Recognition: unknown
Practical Formal Verification for MLIR Programs
Pith reviewed 2026-05-09 14:18 UTC · model grok-4.3
The pith
Restricting to a subset of MLIR programs enables linear-time semantic equivalence checks via hybrid concrete-symbolic interpretation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A hybrid concrete-symbolic interpretation approach, applied to a restricted class of MLIR programs, can establish semantic equivalence between an original program and its optimized version in time linear in the operations executed, while remaining agnostic to implementation details such as syntax, schedule, and storage.
What carries the argument
The hybrid concrete-symbolic interpretation approach to equivalence checking, which executes program operations while maintaining symbolic representations to compare outcomes without full symbolic simulation.
If this is right
- Optimizations applied through MLIR flows can be checked for semantic preservation without manual proofs for each transformation.
- Verification becomes feasible for entire toolchains processing many benchmark variants.
- The linear-time bound supports repeated checks during iterative optimization processes.
- Correctness guarantees extend across different implementation choices as long as the programs stay in the subset.
Where Pith is reading between the lines
- The same hybrid technique could be tested on other intermediate representations by applying similar program restrictions.
- Fast equivalence verification might enable automated exploration of optimization sequences where each candidate is checked before acceptance.
- Expanding the subset while preserving linearity would increase the range of verifiable transformations.
Load-bearing premise
The programs to be verified must fall within the supported subset so that their behaviors remain comparable through hybrid interpretation independent of how the transformations were performed.
What would settle it
A pair of programs in the supported subset that compute different results on the same input yet are reported as equivalent by the verifier, or an equivalent pair reported as inequivalent.
Figures






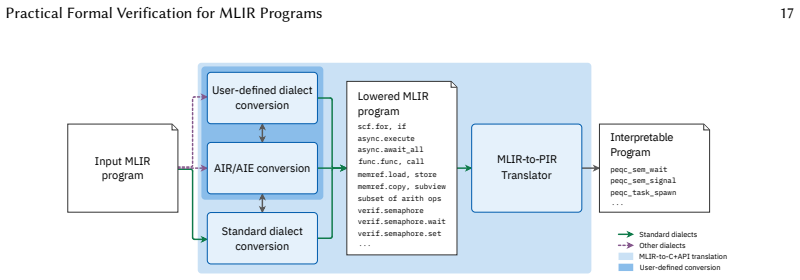
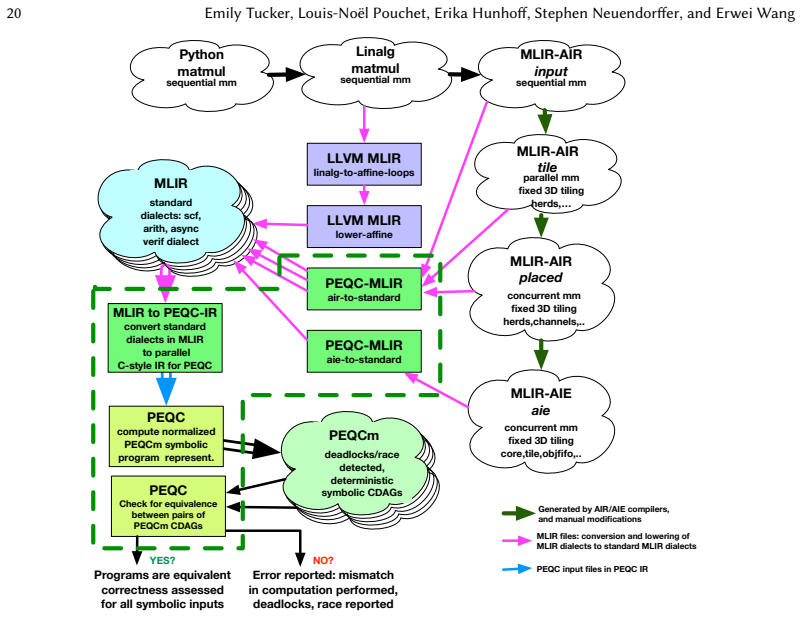

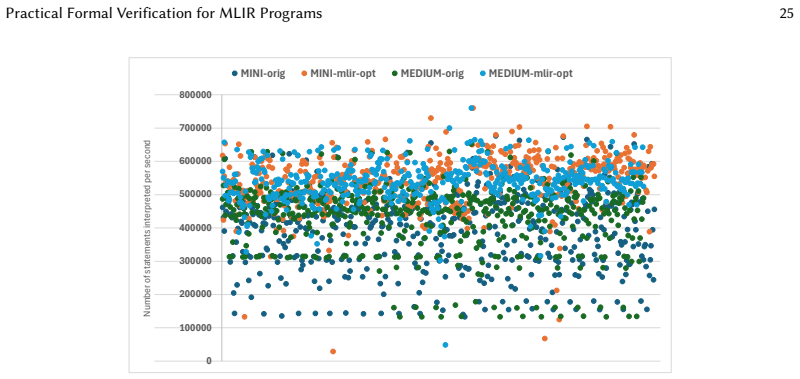
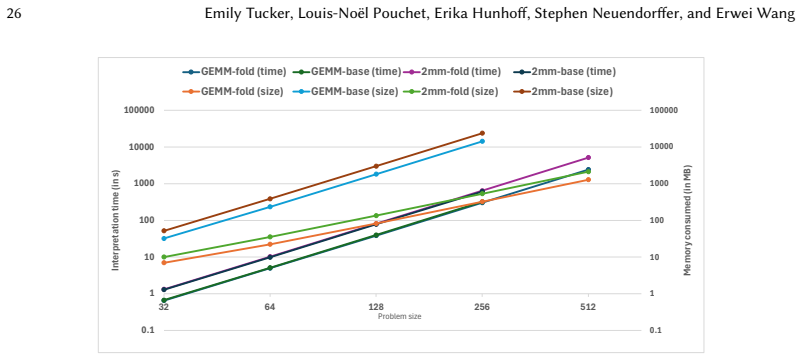

read the original abstract
Optimizing compilers have become a cornerstone for high-performance program generation in research and industry. Optimizations, including those implemented manually by a user and those target-specific and non-target-specific, are used to transform programs to achieve good performance. Although these optimizations are necessary for performance, assessing their correctness has remained a major challenge; the risk of incorrect code being deployed increases with unproven optimization flows. In this work, we target the formal verification of correctness of a transformed program by computing whether a pair of programs are semantically equivalent, one being a transformed version of the other. We restrict the class of programs supported to enable a hybrid concrete-symbolic interpretation approach to equivalence, which in turn is mostly agnostic to how the programs are implemented (syntax, schedule, storage, etc.). This approach can show equivalence in linear time with respect to the operations executed by the programs. We develop a verifier for a meaningful subset of MLIR, and report on the verification of the AMD MLIR-AIR and MLIR-AIE toolchains, as well as the standard mlir-opt on hundreds of benchmarks variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to enable practical formal verification of MLIR program transformations by restricting the supported program class to permit a hybrid concrete-symbolic interpreter that decides semantic equivalence in linear time with respect to executed operations. The interpreter is described as mostly agnostic to implementation details such as syntax, schedule, and storage. A verifier is implemented for a meaningful subset of MLIR and applied to the AMD MLIR-AIR and MLIR-AIE toolchains plus the standard mlir-opt pass on hundreds of benchmark variants.
Significance. If the hybrid method is shown to be sound for the restricted subset and the reported applications to production toolchains hold, the work would supply a scalable, practical technique for checking optimization correctness in the widely used MLIR infrastructure. The linear-time guarantee and direct use on industrial flows (AMD AIR/AIE) and standard passes would constitute a concrete contribution to compiler verification.
major comments (2)
- [Abstract] Abstract: the central claim that equivalence can be shown 'in linear time with respect to the operations executed by the programs' is asserted without any complexity argument, recurrence, or measurement in the provided text; this is load-bearing for the practicality argument.
- [Abstract] Abstract and approach description: the statement that the method 'is mostly agnostic to how the programs are implemented (syntax, schedule, storage, etc.)' is not supported once per-operation semantics must be supplied for every MLIR dialect operation (e.g., memref.load, affine.for, or AIR-specific ops). The restriction bounds the set of operations that require manual models but does not remove dependence on implementation semantics; any transformation that alters unmodeled storage layout or schedule renders the equivalence result unsound.
minor comments (1)
- [Evaluation] The evaluation section should report the precise number of benchmark variants, the distribution across dialects, and any cases where the verifier returned 'unknown' rather than a definitive equivalence result.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments highlight opportunities to strengthen the abstract's support for the central claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that equivalence can be shown 'in linear time with respect to the operations executed by the programs' is asserted without any complexity argument, recurrence, or measurement in the provided text; this is load-bearing for the practicality argument.
Authors: We agree that the abstract, as a high-level summary, does not contain an explicit complexity argument. The body of the paper (Section 3) establishes linearity by showing that the hybrid interpreter processes each operation exactly once, performing only constant-time concrete or symbolic updates per operation for the restricted subset (no unbounded loops or data-dependent control flow). To better support the claim in the abstract, we will add a concise parenthetical: '(by executing each operation once with O(1) work per operation)'. This revision will be made without altering the abstract's length constraints. revision: yes
-
Referee: [Abstract] Abstract and approach description: the statement that the method 'is mostly agnostic to how the programs are implemented (syntax, schedule, storage, etc.)' is not supported once per-operation semantics must be supplied for every MLIR dialect operation (e.g., memref.load, affine.for, or AIR-specific ops). The restriction bounds the set of operations that require manual models but does not remove dependence on implementation semantics; any transformation that alters unmodeled storage layout or schedule renders the equivalence result unsound.
Authors: The referee's observation is correct: semantic models must be supplied for each supported operation, and the approach is not fully independent of implementation semantics. Our phrasing 'mostly agnostic' was meant to indicate that the verifier framework does not embed assumptions about particular syntactic forms, schedules, or storage mappings once the per-operation models are provided. We will revise the abstract and introduction to read: 'mostly agnostic to implementation details such as specific syntax, schedules, or storage layouts, provided semantic models for the operations are supplied.' We will also add an explicit soundness caveat noting that transformations affecting unmodeled aspects fall outside the verified subset. revision: yes
Circularity Check
No circularity; derivation is self-contained methodological choice
full rationale
The paper presents restricting the program class as an explicit design decision that enables hybrid concrete-symbolic equivalence checking in linear time, with the verifier then applied empirically to MLIR toolchains and benchmarks. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text. The central claim does not reduce to its inputs by construction; the restriction is stated as a prerequisite rather than derived from the results it produces. This is the normal case of an independent engineering approach.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[n. d.]. LLVM. http://llvm.org
-
[2]
[n. d.]. PolyGeist: C/C++ frontend for MLIR. https://github.com/llvm/Polygeist
-
[3]
The KLEE Symbolic Execution Engine
2023. The KLEE Symbolic Execution Engine. https://klee.github.io
2023
-
[4]
AMD. [n. d.].MLIR-AIE. https://github.com/Xilinx/mlir-aie
-
[5]
AMD. [n. d.]. MLIR-AIR. https://xilinx.github.io/mlir-air/
-
[6]
AMD. [n. d.].MLIR-AIR. https://github.com/Xilinx/mlir-air
-
[7]
Ahn, Ignacio Laguna, Martin Schulz, Gregory L
Simone Atzeni, Ganesh Gopalakrishnan, Zvonimir Rakamaric, Dong H. Ahn, Ignacio Laguna, Martin Schulz, Gregory L. Lee, Joachim Protze, and Matthias S. Müller. 2016. ARCHER: Effectively Spotting Data Races in Large OpenMP Applications. In2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 53–62. https://doi.org/ 10.1109/IPDPS.2016.68
-
[8]
Travis Augustine, Janarthanan Sarma, Louis-Noël Pouchet, and Gabriel Rodríguez. 2019. Generating Piecewise-Regular Code from Irregular Structures. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI. Phoenix, AZ, USA, 625–639
2019
-
[9]
Baader and T
F. Baader and T. Nipkow. 1998.Term Rewriting and All That. Cambridge University Press
1998
-
[10]
Seongwon Bang, Seunghyeon Nam, Inwhan Chun, Ho Young Jhoo, and Juneyoung Lee. 2022. Smt-based translation validation for machine learning compiler. InInternational Conference on Computer Aided Verification. Springer, 386–407
2022
-
[11]
Sadayappan
Wenlei Bao, Sriram Krishnamoorthy, Louis-Noël Pouchet, Fabrice Rastello, and P. Sadayappan. 2016. PolyCheck: Dynamic Verification of Iteration Space Transformations on Affine Programs. InProceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages
2016
-
[12]
Siddharth Bhat, Alex Keizer, Chris Hughes, Andrés Goens, and Tobias Grosser. 2024. Verifying Peephole Rewriting in SSA Compiler IRs.LIPIcs, Volume 309, ITP 2024309 (2024), 9:1–9:20. https://doi.org/10.4230/LIPICS.ITP.2024.9
-
[13]
Ramanujam, and P
Uday Bondhugula, Albert Hartono, J. Ramanujam, and P. Sadayappan. 2008. A Practical Automatic Polyhedral Program Optimization System. InACM SIGPLAN Conference on Programming Language Design and Implementation. ACM. 28 Emily Tucker, Louis-Noël Pouchet, Erika Hunhoff, Stephen Neuendorffer, and Erwei Wang
2008
-
[14]
Zoran Budimlic, Michael Burke, Vincent Cavé, Kathleen Knobe, Geoff Lowney, Ryan Newton, Jens Palsberg, David Peixotto, Vivek Sarkar, and Frank Schlimbach. 2010. Concurrent Collections.Scientific Programming18, 3-4 (2010), 203–217
2010
-
[15]
Yang Chen, Alex Groce, Chaoqiang Zhang, Weng-Keen Wong, Xiaoli Fern, Eric Eide, and John Regehr. 2013. Tam- ing compiler fuzzers. InProceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation. 197–208
2013
-
[16]
Ramanuj Chouksey and Chandan Karfa. 2020. Verification of Scheduling of Conditional Behaviors in High-Level Synthesis.IEEE Transactions on Very Large Scale Integration (VLSI) Systems(2020)
2020
-
[17]
Basile Clément and Albert Cohen. 2022. End-to-end translation validation for the halide language. InOOPSLA 2022-Conference on Object-Oriented Programming Systems, Languages, and Applications
2022
-
[18]
Steven Eker. 2003. Associative-Commutative Rewriting on Large Terms. InRewriting Techniques and Applications, Gerhard Goos, Juris Hartmanis, Jan van Leeuwen, and Robert Nieuwenhuis (Eds.). Vol. 2706. Springer Berlin Heidelberg, Berlin, Heidelberg, 14–29. https://doi.org/10.1007/3-540-44881-0_3
-
[19]
Venmugil Elango, Fabrice Rastello, Louis-Noël Pouchet, Jagannathan Ramanujam, and Ponnuswamy Sadayappan. 2015. On characterizing the data access complexity of programs. InProceedings of the 42nd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages
2015
-
[20]
Schuyler Eldridge, Prithayan Barua, Aliaksei Chapyzhenka, Adam Izraelevitz, Jack Koenig, Chris Lattner, Andrew Lenharth, George Leontiev, Fabian Schuiki, Ram Sunder, et al. 2021. MLIR as Hardware Compiler Infrastructure. In Workshop on Open-Source EDA Technology (WOSET), Vol. 3
2021
-
[21]
Mathieu Fehr, Yuyou Fan, Hugo Pompougnac, John Regehr, and Tobias Grosser. 2025. First-Class Verification Dialects for MLIR.Proceedings of the ACM on Programming Languages9, PLDI (June 2025), 1466–1490. https: //doi.org/10.1145/3729309
-
[22]
Oliver Flatt and Yihong Zhang. [n. d.]. Egglog In Practice: Automatically Improving Floating-point Error. ([n. d.])
-
[23]
Pavel Golovin, Michalis Kokologiannakis, and Viktor Vafeiadis. 2025. RELINCHE: Automatically Checking Lineariz- ability under Relaxed Memory Consistency.Proceedings of the ACM on Programming Languages9, POPL (Jan. 2025), 2090–2117. https://doi.org/10.1145/3704906
-
[24]
Yizi Gu and John Mellor-Crummey. 2018. Dynamic Data Race Detection for OpenMP Programs. InSC18: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, Dallas, TX, USA, 767–778. https://doi.org/10.1109/SC.2018.00064
-
[25]
Yann Herklotz, James D Pollard, Nadesh Ramanathan, and John Wickerson. 2021. Formal verification of high-level synthesis.Proceedings of the ACM on Programming Languages5, OOPSLA (2021), 1–30
2021
-
[26]
Erika Hunhoff, Joseph Melber, Kristof Denolf, Andra Bisca, Samuel Bayliss, Stephen Neuendorffer, Jeff Fifield, Jack Lo, Pranathi Vasireddy, Phil James-Roxby, and Eric Keller. 2025. Efficiency, Expressivity, and Extensibility in a Close-to- Metal NPU Programming Interface. In2025 IEEE 33rd Annual International Symposium on Field-Programmable Custom Computi...
-
[27]
Marie-Christine Jakobs. 2021. PEQCHECK: Localized and Context-aware Checking of Functional Equivalence. In2021 IEEE/ACM 9th International Conference on Formal Methods in Software Engineering (FormaliSE). 130–140. https://doi.org/10.1109/FormaliSE52586.2021.00019
-
[28]
Feiyang Jin, Lechen Yu, Tiago Cogumbreiro, Jun Shirako, and Vivek Sarkar. 2023. Dynamic Determinacy Race Detection for Task-Parallel Programs with Promises. In37th European Conference on Object-Oriented Programming (ECOOP 2023). Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 13–1
2023
-
[29]
Chandan Karfa, Kunal Banerjee, Dipankar Sarkar, and Chittaranjan Mandal. 2013. Verification of loop and arithmetic transformations of array-intensive behaviors.IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems 32, 11 (2013), 1787–1800
2013
-
[30]
Karfa, C
C. Karfa, C. Mandal, D. Sarkar, S.R. Pentakota, and C. Reade. 2006. A formal verification method of scheduling in high-level synthesis. In7th International Symposium on Quality Electronic Design (ISQED’06)
2006
-
[31]
Michalis Kokologiannakis, Azalea Raad, and Viktor Vafeiadis. 2019. Model Checking for Weakly Consistent Libraries. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2019). Association for Computing Machinery, New York, NY, USA, 96–110. https://doi.org/10.1145/3314221.3314609
-
[32]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. 2021. MLIR: Scaling compiler infrastructure for domain specific computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2–14
2021
-
[33]
Jonathan K. Lee and Jens Palsberg. 2010. Featherweight X10: A Core Calculus for Async-Finish Parallelism.SIGPLAN Not.45, 5 (Jan. 2010), 25–36. https://doi.org/10.1145/1837853.1693459
-
[34]
Xavier Leroy, Sandrine Blazy, Daniel Kästner, Bernhard Schommer, Markus Pister, and Christian Ferdinand. 2016. CompCert-a formally verified optimizing compiler. InERTS 2016: Embedded Real Time Software and Systems, 8th European Congress. Practical Formal Verification for MLIR Programs 29
2016
-
[35]
Daniel Liew, Daniel Schemmel, Cristian Cadar, Alastair F Donaldson, Rafael Zahl, and Klaus Wehrle. 2017. Floating- point symbolic execution: a case study in n-version programming. In2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 601–612
2017
-
[36]
Nuno P Lopes, Juneyoung Lee, Chung-Kil Hur, Zhengyang Liu, and John Regehr. 2021. Alive2: bounded translation validation for LLVM. InACM SIGPLAN International Conference on Programming Language Design and Implementation
2021
-
[37]
Michaël Marcozzi, Qiyi Tang, Alastair F Donaldson, and Cristian Cadar. 2019. Compiler fuzzing: How much does it matter?Proceedings of the ACM on Programming Languages3, OOPSLA (2019), 1–29
2019
-
[38]
Eric G Mercer, Peter Anderson, Nick Vrvilo, and Vivek Sarkar. 2015. Model Checking Task Parallel Programs Using Gradual Permissions (N). In2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 535–540
2015
- [39]
-
[40]
d.].MLIR: Multi-Level IR in LLVM
MLIR [n. d.].MLIR: Multi-Level IR in LLVM. https://mlir.llvm.org
-
[41]
George C Necula. 2000. Translation validation for an optimizing compiler.ACM SIGPLAN Notices35, 5 (2000), 83–94
2000
-
[42]
Louis-Noel Pouchet. [n. d.]. PolyBench/C: the Polyhedral Benchmark suite. http://polybench.sourceforge.net
-
[43]
Louis-Noël Pouchet, Emily Tucker, Niansong Zhang, Hongzheng Chen, Debjit Pal, Gabriel Rodríguez, and Zhiru Zhang. 2024. Formal Verification of Source-to-Source Transformations for HLS. InProceedings of the 2024 ACM/SIGDA International Symposium on Field Programmable Gate Arrays. 97–107
2024
-
[44]
Louis-Noël Pouchet and Tomofumi Yuki. [n. d.].PolyBench/C 4.2.1. http://polybench.sourceforge.net
-
[45]
David A Ramos and Dawson Engler. 2015. Under-constrained symbolic execution: Correctness checking for real code. In24th{USENIX}Security Symposium ({USENIX}Security 15)
2015
-
[46]
Alejandro Rico, Satyaprakash Pareek, Javier Cabezas, David Clarke, Baris Ozgul, Francisco Barat, Yao Fu, Stephan Munz, Dylan Stuart, Patrick Schlangen, Pedro Duarte, Sneha Date, Indrani Paul, Jian Weng, Sonal Santan, Vinod Kathail, Ashish Sirasao, and Juanjo Noguera. 2024. AMD XDNA NPU in Ryzen AI Processors .IEEE Micro44, 06 (Nov. 2024), 73–82. https://d...
-
[47]
Gabriel Rodríguez, José M Andión, Mahmut T Kandemir, and Juan Touriño. 2016. Trace-based affine reconstruction of codes. InProceedings of the 2016 International Symposium on Code Generation and Optimization. 139–149
2016
-
[48]
Grigore Ros,u and Traian Florin S, erbănută. 2010. An Overview of the K Semantic Framework.The Journal of Logic and Algebraic Programming79, 6 (2010), 397–434
2010
-
[49]
Jaroslav Ševčík, Viktor Vafeiadis, Francesco Zappa Nardelli, Suresh Jagannathan, and Peter Sewell. 2013. CompCertTSO: A verified compiler for relaxed-memory concurrency.Journal of the ACM (JACM)60, 3 (2013), 1–50
2013
-
[50]
KC Shashidhar, Maurice Bruynooghe, Francky Catthoor, and Gerda Janssens. 2005. Verification of Source Code Transformations by Program Equivalence Checking.CC(2005)
2005
-
[51]
Stephen F Siegel, Manchun Zheng, Ziqing Luo, Timothy K Zirkel, Andre V Marianiello, John G Edenhofner, Matthew B Dwyer, and Michael S Rogers. 2015. CIVL: the concurrency intermediate verification language. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–12
2015
-
[52]
Siegel, Manchun Zheng, Ziqing Luo, Timothy K
Stephen F. Siegel, Manchun Zheng, Ziqing Luo, Timothy K. Zirkel, Andre V. Marianiello, John G. Edenhofner, Matthew B. Dwyer, and Michael S. Rogers. 2015. CIVL: The Concurrency Intermediate Verification Language. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. ACM, Austin Texas, 1–12. https://...
-
[53]
Bradley Swain, Yanze Li, Peiming Liu, Ignacio Laguna, Giorgis Georgakoudis, and Jeff Huang. 2020. OMPRacer: A Scalable and Precise Static Race Detector for OpenMP Programs. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14. https://doi.org/10.1109/SC41405.2020.00058
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00058 2020
-
[54]
Ross Tate, Michael Stepp, Zachary Tatlock, and Sorin Lerner. 2009. Equality saturation: a new approach to optimization. InProceedings of the 36th annual ACM SIGPLAN-SIGACT symposium on Principles of programming languages. 264–276
2009
-
[55]
Emily Tucker and Louis-Noël Pouchet. [n. d.].PEQC-MLIR. https://github.com/axolotls73/PEQC-MLIR
-
[56]
Emily Tucker and Louis-Noël Pouchet. 2025. Verification of Concurrent Programs Using Hybrid Concrete-Symbolic Interpretation.Principles and Practices of Building Parallel Software: Essays Dedicated to Vivek Sarkar on the Occasion of His 64th Birthday14564 (2025), 90
2025
-
[57]
Martin Vechev, Eran Yahav, Raghavan Raman, and Vivek Sarkar. 2010. Automatic verification of determinism for structured parallel programs. InStatic Analysis: 17th International Symposium, SAS 2010, Perpignan, France, September 14-16, 2010. Proceedings 17. Springer, 455–471
2010
-
[58]
Sven Verdoolaege, Gerda Janssens, and Maurice Bruynooghe. 2012. Equivalence checking of static affine programs using widening to handle recurrences.ACM Trans. on Programming Languages and Systems (TOPLAS)34, 3 (2012), 11
2012
-
[59]
Erwei Wang, Samuel Bayliss, Andra Bisca, Zachary Blair, Sangeeta Chowdhary, Kristof Denolf, Jeff Fifield, Brandon Freiberger, Erika Hunhoff, Phil James-Roxby, et al. 2025. From Loop Nests to Silicon: Mapping AI Workloads onto 30 Emily Tucker, Louis-Noël Pouchet, Erika Hunhoff, Stephen Neuendorffer, and Erwei Wang AMD NPUs with MLIR-AIR.arXiv preprint arXi...
-
[60]
Jie Wang, Licheng Guo, and Jason Cong. 2021. AutoSA: A polyhedral compiler for high-performance systolic arrays on FPGA. InThe 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays
2021
-
[61]
Yanzhao Wang, Fei Xie, Zhenkun Yang, Pasquale Cocchini, and Jin Yang. 2024. A Systematic Translation Validation Framework for MLIR-Based Compilers. (2024)
2024
-
[62]
Yanzhao Wang, Fei Xie, Zhenkun Yang, Pasquale Cocchini, and Jin Yang. 2024. A Systematic Translation Validation Framework for MLIR-Based Compilers.International Journal of Software Engineering and Knowledge Engineering(June 2024), 1–20. https://doi.org/10.1142/S021819402450030X
-
[63]
Yisu Remy Wang, Shana Hutchison, Jonathan Leang, Bill Howe, and Dan Suciu. 2020. SPORES: Sum-Product Optimization via Relational Equality Saturation for Large Scale Linear Algebra.Proc. VLDB Endow.13, 12 (jul 2020), 1919–1932
2020
-
[64]
Max Willsey, Chandrakana Nandi, Yisu Remy Wang, Oliver Flatt, Zachary Tatlock, and Pavel Panchekha. 2021. Egg: Fast and extensible equality saturation.Proceedings of the ACM on Programming Languages(2021)
2021
-
[65]
Wenhao Wu, Jan Hückelheim, Paul D Hovland, and Stephen F Siegel. 2022. Verifying Fortran Programs with CIVL. In International Conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 106–124
2022
-
[66]
Jiaqi Yin, Zhan Song, Nicolas Bohm Agostini, Antonino Tumeo, and Cunxi Yu. 2025. HEC: Equivalence Verification Checking for Code Transformation via Equality Saturation. In2025 USENIX Annual Technical Conference (USENIX ATC 25). 1181–1196
2025
-
[67]
Yihong Zhang, Yisu Remy Wang, Oliver Flatt, David Cao, Philip Zucker, Eli Rosenthal, Zachary Tatlock, and Max Willsey. 2023. Better together: Unifying datalog and equality saturation.Proceedings of the ACM on Programming Languages7, PLDI (2023), 468–492
2023
-
[68]
Yihong Zhang, Yisu Remy Wang, Oliver Flatt, David Cao, Philip Zucker, Eli Rosenthal, Zachary Tatlock, and Max Willsey. 2023. Better Together: Unifying Datalog and Equality Saturation.Proceedings of the ACM on Programming Languages7, PLDI (June 2023), 468–492. https://doi.org/10.1145/3591239 Practical Formal Verification for MLIR Programs 31 A Appendix A.1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.