Recognition: unknown
PRISM: Exposing and Resolving Spurious Isolation in Federated Multimodal Continual Learning
Pith reviewed 2026-05-09 14:30 UTC · model grok-4.3
The pith
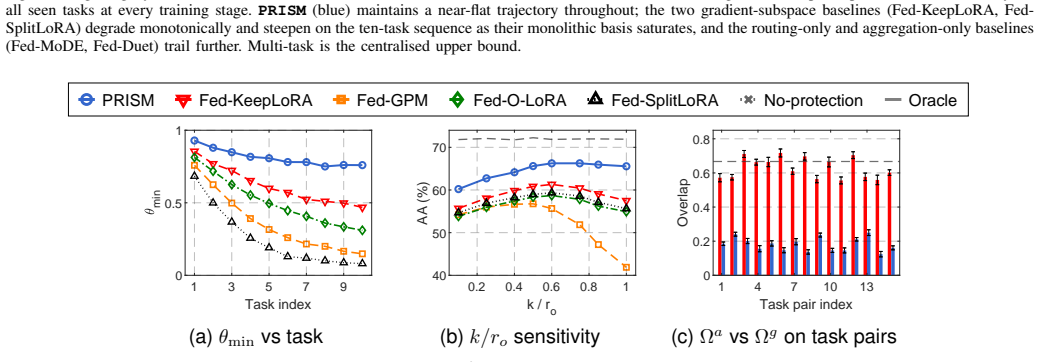
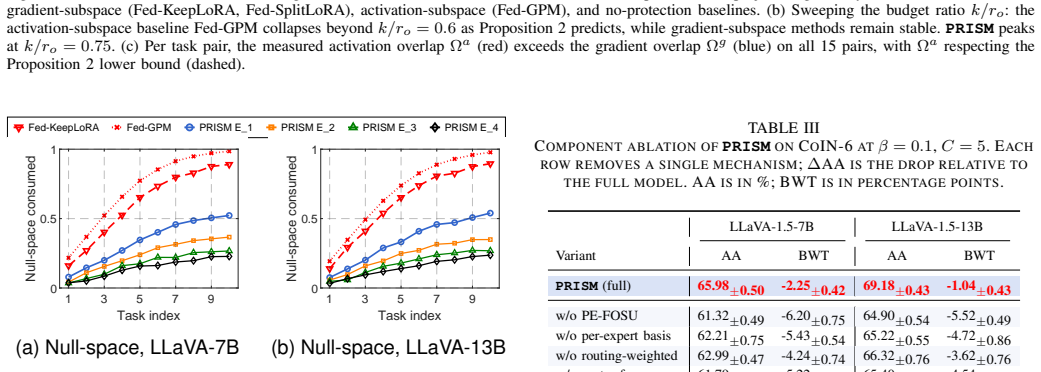
PRISM shows that per-sample routing in MoE-LoRA fails to isolate task knowledge in federated multimodal continual learning, and a per-expert orthogonal gradient subspace method resolves the resulting conflicts and forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
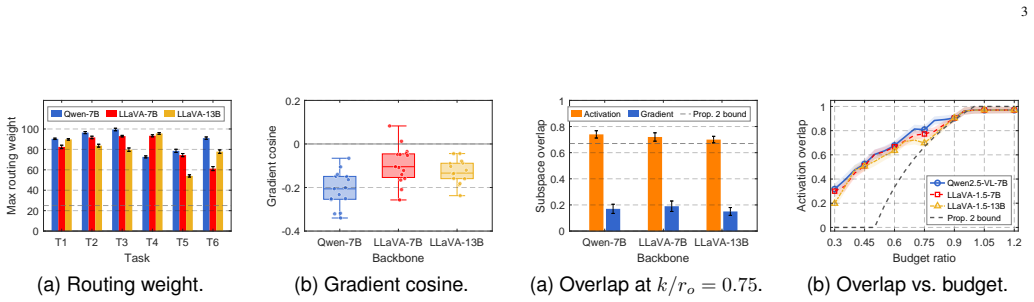
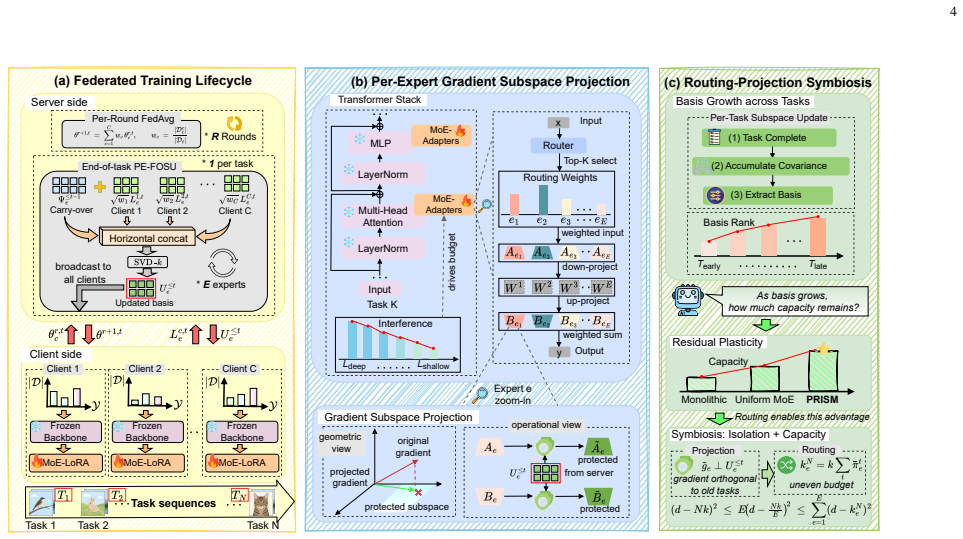
Current federated multimodal continual learning over MoE-LoRA rests on the unverified assumption that routing isolates task-specific knowledge into disjoint experts. Routing operates per-sample while forgetting accumulates across the task sequence, and gradient conflict persists within each expert even when routing is maximally polarized. Activation-subspace protection fails because under parameter-efficient fine-tuning it entangles tasks due to a dimension-counting bound, and federated averaging disrupts client-side orthogonality. PRISM maintains a per-expert gradient subspace basis whose orthogonality is preserved under FedAvg and reinterprets MoE routing as a capacity allocator. On LLaVA-
What carries the argument
The per-expert gradient subspace basis whose orthogonality is preserved under FedAvg, which resolves intra-expert gradient conflicts and forgetting while the router allocates capacity across tasks.
Load-bearing premise
That maintaining a per-expert gradient subspace basis whose orthogonality is preserved under FedAvg is both computationally feasible and sufficient to resolve gradient conflicts and forgetting without introducing new interference or requiring task-specific hyperparameter tuning.
What would settle it
If the orthogonality of the per-expert gradient subspaces is not preserved after multiple rounds of FedAvg on the CoIN-Long-10 sequence, or if the accuracy margin over the best baseline fails to widen from the short to the long task set, the claim would not hold.
Figures

read the original abstract
While current federated multimodal continual learning over mixture-of-experts low-rank adaptation (MoE-LoRA) is built on the unverified assumption that routing isolates task-specific knowledge into disjoint experts, we argue that routing operates per-sample, while forgetting accumulates across the task sequence, and gradient conflict persists within each expert even when routing is maximally polarized. Moreover, activation-subspace protection can also fail because, under parameter-efficient fine-tuning, it entangles tasks due to a dimension-counting bound, and federated averaging (FedAvg) disrupts client-side orthogonality. To address this, we propose PRISM (Per-expert Routing-projection Interference-informed Subspace Method), which maintains a per-expert gradient subspace basis whose orthogonality is preserved under FedAvg and reinterprets MoE routing as a capacity allocator. Our results show that, on LLaVA-1.5-7B, LLaVA-1.5-13B, and Qwen2.5-VL-7B across CoIN-6 and CoIN-Long-10, PRISM outperforms sixteen the state of the art baselines in average accuracy. Compared to the best federated multimodal baseline, the performance margin increases from +3.23 pp on CoIN-6 to +6.06 pp on CoIN-Long-10.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that MoE-LoRA routing in federated multimodal continual learning fails to isolate task knowledge because routing is per-sample while forgetting and gradient conflicts accumulate within experts; it further claims that activation-subspace protection is undermined by a dimension-counting bound under PEFT and by FedAvg disrupting client orthogonality. PRISM is proposed to maintain a per-expert gradient subspace basis whose orthogonality is preserved under FedAvg, while reinterpreting routing as a capacity allocator. On LLaVA-1.5-7B, LLaVA-1.5-13B and Qwen2.5-VL-7B over CoIN-6 and CoIN-Long-10, PRISM reports higher average accuracy than sixteen baselines, with the margin over the strongest federated multimodal baseline growing from +3.23 pp to +6.06 pp on the longer sequence.
Significance. If the orthogonality-preservation mechanism is shown to be both computationally feasible and sufficient to eliminate intra-expert conflicts without new interference, the work would offer a concrete advance for federated PEFT continual learning on multimodal models. The reported widening margin on longer task sequences would be particularly noteworthy if supported by ablations confirming subspace stability.
major comments (2)
- [§3] §3 (PRISM construction): the claim that the per-expert gradient subspace basis remains orthogonal after FedAvg is asserted without an explicit re-orthogonalization step (e.g., QR or Gram-Schmidt on the aggregated basis) or a proof that such a step commutes with the routing reinterpretation. Because FedAvg performs a convex combination of client parameters, the averaged weights generally rotate the subspace; this step is load-bearing for the central argument that PRISM resolves gradient conflicts and forgetting.
- [§4–5] §4–5 (experiments): the reported gains on CoIN-Long-10 (+6.06 pp) rest on the subspace-preservation property, yet no verification metric (e.g., post-FedAvg cosine similarity of basis vectors or condition-number checks) or ablation on subspace dimension is described. Without these, the link between the proposed fix and the observed improvement cannot be assessed.
minor comments (1)
- [Abstract] Abstract: 'outperforms sixteen the state of the art baselines' contains a grammatical error; should read 'sixteen state-of-the-art baselines'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of PRISM's core mechanism. We respond point-by-point to the major comments below and will incorporate revisions to strengthen both the theoretical justification and empirical validation.
read point-by-point responses
-
Referee: [§3] §3 (PRISM construction): the claim that the per-expert gradient subspace basis remains orthogonal after FedAvg is asserted without an explicit re-orthogonalization step (e.g., QR or Gram-Schmidt on the aggregated basis) or a proof that such a step commutes with the routing reinterpretation. Because FedAvg performs a convex combination of client parameters, the averaged weights generally rotate the subspace; this step is load-bearing for the central argument that PRISM resolves gradient conflicts and forgetting.
Authors: We acknowledge that the manuscript asserts orthogonality preservation under FedAvg without supplying an explicit re-orthogonalization procedure or a formal proof. We will revise §3 to include a self-contained proof showing that, under PRISM's per-expert construction (where the basis is formed from interference-informed gradient projections), the FedAvg convex combination on the low-rank parameters preserves the spanned subspace and its orthogonality properties. Because the updates are linear and the projection is applied to the same expert-specific directions on each client, the averaged basis remains orthogonal to the interference directions without rotation that would reintroduce conflicts; this commutes directly with the reinterpretation of routing as capacity allocation. No additional re-orthogonalization step is required in the algorithm, but the proof will be added for rigor. revision: yes
-
Referee: [§4–5] §4–5 (experiments): the reported gains on CoIN-Long-10 (+6.06 pp) rest on the subspace-preservation property, yet no verification metric (e.g., post-FedAvg cosine similarity of basis vectors or condition-number checks) or ablation on subspace dimension is described. Without these, the link between the proposed fix and the observed improvement cannot be assessed.
Authors: We agree that direct verification metrics and ablations are necessary to establish the causal link between subspace preservation and the widening performance margin on longer sequences. We will extend §4 and §5 with: (i) post-FedAvg cosine-similarity measurements between client-side and server-aggregated basis vectors, (ii) condition-number monitoring of the basis matrices across rounds, and (iii) a subspace-dimension ablation on both CoIN-6 and CoIN-Long-10 that reports accuracy and margin over the strongest baseline. These additions will quantify stability and confirm that the observed gains scale with the preservation property. revision: yes
Circularity Check
No significant circularity; empirical performance claims independent of any derivation chain
full rationale
The provided manuscript text contains no equations, derivations, or mathematical reductions. PRISM is introduced by asserting that it maintains a per-expert gradient subspace basis with orthogonality preserved under FedAvg and reinterprets routing as capacity allocation, but this is presented as a design choice rather than derived from prior inputs. All reported results consist of average accuracy comparisons against sixteen baselines on LLaVA and Qwen models across CoIN-6 and CoIN-Long-10, which are external empirical benchmarks and do not reduce to fitted parameters, self-definitions, or self-citation chains within the paper. No load-bearing step equates a claimed prediction or uniqueness result to its own construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Review of Continual Learning in Edge AI,
B. Wu, Z. Ding, and J. Huang, “A Review of Continual Learning in Edge AI,”IEEE Transactions on Network Science and Engineering, vol. 13, pp. 6571–6588, 2026
2026
-
[2]
“X of Information
B. Wu, J. Huang, and S. Yu, ““X of Information” Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Net- worked Systems,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 5307–5344, 2026
2026
-
[3]
Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,
B. Wu, J. Huang, Q. Duan, L. Dong, and Z. Cai, “Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,”IEEE/ACM Transactions on Networking, pp. 1–1, 2025
2025
-
[4]
A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,
Z. Ding, J. Huang, Q. Duan, C. Zhang, Y . Zhao, and S. Gu, “A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,” in2025 IEEE International Performance, Computing, and Communications Conference (IPCCC). IEEE, 2025, pp. 1–8. 13 TABLE S2 CROSS-ARCHITECTURE GENERALIZATION ONQWEN2.5-VL-7B:MAIN RESU...
2025
-
[5]
A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,
J. Huang, B. Wu, Q. Duan, L. Dong, and S. Yu, “A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,”IEEE Transactions on Mobile Computing, pp. 1–16, 2025
2025
-
[6]
Transformer-based dynamic resource allocation for multi-carrier noma systems,
L. Dong, J. Huang, and R. W. Heath, “Transformer-based dynamic resource allocation for multi-carrier noma systems,”IEEE Transactions on Cognitive Communications and Networking, vol. 12, pp. 4926–4941, 2026
2026
-
[7]
CoIN: A Benchmark of Continual Instruction Tuning for Multimodel Large Lan- guage Model,
C. Chen, J. Zhu, X. Luo, H. T. Shen, L. Gao, and J. Song, “CoIN: A Benchmark of Continual Instruction Tuning for Multimodel Large Lan- guage Model,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[8]
SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning,
Z. Wang, C. Che, Q. Wang, Y . Li, Z. Shi, and M. Wang, “SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[9]
Mitigating Intra- and Inter- modal Forgetting in Continual Learning of Unified Multimodal Models,
X. Wei, M. Munir, and R. Marculescu, “Mitigating Intra- and Inter- modal Forgetting in Continual Learning of Unified Multimodal Models,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[10]
PCLR: Progressively Compressed LoRA for Multimodal Continual Instruction Tuning,
W. Meng, J. Qiao, Z. Zhang, S. Liu, and Y . Xie, “PCLR: Progressively Compressed LoRA for Multimodal Continual Instruction Tuning,” in International Conference on Learning Representations, 2026
2026
-
[11]
Fed-Duet: Dual Expert-Orchestrated Framework for Continual Federated Vision-Language Learning,
T. Guo, J. Chen, and L. Cui, “Fed-Duet: Dual Expert-Orchestrated Framework for Continual Federated Vision-Language Learning,” in International Conference on Learning Representations, 2026
2026
-
[12]
Gradient Projection Memory for Contin- ual Learning,
G. Saha, I. Garg, and K. Roy, “Gradient Projection Memory for Contin- ual Learning,” inInternational Conference on Learning Representations, 2021
2021
-
[13]
Training Networks in Null Space of Feature Covariance for Continual Learning,
S. Wang, X. Li, J. Sun, and Z. Xu, “Training Networks in Null Space of Feature Covariance for Continual Learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 184–193
2021
-
[14]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inProceedings of the International Conference on Artificial Intelligence and Statistics, 2017
2017
-
[15]
FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,
B. Wu, J. Huang, and Q. Duan, “FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,” inInternational Conference on Wireless Artificial Intelligent Computing Systems and Applications (WASA). Springer, 2025, pp. 13–24
2025
-
[16]
Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,
Z. Ding, J. Huang, and J. Qi, “Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,” inInternational Conference on Computing, Networking and Communications (ICNC). Honolulu, Hawaii, USA: IEEE, February 2026
2026
-
[17]
En- hancing Multimodal Continual Instruction Tuning with BranchLoRA,
D. Zhang, Y . Ren, Z.-Z. Li, Y . Yu, J. Dong, C. Li, Z. Ji, and J. Bai, “En- hancing Multimodal Continual Instruction Tuning with BranchLoRA,” in Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2025. 14
2025
-
[18]
Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning,
C. Ge, X. Wang, Z. Zhang, H. Chen, J. Fan, L. Huang, H. Xue, and W. Zhu, “Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning,” inProceedings of the International Conference on Machine Learning, 2025
2025
-
[19]
HiDe-LLaV A: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model,
H. Guo, F. Zeng, Z. Xiang, F. Zhu, D.-H. Wang, X.-Y . Zhang, and C.-L. Liu, “HiDe-LLaV A: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model,” inProceedings of the Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[20]
Federated Continual Learning with Weighted Inter-client Transfer,
J. Yoon, W. Jeong, G. Lee, E. Yang, and S. J. Hwang, “Federated Continual Learning with Weighted Inter-client Transfer,” inProceedings of the International Conference on Machine Learning, 2021
2021
-
[21]
LoRAMoE: Alleviating World Knowledge Forgetting in Large Language Models via MoE-Style Plugin,
S. Dou, E. Zhou, Y . Liu, S. Gao, W. Shen, L. Xiong, Y . Zhou, X. Wang, Z. Xi, X. Fan, S. Pu, J. Zhu, R. Zheng, T. Gui, Q. Zhang, and X. Huang, “LoRAMoE: Alleviating World Knowledge Forgetting in Large Language Models via MoE-Style Plugin,” inProceedings of the Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[22]
Z. Hou, H. Guo, H. Ma, Y . Sun, Y . Yang, and J. Wang, “PASs- MoE: Mitigating Misaligned Co-drift among Router and Experts via Pathway Activation Subspaces for Continual Learning,” arXiv preprint arXiv:2601.13020, 2026
-
[23]
Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers,
A. Chen, R. Huang, X. Zhang, F. Dong, H. Cao, Z. Huang, Y . Yang, M. Chen, J. Zhou, M. Dong, Y . Wang, J. Hou, Q. Lv, R. P. Dick, Y . Cheng, T. Lu, F. Yang, and L. Shang, “Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers,” arXiv preprint arXiv:2602.12587, 2026
-
[24]
Orthogonal Subspace Learning for Language Model Continual Learning,
X. Wang, T. Chen, Q. Ge, H. Xia, R. Bao, R. Zheng, Q. Zhang, T. Gui, and X. Huang, “Orthogonal Subspace Learning for Language Model Continual Learning,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 10 658–10 671
2023
-
[25]
KeepLoRA: Continual Learning with Residual Gradient Adaptation,
M.-L. Luo, Z. Zhou, Y .-L. Zhang, Y . Wan, T. Wei, and M.-L. Zhang, “KeepLoRA: Continual Learning with Residual Gradient Adaptation,” inInternational Conference on Learning Representations, 2026
2026
-
[26]
SplitLoRA: Balancing Stability and Plasticity in Continual Learning Through Gradient Space Splitting,
Qiu, Zhang, Qiao, Guan, Zhang, and Nie, “SplitLoRA: Balancing Stability and Plasticity in Continual Learning Through Gradient Space Splitting,” inInternational Conference on Learning Representations, 2026
2026
-
[27]
SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing,
Z. Ding, B. Wu, and J. Huang, “SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing,” inProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[28]
B. Wu, Z. Ding, and J. Huang, “RELIEF: Turning Missing Modalities into Training Acceleration for Federated Learning on Heterogeneous IoT Edge,” arXiv preprint arXiv:2604.04243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Shared Spatial Memory Through Predictive Coding,
Z. Fang, Y . Guo, J. Wang, Y . Zhang, H. An, Y . Wang, and Y . Fang, “Shared Spatial Memory Through Predictive Coding,” arXiv preprint arXiv:2511.04235, 2025
-
[30]
Securing Smart Agriculture with Communication-Efficient Federated Unlearning,
U. Pudasaini, Z. Ding, and J. Huang, “Securing Smart Agriculture with Communication-Efficient Federated Unlearning,” in2026 IEEE International Conference on High Performance Switching and Routing (HPSR). IEEE, 2026, pp. 1–8
2026
-
[31]
Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,
B. Wu and W. Wu, “Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,”Mathematical Problems in Engineering, vol. 2023, no. 1, p. 6350647, 2023
2023
-
[32]
Continual Instruction Tuning for Large Multimodal Models,
J. He, H. Guo, K. Zhu, M. Tang, and J. Wang, “Continual Instruction Tuning for Large Multimodal Models,”IEEE Transactions on Image Processing, vol. 35, pp. 2699–2713, 2026
2026
-
[33]
From Alpha to Omega: Lifecycle- Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration,
B. Wu, J. Huang, and Y . Zhao, “From Alpha to Omega: Lifecycle- Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration,” inProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[34]
Federated Continual Instruction Tuning,
H. Guo, F. Zeng, F. Zhu, W. Liu, D.-H. Wang, J. Xu, X.-Y . Zhang, and C.-L. Liu, “Federated Continual Instruction Tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[35]
A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,
D. Pan, B.-N. Wu, Y .-L. Sun, and Y .-P. Xu, “A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,”Sustainable Computing: In- formatics and Systems, vol. 37, p. 100827, 2023
2023
-
[36]
Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,
Z. Fang, S. Hu, J. Wang, Y . Deng, X. Chen, and Y . Fang, “Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,”IEEE Transactions on Networking, pp. 1–17, 2025
2025
-
[37]
R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,
Z. Fang, J. Wang, Y . Ma, Y . Tao, Y . Deng, X. Chen, and Y . Fang, “R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,”IEEE Journal on Selected Areas in Communications, 2025
2025
-
[38]
Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,
B. Wu, J. Huang, and Q. Duan, “Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,”IEEE Network, vol. 40, no. 2, pp. 184–191, 2025
2025
-
[39]
A Stochastic Geometry- Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting,
C.-C. Xing, Z. Ding, and J. Huang, “A Stochastic Geometry- Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting,”SIGAPP Appl. Comput. Rev., vol. 25, no. 4, p. 18–34, Jan
-
[40]
Available: https://doi.org/10.1145/3787594.3787596
[Online]. Available: https://doi.org/10.1145/3787594.3787596
-
[41]
Orthogonal Gradient Descent for Continual Learning,
M. Farajtabar, N. Azizan, A. Mott, and A. Li, “Orthogonal Gradient Descent for Continual Learning,” inProceedings of the International Conference on Artificial Intelligence and Statistics, 2020
2020
-
[42]
OPLoRA: Orthogonal Projection LoRA Pre- vents Catastrophic Forgetting during Parameter-Efficient Fine-Tuning,
Y . Xiong and X. Xie, “OPLoRA: Orthogonal Projection LoRA Pre- vents Catastrophic Forgetting during Parameter-Efficient Fine-Tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[43]
Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems
B. Wu and J. Huang, “Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems,” arXiv preprint arXiv:2604.20745, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,
B. Wu, Z. Ding, L. Ostigaard, and J. Huang, “Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,” in2025 ACM Research on Adaptive and Convergent Systems (RACS). ACM, 2025, pp. 1–8
2025
-
[45]
Subspace Geometry Governs Catastrophic Forgetting in Low- Rank Adaptation,
B. Steele, “Subspace Geometry Governs Catastrophic Forgetting in Low- Rank Adaptation,” arXiv preprint arXiv:2603.02224, 2026
-
[46]
T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the Effects of Non- Identical Data Distribution for Federated Visual Classification,” arXiv preprint arXiv:1909.06335, 2019
-
[47]
LoRA: Low-Rank Adaptation of Large Language Models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-Rank Adaptation of Large Language Models,” inInternational Conference on Learning Representations, 2022
2022
-
[48]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wanget al., “Qwen2.5-VL Technical Report,” arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Federated Optimization in Heterogeneous Networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated Optimization in Heterogeneous Networks,” inProceedings of Machine Learning and Systems, vol. 2, 2020, pp. 429–450
2020
-
[50]
Overcoming Catastrophic Forgetting in Neural Networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming Catastrophic Forgetting in Neural Networks,”Proceedings of the Na- tional Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[51]
Learning without Forgetting,
Z. Li and D. Hoiem, “Learning without Forgetting,” inEuropean Conference on Computer Vision, 2016, pp. 614–629
2016
-
[52]
iCaRL: Incremental Classifier and Representation Learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “iCaRL: Incremental Classifier and Representation Learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2001–2010
2017
-
[53]
Gradient Episodic Memory for Contin- ual Learning,
D. Lopez-Paz and M. Ranzato, “Gradient Episodic Memory for Contin- ual Learning,” inAdvances in Neural Information Processing Systems, 2017, pp. 6467–6476
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.