Recognition: unknown
Teaching LLMs Brazilian Healthcare: Injecting Knowledge from Official Clinical Guidelines
Pith reviewed 2026-05-09 18:45 UTC · model grok-4.3
The pith
A 14B model trained on synthetic data from Brazilian clinical guidelines outperforms much larger general LLMs on domain-specific medical recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
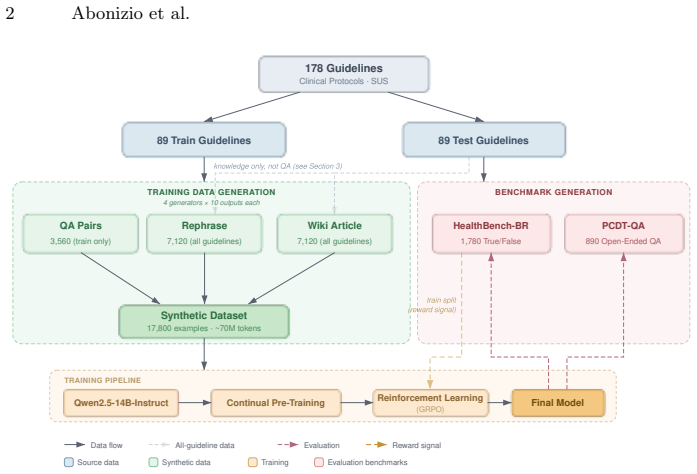
The authors establish that converting official Brazilian clinical guidelines into diverse synthetic datasets via multiple generator LLMs, followed by continual pre-training and Group Relative Policy Optimization, produces a 14B model that scores 83.9 percent on a balanced true/false benchmark and 85.4 percent on open-ended questions, exceeding the performance of GPT-5.2, Claude Sonnet 4.6, Gemini 3.1 Pro, and web-grounded retrieval systems while using far fewer parameters.
What carries the argument
A data-generation pipeline that turns 178 official guidelines into roughly 70 million tokens of rephrases, wiki-style articles, and question-answer pairs using four generator LLMs, then applies continual pre-training and Group Relative Policy Optimization to embed the content into the base model.
If this is right
- Smaller models can achieve reliable command of guideline-specific details such as diagnostic criteria, dosages, and monitoring steps for Brazilian protocols.
- Using multiple generators and the reinforcement learning stage each contribute measurably to the final accuracy.
- The released datasets and benchmarks provide a reproducible way to measure how well any model captures Brazilian clinical protocols.
- Deployment of such adapted models becomes practical in settings where compute resources are limited.
Where Pith is reading between the lines
- The same guideline-to-synthetic-data approach could be repeated for clinical protocols from other national health systems.
- Models trained this way might reduce certain types of medical hallucinations when answering questions within the covered guideline topics.
- The new benchmarks could be extended over time to include cases from guidelines released after the current training cutoff.
- Integration into clinical decision-support tools would still require separate safety and usability testing beyond the reported benchmarks.
Load-bearing premise
The synthetic data created from the guidelines accurately reflects their content without introducing factual errors, omissions, or biases that would distort what the model learns.
What would settle it
The fine-tuned model giving wrong answers on clinical scenarios taken directly from the guidelines where one of the larger comparison models answers correctly.
Figures

read the original abstract
Brazil's Unified Health System (SUS) relies on official clinical guidelines that define diagnostic criteria, treatments, dosages, and monitoring procedures for over 200 million citizens. Yet current LLMs perform poorly on this guideline-specific knowledge, and no benchmark evaluates clinical recall grounded in Brazilian Portuguese protocols. We address this gap by adapting Qwen2.5-14B-Instruct to the Brazilian clinical domain. From 178 official guidelines (~5.4M tokens), we generate ~70M tokens of synthetic data in three formats -- rephrases, wiki-style articles, and question-answer pairs -- using four generator LLMs. We then apply continual pre-training followed by Group Relative Policy Optimization (GRPO). We introduce HealthBench-BR, with 1,780 balanced true/false clinical assertions, and PCDT-QA, with 890 open-ended clinical questions scored by an LLM judge. Our best model achieves 83.9% on HealthBench-BR and 85.4% on PCDT-QA, outperforming GPT-5.2, Claude Sonnet 4.6, Gemini 3.1 Pro, and Google AI Overview's web-grounded RAG despite having only 14B parameters. Ablations show that generator diversity and reinforcement learning are critical to these gains. We release all datasets, benchmarks, and model weights to support reproducible clinical NLP research for Brazilian Portuguese. Code, data, and model weights are available at https://github.com/hugoabonizio/clinical-protocols-br
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts Qwen2.5-14B-Instruct to Brazilian clinical guidelines by generating ~70M tokens of synthetic rephrases, wiki articles, and QA pairs from 178 official SUS documents using four generator LLMs, followed by continual pre-training and GRPO. It introduces HealthBench-BR (1,780 balanced true/false assertions) and PCDT-QA (890 open-ended questions scored by LLM judge), reporting 83.9% and 85.4% accuracy respectively. The model outperforms GPT-5.2, Claude Sonnet 4.6, Gemini 3.1 Pro, and web-grounded RAG despite its size; ablations highlight the value of generator diversity and RL. All datasets, benchmarks, and weights are released.
Significance. If the central results hold after verification, the work is significant for showing that targeted synthetic-data adaptation plus GRPO can enable a 14B model to surpass much larger general-purpose LLMs on domain-specific clinical recall in Brazilian Portuguese. The public release of the guideline-derived datasets, two new benchmarks, and fine-tuned weights provides concrete resources for reproducible clinical NLP research in a low-resource language setting and supports further investigation of efficient knowledge injection methods.
major comments (2)
- [Section 3.2] Section 3.2 (Synthetic Data Generation): No expert review, error-rate quantification, or fidelity check against the source PDFs is reported for the ~70M tokens of generated rephrases/wiki/QA. If generator LLMs introduce factual distortions (incorrect dosages, omitted contraindications, or stylistic biases), these will be reinforced by continual pre-training and GRPO, directly undermining the claim that performance gains reflect accurate guideline knowledge rather than artifacts.
- [Section 4] Section 4 (Benchmark Construction): HealthBench-BR and PCDT-QA lack reported details on item sourcing, overlap controls with the synthetic training data, inter-annotator agreement for the true/false labels, or human validation of the LLM judge used for PCDT-QA. Without these, the headline scores (83.9% and 85.4%) and outperformance claims cannot be independently verified and may be inflated by shared synthetic patterns.
minor comments (2)
- [Abstract and Section 5] The abstract states that ablations demonstrate the importance of generator diversity and reinforcement learning, but the main text should include the exact accuracy drops, confidence intervals, and statistical tests for each ablation condition.
- [Section 3.3] Notation for the GRPO objective and the three synthetic data formats could be clarified with a small table or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the transparency and rigor of the manuscript. We address each major point below and have revised the paper accordingly where possible.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Synthetic Data Generation): No expert review, error-rate quantification, or fidelity check against the source PDFs is reported for the ~70M tokens of generated rephrases/wiki/QA. If generator LLMs introduce factual distortions (incorrect dosages, omitted contraindications, or stylistic biases), these will be reinforced by continual pre-training and GRPO, directly undermining the claim that performance gains reflect accurate guideline knowledge rather than artifacts.
Authors: We acknowledge that the absence of expert review or explicit error-rate quantification for the synthetic data is a limitation. Performing such validation at the scale of 70M tokens would require significant clinical resources beyond the scope of this study. In response, we have added a dedicated paragraph in Section 3.2 describing the multi-generator approach and its intended bias-mitigation benefits, supported by our existing ablations. We have also inserted a Limitations section that explicitly notes the lack of expert fidelity checks and recommends that practitioners always consult the original SUS PDFs for safety-critical decisions. All generated data is released to facilitate external audits. revision: partial
-
Referee: [Section 4] Section 4 (Benchmark Construction): HealthBench-BR and PCDT-QA lack reported details on item sourcing, overlap controls with the synthetic training data, inter-annotator agreement for the true/false labels, or human validation of the LLM judge used for PCDT-QA. Without these, the headline scores (83.9% and 85.4%) and outperformance claims cannot be independently verified and may be inflated by shared synthetic patterns.
Authors: We agree that additional methodological details are required for independent verification. We have expanded Section 4 to document item sourcing (assertions and questions were manually derived by the authors from the 178 official guidelines), overlap controls (disjoint guideline sections plus embedding-based deduplication were applied), and the construction process. We have added a note clarifying that formal inter-annotator agreement was not computed because labels are objective extractions from the source documents, and we have included a human validation study of the LLM judge on a held-out subset of PCDT-QA. These additions allow readers to assess potential data leakage and judge reliability. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central result is an empirical performance measurement obtained by ingesting external official Brazilian clinical guidelines, generating synthetic data via four generator LLMs, performing continual pre-training plus GRPO, and evaluating on two newly introduced benchmarks (HealthBench-BR true/false assertions and PCDT-QA open-ended questions). No equations, self-definitions, or fitted parameters reduce the reported accuracies (83.9% and 85.4%) to the inputs by construction; the benchmarks are presented as independent test sets, and no load-bearing self-citation or uniqueness theorem is invoked to justify the gains. The process remains externally grounded in the source guidelines and measurable outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Continual pre-training and GRPO hyperparameters
axioms (2)
- domain assumption Synthetic data generated by four external LLMs accurately reflects the content and intent of the 178 official Brazilian clinical guidelines
- domain assumption The LLM judge used to score PCDT-QA open-ended answers produces reliable, unbiased evaluations aligned with clinical expert judgment
Reference graph
Works this paper leans on
-
[1]
In: Naldi, M.C., Bianchi, R.A.C
Almeida, T.S., Laitz, T., Bonás, G.K., Nogueira, R.: Bluex: A benchmark based on brazilian leading universities entrance exams. In: Intelligent Systems: 12th Brazilian Conference, BRACIS 2023, Belo Horizonte, Brazil, September 25–29, 2023, Proceedings, Part I. p. 337–347. Springer-Verlag, Berlin, Heidelberg (2023). https://doi.org/10.1007/978-3-031-45368-...
-
[2]
In: ICML (2025)
Bethune, L., Grangier, D., Busbridge, D., Gualdoni, E., Cuturi, M., Ablin, P.: Scaling laws for forgetting during finetuning with pretraining data injection. In: ICML (2025)
2025
-
[3]
Transactions on Machine Learning Research (2024) 14 Abonizio et al
Biderman, D., et al.: LoRA learns less and forgets less. Transactions on Machine Learning Research (2024) 14 Abonizio et al
2024
-
[4]
12.401, de 28 de abril de 2011
BRASIL: Lei n. 12.401, de 28 de abril de 2011. Altera a Lei n. 8.080/1990, para dispor sobre a assistência terapêutica e a incorporação de tecnologia em saúde no âmbito do SUS (2011), diário Oficial da União, seção 1, Brasília, DF, 29 abr. 2011
2011
-
[5]
BMJ Health & Care Informatics32(1), e101195 (2025)
Bruneti Severino, J.V., Basei de Paula, P.A., Nespolo Berger, M., Silveira Loures, F., Amadori Todeschini, S., Roeder, E.A., Han Veiga, M., Guedes, M., Lenci Mar- ques,G.:Benchmarkingopen-sourcelargelanguagemodelsonPortugueseRevalida multiple-choice questions. BMJ Health & Care Informatics32(1), e101195 (2025). https://doi.org/10.1136/bmjhci-2024-101195
-
[6]
arXiv e-prints arXiv:2511.11878 (Nov 2025).https://doi.org/10.48550/arXiv.2511.11878
Bufon Färber, F., Alves Brito, I., Soares Dollis, J., Schindler Freire Brasil Ribeiro, P., Teixeira Sousa, R., Rodrigues Galvão Filho, A.: MedPT: A Massive Medi- cal Question Answering Dataset for Brazilian-Portuguese Speakers. arXiv e-prints arXiv:2511.11878 (Nov 2025).https://doi.org/10.48550/arXiv.2511.11878
-
[7]
Chen, Z., Hernández-Cano, A., Romanou, A., Bonnet, A., Matoba, K., et al.: Meditron-70b: Scaling medical pretraining for large language models (2023)
2023
-
[8]
In: ICLR (2024)
Cheng, D., Huang, S., Wei, F.: Adapting large language models to domains via reading comprehension. In: ICLR (2024)
2024
-
[9]
arXiv preprint arXiv:2506.21578 (2025), https://arxiv.org/abs/2506.21578
D’addario, A.M.V.: Healthqa-br: A system-wide benchmark reveals critical knowl- edge gaps in large language models. arXiv preprint arXiv:2506.21578 (2025), https://arxiv.org/abs/2506.21578
-
[10]
Submitted to IEEE
Garcia,G.L.,Manesco,J.R.R.,Paiola,P.H.,CrespanRibeiro,P.H.,Garcia,A.L.A., Papa, J.P.: A step forward for medical LLMs in Brazilian Portuguese: Establishing a benchmark and a strong baseline (2025), preprint available on ResearchGate. Submitted to IEEE
2025
-
[11]
Gunasekar, S., Zhang, Y., Aneja, J., Mendes, C.C.T., Del Giorno, A., et al.: Text- books are all you need. arXiv preprint arXiv:2306.11644 (2023)
work page internal anchor Pith review arXiv 2023
-
[12]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[13]
Scaling laws for forgetting when fine-tuning large language models, 2024
Kalajdzievski, D.: Scaling laws for forgetting when fine-tuning large language mod- els. arXiv preprint arXiv:2401.05605 (2024)
-
[14]
In: Findings of ACL (2024)
Labrak, Y., Bazoge, A., Morin, E., Gourraud, P.A., Rouvier, M., Dufour, R.: BioMistral: A collection of open-source pretrained large language models for med- ical domains. In: Findings of ACL (2024)
2024
-
[15]
Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge
Li, Y., Li, Z., Zhang, K., Dan, R., Jiang, S., Zhang, Y.: ChatDoctor: A medical chat model fine-tuned on LLaMA using medical domain knowledge. arXiv preprint arXiv:2303.14070 (2023)
-
[16]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Maini, P., Seto, S., Bai, R., Grangier, D., Zhang, Y., Jaitly, N.: Rephrasing the web: A recipe for compute and data-efficient language modeling. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 14044–14072. Association for Computational Linguistics (2024)
2024
-
[17]
Capabilities of GPT-4 on Medical Challenge Problems
Nori, H., King, N., McKinney, S.M., Carignan, D., Horvitz, E.: Capabilities of GPT-4 on medical challenge problems. arXiv preprint arXiv:2303.13375 (2023)
- [18]
-
[19]
In: NeurIPS Datasets and Benchmarks Track (2024)
Penedo, G., Kydlíček, H., et al.: The FineWeb datasets: Decanting the web for the finest text data at scale. In: NeurIPS Datasets and Benchmarks Track (2024)
2024
-
[20]
Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416.2024
Saab, K., Tu, T., Weng, W.H., Tanno, R., Stutz, D., et al.: Capabilities of Gemini models in medicine. arXiv preprint arXiv:2404.18416 (2024)
-
[21]
In: Rumshisky, A., Roberts, K., Bethard, S., Nau- mann, T
Schneider, E.T.R., de Souza, J.V.A., Knafou, J., Oliveira, L.E.S.e., Co- para, J., Gumiel, Y.B., Oliveira, L.F.A.d., Paraiso, E.C., Teodoro, D., Barra, Teaching LLMs Brazilian Healthcare 15 C.M.C.M.: BioBERTpt - a Portuguese neural language model for clinical named entity recognition. In: Rumshisky, A., Roberts, K., Bethard, S., Nau- mann, T. (eds.) Proce...
-
[22]
Schulman, J., Lab, T.M.: Lora without regret. Thinking Machines Lab: Connectionism (2025).https://doi.org/10.64434/tml.20250929, https://thinkingmachines.ai/blog/lora/
-
[23]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models (2024),https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Lora vs full fine-tuning: An illusion of equivalence
Shuttleworth, R., Andreas, J., Torralba, A., Sharma, P.: Lora vs full fine-tuning: An illusion of equivalence. arXiv preprint arXiv:2410.21228 (2024)
-
[26]
Nature620, 172–180 (2023)
Singhal, K., Azizi, S., Tu, T., Mahdavi, S.S., Wei, J., Chung, H.W., et al.: Large language models encode clinical knowledge. Nature620, 172–180 (2023)
2023
-
[27]
Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., et al.: To- ward expert-level medical question answering with large language models. Nature Medicine31(3),943–950(2025).https://doi.org/10.1038/s41591-024-03423-7
-
[28]
In: Paes, A., Verri, F.A.N
de Souza Pinto, J.G., Rodrigues de Freitas, A., Martins, A.C.G., Sawazaki, C.M.R., Vidal,C.,SilvaeOliveira,L.E.:Developingresource-efficientclinicalllmsforbrazil- ian portuguese. In: Paes, A., Verri, F.A.N. (eds.) Intelligent Systems. pp. 46–60. Springer Nature Switzerland, Cham (2025)
2025
-
[29]
Su,D.,Kong,K.,Lin,Y.,Jennings,J.,Norick,B.,Kliegl,M.,Patwary,M.,Shoeybi, M., Catanzaro, B.: Nemotron-cc: Transforming common crawl into a refined long- horizon pretraining dataset (2024)
2024
-
[30]
Journal of the American Med- ical Informatics Association31(9), 1833–1843 (09 2024).https://doi.org/10
Wu, C., Lin, W., Zhang, X., Zhang, Y., Xie, W., Wang, Y.: Pmc-llama: toward building open-source language models for medicine. Journal of the American Med- ical Informatics Association31(9), 1833–1843 (09 2024).https://doi.org/10. 1093/jamia/ocae045
2024
-
[31]
arXiv preprint arXiv:2402.12749 (2024)
Xie, Q., Chen, Q., Chen, A., Peng, C., Hu, Y., et al.: Me-LLaMA: Foundation large language models for medical applications. arXiv preprint arXiv:2402.12749 (2024)
-
[32]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., et al.: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [33]
-
[34]
arXiv preprint arXiv:2310.14558 (2024)
Zhang, X., Tian, C., Yang, X., Chen, L., Li, Z., Petzold, L.R.: AlpaCare: Instruction-tuned large language models for medical application. arXiv preprint arXiv:2310.14558 (2024)
- [35]
-
[36]
In: ICLR (2025)
Zheng, J., et al.: Spurious forgetting in continual learning of language models. In: ICLR (2025)
2025
-
[37]
Instruction-Following Evaluation for Large Language Models
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., Hou, L.: Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.