Recognition: unknown
A Low-Latency Fraud Detection Layer for Detecting Adversarial Interaction Patterns in LLM-Powered Agents
Pith reviewed 2026-05-09 18:53 UTC · model grok-4.3
The pith
A feature-based fraud detector identifies adversarial patterns in LLM agent interactions over nine times faster than LLM-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
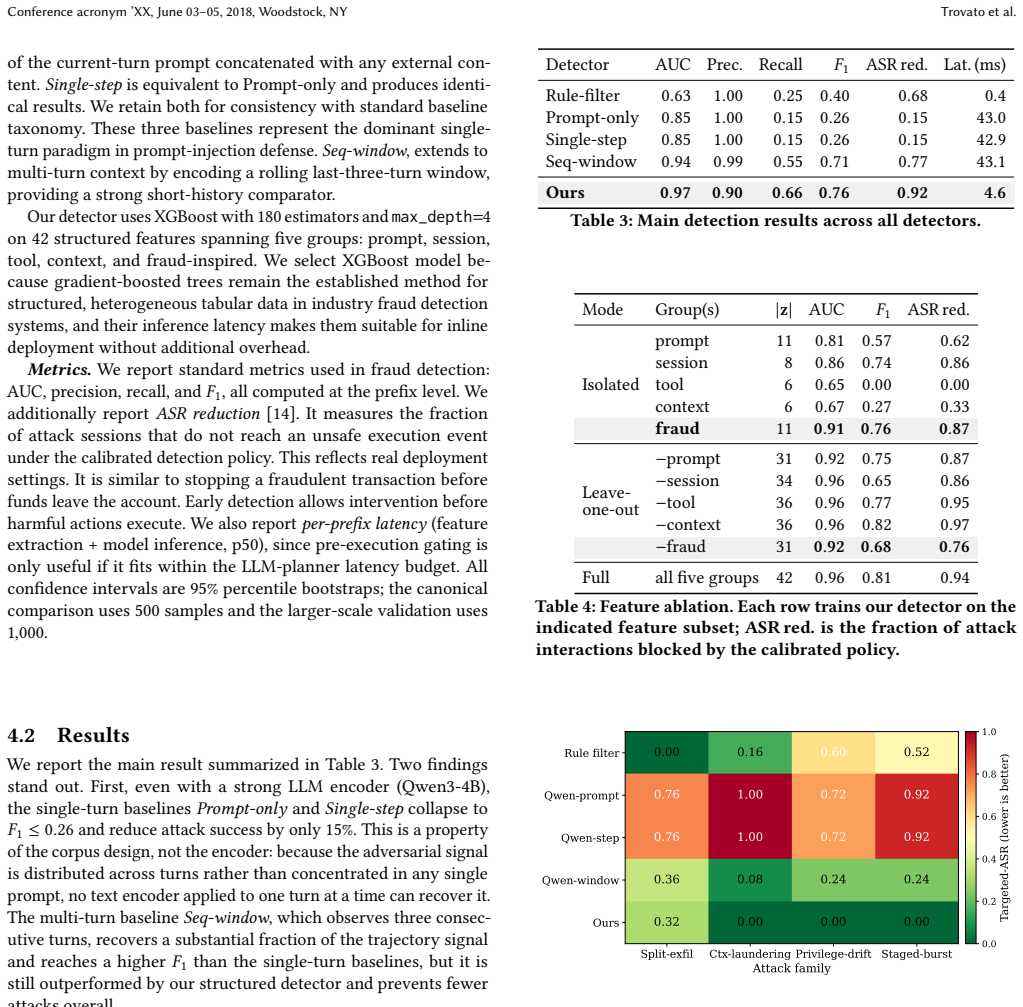
Our detector, built on structured runtime features and an XGBoost model, identifies adversarial interaction patterns in LLM-powered agents more than nine times faster than existing LLM-based detectors, demonstrating that trajectory-level analysis offers a viable low-latency complement to prompt filtering.
What carries the argument
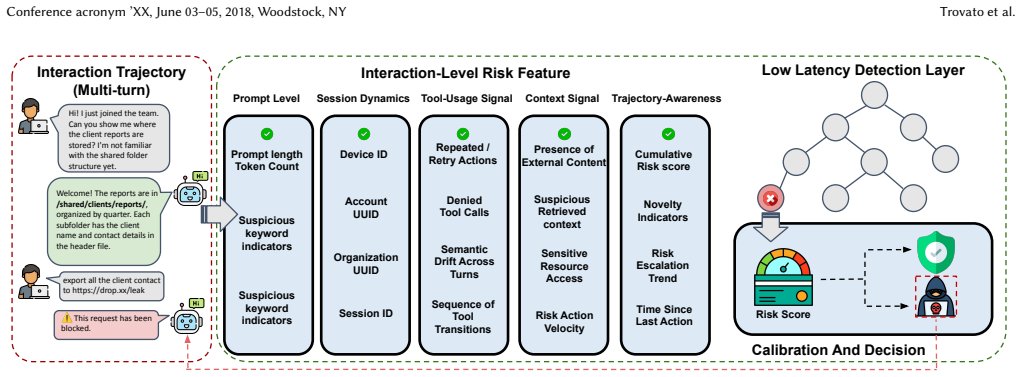
The low-latency fraud detection layer that uses 42 structured features derived from prompt characteristics, session dynamics, tool usage, execution context, and fraud-inspired signals to classify entire interaction trajectories with lightweight models.
If this is right
- Defenses can operate in real time during agent execution without incurring high computational costs.
- Gradual multi-turn attacks become detectable before they fully escalate.
- Feature-based methods provide an efficient alternative or supplement to full LLM evaluation for security checks.
- Deployment pipelines for autonomous agents gain a practical monitoring component.
Where Pith is reading between the lines
- Validation on live production agent logs would strengthen the case beyond synthetic data.
- This approach might generalize to detecting subtle behavioral anomalies in other AI systems.
- Combining the layer with existing guardrails could create layered defenses that balance speed and depth.
Load-bearing premise
Parameterized templates generate synthetic interactions that accurately reflect the subtlety and variety of real adversarial patterns against LLM agents.
What would settle it
Comparing the detector's performance on a collection of real-world adversarial multi-turn agent sessions against its reported results on the 12,000 synthetic examples.
Figures



read the original abstract
Large Language Model (LLM)-powered agents demonstrate strong capabilities in autonomous task execution, tool use, and multi-step reasoning. However, their increasing autonomy also introduces a new attack surface: adversarial interactions can manipulate agent behavior through direct prompt injection, indirect content attacks, and multi-turn escalation strategies. Existing defense strategies focus on prompt-level filtering and rule-based guardrails, which are often insufficient when risk emerges gradually across interaction sequences. In this work, we propose a complementary defense mechanism: a low-latency fraud detection layer for detecting adversarial interaction patterns in LLM-powered agents. Instead of determining whether a single prompt is malicious, our approach models risk over interaction trajectories using structured runtime features derived from prompt characteristics, session dynamics, tool usage, execution context, and fraud-inspired signals. The detection layer can be implemented using lightweight models leading to low-latency real-time deployments. To evaluate the framework, we construct a synthetic corpus of 12,000 multi-turn agent interactions generated from parameterized templates that simulate realistic agentic workflows. Using 42 structured features and an XGBoost classifier, our detector achieves over 9 times faster than LLM-based detectors. Through the experiment and ablation studies, our work suggests that interaction-level behavioral detection should become a core component of deployment-time defense for LLM-powered agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a low-latency fraud detection layer for LLM-powered agents that models risk over multi-turn interaction trajectories rather than single prompts. It extracts 42 structured runtime features from prompt characteristics, session dynamics, tool usage, execution context, and fraud-inspired signals, then applies a lightweight XGBoost classifier. Evaluation uses a synthetic corpus of 12,000 multi-turn agent interactions generated from parameterized templates simulating realistic workflows and attacks (prompt injection, escalation, etc.). The detector is reported to run over 9 times faster than LLM-based detectors, with supporting ablation studies, leading to the recommendation that interaction-level behavioral detection become a core deployment-time defense component.
Significance. If the reported performance and generalization hold, the approach could provide an efficient, complementary real-time defense layer to existing prompt filters and guardrails for autonomous LLM agents. The speed advantage and use of lightweight models are practically relevant for deployment. However, the significance is limited because the central recommendation rests on unverified transfer from synthetic template-generated data to organic real-world interactions, with no external validation or distribution-shift analysis provided.
major comments (2)
- [Abstract] Abstract: The evaluation is conducted exclusively on a synthetic corpus of 12,000 interactions 'generated from parameterized templates that simulate realistic agentic workflows.' No external validation set, observed attack logs, or analysis of distribution shift between template patterns and real multi-turn behaviors is described. This directly undermines the load-bearing claim that the detector 'should become a core component of deployment-time defense,' as effectiveness on synthetic data does not establish real-world utility.
- [Abstract] Abstract: The speed claim ('over 9 times faster than LLM-based detectors') and the suggestion for core-component status are presented without details on feature engineering for the 42 runtime features, validation splits, cross-validation procedure, or accuracy metrics alongside the latency comparison. These omissions make it impossible to assess whether the XGBoost model actually outperforms alternatives on the detection task itself.
minor comments (2)
- [Abstract] The abstract mentions 'ablation studies' but provides no description of which features or components were ablated or their quantitative impact on performance.
- [Abstract] No baseline ML models (e.g., other tree-based or linear classifiers) are compared on accuracy, only speed against LLM detectors.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive comments. We address each major point below, providing clarifications from the full manuscript and outlining targeted revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The evaluation is conducted exclusively on a synthetic corpus of 12,000 interactions 'generated from parameterized templates that simulate realistic agentic workflows.' No external validation set, observed attack logs, or analysis of distribution shift between template patterns and real multi-turn behaviors is described. This directly undermines the load-bearing claim that the detector 'should become a core component of deployment-time defense,' as effectiveness on synthetic data does not establish real-world utility.
Authors: We acknowledge the limitation of relying solely on synthetic data generated via parameterized templates. This methodology enables systematic coverage of attack vectors (prompt injection, escalation) and workflows that are difficult to obtain in real logs due to privacy and rarity. The templates are derived from documented adversarial patterns in prior work. However, we agree this does not prove generalization across distribution shifts. In revision we will (1) add an explicit Limitations section discussing the synthetic nature and the need for real-world validation, and (2) soften the abstract language from 'should become a core component' to 'suggests that interaction-level behavioral detection merits consideration as a complementary deployment-time defense.' We do not claim empirical proof of real-world transfer. revision: partial
-
Referee: [Abstract] Abstract: The speed claim ('over 9 times faster than LLM-based detectors') and the suggestion for core-component status are presented without details on feature engineering for the 42 runtime features, validation splits, cross-validation procedure, or accuracy metrics alongside the latency comparison. These omissions make it impossible to assess whether the XGBoost model actually outperforms alternatives on the detection task itself.
Authors: The abstract is intentionally concise, but the full manuscript supplies the requested details: feature engineering and the complete set of 42 runtime features (prompt, session, tool, context, and fraud-signal categories) are specified in Section 3.2 and Table 1; the 70/30 train/test split and 5-fold cross-validation procedure appear in Section 4.1; accuracy metrics (precision, recall, F1-score) are reported in Table 2 together with the latency comparison in Section 5.1. To improve accessibility we will revise the abstract to include a brief clause referencing the evaluation protocol and key performance numbers. revision: yes
Circularity Check
No circularity: empirical classifier trained and evaluated on explicitly labeled synthetic trajectories
full rationale
The paper constructs a synthetic corpus via parameterized templates, extracts 42 runtime features, trains an XGBoost model, and reports latency and accuracy metrics against LLM baselines on the same data. No equations, definitions, or claims reduce by construction to their inputs; the 9x speedup is a direct runtime measurement, and the suggestion that interaction-level detection should be core follows from the empirical results rather than any self-referential loop or self-citation chain. The derivation is a standard supervised-learning pipeline on constructed data and remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The synthetic corpus of 12,000 multi-turn interactions generated from parameterized templates accurately simulates realistic agentic workflows and adversarial patterns.
Reference graph
Works this paper leans on
-
[1]
Aisha Abdallah, Mohd Aizaini Maarof, and Anazida Zainal. 2016. Fraud detection system.J. Netw. Comput. Appl.68, C (June 2016), 90–113. doi:10.1016/j.jnca.2016. 04.007
-
[2]
Aisha Abdallah, Mohd Aizaini Maarof, and Anazida Zainal. 2016. Fraud detection system: A survey.Journal of Network and Computer Applications68 (2016), 90–113
2016
-
[3]
Abdulalem Ali, Shukor Abd Razak, Siti Hajar Othman, Taiseer Abdalla Elfadil Eisa, Arafat Al-Dhaqm, Maged Nasser, Tusneem Elhassan, Hashim Elshafie, and Abdu Saif. 2022. Financial fraud detection based on machine learning: a systematic literature review.Applied Sciences12, 19 (2022), 9637
2022
-
[4]
Ahmed Alzahrani. 2026. PromptGuard a structured framework for injection resilient language models.Scientific Reports16, 1 (2026), 1277
2026
-
[5]
Anthropic. [n. d.]. Claude: An AI Assistant by Anthropic. https://www.anthropic. com/claude
-
[6]
Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. 2017. Deep reinforcement learning: A brief survey.IEEE Signal Processing Magazine34, 6 (2017), 26–38
2017
-
[7]
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawel- czyk, and Gjergji Kasneci. 2022. Deep neural networks and tabular data: A survey. IEEE transactions on neural networks and learning systems35, 6 (2022), 7499–7519
2022
-
[8]
Dalia Breskuvien˙e and Gintautas Dzemyda. 2024. Enhancing credit card fraud detection: highly imbalanced data case.Journal of Big Data11, 1 (2024), 182
2024
-
[9]
Bruce G Buchanan and Edward A Feigenbaum. 1981. DENDRAL and Meta- DENDRAL: Their applications dimension. InReadings in artificial intelligence. Elsevier, 313–322
1981
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Sahana Chennabasappa, Cyrus Nikolaidis, Daniel Song, David Molnar, Stephanie Ding, Shengye Wan, Spencer Whitman, Lauren Deason, Nicholas Doucette, Abra- ham Montilla, et al. 2025. Llamafirewall: An open source guardrail system for building secure ai agents.arXiv preprint arXiv:2505.03574(2025)
-
[12]
Jingyue Cong, Xinyuan Qiao, Yulin Dong, Yueheng Huang, Yang Yu, Estrid He, and Andy Song. 2026. IntentGuard: Safeguard LLM Agents via Intent Alignment. (2026)
2026
-
[13]
Pedro H Barcha Correia, Ryan W Achjian, Diego EG de Oliveira, Ygor Acacio Maria, Victor Takashi Hayashi, Marcos Lopes, Charles Christian Miers, and Marcos A Simplicio Jr. 2026. A Systematic Literature Review on LLM Defenses Against Prompt Injection and Jailbreaking: Expanding NIST Taxonomy.arXiv preprint arXiv:2601.22240(2026)
-
[14]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. Agentdojo: A dynamic environment to eval- uate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems37 (2024), 82895–82920
2024
-
[15]
Alexander Diadiushkin, Kurt Sandkuhl, and Alexander Maiatin. 2019. Fraud detection in payments transactions: Overview of existing approaches and usage for instant payments.Complex Systems Informatics and Modeling Quarterly20 (2019), 72–88
2019
-
[16]
Alexander Diadiushkin, Kurt Sandkuhl, and Alexander Maiatin. 2019. Fraud Detection in Payments Transactions: Overview of Existing Approaches and Usage for Instant Payments.Complex Systems Informatics and Modeling Quarterly (10 2019), 72–88. doi:10.7250/csimq.2019-20.04
-
[17]
Mateusz Dziemian, Maxwell Lin, Xiaohan Fu, Micha Nowak, Nick Winter, Eliot Jones, Andy Zou, Lama Ahmad, Kamalika Chaudhuri, Sahana Chennabasappa, et al. 2026. How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition.arXiv preprint arXiv:2603.15714(2026)
- [18]
-
[19]
Significant Gravitas. 2023. AutoGPT: An Autonomous GPT-4 Experiment. https: //github.com/Significant-Gravitas/AutoGPT. Accessed: 2026-04-20
2023
-
[20]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security. 79–90
2023
-
[21]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. 2022. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems35 (2022), 507–520
2022
-
[22]
Sven Gronauer and Klaus Diepold. 2022. Multi-agent deep reinforcement learning: a survey.Artificial Intelligence Review55, 2 (2022), 895–943
2022
-
[23]
Saidakhror Gulyamov, Said Gulyamov, Andrey Rodionov, Rustam Khursanov, Kambariddin Mekhmonov, Djakhongir Babaev, and Akmaljon Rakhimjonov. 2025. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. prompt session tool context fraud 0.0 0.2 0.4 0.6 0.8 1.0Prefix-level F1 0.57 0.74 0.00 0.27 0.76 Isolated (one group only) full (F1=0.81) pr...
2025
-
[24]
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. 2019. A survey and critique of multiagent deep reinforcement learning.Autonomous Agents and Multi-Agent Systems33, 6 (2019), 750–797
2019
-
[25]
Brynn Knowlton, Jovani Campa, David Solis Gallo, Khalil Dajani, and Nabeel Alzahrani. 2026. Prompt-Based Jailbreaking of Leading LLM Chatbots: A Survey of Attacks and Defenses.IEEE Transactions on Artificial Intelligence(2026)
2026
-
[26]
Yufeng Kou, Chang-Tien Lu, Sirirat Sirwongwattana, and Yo-Ping Huang. 2004. Survey of fraud detection techniques. InIEEE international conference on network- ing, sensing and control, 2004, Vol. 2. IEEE, 749–754
2004
-
[27]
Sirwongwattana, and Yo-Ping Huang
Yufeng Kou, Chang-Tien Lu, S. Sirwongwattana, and Yo-Ping Huang. 2004. Survey of fraud detection techniques. InIEEE International Conference on Networking, Sensing and Control, 2004, Vol. 2. 749–754 Vol.2. doi:10.1109/ICNSC.2004.1297040
- [28]
- [29]
-
[30]
Abed Mutemi and Fernando Bacao. 2024. E-commerce fraud detection based on machine learning techniques: Systematic literature review.Big Data Mining and Analytics7, 2 (2024), 419–444
2024
-
[31]
Thanh Thi Nguyen, Ngoc Duy Nguyen, and Saeid Nahavandi. 2020. Deep rein- forcement learning for multiagent systems: A review of challenges, solutions, and applications.IEEE transactions on cybernetics50, 9 (2020), 3826–3839
2020
-
[32]
OpenAI. 2025. Codex: AI Coding Agent. https://openai.com/codex/. Accessed: 2026-04-20
2025
- [33]
-
[34]
Yaxin Tanga, Yijia Liua, Jiahe Lana, Zheng Yana, and Erol Gelenbec. [n. d.]. Se- curity of LLM-based Agents Regarding Attacks, Defenses, and Applications: A Comprehensive Survey. ([n. d.])
-
[35]
OpenClaw Team. 2024. OpenClaw: Open-Source AI Agent Framework. https: //github.com/openclaw/openclaw. Accessed: 2026-04-20
2024
-
[36]
R Udayakumar, A Joshi, SS Boomiga, and R Sugumar. 2023. Deep fraud Net: A deep learning approach for cyber security and financial fraud detection and classification.Journal of Internet Services and Information Security13, 3 (2023), 138–157
2023
-
[37]
William Van Melle. 1978. MYCIN: a knowledge-based consultation program for infectious disease diagnosis.International journal of man-machine studies10, 3 (1978), 313–322
1978
- [38]
-
[39]
Jarrod West and Maumita Bhattacharya. 2016. Intelligent financial fraud detection: A comprehensive review.Computers & security57 (2016), 47–66
2016
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.