Recognition: unknown
Deep Variational Inference Symbolic Regression
Pith reviewed 2026-05-09 19:15 UTC · model grok-4.3
The pith
DVISR recovers the true posterior over symbolic expressions and constants by optimizing the ELBO integrand as a reward in a neural network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DVISR recovers the true posterior in simple settings by training a neural network whose outputs define a variational distribution over expression trees and associated constants, with the evidence lower bound integrand substituted for the original reward signal.
What carries the argument
Neural network that parameterizes a variational posterior over discrete expression trees and continuous constants, optimized by using the ELBO integrand directly as the reward.
If this is right
- Uncertainty can be quantified over entire symbolic models instead of point estimates of a single expression.
- Posterior inference applies jointly to both the structure of the expression tree and the numerical constants it contains.
- The quality of posterior approximation can be examined as the size of the expression space is increased.
- The method supplies a concrete route toward Bayesian symbolic regression that remains tractable at moderate scales.
Where Pith is reading between the lines
- On problems small enough for exhaustive enumeration, direct comparison of DVISR samples to the true posterior would give a quantitative test of approximation fidelity.
- The same reward-replacement approach might be applied to other discrete search spaces in machine learning where posterior inference is desired.
- Extending the constant-distribution output to more flexible families such as mixtures could reduce bias when constants have multimodal posteriors.
Load-bearing premise
The neural network can represent the variational posterior over discrete trees and continuous constants accurately enough that optimizing the ELBO integrand yields samples from the true posterior.
What would settle it
Exact enumeration of the posterior on a small expression space and data set, followed by direct comparison of the sampled distribution from DVISR to the enumerated distribution.
Figures



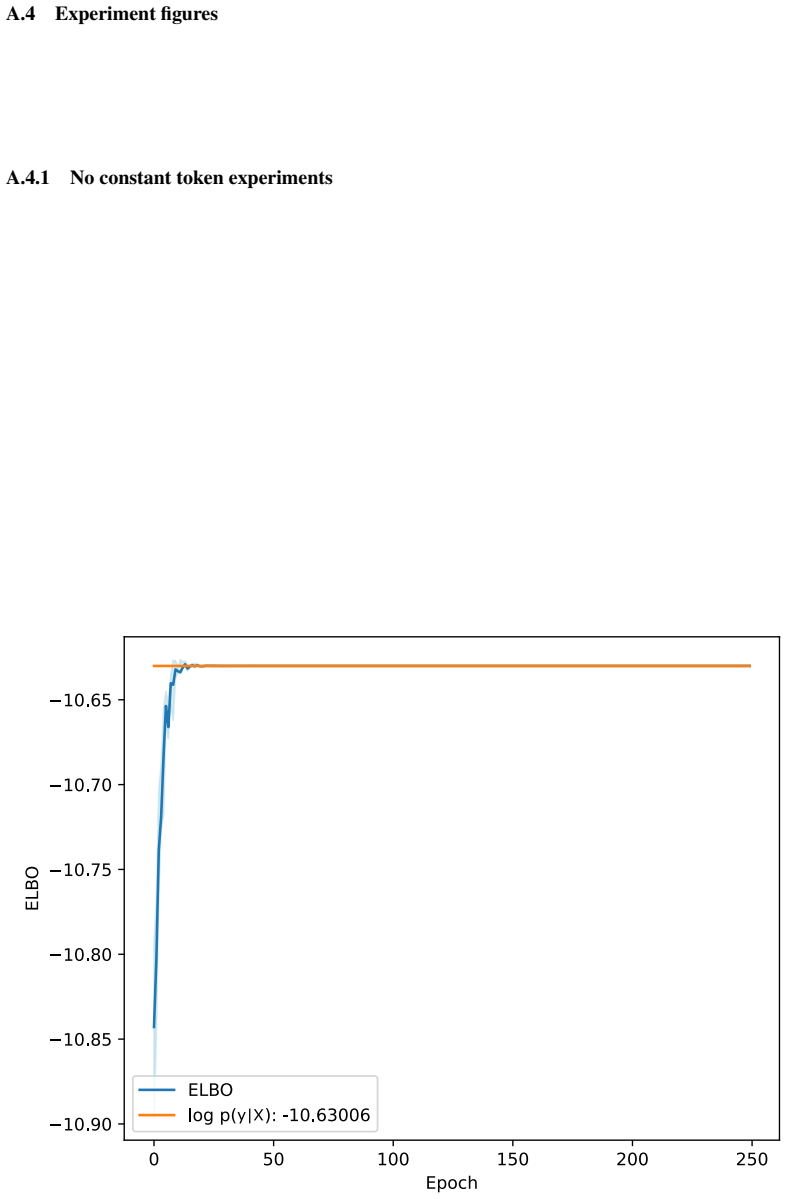
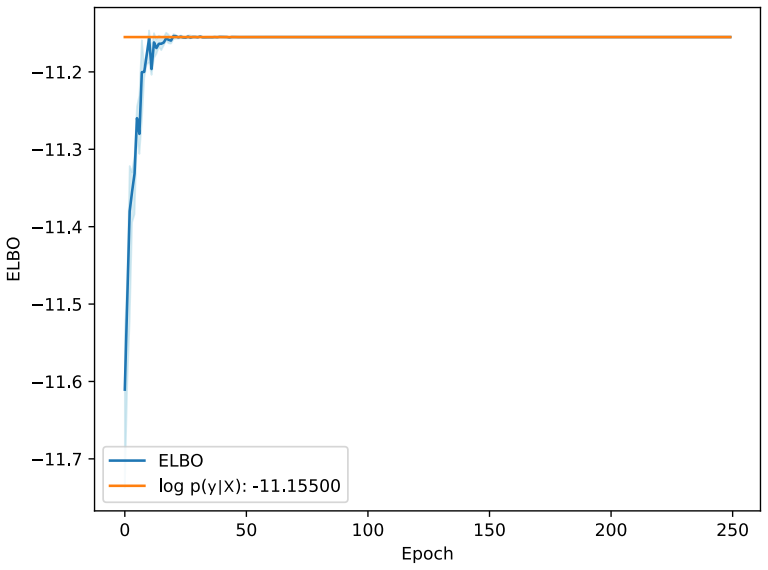
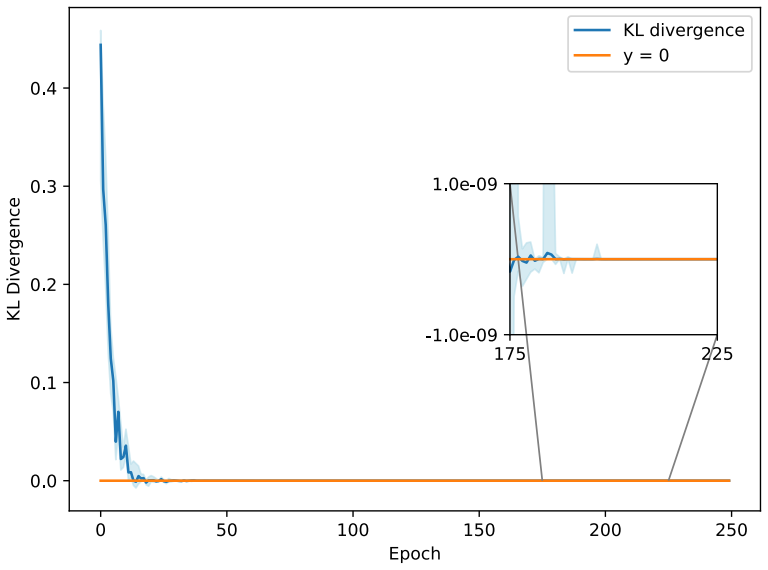

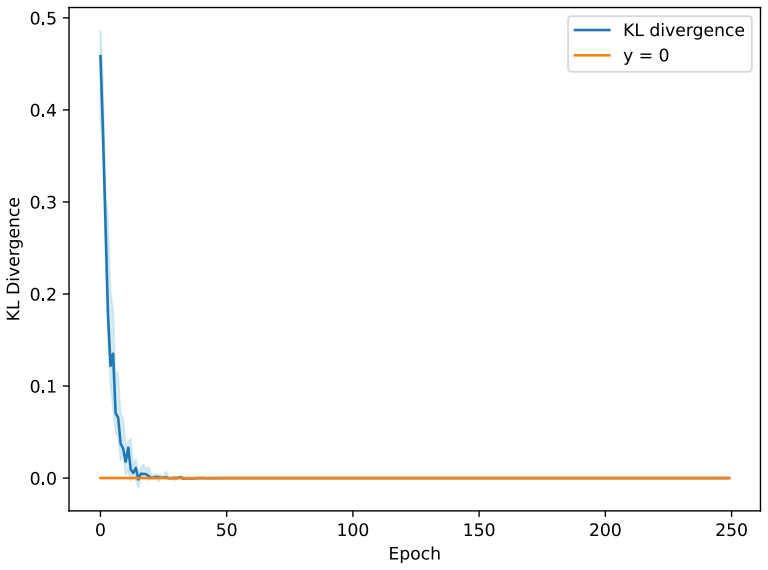





read the original abstract
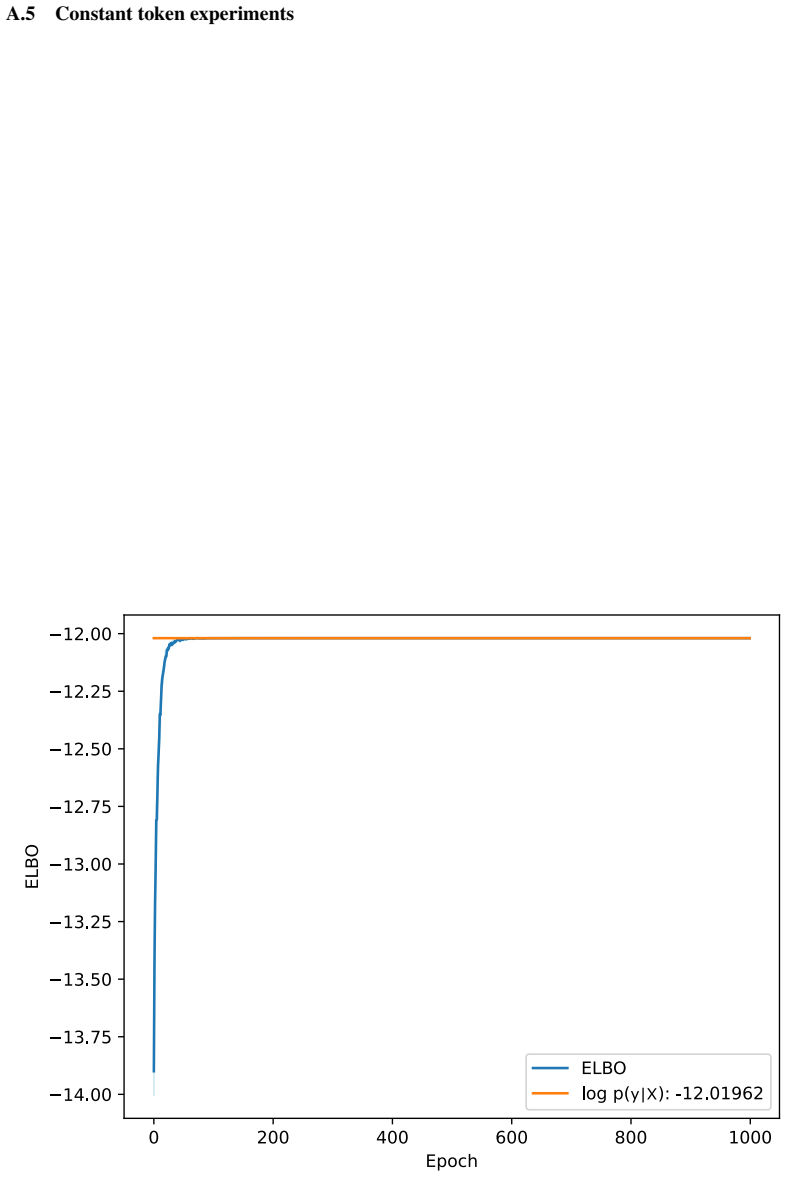
Symbolic regression discovers explicit, interpretable equations without assuming a functional form in advance. A Bayesian approach strengthens this through probability distributions over candidate expressions, thus quantifying uncertainty in the presence of noisy and limited data. Deep Symbolic Regression (DSR) uses a neural network to generate symbolic expressions, but it is designed to identify a single best-fitting expression rather than infer a posterior distribution over models. We introduce Deep Variational Inference Symbolic Regression (DVISR), a variational Bayesian extension of DSR. DVISR replaces the original reward with the integrand of the evidence lower bound. It also extends the network architecture to output distributions over constants within expressions, enabling posterior inference over both expression trees and their associated constants. We show that DVISR can recover the true posterior in simple settings, both with and without constant tokens, and we examine how its performance changes as the size of the expression space increases. These results position DVISR as a step toward scalable Bayesian symbolic regression with uncertainty over full symbolic models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Deep Variational Inference Symbolic Regression (DVISR) as a variational Bayesian extension of Deep Symbolic Regression (DSR). It replaces the DSR reward with the integrand of the evidence lower bound (ELBO) and extends the neural network to output distributions over both discrete expression trees and continuous constants. The central empirical claim is that DVISR recovers the true posterior over symbolic expressions in simple enumerable settings (with and without constant tokens) and that performance trends can be examined as the size of the expression space increases.
Significance. If the recovery claim holds under quantitative scrutiny, the work provides a direct and standard application of variational inference to the joint discrete-continuous space of symbolic models. This is a natural and non-circular extension of existing DSR machinery, offering a feasible route toward scalable Bayesian symbolic regression with uncertainty quantification over full expressions. The limited-scope validation in enumerable regimes is a reasonable starting point for assessing feasibility.
major comments (2)
- Abstract and experimental section: the claim that DVISR 'recovers the true posterior in simple settings' is stated without any reported quantitative metrics (e.g., KL divergence, posterior probability of the ground-truth expression, or total variation distance), experimental details on how the true posterior is computed for comparison, or baselines such as exact enumeration or MCMC. This evidence is load-bearing for the central claim.
- Method description: while the substitution of the ELBO integrand for the reward is a standard construction, the paper does not specify how the variational posterior is parameterized to ensure it can faithfully represent distributions over discrete trees of varying depth and continuous constants, which is required for the recovery result to be non-trivial.
minor comments (3)
- Notation for the joint discrete-continuous posterior and the corresponding variational family should be introduced more explicitly, perhaps with a dedicated equation, to avoid ambiguity when constants are or are not present.
- The description of how performance changes with expression-space size would benefit from a table or plot that reports both recovery quality and computational cost as a function of space cardinality.
- A few sentences clarifying the relationship to prior work on variational inference over program spaces (e.g., in program synthesis or Bayesian program learning) would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the presentation of our central claims. We will revise the manuscript to incorporate quantitative metrics and expanded methodological details as requested. Point-by-point responses follow.
read point-by-point responses
-
Referee: Abstract and experimental section: the claim that DVISR 'recovers the true posterior in simple settings' is stated without any reported quantitative metrics (e.g., KL divergence, posterior probability of the ground-truth expression, or total variation distance), experimental details on how the true posterior is computed for comparison, or baselines such as exact enumeration or MCMC. This evidence is load-bearing for the central claim.
Authors: We agree that quantitative metrics would strengthen the evidence. In the simple enumerable regimes, the true posterior is obtained by exhaustive enumeration over the finite expression space (with and without constants), which serves as the ground truth for comparison. We will add explicit metrics including KL divergence to the true posterior, the posterior mass on the ground-truth expression, and total variation distance in the revised experimental section, along with full details of the enumeration procedure and exact enumeration as a baseline. revision: yes
-
Referee: Method description: while the substitution of the ELBO integrand for the reward is a standard construction, the paper does not specify how the variational posterior is parameterized to ensure it can faithfully represent distributions over discrete trees of varying depth and continuous constants, which is required for the recovery result to be non-trivial.
Authors: The current description notes the extension to output distributions over constants but is indeed brief. The variational posterior is parameterized via an RNN that generates expression trees token-by-token using categorical distributions over the library (operators, variables, constants), with tree depth handled by the sequential generation process and termination tokens. For each constant token, the network outputs parameters of a Gaussian distribution. We will expand the method section with a precise description of this architecture, the ELBO estimation procedure, and how it supports faithful representation over the joint discrete-continuous space. revision: yes
Circularity Check
No significant circularity in the variational extension or empirical claims
full rationale
The paper applies the standard evidence lower bound (ELBO) from variational inference by substituting its integrand for the DSR reward function. This is a direct, non-circular construction from established VI principles rather than a self-definition or fitted input renamed as a prediction. The central empirical claim—recovery of the true posterior in simple enumerable settings—is validated by direct comparison to ground-truth posteriors, not by algebraic reduction to parameters defined inside the paper. No load-bearing self-citations, uniqueness theorems, or smuggled ansatzes are used to force the results; the derivation remains independent of the reported experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The evidence lower bound provides a tractable surrogate for the marginal likelihood that can be optimized via gradient methods.
Reference graph
Works this paper leans on
-
[1]
A. Science Advances , author =. 2020 , pages =. doi:10.1126/sciadv.aav6971 , abstract =
-
[2]
Bayesian
Jin, Ying and Fu, Weilin and Kang, Jian and Guo, Jiadong and Guo, Jian , month = jan, year =. Bayesian
-
[3]
and Larma, Mikel Landajuela and Mundhenk, Terrell N
Petersen, Brenden K. and Larma, Mikel Landajuela and Mundhenk, Terrell N. and Santiago, Claudio Prata and Kim, Soo Kyung and Kim, Joanne Taery , year =. Deep symbolic regression:. International
-
[4]
Simple. Mach. Learn. , author =. 1992 , note =. doi:10.1007/BF00992696 , abstract =
-
[5]
PLOS Computational Biology , author =
Bayesian polynomial neural networks and polynomial neural ordinary differential equations , volume =. PLOS Computational Biology , author =. 2024 , note =. doi:10.1371/journal.pcbi.1012414 , abstract =
-
[6]
Chen, Ricky T. Q. and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David , year =. Neural ordinary differential equations , abstract =. Proceedings of the 32nd
-
[7]
Koza , title =
John R. Koza , title =. 1992 , publisher =
1992
-
[8]
Advances in Neural Information Processing Systems , volume=
End-to-end symbolic regression with transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
Transformer-based planning for symbolic regression , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Symbolic regression with a learned concept library , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
PeerJ Computer Science , volume=
Symbolic expression generation via variational auto-encoder , author=. PeerJ Computer Science , volume=. 2023 , publisher=
2023
-
[12]
Advances in Neural Information Processing Systems , volume=
A unified framework for deep symbolic regression , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
IEEE transactions on neural networks and learning systems , volume=
Integration of neural network-based symbolic regression in deep learning for scientific discovery , author=. IEEE transactions on neural networks and learning systems , volume=. 2020 , publisher=
2020
-
[14]
and Soljačić, Marin , journal=
Zhang, Michael and Kim, Samuel and Lu, Peter Y. and Soljačić, Marin , journal=. Deep Learning and Symbolic Regression for Discovering Parametric Equations , year=
-
[15]
Science advances , volume=
AI Feynman: A physics-inspired method for symbolic regression , author=. Science advances , volume=. 2020 , publisher=
2020
-
[16]
Advances in Neural Information Processing Systems , volume=
AI Feynman 2.0: Pareto-optimal symbolic regression exploiting graph modularity , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2111.00053 (2021)
Symbolic regression via neural-guided genetic programming population seeding , author=. arXiv preprint arXiv:2111.00053 , year=
-
[18]
Castellini, Jacopo and Devlin, Sam and Oliehoek, Frans A. and Savani, Rahul , title=. Neural Computing and Applications , year=. doi:10.1007/s00521-022-07960-5 , url=
-
[19]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , url =. 1707.06347 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[21]
arXiv preprint arXiv:2401.00282 , year=
Deep generative symbolic regression , author=. arXiv preprint arXiv:2401.00282 , year=
-
[22]
arXiv preprint arXiv:1910.08892 , year=
Bayesian symbolic regression , author=. arXiv preprint arXiv:1910.08892 , year=
-
[23]
Neural Computing and Applications , volume=
Evolutionary variational inference for Bayesian generalized nonlinear models , author=. Neural Computing and Applications , volume=. 2024 , publisher=
2024
-
[24]
Advances in Neural Information Processing Systems , volume=
Learning libraries of subroutines for neurally--guided bayesian program induction , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2406.06751 , year=
Complexity-Aware Deep Symbolic Regression with Robust Risk-Seeking Policy Gradients , author=. arXiv preprint arXiv:2406.06751 , year=
-
[26]
Advances in neural information processing systems , volume=
A bayesian-symbolic approach to reasoning and learning in intuitive physics , author=. Advances in neural information processing systems , volume=
-
[27]
Machine Learning with Applications , volume=
Uncertainty quantification based on symbolic regression and probabilistic programming and its application , author=. Machine Learning with Applications , volume=. 2025 , publisher=
2025
-
[28]
Proceedings of the Genetic and Evolutionary Computation Conference , pages=
A probabilistic linear genetic programming with stochastic context-free grammar for solving symbolic regression problems , author=. Proceedings of the Genetic and Evolutionary Computation Conference , pages=
-
[29]
Hubin, Aliaksandr and Storvik, Geir and Frommlet, Florian , title =. J. Artif. Int. Res. , month = jan, pages =. 2022 , issue_date =. doi:10.1613/jair.1.13047 , abstract =
-
[30]
Gunapati, Geetakrishnasai and Jain, Anirudh and Srijith, P. K. and Desai, Shantanu , year=. Variational inference as an alternative to MCMC for parameter estimation and model selection , volume=. doi:10.1017/pasa.2021.64 , journal=
-
[31]
M., KUCUKELBIR, A., MCAULIFFE, J
David M. Blei and Alp Kucukelbir and Jon D. McAuliffe , title =. Journal of the American Statistical Association , volume =. 2017 , publisher =. doi:10.1080/01621459.2017.1285773 , URL =
-
[32]
and Welling, Max , title =
Salimans, Tim and Kingma, Diederik P. and Welling, Max , title =. Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37 , pages =. 2015 , publisher =
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.