Recognition: unknown
ARIS: Agentic and Relationship Intelligence System for Social Robots
Pith reviewed 2026-05-09 19:22 UTC · model grok-4.3
The pith
ARIS integrates a social relationship graph and retrieval-augmented generation to improve how users rate social robots on intelligence and likeability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
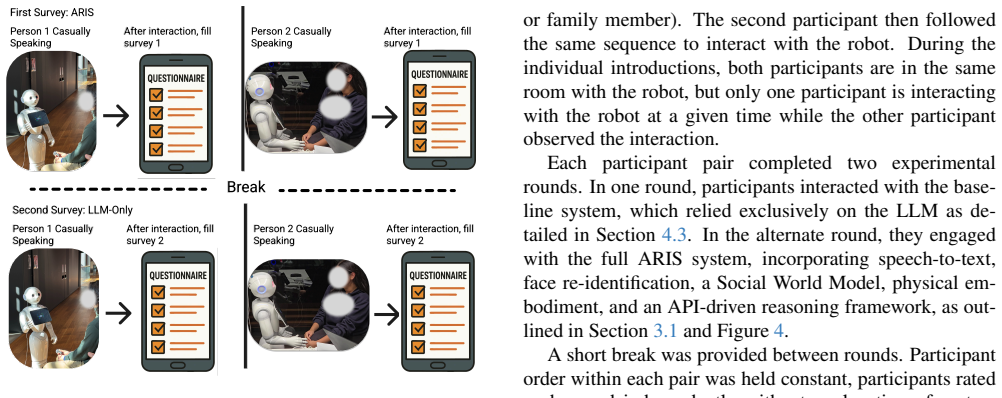
ARIS is an agentic AI framework that unifies multimodal reasoning, a graph-based Social World Model, and retrieval-augmented generation inside one modular architecture for social robots. The Social World Model maps and updates relationships between users via a knowledge graph to enable reasoning and re-identification across encounters. The RAG pipeline keeps response latency bounded even when dialogue histories reach thousands of exchanges while preserving relevance. When evaluated on the Pepper robot in dyadic conversations, ARIS produced significantly higher user ratings for intelligence, animacy, anthropomorphism, and likeability than an LLM baseline.
What carries the argument
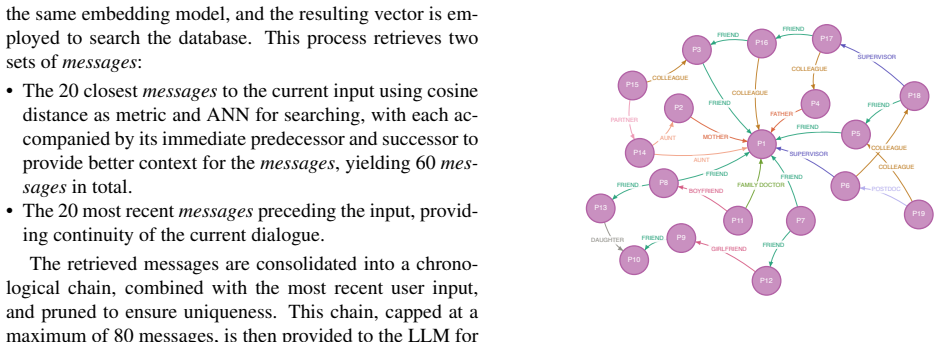
The Social World Model, a knowledge graph that explicitly tracks and refreshes social relationships among users to support reasoning and cross-encounter re-identification, together with an RAG conversational pipeline that scales dialogue history without unbounded latency.
If this is right
- Robots can track and reason about social ties across separate meetings with the same users.
- Dialogue responses stay relevant and fast even after thousands of exchanges accumulate.
- Speech, vision, and physical actions can be coordinated through structured APIs inside one agentic loop.
- The open-source release allows direct replication and extension on other robot platforms.
Where Pith is reading between the lines
- If relationship tracking proves central, similar graphs could be added to non-robot dialogue agents to improve consistency with repeat users.
- Bounded latency opens the possibility of long-term deployments where one robot maintains ongoing social context with multiple people over weeks or months.
- Linking observed physical behaviors to the relationship graph could let robots update social knowledge from vision alone during interactions.
Load-bearing premise
The measured gains in user perceptions stem from the Social World Model and RAG components rather than from other implementation choices, the specific robot platform, or details of the study design.
What would settle it
A controlled comparison that runs ARIS with the Social World Model disabled against the full system, using the same user perception scales and participant pool, would show whether the graph component is required for the reported improvements.
Figures



read the original abstract
Foundational models have advanced social robotics, enabling richer perception and communicative interaction with users. However, current systems still struggle with multi-turn engagement, social-relationship reasoning, and contextually grounded dialogue at scale. We present ARIS (Agentic and Relationship Intelligence System), an agentic AI framework that unifies multimodal reasoning, a graph-based Social World Model, and retrieval-augmented generation (RAG) within a single modular architecture for social robots. We evaluate ARIS with the Pepper robot in a robot-mediated dyadic conversational setting, comparing it against a large language model baseline. A user study (N=23) shows that ARIS yields significantly higher perceived intelligence, animacy, anthropomorphism, and likeability. Our contributions are threefold: (1)~a Social World Model that explicitly maps and updates social relationships between users through a knowledge graph, enabling social reasoning and re-identification across encounters; (2)~an efficient RAG-based conversational pipeline that maintains bounded latency as dialogue histories grow to thousands of exchanges while preserving response relevance; and (3)~system integration and empirical validation of these components within a modular agentic architecture that coordinates speech, vision, and physical action through structured APIs. The implementation of ARIS will be released as open source upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ARIS, an agentic AI framework for social robots that integrates multimodal reasoning, a graph-based Social World Model for explicit social-relationship mapping and updating, and a RAG-based conversational pipeline for bounded-latency responses. It describes system integration with the Pepper robot for dyadic interactions and reports results from a user study (N=23) claiming that ARIS produces significantly higher ratings than an LLM baseline on perceived intelligence, animacy, anthropomorphism, and likeability. Contributions center on the Social World Model, efficient RAG, and modular architecture, with a promise of open-source release.
Significance. If the empirical claims hold under rigorous controls, the work could advance social robotics by demonstrating a practical architecture for long-term relationship reasoning and scalable dialogue in physical robots. The modular design and open-source commitment would facilitate reproducibility and extension by the community.
major comments (1)
- Evaluation section (and abstract): The headline claim of significantly higher perceived intelligence, animacy, anthropomorphism, and likeability rests on a 23-person user study, yet no details are supplied on experimental protocol, task scripts, baseline agentic features or prompting, blinding/counterbalancing, statistical tests, effect sizes, exclusion criteria, or ablation results isolating the Social World Model and RAG components. Without these, the observed differences cannot be attributed to the claimed mechanisms rather than confounds such as latency, speech quality, or overall integration.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. The feedback highlights important gaps in the reporting of our user study, and we will revise the manuscript accordingly to improve transparency and allow proper evaluation of the results.
read point-by-point responses
-
Referee: Evaluation section (and abstract): The headline claim of significantly higher perceived intelligence, animacy, anthropomorphism, and likeability rests on a 23-person user study, yet no details are supplied on experimental protocol, task scripts, baseline agentic features or prompting, blinding/counterbalancing, statistical tests, effect sizes, exclusion criteria, or ablation results isolating the Social World Model and RAG components. Without these, the observed differences cannot be attributed to the claimed mechanisms rather than confounds such as latency, speech quality, or overall integration.
Authors: We agree that the Evaluation section as currently written does not provide sufficient methodological detail. In the revised manuscript we will expand this section (and adjust the abstract) to include: a complete description of the experimental protocol and the specific task scripts used for the dyadic interactions; the exact configuration of the LLM baseline, including any agentic scaffolding and prompting approach; details on blinding, counterbalancing, participant instructions, and exclusion criteria; the statistical tests performed, exact p-values, effect sizes, and any power considerations; and a discussion of potential confounds such as latency and speech synthesis quality together with how they were measured or mitigated. Regarding ablation studies isolating the Social World Model and RAG pipeline, the original study was designed as a holistic system-level comparison; we will add any post-hoc analyses feasible with the existing data and explicitly discuss the limitations of the current design in attributing effects to individual components. These additions will allow readers to assess the strength of the claims and the role of the proposed mechanisms. revision: yes
Circularity Check
No significant circularity in system description or user study
full rationale
The paper describes an agentic framework (ARIS) with a graph-based Social World Model and RAG pipeline, then reports an empirical user study (N=23) comparing perceived intelligence, animacy, anthropomorphism, and likeability against an LLM baseline on the Pepper robot. No equations, fitted parameters, predictions, or derivation chains appear in the provided text or abstract. The central claims rest on the user study outcomes rather than any self-referential reduction, self-citation load-bearing premise, or ansatz smuggled via prior work. This is a standard system-plus-evaluation paper with no load-bearing steps that collapse by construction to their inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Social World Model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jibo social robotic research platform. 1
-
[2]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Cheb- otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Ir- pan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kua...
work page internal anchor Pith review arXiv 2022
-
[3]
Christoph Bartneck, Dana Kuli ´c, Elizabeth Croft, and Su- sana Zoghbi. Measurement instruments for the anthropo- morphism, animacy, likeability, perceived intelligence, and perceived safety of robots.International Journal of Social Robotics, 1(1):71–81, 2009-01-01. 6
2009
-
[4]
Social robotics
Cynthia Breazeal, Kerstin Dautenhahn, and Takayuki Kanda. Social robotics. InSpringer Handbook of Robotics, pages 1935–1972. Springer International Publishing, 2016. 1, 2
1935
-
[5]
Yaran Chen, Wenbo Cui, Yuanwen Chen, Mining Tan, Xinyao Zhang, Dongbin Zhao, and He Wang. RoboGPT: an intelligent agent of making embodied long-term decisions for daily instruction tasks, 2024. eprint: 2311.15649. 1, 2
-
[6]
Human-robot interaction using retrieval-augmented generation and fine-tuning with trans- former neural networks in industry 5.0.Scientific Reports, 15(1):29233, 2025-08-10
Hamed Fazlollahtabar. Human-robot interaction using retrieval-augmented generation and fine-tuning with trans- former neural networks in industry 5.0.Scientific Reports, 15(1):29233, 2025-08-10. 2
2025
-
[7]
Understanding sophia? on human interac- tion with artificial agents.Phenomenology and the Cognitive Sciences, 23(1):21–42, 2024-02-01
Thomas Fuchs. Understanding sophia? on human interac- tion with artificial agents.Phenomenology and the Cognitive Sciences, 23(1):21–42, 2024-02-01. 1
2024
-
[8]
Luca Garello, Giulia Belgiovine, Gabriele Russo, Francesco Rea, and Alessandra Sciutti. Building knowledge from in- teractions: An LLM-based architecture for adaptive tutoring and social reasoning, 2025. eprint: 2504.01588. 2
-
[9]
Kochenderfer, Shayegan Omid- shafiei, and Ali-akbar Agha-mohammadi
Muhammad Fadhil Ginting, Dong-Ki Kim, Sung-Kyun Kim, Bandi Jai Krishna, Mykel J. Kochenderfer, Shayegan Omid- shafiei, and Ali-akbar Agha-mohammadi. SayComply: Grounding field robotic tasks in operational compliance through retrieval-based language models. In2025 IEEE International Conference on Robotics and Automation ( ICRA), pages 13730–13736, 2025. 2
2025
-
[10]
A comprehensive survey of retrieval-augmented generation (RAG): Evolution, current landscape and future directions,
Shailja Gupta, Rajesh Ranjan, and Surya Narayan Singh. A comprehensive survey of retrieval-augmented generation (RAG): Evolution, current landscape and future directions,
- [11]
-
[12]
”this really lets us see the entire world:” de- signing a conversational telepresence robot for homebound older adults
Yaxin Hu, Laura Stegner, Yasmine Kotturi, Caroline Zhang, Yi-Hao Peng, Faria Huq, Yuhang Zhao, Jeffrey P Bigham, and Bilge Mutlu. ”this really lets us see the entire world:” de- signing a conversational telepresence robot for homebound older adults. InProceedings of the 2024 ACM Designing Interactive Systems Conference, pages 2450–2467. Associa- tion for ...
2024
-
[13]
Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hos- seini, Fabio Petroni, Timo Schick, Jane A. Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Few-shot learning with retrieval augmented language models.J. Mach. Learn. Res., 24:251:1–251:43, 2022. 2
2022
-
[14]
Philip N. Johnson-Laird. Mental models and hu- man reasoning.Proceedings of the National Academy of Sciences, 107(43):18243–18250, 2010. eprint: https://www.pnas.org/doi/pdf/10.1073/pnas.1012933107. 2
-
[15]
HYDRA: A hy- per agent for dynamic compositional visual reasoning, 2024
Fucai Ke, Zhixi Cai, Simindokht Jahangard, Weiqing Wang, Pari Delir Haghighi, and Hamid Rezatofighi. HYDRA: A hy- per agent for dynamic compositional visual reasoning, 2024. eprint: 2403.12884. 2, 9
-
[16]
Fucai Ke, Joy Hsu, Zhixi Cai, Zixian Ma, Xin Zheng, Xindi Wu, Sukai Huang, Weiqing Wang, Pari Delir Haghighi, Gho- lamreza Haffari, Ranjay Krishna, Jiajun Wu, and Hamid Rezatofighi. Explain before you answer: A survey on com- positional visual reasoning.ArXiv, abs/2508.17298, 2025. 2
-
[17]
Kim, Christine P
Callie Y . Kim, Christine P. Lee, and Bilge Mutlu. Un- derstanding large-language model (LLM)-powered human- robot interaction. InProceedings of the 2024 ACM/IEEE In- ternational Conference on Human-Robot Interaction, pages 371–380. Association for Computing Machinery, 2024. 1, 2, 6
2024
-
[18]
Yayu Long, Kewei Chen, Long Jin, and Mingsheng Shang. DRAE: Dynamic retrieval-augmented expert networks for lifelong learning and task adaptation in robotics.ArXiv, abs/2507.04661, 2025. 2
-
[19]
Social group human-robot in- teraction: A scoping review of computational challenges
Massimiliano Nigro, Emmanuel Akinrintoyo, Nicole Sa- lomons, and Micol Spitale. Social group human-robot in- teraction: A scoping review of computational challenges. In Proceedings of the 2025 ACM/IEEE International Confer- ence on Human-Robot Interaction (HRI), 2025. 2
2025
-
[20]
New embedding models and API updates, 2024- 01-25
OpenAI. New embedding models and API updates, 2024- 01-25. 3, 4
2024
-
[21]
A mass-produced sociable humanoid robot: Pepper: The first machine of its kind.IEEE Robotics & Automation Magazine, PP:1–1, 2018-07
Amit Kumar Pandey and Rodolphe Gelin. A mass-produced sociable humanoid robot: Pepper: The first machine of its kind.IEEE Robotics & Automation Magazine, PP:1–1, 2018-07. 3
2018
-
[22]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInterna- tional Conference on Machine Learning, 2022. 3, 6
2022
-
[23]
EmbeddingGemma: Powerful and lightweight text representations
Henrique* Schechter Vera, Sahil* Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Al- ice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, Weiyi Wang, Zhe Li, Gus Martins, Jinhyuk Lee, Mark Sher- wood, Juyeong Ji, Renji...
2025
-
[24]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Can- cedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.ArXiv, abs/2302.04761,
work page internal anchor Pith review arXiv
-
[25]
R ¨uppel, Rishi Hazra, Andrey Rudenko, Martin Magnusson, and Achim J
Tim Schreiter, Jens V . R ¨uppel, Rishi Hazra, Andrey Rudenko, Martin Magnusson, and Achim J. Lilienthal. Evaluating efficiency and engagement in scripted and llm- enhanced human-robot interactions, 2025. 1
2025
-
[26]
Rutav Shah, Albert Yu, Yifeng Zhu, Yuke Zhu, and Roberto Mart´ın-Mart´ın. BUMBLE: Unifying reasoning and acting with vision-language models for building-wide mobile ma- nipulation, 2024. eprint: 2410.06237. 1, 2, 3
-
[27]
Retrieving memory content from a cognitive architecture by impressions from language models for use in a social robot.Applied Sciences, 15(10), 2025
Thomas Sievers and Nele Russwinkel. Retrieving memory content from a cognitive architecture by impressions from language models for use in a social robot.Applied Sciences, 15(10), 2025. 3
2025
-
[28]
ViperGPT: Visual inference via python execution for reasoning.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 11854–11864, 2023
D’idac Sur’is, Sachit Menon, and Carl V ondrick. ViperGPT: Visual inference via python execution for reasoning.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 11854–11864, 2023. 2
2023
-
[29]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montse Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauz´a, Michiel Blokzijl, Steven Bohez, Konstantinos Bousmalis, Anthony Brohan, Thomas Buschmann, Arunk- umar Byravan, Serkan Cabi, Ken Caluwaerts, Federico Casarini, Os-car Chang, Jos ´e Enriqu...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.