Recognition: unknown
SURGE: SuperBatch Unified Resource-efficient GPU Encoding for Heterogeneous Partitioned Data
Pith reviewed 2026-05-09 18:11 UTC · model grok-4.3
The pith
SURGE streams GPU encoding over heterogeneous partitions at fixed-batch throughput with O(B_min + n_max) memory instead of O(N).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a streaming two-threshold policy, grounded in a cost model (Theorem 1) that predicts throughput within 2 percent and a memory-safety bound (Lemma 3) limiting peak memory to O(B_min + n_max), allows encoding of heterogeneous partitioned data on GPUs to match fixed-batch throughput while using 12.6 times less memory, delivering 68 times faster time-to-first-output, and enabling crash recovery at SuperBatch granularity.
What carries the argument
The streaming two-threshold policy with SuperBatch granularity, enabled by the memory-safety bound and cost model for unified resource-efficient encoding across partitions.
Load-bearing premise
The cost model and memory-safety bound accurately predict throughput and enable safe streaming for the heterogeneous partitions and encoders in the workload.
What would settle it
Run the system on a 100 million text dataset with the same log-normal partition sizes and measure whether peak memory remains near 3 GB while throughput stays within 2 percent of the fixed-batch baseline.
Figures






read the original abstract
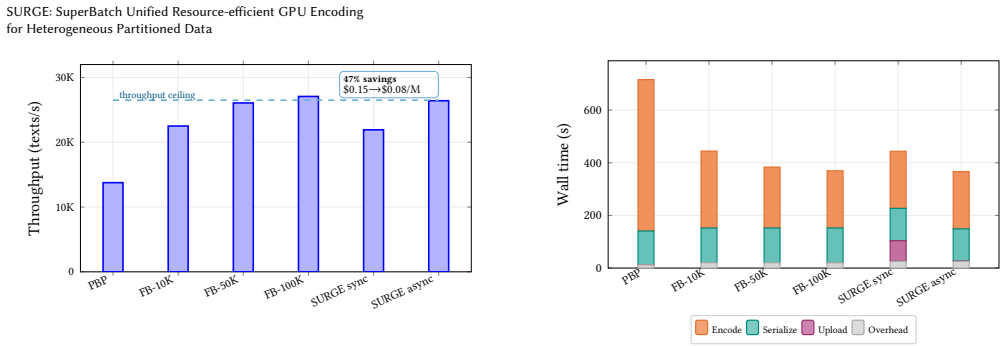
We present SURGE, a streaming GPU encoding system deployed in production to generate embeddings for over 800 million texts across 40,000 logical partitions. Production embedding pipelines face a tension between logical data partitioning and efficient GPU utilization: processing each partition independently incurs $P$ inter-process communication (IPC) calls whose overhead limits throughput for compute-light models. Our contributions are analytical: (i) a cost model (Theorem 1) predicting throughput within 2% across three encoders spanning a 15$\times$ parameter range; (ii) a memory-safety bound (Lemma 3) enabling a streaming two-threshold policy with peak memory $O(B_{\min} + n_{\max})$ rather than $O(N)$; and (iii) a $\phi$/CV decision framework characterizing when the pattern applies beyond our workload. The naive fix of batching at fixed size requires $O(N)$ peak memory (32.7 GB at 10M texts; infeasible beyond ~60M on 192 GB nodes), produces no output until all encoding completes, and offers no fault tolerance. SURGE achieves the same throughput with $O(B_{\min} + n_{\max})$ bounded memory (2.6 GB), 68$\times$ faster time-to-first-output, and crash recovery at SuperBatch granularity. On 10M texts with 4 NVIDIA L4 GPUs, SURGE delivers 26,413 texts/s -- matching fixed-batch throughput while using 12.6$\times$ less memory. We validate on bge-base (109M, $d$=768, error 1.3%) and across log-normal $\sigma$ in {1.0, 1.72, 2.5} (speedup invariant within $\pm$3%), and compare against a partition-batched baseline (PB-PBP-LB), against which SURGE retains a 7% throughput edge and 2.5$\times$ faster TTFO. Complementary engineering -- zero-copy Arrow serialization (22-25$\times$ speedup) and async I/O pipelining (up to 93% benefit) -- realizes the design but is not the contribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SURGE, a streaming GPU encoding system for heterogeneous partitioned data in production embedding pipelines. It contributes an analytical cost model (Theorem 1) claimed to predict throughput within 2% across three encoders, a memory-safety bound (Lemma 3) enabling a two-threshold streaming policy with peak memory O(B_min + n_max) instead of O(N), and a phi/CV framework for characterizing applicability. The system is reported to match fixed-batch throughput (26,413 texts/s on 10M texts with 4 L4 GPUs) while using 12.6x less memory (2.6 GB vs 32.7 GB), achieving 68x faster time-to-first-output and crash recovery, with validation across log-normal sigmas {1.0, 1.72, 2.5} and encoders including bge-base.
Significance. If the cost model and memory bound hold as stated, the work addresses a practical tension in large-scale embedding generation by enabling efficient GPU utilization without prohibitive memory or latency costs, while adding fault tolerance. The quantitative results across encoders, distributions, and baselines (including 7% throughput edge over partition-batched) suggest robustness, and the analytical framing (if substantiated with derivations) provides a reusable decision framework beyond the specific workload.
major comments (2)
- [Theorem 1] Theorem 1: The cost model is presented as predicting throughput within 2% across encoders and distributions, but the explicit derivation, model equations, parameter definitions, and full error analysis (including per-encoder and per-sigma breakdowns) are not provided in sufficient detail to verify that the 2% figure reflects genuine prediction rather than post-hoc agreement. This is load-bearing for the central analytical contribution.
- [Lemma 3] Lemma 3: The memory-safety bound O(B_min + n_max) is central to the streaming policy and the claimed reduction from 32.7 GB to 2.6 GB. The proof assumptions (e.g., on partition size heterogeneity and the two-threshold policy) and any dependence on total dataset size N require explicit expansion to confirm generality beyond the tested 10M-text log-normal cases.
minor comments (2)
- The abstract states validation 'within 2%' and 'within ±3%' but does not include a table or figure summarizing exact measured vs. predicted throughput values per encoder and sigma; adding such a summary would improve verifiability.
- The phi/CV framework is introduced to characterize applicability beyond tested distributions, but its precise definition and decision thresholds are not elaborated; a short formal statement or pseudocode would clarify its use.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable comments. We provide point-by-point responses to the major comments, clarifying the analytical contributions and committing to revisions where additional detail is needed to substantiate the claims.
read point-by-point responses
-
Referee: [Theorem 1] Theorem 1: The cost model is presented as predicting throughput within 2% across encoders and distributions, but the explicit derivation, model equations, parameter definitions, and full error analysis (including per-encoder and per-sigma breakdowns) are not provided in sufficient detail to verify that the 2% figure reflects genuine prediction rather than post-hoc agreement. This is load-bearing for the central analytical contribution.
Authors: We acknowledge that the presentation of Theorem 1 could benefit from more explicit detail. The cost model derivation is outlined in Section 4, with the 2% accuracy validated empirically across the three encoders and sigma values in Table 3 and Figure 5. To enable full verification, we will include the complete step-by-step derivation, all model equations, parameter definitions, and a detailed error analysis with per-encoder and per-sigma breakdowns in an expanded appendix in the revised manuscript. revision: yes
-
Referee: [Lemma 3] Lemma 3: The memory-safety bound O(B_min + n_max) is central to the streaming policy and the claimed reduction from 32.7 GB to 2.6 GB. The proof assumptions (e.g., on partition size heterogeneity and the two-threshold policy) and any dependence on total dataset size N require explicit expansion to confirm generality beyond the tested 10M-text log-normal cases.
Authors: We agree that the assumptions underlying Lemma 3 should be stated more explicitly. The bound holds under the two-threshold policy where batches are formed to respect memory limits, with n_max being the largest partition size and B_min the minimum batch size, and it is independent of total N due to the streaming nature. We will expand the proof in the appendix to detail the assumptions on heterogeneity (log-normal distributions with the tested sigmas) and the policy, including a discussion of generality to other distributions where partition sizes are bounded. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper's central contributions are an analytical cost model (Theorem 1) that predicts throughput within 2% across encoders and a memory-safety bound (Lemma 3) enabling O(B_min + n_max) streaming, both presented as independent derivations validated on external 10M-text workloads with log-normal distributions and multiple baselines. These do not reduce to fitted parameters by construction, self-citations, or ansatzes imported from prior author work; the phi/CV framework further characterizes applicability without circularity. No load-bearing step matches any enumerated pattern, and the claims rest on mathematical bounds plus empirical matching to fixed-batch throughput.
Axiom & Free-Parameter Ledger
free parameters (2)
- B_min
- n_max
axioms (3)
- domain assumption Throughput can be modeled analytically by Theorem 1 with accuracy within 2% across encoders spanning 15x parameter range.
- domain assumption Memory-safety bound of Lemma 3 enables streaming policy with peak memory O(B_min + n_max) rather than O(N).
- domain assumption The phi/CV decision framework characterizes when the streaming pattern applies beyond the tested workload.
Reference graph
Works this paper leans on
-
[1]
Tyler Akidau, Robert Bradshaw, Craig Chambers, Slava Chernyak, Rafael J Fernández-Moctezuma, Reuven Lax, Sam McVeety, Daniel Mills, Frances Perry, Eric Schmidt, and Sam Whittle. 2015. The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out- of-Order Data Processing. InProceedings of VLDB, Vol. 8
2015
-
[2]
Apache Software Foundation. 2024. Apache Arrow. https://arrow.apache.org
2024
-
[3]
Zhihao Bai, Zhen Zhang, Yibo Zhu, and Xin Jin. 2020. PipeSwitch: Fast Pipelined Context Switching for Deep Learning Applications. InProceedings of OSDI
2020
-
[4]
Alexander Borzunov, Dmitry Baranchuk, Tim Dettmers, Max Ryabinin, Younes Belkada, Artem Chumachenko, Pavel Samygin, and Colin Raffel. 2023. Petals: Collaborative Inference and Fine-tuning of Large Models. InProceedings of ACL: System Demonstrations
2023
-
[5]
Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. 2015. Apache Flink: Stream and Batch Processing in a Single Engine.IEEE Data Engineering Bulletin38, 4 (2015), 28–38
2015
-
[6]
Coffman, Jr., János Csirik, Gábor Galambos, Silvano Martello, and Daniele Vigo
Edward G. Coffman, Jr., János Csirik, Gábor Galambos, Silvano Martello, and Daniele Vigo. 2013. Bin Packing Approximation Algorithms: Survey and Clas- sification. InHandbook of Combinatorial Optimization. Springer
2013
-
[7]
Coffman, Jr., Michael R
Edward G. Coffman, Jr., Michael R. Garey, and David S. Johnson. 1978. An Ap- plication of Bin-Packing to Multiprocessor Scheduling.SIAM J. Comput.7, 1 (1978), 1–17
1978
-
[8]
Daniel Crankshaw, Gur-Eyal Sela, Xiangxi Mo, Corey Zuber, Ion Stoica, Joseph Gonzalez, and Alexey Tumanov. 2020. InferLine: Latency-Aware Provisioning and Scaling for Prediction Serving Pipelines. InProceedings of SoCC
2020
-
[9]
Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J Franklin, Joseph E Gon- zalez, and Ion Stoica. 2017. Clipper: A Low-Latency Online Prediction Serving System. InProceedings of NSDI
2017
-
[10]
Dask Development Team. 2024. Dask: Library for dynamic task scheduling. https://dask.org
2024
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Under- standing. InProceedings of NAACL-HLT
2019
-
[12]
1971.An Introduction to Probability Theory and Its Applications (2nd ed.)
William Feller. 1971.An Introduction to Probability Theory and Its Applications (2nd ed.). Vol. 2. Wiley
1971
-
[13]
Google Cloud. 2024. Google Cloud Storage: Performance and Latency. https: //cloud.google.com/storage/docs/performance
2024
-
[14]
Arpan Gujarati, Reza Karber, Srikanth Kandula, Boris Calder, Peter Bodik, Paramvir Bahl, and Peter Druschel. 2020. Serving DNNs like Clockwork: Per- formance Predictability from the Bottom Up. InProceedings of OSDI
2020
-
[15]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. InProceedings of ICML
2020
-
[16]
Mingcong Han, Hanze Zhang, Rong Chen, and Haibo Chen. 2022. REEF: Fast, Ef- ficient, and Energy-Aware Microsecond-Scale Preemption for Concurrent GPU- Accelerated DNN Inferences. InProceedings of OSDI
2022
-
[17]
Kim Hazelwood, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov, Mohamed Fawzy, Bill Jia, Yangqing Jia, Aditya Kalro, et al
-
[18]
InProceedings of HPCA
Applied Machine Learning at Facebook: A Datacenter Infrastructure Per- spective. InProceedings of HPCA
-
[19]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and Zhifeng Chen. 2019. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. InProceedings of NeurIPS
2019
-
[20]
Hugging Face. 2024. Text Embeddings Inference. https://github.com/ huggingface/text-embeddings-inference
2024
-
[21]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[22]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of EMNLP
2020
-
[23]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Mem- ory Management for Large Language Model Serving with PagedAttention. In Proceedings of SOSP
2023
-
[24]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, and Ion Sto- ica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. InProceedings of OSDI
2023
-
[25]
Zhuoran Liu, Leqi Zou, Xuan Zou, Caihua Wang, Biao Zhang, Da Tang, Bolin Zhu, Yijie Zhu, Peng Wu, Ruiming Wang, and Ping Li. 2022. Monolith: Real Time Recommendation System With Collisionless Embedding Table. InRecSys Workshop
2022
-
[26]
Microsoft DeepSpeed Team. 2023. DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. https://www. deepspeed.ai/inference/
2023
-
[27]
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applica- tions. InProceedings of OSDI
2018
-
[28]
Dheevatsa Mudigere, Yuchen Hao, Jianyu Huang, Zhihao Jia, Andrew Tulloch, Srinivas Sridharan, Xing Liu, Mustafa Ozdal, Jiadong Nie, Jongsoo Park, et al
-
[29]
InProceedings of ISCA
Software-Hardware Co-design for Fast and Scalable Training of Deep Learning Recommendation Models. InProceedings of ISCA
-
[30]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized Pipeline Parallelism for DNN Training. InProceedings of SOSP
2019
-
[31]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, et al. 2019. Deep Learning Recommendation Model for Personalization and Recommendation Systems.arXiv preprint arXiv:1906.00091 (2019)
work page Pith review arXiv 2019
-
[32]
NVIDIA. 2023. DALI: Data Loading Library. https://github.com/NVIDIA/DALI
2023
-
[33]
NVIDIA. 2023. Triton Inference Server. https://github.com/triton-inference- server/server
2023
-
[34]
NVIDIA. 2024. RAPIDS: Open GPU Data Science. https://rapids.ai
2024
-
[35]
Christopher Olston, Noah Fiedel, Kirill Gorovoy, Jeremiah Harmsen, Li Lao, Fangwei Li, Vinu Rajashekhar, Suresh Ramesh, and Jordan Soyke. 2017. TensorFlow-Serving: Flexible, High-Performance ML Serving. InWorkshop on ML Systems at NeurIPS
2017
-
[36]
PyTorch. 2023. TorchServe. https://github.com/pytorch/serve
2023
-
[37]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of EMNLP-IJCNLP
2019
-
[38]
Nils Reimers and Iryna Gurevych. 2020. Making Monolingual Sentence Embed- dings Multilingual using Knowledge Distillation. InProceedings of EMNLP
2020
-
[39]
Geet Sethi, Bilge Acun, Berkin Akin, Newsha Mnih, Maxim Naumov, Carole- Jean Wu, and Zhihao Jia. 2022. RecShard: Statistical Feature-Based Memory Optimization for Industry-Scale Neural Recommendation. InProceedings of AS- PLOS
2022
-
[40]
Haichen Shen, Lequn Chen, Yuchen Jin, Lijie Zhao, Bingqing Kong, Matthai Philipose, Arvind Krishnamurthy, and Ravi Sundaram. 2019. Nexus: A GPU Cluster Engine for Accelerating DNN-Based Video Analysis. InProceedings of SOSP
2019
-
[41]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. InProceedings of ICML
2023
-
[42]
Chijun Sima, Yao Fu, Man-Kit Sit, Liyi Guo, Xuri Gong, Feng Lin, Junyu Wu, Yongsheng Li, Haidong Rong, Pierre-Louis Aublin, and Luo Bi. 2022. Ekko: A Large-Scale Deep Learning Recommender System with Low-Latency Model Up- date. InProceedings of OSDI
2022
-
[43]
Abraham Wald. 1944. On Cumulative Sums of Random Variables.The Annals of Mathematical Statistics15, 3 (1944), 283–296
1944
-
[44]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text Embeddings by Weakly-Supervised Contrastive Pre-training.arXiv preprint arXiv:2212.03533(2022)
work page internal anchor Pith review arXiv 2022
-
[45]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
-
[46]
InProceedings of NeurIPS
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. InProceedings of NeurIPS
-
[47]
Qizhen Weng, Wencong Xiao, Yiwei Yu, Wei Wang, Cheng Wang, Jian He, Yongkun Li, Lixin Zhang, Wei Lin, and Yu Ding. 2023. Beware of Fragmentation: Scheduling GPU-Sharing Workloads with Fragmentation Gradient Descent. In Proceedings of USENIX ATC. 103–117
2023
-
[48]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian- Yun Nie. 2024. C-Pack: Packed Resources For General Chinese Embeddings. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
2024
-
[49]
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. 2018. Gandiva: Introspective Cluster Sched- uling for Deep Learning. InProceedings of OSDI
2018
-
[50]
Wencong Xiao, Shiru Ren, Yong Li, Yang Zhang, Pengyang Hou, Zhi Li, Yihui Feng, Wei Lin, and Yangqing Jia. 2020. AntMan: Dynamic Scaling on GPU Clus- ters for Deep Learning. InProceedings of OSDI
2020
-
[51]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Gener- ative Models. InProceedings of OSDI. 14 SURGE: SuperBatch Unified Resource-efficient GPU Encoding for Heterogeneous Partitioned Data
2022
-
[52]
Matei Zaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, and Ion Stoica. 2013. Discretized Streams: Fault-Tolerant Streaming Computation at Scale. InProceedings of SOSP
2013
-
[53]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kober, Ying Sheng, Joseph E Gonzalez, Ion Stoica, and Hao Zhang. 2023. Efficiently Programming Large Language Models using SGLang.arXiv preprint arXiv:2312.07104(2023). 15
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.