Recognition: unknown
Watch Your Step: Information Injection in Diffusion Models via Shadow Timestep Embedding
Pith reviewed 2026-05-09 19:34 UTC · model grok-4.3
The pith
Timestep embeddings in diffusion models can carry hidden side-channel information while preserving generation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
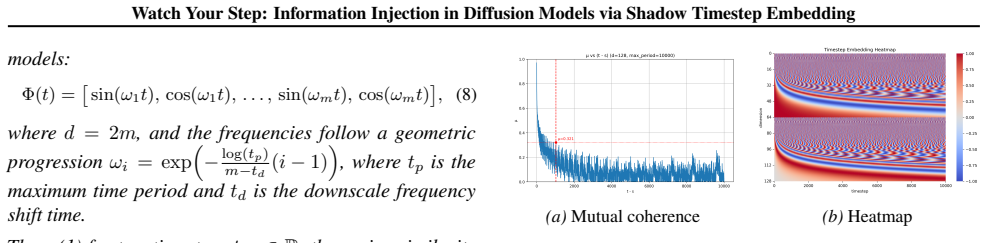
We introduce Shadow Timestep Embedding (STE) to inject malicious information by exploiting the underutilized temporal space in diffusion models. Timestep embeddings are analyzed as position-encoding mappings, and a mutual coherence evaluation is derived to show the separability of disjoint timestep intervals. This separability permits encoding of side-channel information that can be activated or controlled through the scheduler interface for attack and defense purposes, while the primary denoising task continues without measurable disruption to generation metrics.
What carries the argument
Shadow Timestep Embedding (STE), which uses the distinct representational capabilities across timestep intervals to encode and transmit side-channel data via the scheduler.
If this is right
- Side-channel information can be reliably injected and extracted through the diffusion scheduler interface.
- The timestep becomes an active vector for both adversarial attacks and defensive monitoring in generative pipelines.
- Mutual coherence between timestep intervals determines which ranges can safely carry hidden data.
- New attack and defense strategies arise by manipulating the temporal dimension rather than the spatial or noise aspects of the model.
Where Pith is reading between the lines
- Generated content could be watermarked at the timestep level for provenance tracking without altering pixel statistics.
- Detection tools might scan scheduler behavior or timestep usage patterns to flag potential covert channels.
- The same separability principle could apply to other conditioning signals in generative architectures beyond diffusion.
Load-bearing premise
Different timesteps possess distinct representational capabilities that let side-channel information be encoded without harming the main denoising task or being caught by ordinary generation quality checks.
What would settle it
Generate images while embedding a known bit string via STE across chosen timestep ranges, then measure both standard quality metrics on the outputs and the success rate of recovering the exact bit string from scheduler logs or intermediate states.
Figures






read the original abstract
Diffusion models have become the foundation of modern generative systems, with most research focusing primarily on improving generation efficiency and output quality. The timestep embedding component is a crucial part of the diffusion pipeline, which provides a temporal conditioning signal to the denoising network, enabling it to adapt its predictions across different noise levels throughout the process. Despite their potential to contain substantial information, timestep embeddings remain underexplored in current research, especially for security risks and reliable provenance. To fill this gap, we introduce Shadow Timestep Embedding (STE), a novel mechanism that investigates the underutilized temporal space for malicious information injection into diffusion models. In particular, when zooming in on the timestep embedding space, we find that different timesteps exhibit distinct representational capabilities that can encode side-channel information. Moreover, such encoded information can be utilized for attack and defense purposes through the scheduler interface. We present a theoretical analysis of timestep embeddings as position-encoding mappings and derive a mutual coherence evaluation that explains the separability of disjoint timestep intervals. Our findings reveal the diffusion model's timestep as a powerful side channel for carrying dedicated information, motivating new directions for adversarial generative modeling by understanding the temporal dimension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Shadow Timestep Embedding (STE) as a mechanism for injecting side-channel information into diffusion models by exploiting the timestep embedding space. Treating timestep embeddings as position-encoding mappings, the authors derive a mutual coherence metric to argue that disjoint timestep intervals are separable enough to encode dedicated information. This information can be used for attack and defense purposes through the scheduler interface while preserving the primary denoising task, with the central claim being that the timestep acts as a powerful, underutilized side channel in generative modeling.
Significance. If the central claim holds, the work would open new directions in adversarial generative modeling by highlighting the temporal dimension as a side channel, with potential implications for security, provenance, and robustness of diffusion-based systems. The theoretical framing of timestep embeddings as position encodings and the mutual coherence analysis represent a novel lens on conditioning mechanisms.
major comments (2)
- [Theoretical Analysis] Theoretical Analysis section: the mutual coherence evaluation establishes separability in embedding space but provides no derivation showing that this separability implies invariance of the learned score function or the final marginal distribution after the full reverse process (the load-bearing step for the claim that injected information survives sampling without detectable alteration to output statistics).
- [Mutual Coherence Evaluation] The transition from embedding-space separability to end-to-end behavior is not established: the denoising network (U-Net with shared weights) receives the modified embedding at each step, yet no analysis or experiment demonstrates that the primary noise-prediction objective remains unaffected while the side-channel signal remains recoverable or invisible to standard metrics such as FID.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit statements of the assumptions underlying the position-encoding analogy and the precise definition of the mutual coherence metric (including any normalization or interval-selection choices).
- [Method] Notation for the Shadow Timestep Embedding (STE) and its integration with the scheduler should be clarified with a diagram or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify the scope and rigor needed for our claims about Shadow Timestep Embedding. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: the mutual coherence evaluation establishes separability in embedding space but provides no derivation showing that this separability implies invariance of the learned score function or the final marginal distribution after the full reverse process (the load-bearing step for the claim that injected information survives sampling without detectable alteration to output statistics).
Authors: We agree that the mutual coherence analysis alone does not constitute a complete proof of invariance for the score function or the final marginal. The current theoretical section derives separability from the position-encoding perspective but stops short of bounding the effect on the reverse SDE. In the revision we will add a short derivation sketch in the Theoretical Analysis section that uses the coherence bound to show that the perturbation to the timestep embedding induces only a Lipschitz-bounded change in the network output, which in turn yields a controlled Wasserstein distance between the original and modified marginals after the full reverse process. This addition directly addresses the load-bearing step identified by the referee. revision: partial
-
Referee: [Mutual Coherence Evaluation] The transition from embedding-space separability to end-to-end behavior is not established: the denoising network (U-Net with shared weights) receives the modified embedding at each step, yet no analysis or experiment demonstrates that the primary noise-prediction objective remains unaffected while the side-channel signal remains recoverable or invisible to standard metrics such as FID.
Authors: We acknowledge that the manuscript would benefit from a more explicit bridge between embedding separability and end-to-end metrics. While we already report FID values and side-channel recovery rates in the experimental section, we did not include a direct ablation of the primary denoising loss under STE injection. In the revised version we will add an ablation table that compares the training and validation denoising loss (MSE on noise prediction) with and without shadow-timestep modifications, together with the corresponding FID and recovery accuracy. This will demonstrate that the shared U-Net weights continue to optimize the primary objective while the additional capacity in the timestep channel carries the side information without measurable degradation on standard generative metrics. revision: partial
Circularity Check
No significant circularity; derivation relies on independent theoretical analysis of embeddings.
full rationale
The paper's core chain treats timestep embeddings as position-encoding mappings, derives a mutual coherence metric, and uses it to argue separability of intervals for side-channel injection. This is presented as a fresh theoretical step rather than a renaming or self-referential fit. No equation or claim reduces a 'prediction' (e.g., end-to-end invariance or recoverability) to the input data or to a prior self-citation by construction. The transition from embedding separability to scheduler-level behavior is asserted but not shown to be tautological; it remains an independent (if unproven) modeling claim. Self-citations, if present, are not load-bearing for the mutual-coherence derivation itself. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Timestep embeddings act as position-encoding mappings whose representational capacity varies across intervals
invented entities (1)
-
Shadow Timestep Embedding (STE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
Journal of Information Security and Applications , volume=
Software supply chain: A taxonomy of attacks, mitigations and risk assessment strategies , author=. Journal of Information Security and Applications , volume=. 2026 , publisher=
2026
-
[6]
IEEE Communications Surveys & Tutorials , volume=
Data and model poisoning backdoor attacks on wireless federated learning, and the defense mechanisms: A comprehensive survey , author=. IEEE Communications Surveys & Tutorials , volume=. 2024 , publisher=
2024
-
[7]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[8]
Suppressed for Anonymity , author=
-
[9]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[10]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[11]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[12]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[14]
Advances in neural information processing systems , volume=
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps , author=. Advances in neural information processing systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Unipc: A unified predictor-corrector framework for fast sampling of diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Villandiffusion: A unified backdoor attack framework for diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Text-to-image diffusion models can be easily backdoored through multimodal data poisoning , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[18]
Tree-ring watermarks: Fingerprints for diffusion images that are invisible and robust , author=. arXiv preprint arXiv:2305.20030 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Robin: Robust and invisible watermarks for diffusion models with adversarial optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in neural information processing systems , volume=
Invisible image watermarks are provably removable using generative ai , author=. Advances in neural information processing systems , volume=
-
[21]
BackdoorDM: A Comprehensive Benchmark for Backdoor Learning in Diffusion Model , author=. arXiv preprint arXiv:2502.11798 , year=
-
[22]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Erasing concepts from diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[23]
European Conference on Computer Vision , pages=
Reliable and efficient concept erasure of text-to-image diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[24]
arXiv preprint arXiv:2409.11219 , year=
Score forgetting distillation: A swift, data-free method for machine unlearning in diffusion models , author=. arXiv preprint arXiv:2409.11219 , year=
-
[25]
Advances in neural information processing systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in neural information processing systems , volume=
-
[26]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Laion-400m: Open dataset of clip-filtered 400 million image-text pairs , author=. arXiv preprint arXiv:2111.02114 , year=
work page internal anchor Pith review arXiv
-
[27]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[28]
Journal of Machine Learning Research , volume=
Cascaded diffusion models for high fidelity image generation , author=. Journal of Machine Learning Research , volume=
-
[29]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review arXiv
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Fast sampling of dif- fusion models with exponential integrator
Fast sampling of diffusion models with exponential integrator , author=. arXiv preprint arXiv:2204.13902 , year=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
How to backdoor diffusion models? , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Sleepermark: Towards robust watermark against fine-tuning text-to-image diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
CopyrightShield: Enhancing Diffusion Model Security Against Copyright Infringement Attacks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[35]
32nd USENIX security symposium (USENIX Security 23) , pages=
Extracting training data from diffusion models , author=. 32nd USENIX security symposium (USENIX Security 23) , pages=
-
[36]
International Conference on Machine Learning , pages=
Are diffusion models vulnerable to membership inference attacks? , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[37]
ACM Computing Surveys , volume=
Attacks and defenses for generative diffusion models: A comprehensive survey , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[38]
for now , author=
To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Advdiffuser: Natural adversarial example synthesis with diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[40]
2024 IEEE Symposium on Security and Privacy (SP) , pages=
Nightshade: Prompt-specific poisoning attacks on text-to-image generative models , author=. 2024 IEEE Symposium on Security and Privacy (SP) , pages=. 2024 , organization=
2024
-
[41]
Expert Systems with Applications , pages=
An image steganography algorithm using selective timestep embedding and diffusion model , author=. Expert Systems with Applications , pages=. 2026 , publisher=
2026
-
[42]
Advances in Neural Information Processing Systems , volume=
Cross: Diffusion model makes controllable, robust and secure image steganography , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Scientific Reports , volume=
A deep learning-driven multi-layered steganographic approach for enhanced data security , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Hiding Images in Diffusion Models by Editing Learned Score Functions , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
Applied Soft Computing , pages=
AttenHideNet: A novel deep learning-based image steganography method using a lightweight U-net with soft attention , author=. Applied Soft Computing , pages=. 2025 , publisher=
2025
-
[46]
arXiv preprint arXiv:2407.10459 , year=
DiffStega: towards universal training-free coverless image steganography with diffusion models , author=. arXiv preprint arXiv:2407.10459 , year=
-
[47]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Stegaddpm: Generative image steganography based on denoising diffusion probabilistic model , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[48]
IEEE Transactions on Circuits and Systems for Video Technology , year=
Improved generative steganography based on diffusion model , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[49]
2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=
Diffusion-based hierarchical image steganography , author=. 2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=. 2025 , organization=
2025
-
[50]
2025 IEEE 31th International Conference on Parallel and Distributed Systems (ICPADS) , pages=
Invisible Stealthy Backdoor Attack on Diffusion Models , author=. 2025 IEEE 31th International Conference on Parallel and Distributed Systems (ICPADS) , pages=. 2025 , organization=
2025
-
[51]
arXiv preprint arXiv:2504.05815 , year=
Parasite: A Steganography-based Backdoor Attack Framework for Diffusion Models , author=. arXiv preprint arXiv:2504.05815 , year=
-
[52]
International Conference on Information Security and Cryptology , pages=
DNNKeyLock: Securing Deep Neural Network Intellectual Property with Steganography and Token Authentication , author=. International Conference on Information Security and Cryptology , pages=. 2025 , organization=
2025
-
[53]
Concurrency and Computation: Practice and Experience , volume=
Cascade Ownership Verification Framework Based on Invisible Watermark for Model Copyright Protection , author=. Concurrency and Computation: Practice and Experience , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.