Recognition: unknown
MORPH: Multi-Environment Orchestrated Reinforcement Learning for PRB Handling in O-RAN
Pith reviewed 2026-05-09 18:00 UTC · model grok-4.3
The pith
Fusing real measurements, empirical data, and simulations during RL training produces more reliable policies for physical resource block allocation to 5G slices in O-RAN.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
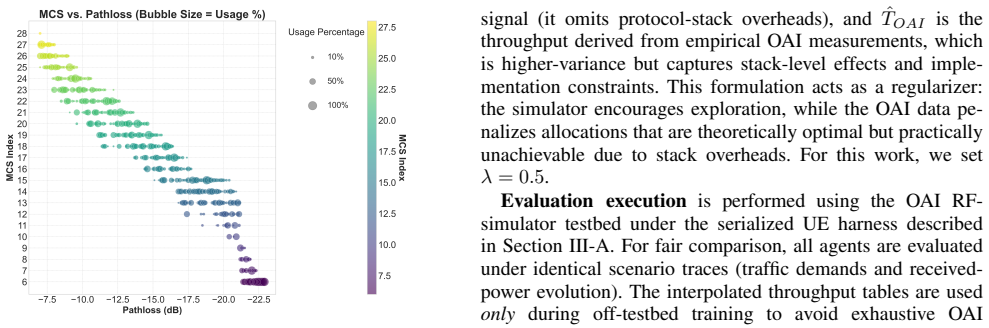
MORPH is a multi-environment RL pipeline for slice-aware PRB-level spectrum allocation built on OpenAirInterface in RF-simulator mode. It fuses three throughput sources—iPerf measurements on the OAI stack under controlled AWGN pathloss, a distribution-aware theoretical estimator conditioned on empirical MCS selections, and scalable estimates from a 3GPP-parameterized PHY-fidelity OFDM simulator—into the training signal. When the resulting policies are evaluated on the OAI execution harness across heterogeneous slicing scenarios, they deliver more robust slice-wise throughput and improved SLA compliance than policies trained on any single throughput source alone.
What carries the argument
The MORPH fusion mechanism, which combines OAI iPerf measurements, empirical MCS-conditioned throughput estimates, and PHY simulator outputs into one training signal for optimizing RL policies on PRB allocation and slice isolation within a single gNB.
If this is right
- Slice-wise throughput stays more consistent across different traffic mixes when policies come from fused training signals.
- Service level agreement compliance rises for multiple slices sharing spectrum inside one cell.
- PRB-level spectrum sharing and slice isolation become practical inside a single gNB using the learned policies.
- The same pipeline supplies a concrete starting point for extending learned coordination to multi-cell interference settings.
Where Pith is reading between the lines
- The fusion idea could transfer to other wireless resource management tasks where real measurements are expensive and simulators miss protocol details.
- Running the same agents on multi-cell testbeds would show whether the robustness carries over when inter-cell interference appears.
- Online versions of the pipeline might allow an O-RAN controller to adapt allocation policies as live traffic statistics arrive.
Load-bearing premise
The combination of the three throughput signals during training does not introduce systematic bias or instability that surfaces only when the learned policy is deployed on the live OAI stack under varying traffic or path-loss conditions.
What would settle it
Train one MORPH agent and one single-source agent on the same slicing scenarios, then deploy both on the OAI stack under a new traffic pattern or path-loss setting outside the training set and measure whether the MORPH agent's slice throughputs remain closer to their targets without sudden SLA violations.
Figures






read the original abstract
Reinforcement-learning (RL) solutions for dynamic spectrum access and radio resource management in Open Radio Access Networks (O-RAN) depend critically on the fidelity of the throughput signal used for training. Analytical or physical-layer (PHY)-only simulators scale well but often miss protocol-stack effects such as signaling overhead and retransmissions, whereas exhaustive throughput profiling on a standards-compliant 5G stack is slow and can be unstable under software execution constraints. This paper presents MORPH, a measurement-grounded multi-environment RL pipeline {for slice-aware PRB-level spectrum allocation (spectrum sharing and slice isolation within a single gNB)} built on OpenAirInterface (OAI) 5G-NR RF-simulator mode. MORPH leverages three complementary throughput sources: (i) application-layer throughput measured via \texttt{iPerf} on the OAI stack under controlled AWGN pathloss settings, (ii) empirical MCS-selection distributions conditioned on path loss, enabling a distribution-aware theoretical throughput estimator that reflects standards-compliant link adaptation, and (iii) scalable throughput estimates from a 3GPP-parameterized PHY-fidelity OFDM simulator. Using these components, we train and compare agents that differ only in the origin of their throughput feedback: an OAI-grounded practical agent, a simulator-driven agent, and MORPH, which fuses real and synthetic throughput signals for policy optimization. Evaluation on the OAI execution harness across heterogeneous slicing scenarios shows that MORPH yields more robust slice-wise performance and improved SLA compliance than single-source training, providing a practical foundation for PRB-level spectrum sharing and slice isolation within a single-cell stack and a stepping stone toward multi-cell spectrum coordination and interference management.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MORPH, a multi-environment RL pipeline for slice-aware PRB-level spectrum allocation in O-RAN built on OpenAirInterface 5G-NR. It fuses three throughput sources—OAI iPerf measurements under AWGN pathloss, MCS-conditioned theoretical throughput estimators, and 3GPP-parameterized PHY simulator estimates—to train agents, claiming that the fused MORPH agent produces more robust slice-wise performance and higher SLA compliance than single-source (OAI-only or simulator-only) baselines across heterogeneous slicing scenarios on the OAI execution harness.
Significance. If the fusion mechanism and empirical gains hold under scrutiny, the work supplies a practical route to training RL policies for PRB allocation that combine measurement fidelity with simulator scalability, directly supporting single-cell spectrum sharing and slice isolation in O-RAN deployments.
major comments (2)
- [Abstract] Abstract: the central claim that 'MORPH yields more robust slice-wise performance and improved SLA compliance than single-source training' is stated without any quantitative metrics, ablation results, or description of the fusion procedure (reward shaping, multi-head critic, data-mixing schedule, or adaptive weighting). This absence prevents verification that the reported robustness follows from the method rather than an artifact of the particular fusion rule.
- [Evaluation] Evaluation description: the manuscript must demonstrate that the fusion of (i) OAI iPerf, (ii) empirical MCS-conditioned throughput, and (iii) 3GPP PHY estimates does not inject systematic bias or instability when policies are deployed back on the real OAI stack under varying traffic loads or path-loss conditions; the current text supplies no such stability analysis or cross-condition results.
minor comments (1)
- [Abstract] The abstract and title use 'PRB Handling' without expanding the acronym on first use; clarify as 'Physical Resource Block' for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'MORPH yields more robust slice-wise performance and improved SLA compliance than single-source training' is stated without any quantitative metrics, ablation results, or description of the fusion procedure (reward shaping, multi-head critic, data-mixing schedule, or adaptive weighting). This absence prevents verification that the reported robustness follows from the method rather than an artifact of the particular fusion rule.
Authors: We agree that the abstract prioritizes brevity and therefore omits specific quantitative results and procedural details. The full manuscript describes the multi-environment fusion of the three throughput sources (OAI iPerf, MCS-conditioned estimators, and 3GPP PHY simulator) in the methods section and presents ablation comparisons of single-source versus fused agents in the evaluation. To improve accessibility, we will revise the abstract to include a high-level description of the fusion approach and reference the robustness gains demonstrated in the results. revision: yes
-
Referee: [Evaluation] Evaluation description: the manuscript must demonstrate that the fusion of (i) OAI iPerf, (ii) empirical MCS-conditioned throughput, and (iii) 3GPP PHY estimates does not inject systematic bias or instability when policies are deployed back on the real OAI stack under varying traffic loads or path-loss conditions; the current text supplies no such stability analysis or cross-condition results.
Authors: The evaluation deploys all trained policies, including the fused MORPH agent, directly on the OAI execution harness across heterogeneous slicing scenarios that vary traffic loads and path-loss settings. This real-stack deployment provides evidence that the fused training does not introduce deployment instability. We acknowledge, however, that an explicit dedicated stability analysis with additional cross-condition breakdowns would strengthen the presentation. We will add this analysis in the revised manuscript. revision: yes
Circularity Check
No significant circularity; claims rest on empirical multi-source RL comparison
full rationale
The paper describes an empirical pipeline that trains separate RL agents on three distinct throughput sources (OAI iPerf measurements, MCS-conditioned theoretical estimates, and 3GPP PHY simulator outputs) and evaluates the resulting policies on the real OAI execution harness. No equations, fitted parameters, or derivation steps are presented that reduce by construction to the inputs; the central claim of improved slice performance and SLA compliance with the fused MORPH agent is supported by direct experimental comparison rather than self-definition, renaming, or self-citation chains. The fusion mechanism itself is not formalized mathematically in the abstract or described text, but this absence does not create circularity—it simply leaves the robustness of the fusion as an open empirical question.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Un- derstanding o-ran: Architecture, interfaces, algorithms, security, and re- search challenges,
M. Polese, L. Bonati, S. D’Oro, S. Basagni, and T. Melodia, “Un- derstanding o-ran: Architecture, interfaces, algorithms, security, and re- search challenges,”IEEE Communications Surveys & Tutorials, vol. 25, no. 2, pp. 1376–1411, 2023
2023
-
[2]
Intelligence and learning in o-ran for data-driven nextg cellular networks,
L. Bonati, M. Polese, S. D’Oro, S. Sharma, and T. Melodia, “Intelligence and learning in o-ran for data-driven nextg cellular networks,”IEEE Communications Magazine, 2020. [Online]. Available: https://ieeexplore.ieee.org/document/9286744
-
[3]
Towards an ai-driven ran: Introducing intelligence in the control loop,
P. Lopez, M. Garc ´ıa-Lozano, O. Sallent, and F. Casadevall, “Towards an ai-driven ran: Introducing intelligence in the control loop,” inIEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), 2020. [Online]. Available: https://ieeexplore.ieee. org/document/9285330
-
[4]
Llm-augmented deep reinforcement learning for dynamic o-ran network slicing,
F. Lotfi, H. Rajoli, and F. Afghah, “Llm-augmented deep reinforcement learning for dynamic o-ran network slicing,” inICC 2025 - IEEE International Conference on Communications, 2025, pp. 3827–3832
2025
-
[5]
Actor-critic network for o-ran resource allocation: xapp design, deployment, and analysis,
M. Kouchaki and V . Marojevic, “Actor-critic network for o-ran resource allocation: xapp design, deployment, and analysis,” in2022 IEEE Globecom Workshops (GC Wkshps), 2022, pp. 968–973
2022
-
[6]
Intelligent task offloading: Advanced mec task offloading and resource management in 5g networks,
A. Ebrahimi and F. Afghah, “Intelligent task offloading: Advanced mec task offloading and resource management in 5g networks,” in2025 IEEE Wireless Communications and Networking Conference (WCNC), 2025, pp. 1–6
2025
-
[7]
Dynamic cu-du selection for resource allocation in o-ran using actor-critic learning,
S. Mollahasani, M. Erol-Kantarci, and R. Wilson, “Dynamic cu-du selection for resource allocation in o-ran using actor-critic learning,” in 2021 IEEE Global Communications Conference (GLOBECOM), 2021, pp. 1–6
2021
-
[8]
Sim2real for reinforcement learning driven next generation networks,
X. Zhang, A. Talwar, P. Li, J. D. Thomas, and A. Sathiaseelan, “Sim2real for reinforcement learning driven next generation networks,” arXiv preprint arXiv:2206.03846, 2022. [Online]. Available: https: //arxiv.org/abs/2206.03846
-
[9]
Overcoming the sim-to-real gap: Leveraging simulation to learn to explore for real-world RL,
A. Wagenmaker, K. Huang, L. Ke, K. Jamieson, and A. Gupta, “Overcoming the sim-to-real gap: Leveraging simulation to learn to explore for real-world RL,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=JjQl8hXJAS
2024
-
[10]
DORA: Dynamic O- RAN resource allocation for multi-slice 5G networks,
A. E. Dorcheh, T. Seyfi, and F. Afghah, “DORA: Dynamic O- RAN resource allocation for multi-slice 5G networks,”arXiv preprint arXiv:2509.07242, 2025
-
[11]
Empowering the 6g cellular architecture with open ran,
M. Polese, M. Dohler, F. Dressler, M. Erol-Kantarci, R. Jana, R. Knopp, and T. Melodia, “Empowering the 6g cellular architecture with open ran,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 2, pp. 245–262, 2024
2024
-
[12]
Machine learning-based xapp for dynamic resource allocation in o-ran networks,
M. M. H. Qazzaz, L. Kulacz, A. Kliks, S. A. Zaidi, M. Dryjanski, and D. McLernon, “Machine learning-based xapp for dynamic resource allocation in o-ran networks,” in2024 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN), 2024, pp. 492–497
2024
-
[13]
C. Tsampazi, M. Levorato, F. Restuccia, and T. Melodia, “Pandora: Automated design and comprehensive evaluation of deep reinforcement learning agents for open ran,”IEEE Transactions on Mobile Computing, 2025, early Access. [Online]. Available: https://ieeexplore. ieee.org/document/10766614
-
[14]
M. Polese, L. Bonati, S. D’Oro, S. Sharma, and T. Melodia, “Colo-ran: Developing machine learning-based xapps for open ran closed-loop control on programmable experimental platforms,” IEEE Communications Magazine, 2022. [Online]. Available: https: //ieeexplore.ieee.org/document/9814869
-
[15]
Oranus: Latency-tailored orchestration via stochastic network calculus in 6g o-ran,
O. Adamuz-Hinojosa, L. Zanzi, V . Sciancalepore, A. Garcia-Saavedra, and X. Costa-P ´erez, “Oranus: Latency-tailored orchestration via stochastic network calculus in 6g o-ran,” 2024. [Online]. Available: https://arxiv.org/abs/2401.03812
-
[16]
Amitai Uzrad 17 35 Kathrin Hanauer, Monika Henzinger, Lara Ost, and Stefan Schmid
C. Puligheddu, J. Ashdown, C. F. Chiasserini, and F. Restuccia, “Sem-o-ran: Semantic and flexible o-ran slicing for nextg edge-assisted mobile systems,” inIEEE INFOCOM 2023 - IEEE Conference on Computer Communications. IEEE, May 2023, p. 1–10. [Online]. Available: http://dx.doi.org/10.1109/INFOCOM53939.2023.10228870
-
[17]
Oranslice: An open source 5g network slicing platform for o-ran,
H. Cheng, S. D’Oro, R. Gangula, S. Velumani, D. Villa, L. Bonati, M. Polese, T. Melodia, G. Arrobo, and C. Maciocco, “Oranslice: An open source 5g network slicing platform for o-ran,” inProceedings of the 30th Annual International Conference on Mobile Computing and Networking, ser. ACM MobiCom ’24. New York, NY , USA: Association for Computing Machinery, ...
-
[18]
Orchestran: Orchestrat- ing network intelligence in the open ran,
S. D’Oro, L. Bonati, M. Polese, and T. Melodia, “Orchestran: Orchestrat- ing network intelligence in the open ran,”IEEE Transactions on Mobile Computing, vol. 23, no. 7, pp. 7952–7968, 2024
2024
-
[19]
M. Zhao, Y . Zhang, Q. Liu, A. Kak, and N. Choi, “Adaslicing: Adaptive online network slicing under continual network dynamics in open radio access networks,”arXiv preprint arXiv:2501.06943, 2025, accepted at IEEE INFOCOM 2025
-
[20]
On the effects of modeling on the sim-to-real transfer gap in twinning the powder platform,
M. McManus, Y . Cui, J. Z. Zhang, E. S. Bentley, M. Medley, N. Mas- tronarde, and Z. Guan, “On the effects of modeling on the sim-to-real transfer gap in twinning the powder platform,” in2024 IEEE Globecom Workshops (GC Wkshps), 2024, pp. 1–6
2024
-
[21]
An open ran framework for the dynamic control of 5g service level agreements,
E. Moro, M. Polese, A. Capone, and T. Melodia, “An open ran framework for the dynamic control of 5g service level agreements,” in 2023 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), 2023, pp. 141–146
2023
-
[22]
Hexran: A pro- grammable approach to open ran base station system design,
A. Kak, V .-Q. Pham, H.-T. Thieu, and N. Choi, “Hexran: A pro- grammable approach to open ran base station system design,”IEEE Transactions on Network and Service Management, vol. 22, no. 6, pp. 5803–5821, 2025
2025
-
[23]
Tc-ran: A programmable traffic control service model for 5g/6g sd-ran,
M. Irazabal and N. Nikaein, “Tc-ran: A programmable traffic control service model for 5g/6g sd-ran,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 2, pp. 406–419, 2024
2024
-
[24]
X5g: An open, programmable, multi-vendor, end-to-end, private 5g o-ran testbed with nvidia arc and openairinterface,
D. Villa, I. Khan, F. Kaltenberger, N. Hedberg, R. S. da Silva, S. Max- enti, L. Bonati, A. Kelkar, C. Dick, E. Baena, J. M. Jornet, T. Melodia, M. Polese, and D. Koutsonikolas, “X5g: An open, programmable, multi-vendor, end-to-end, private 5g o-ran testbed with nvidia arc and openairinterface,”IEEE Transactions on Mobile Computing, vol. 24, no. 11, pp. 1...
2025
-
[25]
Safeslice: Enabling sla-compliant o-ran slicing via safe deep reinforcement learning,
M. Nagib, T. Ciodaro, M. Razzaghpour, M. Polese, L. Bonati, F. Restuccia, and T. Melodia, “Safeslice: Enabling sla-compliant o-ran slicing via safe deep reinforcement learning,”arXiv preprint arXiv:2503.12753, 2025. [Online]. Available: https://arxiv.org/abs/2503. 12753
-
[26]
Onslicing: online end-to-end network slicing with reinforcement learning,
Q. Liu, N. Choi, and T. Han, “Onslicing: online end-to-end network slicing with reinforcement learning,” inProceedings of the 17th International Conference on Emerging Networking EXperiments and Technologies, ser. CoNEXT ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 141–153. [Online]. Available: https://doi.org/10.1145/3485983.3494850
-
[27]
Generalizable resource scaling of 5g slices using constrained reinforce- ment learning,
M. Sulaiman, M. Ahmadi, M. A. Salahuddin, R. Boutaba, and A. Saleh, “Generalizable resource scaling of 5g slices using constrained reinforce- ment learning,” inNOMS 2023-2023 IEEE/IFIP Network Operations and Management Symposium, 2023, pp. 1–9
2023
-
[28]
R. Barker, A. E. Dorcheh, T. Seyfi, and F. Afghah, “Real: Reinforcement learning-enabled xapps for experimental closed-loop optimization in o-ran with osc ric and srsran,”arXiv preprint arXiv:2502.00715, 2025. [Online]. Available: https://arxiv.org/abs/2502.00715
-
[29]
3rd Generation Partnership Project (3GPP): NR; Physical layer procedures for data (Release 17),
“3rd Generation Partnership Project (3GPP): NR; Physical layer procedures for data (Release 17),” 3rd Generation Partnership Project (3GPP), 2024, 3GPP TS 38.214 V17.4.0. [On- line]. Available: https://portal.3gpp.org/desktopmodules/Specifications/ SpecificationDetails.aspx?specificationId=3216
2024
-
[30]
NR—Physical layer procedures for data: Adaptive Modulation and Coding Schemes (MCS) Indices 6–28,
“NR—Physical layer procedures for data: Adaptive Modulation and Coding Schemes (MCS) Indices 6–28,” Technical Specification (TS) 38.214, Version 18.6.0, 3rd Generation Partnership Project (3GPP), April 2025, table 5.1.3.1-1. Available: https://www.3gpp.org/DynaReport/ 38214.htm
2025
-
[31]
A comparative analysis of deep reinforcement learning-based xapps in o-ran,
C. Tsampazi, F. Restuccia, and T. Melodia, “A comparative analysis of deep reinforcement learning-based xapps in o-ran,” inIEEE International Conference on Computer Communications (INFOCOM), 2023. [Online]. Available: https://ieeexplore.ieee.org/ document/10437367
-
[32]
Colosseum: The open ran digital twin,
M. Polese, S. D’Oro, L. Bonati, and T. Melodia, “Colosseum: The open ran digital twin,”IEEE Communications Magazine, 2024. [Online]. Available: https://ieeexplore.ieee.org/document/10643670
-
[33]
Optimizing urllc in open ran: A deep reinforcement learning-based trade-off analysis,
R. M. Sohaib, S. T. Shah, M. A. Jamshed, O. Onireti, and P. Yadav, “Optimizing urllc in open ran: A deep reinforcement learning-based trade-off analysis,”IEEE Communications Standards Magazine, pp. 1– 1, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.