Recognition: unknown
Almost for Free: Crafting Adversarial Examples with Convolutional Image Filters
Pith reviewed 2026-05-09 18:56 UTC · model grok-4.3
The pith
Optimized 3x3 convolutional filters based on edge detection can generate transferable adversarial examples using five orders of magnitude fewer parameters than generative models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adversarial image filters are created by taking classic edge detection algorithms and optimizing their parameters specifically to deceive learning models. The resulting untargeted attacks transfer across models and require only a single pass over the input. With 3x3 filters, success rates reach 30 to 80 percent on different neural networks, and the approach reduces the number of parameters by five orders of magnitude compared to methods that use generative models.
What carries the argument
Adversarial image filters: small 3x3 convolutional kernels derived from edge detection algorithms and optimized to maximize model misclassification in one forward pass.
If this is right
- Adversarial example generation becomes possible with only a single forward pass and no need for gradient computation or model queries during the attack.
- Attacks can be performed with parameters reduced by five orders of magnitude relative to generative-model approaches, enabling very efficient execution.
- Learned filters exhibit structures common to classic image filters, providing a direct link between standard image processing and model vulnerabilities.
- High transferability between models allows attacks optimized on one network to succeed on others without retraining.
Where Pith is reading between the lines
- This method could be tested on other data types such as audio or text to check whether similar low-parameter filter-based attacks exist outside images.
- The filters might serve as a lightweight benchmark for measuring robustness across a wide range of models without requiring full retraining for each test.
- If the approach scales, it could motivate new preprocessing defenses that detect or neutralize perturbations resembling optimized edge filters.
Load-bearing premise
Filters optimized on a limited set of models and data will remain effective and transferable to unseen architectures and datasets without additional per-model tuning or retraining.
What would settle it
Applying the optimized filters to a new neural network architecture or a different dataset and measuring attack success rates that drop to the level of random guessing would falsify the transferability claim.
Figures









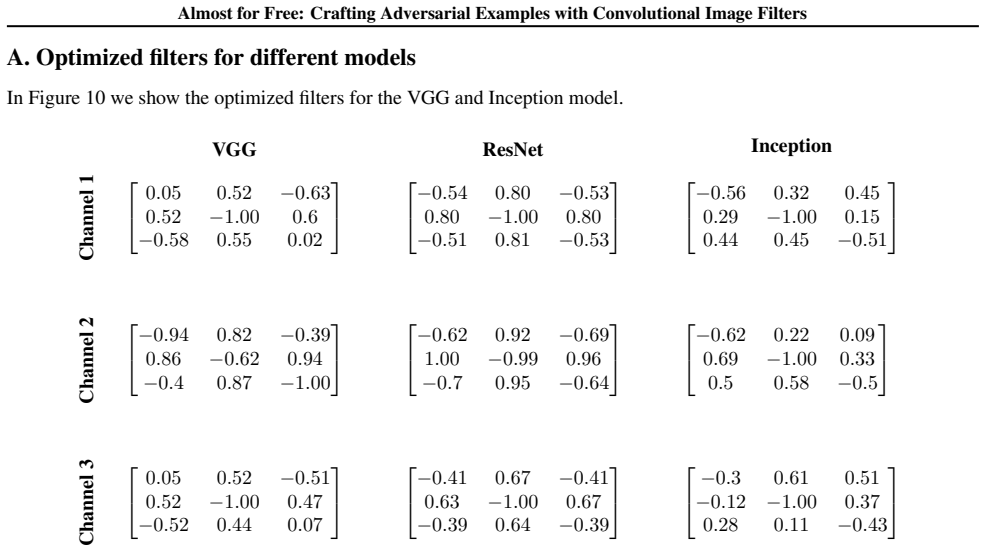

read the original abstract
Adversarial examples in machine learning are typically generated using gradients, obtained either directly through access to the model or approximated via queries to it. In this paper, we propose a much simpler approach to craft adversarial examples, drawing inspiration from insights of explainable machine learning. In particular, we design \emph{adversarial image filters} that are based on classic edge detection algorithms but optimized to deceive learning models. The resulting untargeted attacks are transferable and require only a single pass over the input. Empirically, we find that 3x3 filters already enable success rates between 30% and 80% on different neural networks. Compared to related approaches using generative models for crafting adversarial examples, we reduce the number of parameters by five orders of magnitude, resulting in a very efficient attack. When investigating the parameters of the learned filters, we observe interesting properties such as a high transferability between models and structures common to classic image filters. Our results provide further insights into the vulnerability of neural networks and their fragility to malicious noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes adversarial image filters: 3x3 convolutional kernels inspired by edge-detection algorithms but with weights optimized to maximize model misclassification. These filters generate untargeted adversarial examples via a single forward pass through the filter, claiming 30-80% success rates across neural networks, high transferability, and a five-order-of-magnitude reduction in parameters relative to generative-model attacks.
Significance. If the empirical claims are substantiated with proper optimization details, baselines, and cross-architecture transfer results, the work would demonstrate that extremely low-parameter structured perturbations can reliably fool deep networks. This would strengthen understanding of model fragility to simple, interpretable noise and offer a computationally cheap attack primitive that could inform both attack and defense research.
major comments (3)
- [§4] §4 (Experiments): the abstract states success rates of 30-80% but provides no information on the optimization procedure (loss function, surrogate models/datasets used to learn the filter weights, number of optimization steps, or whether a single filter set is used for all target models). Without these details the central efficiency and transferability claims cannot be evaluated.
- [§4.3] §4.3 (Transferability): the claim that the learned 3x3 filters exhibit 'high transferability between models' and require 'no per-model tuning' is load-bearing for the practical utility argument. The manuscript must report success rates when filters optimized on one architecture family (e.g., CNNs) are applied to held-out families (e.g., Vision Transformers) and on datasets disjoint from the optimization set; current evidence appears limited to the models used for filter learning.
- [Table 1] Table 1 / §4.1: the five-order-of-magnitude parameter reduction is compared only to generative-model baselines. The paper should also include simple non-learned baselines (random 3x3 filters, classic Sobel/Prewitt kernels, Gaussian noise of matched magnitude) to establish that the optimization step itself is responsible for the reported success rates rather than the filter structure alone.
minor comments (2)
- [Abstract / §3] The abstract and introduction use 'almost for free' and 'single pass' without clarifying that filter optimization itself requires gradient access or queries to surrogate models; this should be stated explicitly in the method section.
- [§3] Notation for the filter coefficients and the exact convolution operation applied to produce the adversarial image should be formalized with an equation in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for improving the clarity, reproducibility, and strength of the empirical claims. We address each major comment below and will revise the manuscript to incorporate the requested details and comparisons.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the abstract states success rates of 30-80% but provides no information on the optimization procedure (loss function, surrogate models/datasets used to learn the filter weights, number of optimization steps, or whether a single filter set is used for all target models). Without these details the central efficiency and transferability claims cannot be evaluated.
Authors: We agree that these optimization details are essential for evaluating the claims. The current manuscript provides only a high-level description. In the revised version we will expand §4 with a dedicated paragraph (or subsection) that explicitly states the loss function, the surrogate models and datasets used to learn the filter weights, the number of optimization steps, and confirms that a single filter set is learned and applied to all target models without per-model retuning. revision: yes
-
Referee: [§4.3] §4.3 (Transferability): the claim that the learned 3x3 filters exhibit 'high transferability between models' and require 'no per-model tuning' is load-bearing for the practical utility argument. The manuscript must report success rates when filters optimized on one architecture family (e.g., CNNs) are applied to held-out families (e.g., Vision Transformers) and on datasets disjoint from the optimization set; current evidence appears limited to the models used for filter learning.
Authors: We acknowledge that transfer results are currently limited to the CNN architectures used during filter optimization. The manuscript already shows that the same 3x3 filter works across those models with no per-model tuning. To strengthen the claim we will add, in the revised §4.3, success rates obtained by applying the CNN-optimized filters to Vision Transformers and on a dataset partition held out from the optimization set. revision: yes
-
Referee: [Table 1] Table 1 / §4.1: the five-order-of-magnitude parameter reduction is compared only to generative-model baselines. The paper should also include simple non-learned baselines (random 3x3 filters, classic Sobel/Prewitt kernels, Gaussian noise of matched magnitude) to establish that the optimization step itself is responsible for the reported success rates rather than the filter structure alone.
Authors: We agree that non-learned baselines are needed to isolate the benefit of optimization. In the revised manuscript we will augment Table 1 and the §4.1 discussion with results for random 3x3 filters, the classic Sobel and Prewitt kernels, and Gaussian noise of matched magnitude. These additions will demonstrate that the learned filters outperform the unoptimized alternatives. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical attack construction: 3x3 convolutional filters are explicitly optimized against model outputs to produce adversarial perturbations, with success rates measured directly on held-out models and datasets. No equations or first-principles derivations are offered that reduce to the optimization inputs by construction; the reported 30-80% success rates and five-order parameter reduction are comparative experimental outcomes, not fitted predictions renamed as results. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the core method. The approach is self-contained against external benchmarks via direct measurement.
Axiom & Free-Parameter Ledger
free parameters (1)
- 3x3 filter coefficients
axioms (1)
- domain assumption Neural networks remain vulnerable to structured, low-parameter perturbations derived from image-processing primitives
Reference graph
Works this paper leans on
-
[1]
ImageNet Classification with Deep Convolutional Neural Networks , author =
-
[2]
Very Deep Convolutional Networks for Large-Scale Image Recognition , booktitle = iclr, year =
Karen Simonyan and Andrew Zisserman , @editor =. Very Deep Convolutional Networks for Large-Scale Image Recognition , booktitle = iclr, year =
-
[3]
, author =
Towards Evaluating the Robustness of Neural Networks. , author =
-
[4]
Goodfellow and Rob Fergus , title =
Christian Szegedy and Wojciech Zaremba and Ilya Sutskever and Joan Bruna and Dumitru Erhan and Ian J. Goodfellow and Rob Fergus , title =. 2014 , @url =
2014
-
[5]
Goodfellow and Jonathon Shlens and Christian Szegedy , title =
Ian J. Goodfellow and Jonathon Shlens and Christian Szegedy , title =. 2015 , @url =
2015
-
[6]
2018 , @url =
Andrew Ilyas and Logan Engstrom and Anish Athalye and Jessy Lin , title =. 2018 , @url =
2018
-
[7]
Gardner and Yurong You and Andrew Gordon Wilson and Kilian Q
Chuan Guo and Jacob R. Gardner and Yurong You and Andrew Gordon Wilson and Kilian Q. Weinberger , @editor =. Simple Black-box Adversarial Attacks , booktitle = icml, @series =. 2019 , @url =
2019
-
[8]
2017 , pages =
ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models , author=. 2017 , pages =
2017
-
[9]
2016 , pages=
Universal Adversarial Perturbations , author=. 2016 , pages=
2016
-
[10]
2021 , pages =
Learning Transferable Adversarial Perturbations , author=. 2021 , pages =
2021
-
[11]
Xiao, Chaowei and Li, Bo and Zhu, Jun-Yan and He, Warren and Liu, Mingyan and Song, Dawn , title =. Proc. of the International Joint Conference on Artificial Intelligence , pages =. 2018 , @isbn =
2018
-
[12]
Marco Ancona and Enea Ceolini and Cengiz
-
[13]
2018 , pages=
Sanity Checks for Saliency Maps , author=. 2018 , pages=
2018
-
[14]
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , booktitle = cvpr, pages =
-
[15]
2016 , volume=
Szegedy, Christian and Vanhoucke, Vincent and Ioffe, Sergey and Shlens, Jon and Wojna, Zbigniew , booktitle=cvpr, title=. 2016 , volume=
2016
-
[16]
, title=
Sun, Rui and Lei, Tao and Chen, Qi and Wang, Zexuan and Du, Xiaogang and Zhao, Weiqiang and Nandi, Asoke K. , title=. Frontiers in Signal Processing , volume=
-
[17]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[18]
2019 , pages =
Do ImageNet Classifiers Generalize to ImageNet? , author=. 2019 , pages =
2019
-
[19]
2017 , pages=
Generative Adversarial Perturbations , author=. 2017 , pages=
2017
-
[20]
Learning to Attack: Adversarial Transformation Networks , volume=
Baluja, Shumeet and Fischer, Ian , pages =. Learning to Attack: Adversarial Transformation Networks , volume=. doi:10.1609/aaai.v32i1.11672 , @number=
-
[21]
On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation , journal =
Sebastian Bach and Alexander Binder and Grégoire Montavon and Frederick Klauschen and Klaus-Robert M. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation , journal =
-
[22]
Niels J. S. M. Visualization of neural networks using saliency maps , booktitle =. 1995 , @url =. doi:10.1109/ICNN.1995.488997 , timestamp =
-
[23]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps , Author =
-
[24]
Axiomatic Attribution for Deep Networks , author =. Proc. of International Conference on Machine Learning (ICML) , pages =
-
[25]
Prewitt, J. M. S. Object enhancement and extraction. Picture Processing and. Psychopictorics. 1970
1970
-
[26]
Scharr, Hanno , year =
-
[27]
Image Segmentation using Extended Edge Operator for Mammographic Images , volume =
Kekre, Hemant and Gharge, Saylee , year =. Image Segmentation using Extended Edge Operator for Mammographic Images , volume =
-
[28]
A 3×3 isotropic gradient operator for image processing , journal =
Sobel, Irwin and Feldman, Gary , year =. A 3×3 isotropic gradient operator for image processing , journal =
-
[30]
2016 , pages =
Practical Black-Box Attacks against Machine Learning , author=. 2016 , pages =
2016
-
[31]
Berkay Celik and Ananthram Swami , title =
Nicolas Papernot and Patrick McDaniel and Somesh Jha and Matt Fredrikson and Z. Berkay Celik and Ananthram Swami , title =
-
[32]
Moosavi-Dezfooli, Seyed-Mohsen and Fawzi, Alhussein and Frossard, Pascal , title =
-
[33]
Andrew Ilyas and Logan Engstrom and Aleksander Madry , title =
-
[34]
2019 , pages=
HopSkipJumpAttack: A Query-Efficient Decision-Based Attack , author=. 2019 , pages=
2019
-
[35]
International Conference on Learning Representations (ICLR) , @publisher =
Wieland Brendel and Jonas Rauber and Matthias Bethge , title =. International Conference on Learning Representations (ICLR) , @publisher =. 2018 , biburl =
2018
-
[36]
Generative Adversarial Nets , year =
Goodfellow, Ian and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , booktitle = nips, pages=. Generative Adversarial Nets , year =
-
[37]
2018 , @url =
Aleksander Madry and Aleksandar Makelov and Ludwig Schmidt and Dimitris Tsipras and Adrian Vladu , title =. 2018 , @url =
2018
-
[38]
2019 , @url=
Adversarial Training for Free! , author=. 2019 , @url=
2019
-
[39]
The Space of Transferable Adversarial Examples , journal =
Florian Tram. The Space of Transferable Adversarial Examples , journal =
-
[40]
, booktitle=
Agarwal, Akshay and Vatsa, Mayank and Singh, Richa and Ratha, Nalini K. , booktitle=. Noise is Inside Me! Generating Adversarial Perturbations with Noise Derived from Natural Filters , year=
-
[41]
Crafting Adversarial Perturbations via Transformed Image Component Swapping , year=
Agarwal, Akshay and Ratha, Nalini and Vatsa, Mayank and Singh, Richa , journal=. Crafting Adversarial Perturbations via Transformed Image Component Swapping , year=
-
[42]
Edgefool: an Adversarial Image Enhancement Filter , year=
Shamsabadi, Ali Shahin and Oh, Changjae and Cavallaro, Andrea , booktitle=. Edgefool: an Adversarial Image Enhancement Filter , year=
-
[44]
2023 , eprint=
Don't Look into the Sun: Adversarial Solarization Attacks on Image Classifiers , author=. 2023 , eprint=
2023
-
[46]
Zeiler and Rob Fergus , title =
Matthew D. Zeiler and Rob Fergus , title =. Proceedings of the European Conference on Computer Vision (ECCV) , volume =. 2014 , url =
2014
-
[47]
Proceedings of the International Conference on Learning Representations 2018 , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. Proceedings of the International Conference on Learning Representations 2018 , year=
2018
-
[48]
Watch out! Motion is Blurring the Vision of Your Deep Neural Networks , url =
Guo, Qing and Juefei-Xu, Felix and Xie, Xiaofei and Ma, Lei and Wang, Jian and Yu, Bing and Feng, Wei and Liu, Yang , booktitle =. Watch out! Motion is Blurring the Vision of Your Deep Neural Networks , url =
-
[49]
J., Hardt, M., and Kim, B
Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I. J., Hardt, M., and Kim, B. Sanity checks for saliency maps. In Advances in Neural Information Proccessing Systems ( NIPS ) , pp.\ 9505--9515, 2018
2018
-
[50]
Agarwal, A., Vatsa, M., Singh, R., and Ratha, N. K. Noise is inside me! generating adversarial perturbations with noise derived from natural filters. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp.\ 3354--3363, 2020. doi:10.1109/CVPRW50498.2020.00395
-
[51]
Towards better understanding of gradient-based attribution methods for deep neural networks
Ancona, M., Ceolini, E., \" O ztireli, C., and Gross, M. Towards better understanding of gradient-based attribution methods for deep neural networks. In Proc. of the International Conference on Learning Representations ( ICLR ) , 2018
2018
-
[52]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation
Bach, S., Binder, A., Montavon, G., Klauschen, F., M \"u ller, K.-R., and Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE, 10 0 (7), July 2015
2015
-
[53]
and Fischer, I
Baluja, S. and Fischer, I. Learning to attack: Adversarial transformation networks. In Proc. of the AAAI Conference on Artificial Intelligence (AAAI) , volume 32, pp.\ 2687--2695, 2018
2018
-
[54]
Decision-based adversarial attacks: Reliable attacks against black-box machine learning models
Brendel, W., Rauber, J., and Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. In International Conference on Learning Representations (ICLR), 2018
2018
-
[55]
and Wagner, D
Carlini, N. and Wagner, D. A. Towards evaluating the robustness of neural networks. In Proc. of the IEEE Symposium on Security and Privacy (S&P) , pp.\ 39--57, 2017
2017
-
[56]
and Jordan, M
Chen, J. and Jordan, M. I. Hopskipjumpattack: A query-efficient decision-based attack. pp.\ 1277--1294, 2019
2019
-
[57]
Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models
Chen, P.-Y., Zhang, H., Sharma, Y., Yi, J., and Hsieh, C.-J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. Proc. of ACM Workshop on Artificial Intelligence and Security ( AISEC ) , pp.\ 15--26, 2017
2017
-
[58]
Intriguing properties of adversarial examples
Cubuk, E., Zoph, B., Schoenholz, S., and Le, Q. Intriguing properties of adversarial examples. arXiv:1711.02846, 11 2017
-
[59]
Debenedetti, E., Carlini, N., and Tramer, F. Evading black-box classifiers without breaking eggs. In 2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp.\ 408--424, apr 2024. doi:10.1109/SaTML59370.2024.00027. URL https://doi.ieeecomputersociety.org/10.1109/SaTML59370.2024.00027
-
[60]
Imagenet: A large-scale hierarchical image database
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp.\ 248--255. Ieee, 2009
2009
-
[61]
Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F., and Brendel, W. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. In Proceedings of the International Conference on Learning Representations 2018, volume abs/1811.12231, 2018. URL https://api.semanticscholar.org/CorpusID:54101493
-
[62]
Generative adversarial nets
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. In Advances in Neural Information Proccessing Systems ( NIPS ) , pp.\ 2672--2680, 2014
2014
-
[63]
J., Shlens, J., and Szegedy, C
Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and harnessing adversarial examples. In Proc. of the International Conference on Learning Representations ( ICLR ) , 2015
2015
-
[64]
R., You, Y., Wilson, A
Guo, C., Gardner, J. R., You, Y., Wilson, A. G., and Weinberger, K. Q. Simple black-box adversarial attacks. In Proc. of the International Conference on Machine Learning ( ICML ) , volume 97, pp.\ 2484--2493, 2019
2019
-
[65]
Watch out! motion is blurring the vision of your deep neural networks
Guo, Q., Juefei-Xu, F., Xie, X., Ma, L., Wang, J., Yu, B., Feng, W., and Liu, Y. Watch out! motion is blurring the vision of your deep neural networks. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 975--985. Curran Associates, Inc., 2020. URL https://proceedi...
2020
-
[66]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proc. of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 770--778, 2016
2016
-
[67]
Edge enhancement improves adversarial robustness in image classification
He, L., Ai, Q., Lei, Y., Pan, L., Ren, Y., and Xu, Z. Edge enhancement improves adversarial robustness in image classification. Neurocomputing, 518: 0 122--132, 2023. ISSN 0925-2312. doi:https://doi.org/10.1016/j.neucom.2022.10.059. URL https://www.sciencedirect.com/science/article/pii/S092523122201342X
-
[68]
Black-box adversarial attacks with limited queries and information
Ilyas, A., Engstrom, L., Athalye, A., and Lin, J. Black-box adversarial attacks with limited queries and information. In Proc. of the International Conference on Machine Learning ( ICML ) , pp.\ 2142--2151, 2018
2018
-
[69]
Prior convictions: Black-box adversarial attacks with bandits and priors
Ilyas, A., Engstrom, L., and Madry, A. Prior convictions: Black-box adversarial attacks with bandits and priors. In Proc. of the International Conference on Learning Representations ( ICLR ) , 2019
2019
-
[70]
and Gharge, S
Kekre, H. and Gharge, S. Image segmentation using extended edge operator for mammographic images. International Journal on Computer Science and Engineering, 2, 07 2010
2010
-
[71]
Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Proccessing Systems ( NIPS ) , pp.\ 1106--1114. Curran Associates, Inc., 2012
2012
-
[72]
Towards deep learning models resistant to adversarial attacks
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. In Proc. of the International Conference on Learning Representations ( ICLR ) , 2018
2018
-
[73]
Universal adversarial perturbations
Moosavi-Dezfooli, S.-M., Fawzi, A., Fawzi, O., and Frossard, P. Universal adversarial perturbations. Proc. of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 86--94, 2016 a
2016
-
[74]
Deepfool: A simple and accurate method to fool deep neural networks
Moosavi-Dezfooli, S.-M., Fawzi, A., and Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proc. of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 2574--2582, June 2016 b
2016
-
[75]
Nakka, K. K. and Salzmann, M. Learning transferable adversarial perturbations. In Advances in Neural Information Proccessing Systems ( NIPS ) , pp.\ 13950--13962, 2021
2021
-
[76]
J., Jha, S., Celik, Z
Papernot, N., Mcdaniel, P., Goodfellow, I. J., Jha, S., Celik, Z. B., and Swami, A. Practical black-box attacks against machine learning. Proc. of the ACM Asia Conference on Computer and Communications Security ( ASIA CCS ) , pp.\ 506--519, 2016 a
2016
-
[77]
B., and Swami, A
Papernot, N., McDaniel, P., Jha, S., Fredrikson, M., Celik, Z. B., and Swami, A. The limitations of deep learning in adversarial settings. In Proc. of the IEEE European Symposium on Security and Privacy ( EuroS&P ) , pp.\ 372--387, 2016 b
2016
-
[78]
Poursaeed, O., Katsman, I., Gao, B., and Belongie, S. J. Generative adversarial perturbations. Proc. of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 4422--4431, 2017
2017
-
[79]
Prewitt, J. M. S. Object enhancement and extraction. Picture Processing and. Psychopictorics, 1970
1970
-
[80]
Do imagenet classifiers generalize to imagenet? In Proc
Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do imagenet classifiers generalize to imagenet? In Proc. of the International Conference on Machine Learning ( ICML ) , pp.\ 5389--5400, 2019
2019
-
[81]
Optimal operators in digital image processing [Elektronische Ressource] /
Scharr, H. Optimal operators in digital image processing [Elektronische Ressource] /. PhD thesis, 09 2014
2014
-
[82]
P., Studer, C., Davis, L
Shafahi, A., Najibi, M., Ghiasi, A., Xu, Z., Dickerson, J. P., Studer, C., Davis, L. S., Taylor, G., and Goldstein, T. Adversarial training for free! In Advances in Neural Information Proccessing Systems ( NIPS ) , pp.\ 3353--3364, 2019
2019
-
[83]
Vggsound: A Large-Scale Audio-Visual Dataset
Shamsabadi, A. S., Oh, C., and Cavallaro, A. Edgefool: an adversarial image enhancement filter. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1898--1902, 2020. doi:10.1109/ICASSP40776.2020.9054368
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.