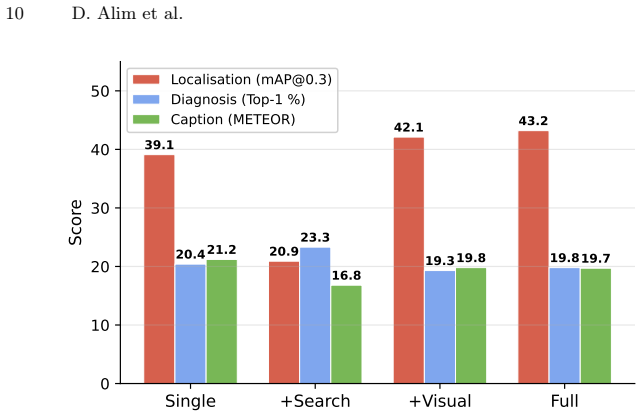
GAZE is a grounded agentic zero-shot evaluation framework that equips vision-language models with viewer-level tools for image manipulation and literature retrieval tools, leading to 58.2 mAP at IoU 0.3 for lesion localisation and 34.9% Top-1 diagnostic accuracy on the NOVA benchmark of 906 brain MRI cases spanning 281 rare conditions, all without task-specific fine-tuning. Structured prompting improves baselines, and tool usage benefits rare pathologies more than common ones, with retrieval showing model-dependent trade-offs between diagnosis and localisation.
What carries the argument
The GAZE framework's integration of viewer-level tools (zoom, windowing, contrast, edge detection) and retrieval tools (PubMed for literature, Open-i for images) with structured, schema-validated outputs and full audit traces.
If this is right
- Tool engagement correlates with larger performance gains on rare conditions, raising good localization cases from 17% to 58% for low-example diagnoses.
- Retrieval ablations show that diagnosis improvements can come at the cost of localization accuracy depending on the underlying model.
- Before tool use, schema-validated structured prompting already lifts performance from 20.2 to 29.4 mAP@0.3 over a Gemini baseline.
- Joint scoring of captioning, diagnosis, and localisation is necessary to capture the full effect of agentic workflows in medical VLMs.
Where Pith is reading between the lines
- Similar agentic tool use might generalize to other medical imaging domains like CT or X-ray for rare conditions.
- The recorded tool-call traces could enable post-hoc analysis to identify which tools contribute most to specific diagnostic improvements.
- By reducing the need for fine-tuning, this approach could accelerate deployment of diagnostic aids in low-resource settings with limited training data.
Load-bearing premise
The assumption that the introduced viewer tools and literature retrieval do not introduce new biases or artifacts, and that the NOVA benchmark fairly represents real-world diagnostic challenges for rare conditions.
What would settle it
An experiment comparing GAZE outputs to expert radiologist reports on the same NOVA cases, or showing that performance gains disappear when tool access is removed or when using a different set of rare cases not in the benchmark.
Figures

read the original abstract
Vision-language models (VLMs) read an image and produce text in a single forward pass, whereas radiologists typically inspect an image several times and consult the literature before writing a report. We introduce GAZE (Grounded Agentic Zero-shot Evaluation), a framework that lets a medical VLM work in this iterative way by calling viewer-level tools (zoom, windowing, contrast, edge detection) and two retrieval tools backed by the U.S. National Library of Medicine (PubMed for medical literature, Open-i for radiological images), with structured outputs validated against a schema and full tool-call traces recorded for auditability. On NOVA, a benchmark of 906 brain MRI cases covering 281 rare neurological conditions, GAZE reaches 58.2 mean average precision (mAP) at intersection-over-union (IoU) 0.3 for lesion localisation and 34.9% Top-1 diagnostic accuracy under a joint protocol that scores captioning, diagnosis, and localisation from the image alone, without task-specific fine-tuning. Before any tool is used, structured prompting and schema-validated outputs already improve over the published Gemini 2.0 Flash baseline (20.2 to 29.4 mAP@0.3), so framework design is itself an experimental variable. Tool use helps rare pathologies disproportionately: the fraction of cases with IoU > 0.3 rises from 17% to 58% for diagnoses with three or fewer examples versus 25% to 68% for common conditions ($\geq$10 cases), with gains tracking engagement (Gemini 3 Flash: Cohen's d = 0.79, 11.8 tool calls per case; Gemini 2.0 Flash: tools used in 8.2% of cases, no significant benefit). Retrieval ablations additionally reveal a model-dependent trade-off in which gains in diagnosis can coincide with losses in localisation, reinforcing the case for joint evaluation of diagnosis, localisation, and captioning in medical VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the GAZE framework, which enables vision-language models to perform iterative, agentic zero-shot evaluation on brain MRI by calling viewer-level tools (zoom, windowing, contrast, edge detection) and retrieval tools (PubMed literature and Open-i images), with schema-validated structured outputs and full tool traces for auditability. On the NOVA benchmark of 906 cases spanning 281 rare neurological conditions, GAZE reports 58.2 mAP at IoU 0.3 for lesion localization and 34.9% Top-1 diagnostic accuracy under a joint protocol scoring captioning, diagnosis, and localization from the image alone without task-specific fine-tuning. The work includes before/after comparisons showing structured prompting improves over the Gemini 2.0 Flash baseline (20.2 to 29.4 mAP@0.3), further gains from tool use (especially for rare cases with ≤3 examples), model-dependent retrieval ablations, and quantitative tool-engagement metrics such as Cohen's d and call counts.
Significance. If the results hold, this is a meaningful contribution to medical AI and agentic VLMs because it supplies concrete evidence that grounded tool use and literature retrieval can disproportionately aid rare-condition performance, while advocating joint evaluation of diagnosis, localization, and captioning. Strengths include the external NOVA benchmark, published baselines, ablation studies that surface trade-offs, and auditability features (schema validation, traces) that support reproducibility and falsifiability of the reported 58.2 mAP and 34.9% accuracy figures.
minor comments (3)
- Abstract and Methods: the exact prompting template used for the structured-prompting baseline (the 20.2 to 29.4 mAP improvement) and the precise schema definition for output validation are not detailed; adding these would improve replicability of the framework-design result.
- Results: the rare/common split (≤3 vs ≥10 cases) and the joint scoring protocol thresholds are defined, but a supplementary table confirming these splits are applied uniformly across all reported statistics (including ablations) would strengthen the disproportionate-benefit claim for rare pathologies.
- Results: while Cohen's d and call-count statistics are mentioned, a compact table or figure summarizing per-model tool engagement and the diagnosis-localization trade-off across retrieval ablations would enhance clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the GAZE framework, recognition of its significance for agentic VLMs in rare-disease medical imaging, and recommendation for minor revision. The report accurately reflects our contributions on the NOVA benchmark, tool-use ablations, and joint evaluation protocol.
Circularity Check
No significant circularity identified
full rationale
The paper presents GAZE as a new agentic framework for VLMs, with performance measured directly on the external NOVA benchmark of 906 cases across 281 rare conditions. Results (58.2 mAP@0.3, 34.9% Top-1 accuracy) are obtained via explicit comparisons to published baselines (Gemini 2.0 Flash at 20.2 mAP@0.3), ablations on tool use/retrieval, and quantitative tracking of engagement metrics, all defined independently of any fitted parameters or self-referential definitions. No equations reduce outputs to inputs by construction, no self-citations bear the central claims, and the joint evaluation protocol uses concrete thresholds and external standards without renaming or smuggling ansatzes. The derivation chain consists of empirical measurements against fixed benchmarks and baselines, remaining self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The NOVA benchmark of 906 cases accurately represents 281 rare neurological conditions without selection bias.
- ad hoc to paper Viewer-level tools (zoom, windowing, contrast, edge detection) and retrieval tools return useful, non-misleading information when called.
invented entities (1)
-
GAZE framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., et al.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025).https://doi.org/10.48550/arXiv.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[2]
In: ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
Banerjee, S., Lavie, A.: METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. pp. 65–72 (2005)
2005
-
[3]
Bercea, C.I., Li, J., Raffler, P.: NOVA: A benchmark for anomaly localization and clinical reasoning in brain MRI. arXiv preprint arXiv:2505.14064 (2025).https: //doi.org/10.48550/arXiv.2505.14064
-
[4]
Lan- glotz, Michael Krauthammer, and Farhad Nooralahzadeh
Bluethgen, C., Van Veen, D., Truhn, D., et al.: Agentic systems in radiology: Design, applications, evaluation, and challenges. arXiv preprint arXiv:2510.09404 (2025).https://doi.org/10.48550/arXiv.2510.09404
-
[5]
Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiology examinations for distribution and retrieval. Journal of the American Medical In- formatics Association23(2), 304–310 (2016).https://doi.org/10.1093/jamia/ ocv080
-
[6]
Drew, T., Evans, K., Võ, M.L.H., Jacobson, F.L., Wolfe, J.M.: Informatics in radiology: What can you see in a single glance and how might this guide vi- sual search in medical images? RadioGraphics33(1), 263–274 (2013).https: //doi.org/10.1148/rg.331125023
-
[7]
European Parliament and Council of the European Union: Regulation (EU) 2024/1689 of the european parliament and of the council laying down harmonised rules on artificial intelligence (AI Act) (2024)
2024
-
[8]
doi: 10.1007/s11263-009-0275-4
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL visual object classes (VOC) challenge. International Journal of Computer Vision88(2), 303–338 (2010).https://doi.org/10.1007/s11263-009-0275-4
-
[9]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Fallahpour, A., Ma, J., Munim, A.: MedRAX: Medical reasoning agent for chest x- ray. arXiv preprint arXiv:2502.02673 (2025).https://doi.org/10.48550/arXiv. 2502.02673
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[10]
arXiv preprint arXiv:2504.20930 (2025).https://doi.org/10.48550/arXiv.2504.20930
Fan, Z., Liang, C., Wu, C.: ChestX-Reasoner: Advancing radiology founda- tion models with reasoning through step-by-step verification. arXiv preprint arXiv:2504.20930 (2025).https://doi.org/10.48550/arXiv.2504.20930
-
[11]
Aura: A multi-modal medical agent for understanding, reasoning & annotation, 2025
Fathi, N., Kumar, A., Arbel, T.: AURA: A multi-modal medical agent for un- derstanding, reasoning & annotation. arXiv preprint arXiv:2507.16940 (2025). https://doi.org/10.48550/arXiv.2507.16940
-
[12]
Archives of Internal Medicine165(13), 1493–1499 (2005).https://doi.org/10
Graber, M.L., Franklin, N., Gordon, R.: Diagnostic error in internal medicine. Archives of Internal Medicine165(13), 1493–1499 (2005).https://doi.org/10. 1001/archinte.165.13.1493
2005
-
[13]
Hoopes, A., Dey, N., Butoi, V.I.: VoxelPrompt: A vision agent for end-to-end medi- cal image analysis. arXiv preprint arXiv:2410.08397 (2024).https://doi.org/10. 48550/arXiv.2410.08397
-
[14]
In: Proceedings of the 2020 Conference on Empirical Meth- ods in Natural Language Processing
Karpukhin, V., Oguz, B., Min, S., et al.: Dense passage retrieval for open-domain question answering. In: Proceedings of the 2020 Conference on Empirical Meth- ods in Natural Language Processing. pp. 6769–6781 (2020).https://doi.org/10. 18653/v1/2020.emnlp-main.550
2020
-
[15]
arXiv preprint arXiv:2511.04720 (2025)
Kim, H.Y., Li, J., Solana, A.B., et al.: Learning to reason about rare dis- eases through retrieval-augmented agents. arXiv preprint arXiv:2511.04720 (2025). https://doi.org/10.48550/arXiv.2511.04720 GAZE: Agentic Medical VLM Evaluation on Rare Brain MRI 15
-
[16]
Ct-agent: A multimodal-LLM agent for 3d CT radiology question answering, 2025
Mao, Y., Xu, W., Qin, Y., Gao, Y.: CT-Agent: A multimodal-llm agent for 3d ct radiology question answering. arXiv preprint arXiv:2505.16229 (2025).https: //doi.org/10.48550/arXiv.2505.16229
-
[17]
GOV.UK report (2025),https://www.gov.uk/government/ publications/ai-airlock-sandbox-pilot-programme-report, published 16 Oc- tober 2025
Medicines and Healthcare products Regulatory Agency: AI Airlock sandbox pi- lot programme report. GOV.UK report (2025),https://www.gov.uk/government/ publications/ai-airlock-sandbox-pilot-programme-report, published 16 Oc- tober 2025
2025
-
[18]
Qwen blog (2026), https://qwen.ai/blog?id=qwen3.5, accessed April 2026
Qwen Team: Qwen3.5: Towards native multimodal agents. Qwen blog (2026), https://qwen.ai/blog?id=qwen3.5, accessed April 2026
2026
-
[19]
Capabilities of gemini models in medicine
Saab, K., et al.: Capabilities of Gemini models in medicine. arXiv preprint arXiv:2404.18416 (2024).https://doi.org/10.48550/arXiv.2404.18416
-
[20]
Nucleic Acids Research50(D1), D20–D26 (2022).https://doi.org/10.1093/nar/gkab1112
Sayers, E.W., Bolton, E.E., Brister, J.R., et al.: Database resources of the national center for biotechnology information. Nucleic Acids Research50(D1), D20–D26 (2022).https://doi.org/10.1093/nar/gkab1112
-
[21]
Sharma, N., Agrawal, P., Banerjee, P.: CXR-Agent: Vision-language models for chest x-ray interpretation with uncertainty aware radiology reporting. arXiv preprintarXiv:2407.08811(2024).https://doi.org/10.48550/arXiv.2407.08811
-
[22]
Shen, W., Hu, Y., Liu, C., et al.: MedOpenClaw: Auditable medical imaging agents reasoning over uncurated full studies. arXiv preprint arXiv:2603.24649 (2026). https://doi.org/10.48550/arXiv.2603.24649
work page internal anchor Pith review doi:10.48550/arxiv.2603.24649 2026
-
[23]
In: International Conference on Learning Repre- sentations (2021)
Xiong, L., Xiong, C., Li, Y.: Approximate nearest neighbor negative contrastive learning for dense text retrieval. In: International Conference on Learning Repre- sentations (2021)
2021
-
[24]
Advancing multimodal medical capabilities of gemini.arXiv preprint arXiv:2405.03162, 2024
Yang, L., Xu, S., Sellergren, A., et al.: Advancing multimodal medical capabilities of Gemini. arXiv preprint arXiv:2405.03162 (2024).https://doi.org/10.48550/ arXiv.2405.03162
-
[25]
arXiv preprint arXiv:2512.02814 (2025).https://doi.org/10.48550/arXiv.2512.02814
Yu, Y., Huang, Z., Mu, L.: Radiologist copilot: An agentic framework orchestrating specialized tools for reliable radiology reporting. arXiv preprint arXiv:2512.02814 (2025).https://doi.org/10.48550/arXiv.2512.02814
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.