Recognition: unknown
Interpretable experiential learning based on state history and global feedback
Pith reviewed 2026-05-09 19:07 UTC · model grok-4.3
The pith
A transition graph built from state histories and global feedback can match some neural networks at playing Atari Breakout while remaining interpretable and light on resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The model learns a behavioral representation as a transition graph between sets of states, where each transition is annotated with a utility value and an evidence count derived solely from accumulated state history and global feedback signals, and this structure proves sufficient to achieve reinforcement learning performance on Atari Breakout comparable to some known neural network solutions.
What carries the argument
Transition graph whose nodes are sets of states and whose edges carry utility and evidence count attributes updated from history and feedback.
If this is right
- Reinforcement learning becomes feasible in memory- and compute-limited settings without relying on neural network training.
- The learned behavior remains human-readable because decisions trace directly to specific transitions in the graph.
- The approach scales to other discrete control tasks where state histories can be recorded and grouped.
- Global feedback can drive incremental updates without requiring backpropagation or gradient-based optimization.
Where Pith is reading between the lines
- The explicit graph could let developers debug or correct agent behavior by inspecting or editing individual transitions.
- Evidence counts might naturally support confidence-weighted exploration or safety checks during deployment.
- The method could combine with neural components to handle continuous state spaces while retaining interpretability for discrete subsets.
- Resource savings could enable on-device reinforcement learning for robotics or embedded control where cloud training is unavailable.
Load-bearing premise
That grouping states into sets and accumulating utilities plus evidence counts from history and global feedback alone can capture the dynamics needed for effective policy learning.
What would settle it
Running the model on Breakout and obtaining average scores substantially below those of the neural network baselines after the same number of training episodes.
Figures
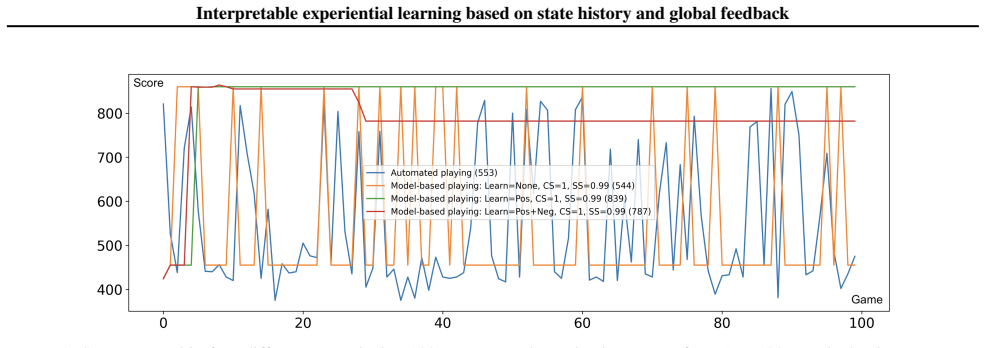


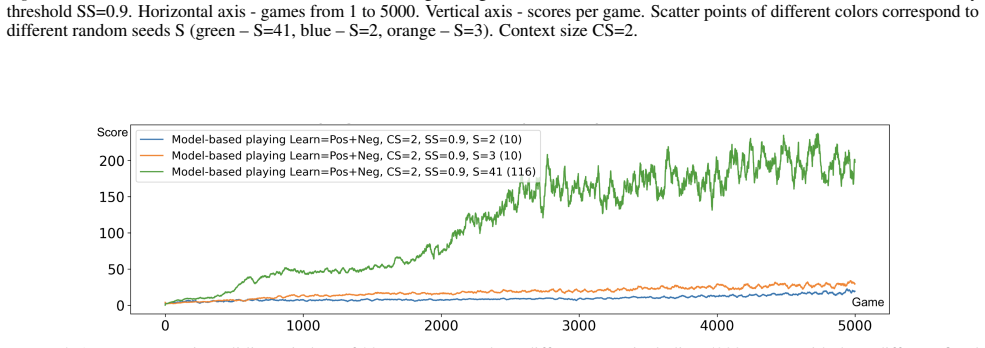

read the original abstract
A new interpretable experiential learning model based on state history and global feedback is presented. It is capable of learning a behavioral model represented by a transition graph between sets of states, with transitions attributed with utility and evidence count. This model is expected to be suitable for solving reinforcement learning problem in resource-constrained environments. The model was thoroughly evaluated on the OpenAI Gym Atari Breakout benchmark, demonstrating performance comparable to some known neural network-based solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an interpretable experiential learning model that builds a transition graph from state history and global feedback. States are grouped into sets, and transitions between them are annotated with utility values and evidence counts. The approach is positioned as suitable for reinforcement learning in resource-constrained environments, with an evaluation on the OpenAI Gym Atari Breakout benchmark claiming performance comparable to some neural-network baselines.
Significance. If the model construction, update rules, and empirical results hold, the work could provide a transparent, graph-based alternative to black-box neural RL methods, with potential advantages in interpretability and efficiency under resource limits.
major comments (1)
- [Abstract] Abstract: The central claims of model construction, suitability for resource-constrained RL, and comparable performance on Atari Breakout are asserted without any derivation, algorithm pseudocode, update equations for utility or evidence counts, quantitative metrics (e.g., scores, episodes), or explicit baseline comparisons. This absence prevents evaluation of the weakest assumption that a transition graph built from state history and global feedback can deliver effective RL.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the concern regarding the abstract below and have made revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of model construction, suitability for resource-constrained RL, and comparable performance on Atari Breakout are asserted without any derivation, algorithm pseudocode, update equations for utility or evidence counts, quantitative metrics (e.g., scores, episodes), or explicit baseline comparisons. This absence prevents evaluation of the weakest assumption that a transition graph built from state history and global feedback can deliver effective RL.
Authors: We agree that the abstract is high-level and omits explicit details on derivations, equations, pseudocode, and metrics, which is common for abstracts but can hinder immediate evaluation. The full manuscript supplies these elements: model construction and state-set transition graph in Section 2, update rules and equations for utility values and evidence counts in Section 3, the complete algorithm as pseudocode in Algorithm 1, and quantitative results (scores, episodes, and direct comparisons to neural baselines such as DQN) in Section 4 with tables and figures on the Atari Breakout benchmark. To address the comment directly, we have revised the abstract to incorporate a concise summary of the update mechanism, key performance metrics, and baseline comparisons while retaining its brevity. This revision enables readers to assess the core assumption more readily without altering the manuscript's technical content. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present only a high-level claim of a new transition-graph model learned from state history and global feedback, with empirical evaluation on Atari Breakout showing comparable performance to some neural baselines. No equations, derivations, fitted parameters renamed as predictions, self-citations, or ansatzes are visible that could reduce any load-bearing step to its own inputs by construction. The model is introduced as novel and evaluated externally, making the argument self-contained against benchmarks with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Discovering state-of-the-art reinforcement learning algorithms , author =. Nature , year =. doi:10.1038/s41586-025-09761-x , url =
-
[2]
Vouros, George A. , title =. ACM Comput. Surv. , month = dec, articleno =. 2022 , issue_date =. doi:10.1145/3527448 , abstract =
-
[3]
Neuro-Symbolic Architecture for Experiential Learning in Discrete and Functional Environments
Kolonin, Anton. Neuro-Symbolic Architecture for Experiential Learning in Discrete and Functional Environments. Artificial General Intelligence. 2022
2022
-
[4]
2025 , eprint=
Computational Concept of the Psyche (in Russian) , author=. 2025 , eprint=
2025
-
[5]
Trudy Instituta Sistemnego Analiza RAN , volume =
Goal-oriented systems, evolution, and the subjective aspect in systemology , author =. Trudy Instituta Sistemnego Analiza RAN , volume =. 2012 , publisher =
2012
-
[6]
Ekonomija Economics , author=
Mathematical Theory of Labour Motivation , year=. Ekonomija Economics , author=. doi:None , url=
-
[7]
Self in the World
Marti-5: A Mathematical Model of "Self in the World" as a First Step Toward Self-Awareness , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Benchmarking In-context Experiential Learning Through Repeated Product Recommendations , author=. 2025 , eprint=
2025
-
[9]
Representation learning: a review and new perspectives
Bengio, Yoshua and Courville, Aaron and Vincent, Pascal , title =. IEEE Trans. Pattern Anal. Mach. Intell. , month = aug, pages =. 2013 , issue_date =. doi:10.1109/TPAMI.2013.50 , abstract =
-
[10]
and Sabri, Omar and Said, Wael , TITLE =
Alginahi, Yasser M. and Sabri, Omar and Said, Wael , TITLE =. Machines , VOLUME =. 2025 , NUMBER =
2025
-
[11]
Opportunities for Reinforcement Learning in Industrial Automation , year=
Xin, Quan and Wu, Guanlin and Fang, Wenqi and Cao, Jiang and Ping, Yang , booktitle=. Opportunities for Reinforcement Learning in Industrial Automation , year=
-
[12]
Deploying Reinforcement Learning Approaches for Smart Home Automation , year=
Sen, Amit Prakash and Goyal, Manish Kumar and Shalini , booktitle=. Deploying Reinforcement Learning Approaches for Smart Home Automation , year=
-
[13]
Energies , VOLUME =
Latoń, Dominik and Grela, Jakub and Ożadowicz, Andrzej , TITLE =. Energies , VOLUME =. 2024 , NUMBER =
2024
-
[14]
Proceedings of the 1st International Workshop on MetaOS for the Cloud-Edge-IoT Continuum , pages =
Christopoulos, Marios and Spantideas, Sotirios and Giannopoulos, Anastasios and Trakadas, Panagiotis , title =. Proceedings of the 1st International Workshop on MetaOS for the Cloud-Edge-IoT Continuum , pages =. 2024 , isbn =. doi:10.1145/3642975.3678961 , abstract =
-
[15]
Accelerating Laboratory Automation Through Robot Skill Learning For Sample Scraping*,
Farooq, Ahmad and Iqbal, Kamran , year=. A Survey of Reinforcement Learning for Optimization in Automation , url=. doi:10.1109/case59546.2024.10711718 , booktitle=
-
[16]
Global Interpretability: A Computational Complexity Perspective , author=
Local vs. Global Interpretability: A Computational Complexity Perspective , author=. 2024 , eprint=
2024
-
[17]
Process Mining for Unstructured Data: Challenges and Research Directions
Koschmider, Agnes and Aleknonytė-Resch, Milda and Fonger, Frederik and Imenkamp, Christian and Lepsien, Arvid and Apaydin, Kaan and Janssen, Dominik and Langhammer, Dominic and Ziolkowski, Tobias and Zisgen, Yorck. Process Mining for Unstructured Data: Challenges and Research Directions. Modellierung 2024. doi:10.18420/modellierung2024_012
-
[18]
2025 , eprint=
Advances in Process Optimization: A Comprehensive Survey of Process Mining, Predictive Process Monitoring, and Process-Aware Recommender Systems , author=. 2025 , eprint=
2025
-
[19]
and Naddaf, Yavar and Veness, Joel and Bowling, Michael , title =
Bellemare, Marc G. and Naddaf, Yavar and Veness, Joel and Bowling, Michael , title =. J. Artif. Int. Res. , month = may, pages =. 2013 , issue_date =
2013
-
[20]
Unsupervised state representation learning in atari , year =
Anand, Ankesh and Racah, Evan and Ozair, Sherjil and Bengio, Yoshua and C\^. Unsupervised state representation learning in atari , year =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =
-
[21]
2019 , eprint=
Is Deep Reinforcement Learning Really Superhuman on Atari? Leveling the playing field , author=. 2019 , eprint=
2019
-
[22]
2013 , eprint=
Playing Atari with Deep Reinforcement Learning , author=. 2013 , eprint=
2013
-
[23]
International Conference on Learning Representations (ICLR) 2019 , year =
Recurrent Experience Replay in Distributed Reinforcement Learning , author =. International Conference on Learning Representations (ICLR) 2019 , year =
2019
-
[24]
2020 , eprint=
Never Give Up: Learning Directed Exploration Strategies , author=. 2020 , eprint=
2020
-
[25]
2020 , eprint=
Agent57: Outperforming the Atari Human Benchmark , author=. 2020 , eprint=
2020
-
[26]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and Lillicrap, Timothy and Silver, David , year=. Mastering Atari, Go, chess and shogi by planning with a learned model , volume=. Nature , publisher=. doi:1...
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4
-
[27]
2022 , eprint=
A Survey on Interpretable Reinforcement Learning , author=. 2022 , eprint=
2022
-
[28]
2023 , eprint=
Interpretable Reinforcement Learning for Robotics and Continuous Control , author=. 2023 , eprint=
2023
-
[29]
Proceedings of the 2023 15th International Conference on Machine Learning and Computing , pages =
Zhao, Chenjing and Deng, Chuanshuai and Liu, Zhenghui and Zhang, Jiexin and Wu, Yunlong and Wang, Yanzhen and Yi, Xiaodong , title =. Proceedings of the 2023 15th International Conference on Machine Learning and Computing , pages =. 2023 , isbn =. doi:10.1145/3587716.3587798 , abstract =
-
[30]
1961 , edition =
Wiener, Norbert , title =. 1961 , edition =
1961
-
[31]
2021 , eprint=
The General Theory of General Intelligence: A Pragmatic Patternist Perspective , author=. 2021 , eprint=
2021
-
[32]
Papers from the
Wang, Pei , title =. Papers from the. 2006 , pages =
2006
-
[33]
2011 , publisher =
Thinking, Fast and Slow , author =. 2011 , publisher =
2011
-
[34]
Pavel Vasilevich Simonov , title =
-
[35]
Dubynin, V. A. , title =. 2024 , note =
2024
-
[36]
1968 , address =
von Bertalanffy, Ludwig , title =. 1968 , address =
1968
-
[37]
E.E. Vityaev and A.V. Demin , keywords =. Cognitive architecture based on the functional systems theory , journal =. 2018 , note =. doi:https://doi.org/10.1016/j.procs.2018.11.072 , url =
-
[38]
Cognitive Architecture of Collective Intelligence Based on Social Evidence , journal =
Anton Kolonin and Evgenii Vityaev and Yuriy Orlov , keywords =. Cognitive Architecture of Collective Intelligence Based on Social Evidence , journal =. 2016 , note =. doi:https://doi.org/10.1016/j.procs.2016.07.467 , url =
-
[39]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume =
Cisek, Paul , title =. Philosophical Transactions of the Royal Society B: Biological Sciences , volume =. 2007 , doi =
2007
-
[40]
1996 , school =
Wang, Pei , title =. 1996 , school =
1996
-
[41]
Computable cognitive model based on social evidence and restricted by resources: Applications for personalized search and social media in multi-agent environments , year=
Kolonin, Anton , booktitle=. Computable cognitive model based on social evidence and restricted by resources: Applications for personalized search and social media in multi-agent environments , year=
-
[42]
2008 , publisher=
Probabilistic Logic Networks: A Comprehensive Framework for Uncertain Inference , author=. 2008 , publisher=
2008
-
[43]
Evgenii E. Vityaev and Leonid I. Perlovsky and Boris Ya. Kovalerchuk and Stanislav O. Speransky , keywords =. Probabilistic dynamic logic of cognition , journal =. 2013 , note =. doi:https://doi.org/10.1016/j.bica.2013.06.006 , url =
-
[44]
The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11 (2):127–138, 2010
Friston, Karl , title=. Nature Reviews Neuroscience , year=. doi:10.1038/nrn2787 , url=
-
[45]
Dawid, Anna and LeCun, Yann , year=. Introduction to latent variable energy-based models: a path toward autonomous machine intelligence , volume=. Journal of Statistical Mechanics: Theory and Experiment , publisher=. doi:10.1088/1742-5468/ad292b , number=
-
[46]
1982 , month =
Tversky, Amos and Kahneman, Daniel and Slovic, Paul , title =. 1982 , month =
1982
-
[47]
Theory of Functional Systems: A Keystone of Integrative Biology
Sudakov, Konstantin V. Theory of Functional Systems: A Keystone of Integrative Biology. Anticipation: Learning from the Past: The Russian/Soviet Contributions to the Science of Anticipation. 2015. doi:10.1007/978-3-319-19446-2_9
-
[48]
1932 , series =
Bekhterev, Vladimir Mikhailovich , title =. 1932 , series =
1932
-
[49]
1920 , address =
Freud, Sigmund , title =. 1920 , address =
1920
-
[50]
2023 , month =
Kryukov, Vladimir Germanovich , title =. 2023 , month =
2023
-
[51]
and Gorban, Pavel A
Gorban, Alexander N. and Gorban, Pavel A. and Judge, George , TITLE =. Entropy , VOLUME =. 2010 , NUMBER =
2010
-
[52]
1927 , address =
Adler, Alfred , title =. 1927 , address =
1927
-
[53]
, title =
Maslow, Abraham H. , title =. 1971 , address =
1971
-
[54]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[55]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[56]
M. J. Kearns , title =
-
[57]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[58]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[59]
Suppressed for Anonymity , author=
-
[60]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[61]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.