Recognition: unknown
Multimodal Data Curation Through Ranked Retrieval
Pith reviewed 2026-05-09 17:56 UTC · model grok-4.3
The pith
A framework of symmetric pair trimming and bias-reduced expert blending collapses the modality gap in multimodal embeddings by over 90 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Symmetric Nucleus Subsampling refines raw training pairs by retaining only the portions of inputs and annotations that best support each other, while the Expert Embedding Engine combines base embedding experts with a learned projection and a bias-aware loss that reduces separation by input modality. Together these operations produce a shared space in which modality accounts for far less of the observed variance, and the curated subsets yield higher-performing models on downstream tasks than those obtained from unrefined or randomly sampled data.
What carries the argument
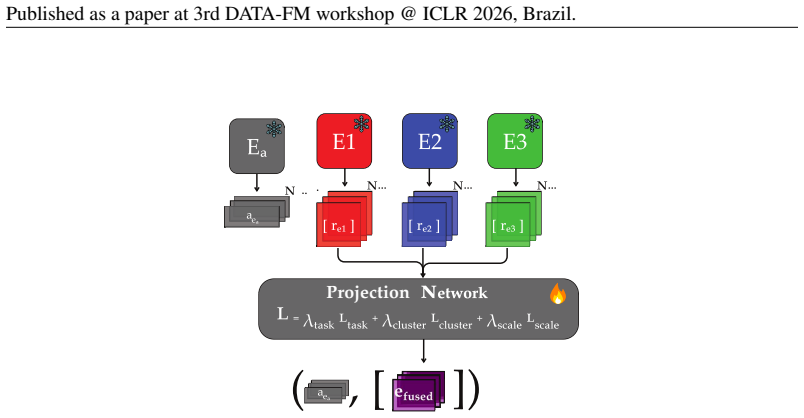
Symmetric Nucleus Subsampling (SNS), which trims pairs to mutually supportive subsets, and Expert Embedding Engine (EEE), which fuses experts via a projection network under a bias-aware objective that penalizes modality separation.
If this is right
- Cross-modal retrieval precision rises because examples cluster by meaning rather than by input type.
- Data curation becomes more reliable: the selected blends outperform both random and stratified baselines on the same downstream tasks.
- The combined pipeline can be applied to any collection of heterogeneous paired datasets without requiring new human labels.
- Embedding quality improves without sacrificing coverage of the original data distribution.
Where Pith is reading between the lines
- The same trimming-plus-bias-reduction pattern could be tested on video-text or audio-text pairs where modality gaps are known to be larger.
- If the bias-aware objective generalizes, it may reduce the need for modality-specific fine-tuning when adding new data sources.
- The approach suggests that curation quality can be improved at the pair level rather than only at the model level, which would change how large multimodal corpora are assembled.
Load-bearing premise
Trimming pairs to their mutually supportive portions preserves all semantically important information without introducing new selection bias.
What would settle it
A controlled experiment in which the downstream model trained on SNS-plus-EEE curated data shows no accuracy gain, or the measured modality gap remains above 10 percent of its baseline value, over multiple random seeds and dataset blends.
Figures






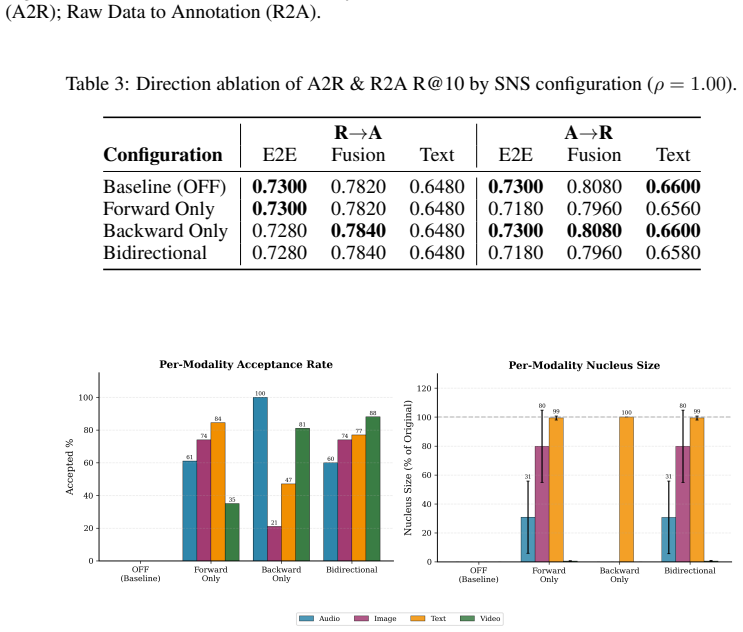















read the original abstract
Shared embedding spaces are widely used for multimodal search and data curation. In practice, two problems often limit how well this works. First, embeddings can reflect modality more than meaning, so examples cluster by input type even when the underlying content matches. Second, the paired supervision used to train these spaces is often noisy. When we blend many heterogeneous, human-labeled datasets, these issues reinforce each other and degrade cross-modal retrieval. We present a framework that improves alignment by acting on both the training pairs and the embedding model. Symmetric Nucleus Subsampling (SNS) refines training pairs by trimming raw inputs and annotations to the portions that best support each other. Expert Embedding Engine (EEE) combines complementary embedding experts using a learned projection network, together with a bias-aware objective that reduces modality-driven separation in the embedding space. We demonstrate that this approach collapses the modality gap by over 90% on average vs base embedding experts and is a strong data curator, with datablends from our method outperforming stratified sampling and traditional curation baselines in downstream model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Symmetric Nucleus Subsampling (SNS) to refine noisy multimodal training pairs by retaining only mutually supportive portions of inputs and annotations, together with an Expert Embedding Engine (EEE) that fuses complementary embedding experts via a learned projection network and a bias-aware objective to reduce modality-driven clustering in the shared space. It claims the combined approach collapses the modality gap by over 90% versus base experts on average and yields superior data blends for downstream model performance compared with stratified sampling and traditional curation baselines.
Significance. If the empirical claims are substantiated, the work would offer a practical dual intervention on both data and model for multimodal retrieval and curation, directly targeting the common problems of modality bias and noisy supervision. The framework's emphasis on ranked retrieval for curation is a timely contribution in cs.IR, but its significance hinges on whether the reported gains are robust rather than dataset- or metric-specific.
major comments (3)
- [Abstract] Abstract: the central claim of a >90% modality-gap collapse versus base embedding experts is presented without any definition of the gap metric, the datasets used, the number of runs, or statistical significance testing; this absence makes the headline quantitative result impossible to evaluate or reproduce from the given information.
- [Methods] Methods (SNS description): the assumption that trimming pairs to 'mutually supportive' portions via Symmetric Nucleus Subsampling preserves all semantically critical content is load-bearing for the curation claim, yet no diagnostic (e.g., semantic similarity retention on held-out tasks) or ablation against random subsampling of identical cardinality is supplied.
- [Experiments] Experiments (EEE objective): the bias-aware term in the Expert Embedding Engine is asserted to reduce modality separation without harming overall embedding quality, but the manuscript provides no isolation experiment separating its effect from the projection network or from the SNS preprocessing, nor any check for introduced spurious correlations on non-alignment tasks.
minor comments (2)
- [Abstract] Abstract: the term 'datablends' is used without definition or construction details, and 'traditional curation baselines' are referenced without naming the specific methods or citations.
- [Abstract] Notation: the acronyms SNS and EEE are introduced without accompanying equations or pseudocode in the abstract, forcing the reader to infer their precise formulations from prose alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight opportunities to strengthen the clarity and experimental validation of our work. We address each major comment below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a >90% modality-gap collapse versus base embedding experts is presented without any definition of the gap metric, the datasets used, the number of runs, or statistical significance testing; this absence makes the headline quantitative result impossible to evaluate or reproduce from the given information.
Authors: We agree that the abstract should provide a concise definition of the modality gap and supporting evaluation details for immediate interpretability. In the manuscript body (Section 3.2), the modality gap is defined as the average difference between intra-modality and cross-modality pairwise cosine distances in the shared embedding space. The >90% collapse is the relative reduction in this gap achieved by the full EEE versus base experts, computed as the mean across the datasets in Section 4.1 over 5 independent runs (with standard deviations reported in the main results). We will revise the abstract to include a brief definition of the metric, reference to the datasets, and note on the multi-run evaluation protocol. revision: yes
-
Referee: [Methods] Methods (SNS description): the assumption that trimming pairs to 'mutually supportive' portions via Symmetric Nucleus Subsampling preserves all semantically critical content is load-bearing for the curation claim, yet no diagnostic (e.g., semantic similarity retention on held-out tasks) or ablation against random subsampling of identical cardinality is supplied.
Authors: SNS ranks and retains the nucleus of each pair according to cross-modal support scores from the embedding experts, which is intended to prioritize content that is mutually reinforcing rather than discarding critical semantics. We acknowledge that an explicit validation of this assumption would strengthen the curation claims. We will add a diagnostic measuring semantic similarity retention via a held-out cross-modal retrieval task (comparing pre- and post-SNS pairs) as well as an ablation against random subsampling of identical cardinality, with results on downstream curation performance. These will appear in the revised Experiments section. revision: yes
-
Referee: [Experiments] Experiments (EEE objective): the bias-aware term in the Expert Embedding Engine is asserted to reduce modality separation without harming overall embedding quality, but the manuscript provides no isolation experiment separating its effect from the projection network or from the SNS preprocessing, nor any check for introduced spurious correlations on non-alignment tasks.
Authors: The current experiments evaluate the combined EEE (projection network plus bias-aware objective) against baselines, but do not isolate the bias-aware term from the projection network or from SNS preprocessing. We will add ablation variants that train the model with and without the bias-aware term (both with and without SNS), reporting effects on modality gap reduction and overall retrieval metrics. We will further evaluate the embeddings on non-alignment tasks such as unimodal classification to check for introduced spurious correlations. These results will be included in the revised Experiments section. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SNS for refining training pairs via mutual support trimming and EEE for combining embedding experts with a bias-aware objective to reduce modality separation. These are presented as independent algorithmic interventions whose effects on modality gap and downstream curation performance are then measured empirically against base experts and baselines. No equations, derivations, or self-citations are invoked that reduce the claimed >90% gap collapse or outperformance to quantities defined by the methods themselves or fitted parameters by construction. The results remain falsifiable via external benchmarks and do not rely on load-bearing self-references or ansatzes smuggled through citations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Paired multimodal examples contain identifiable portions that mutually support each other across modalities
- domain assumption Existing embedding experts can be aligned by a learned projection while penalizing modality-driven separation
invented entities (2)
-
Symmetric Nucleus Subsampling (SNS)
no independent evidence
-
Expert Embedding Engine (EEE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bengio, Yoshua and LeCun, Yann , booktitle =
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =
-
[3]
2025 , doi =
Zha, Daochen and Bhat, Zaid Pervaiz and Lai, Kwei-Herng and Yang, Fan and Jiang, Zhimeng and Zhong, Shaochen and Hu, Xia , journal =. 2025 , doi =
2025
-
[4]
Long, Lin and Wang, Rui and Xiao, Ruixuan and Zhao, Junbo and Ding, Xiao and Chen, Gang and Wang, Haobo , journal=
-
[5]
2016 , publisher=
Goodfellow, Ian and Bengio, Yoshua and Courville, Aaron and Bengio, Yoshua , volume=. 2016 , publisher=
2016
-
[6]
GitHub repository , howpublished =
Jennings, Joseph and Patwary, Mostofa and Subramanian, Sandeep and Prabhumoye, Shrimai and Dattagupta, Ayush and Jawa, Vibhu and Liu, Jiwei and Wolf, Ryan and Yurick, Sarah and Singh, Varun and Chang, Dong Hyuk and Tang, Ao and Lane, Lawrence and Truong, Charlie and Vu, Huy and Garg, Abhinav and Mahajan, Praateek and Karpov, Nikolay and K. GitHub reposito...
2024
-
[7]
2025 , publisher =
NVIDIA , title =. 2025 , publisher =
2025
-
[8]
Kim, Chris Dongjoo and Kim, Byeongchang and Lee, Hyunmin and Kim, Gunhee , booktitle =
-
[9]
Sidorov, Oleksii and Hu, Ronghang and Rohrbach, Marcus and Singh, Amanpreet , booktitle =
-
[10]
Shridhar, Mohit and Thomason, Jesse and Gordon, Daniel and Bisk, Yonatan and Han, Winson and Mottaghi, Roozbeh and Zettlemoyer, Luke and Fox, Dieter , booktitle =
-
[11]
Xu, Jin and Yan, Zhifang and Liu, Zitian and Zhang, Yihao and Zhu, Chunfeng and Ye, Junyang and Song, Jianwei and Lu, Jiaxi and Yang, Sicheng and Yan, Shuai and others , journal =
-
[12]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[13]
Yin, Pengcheng and Deng, Bowen and Chen, Edgar and Vasilescu, Bogdan and Neubig, Graham , booktitle =
-
[14]
and Zettlemoyer, Luke , booktitle =
Joshi, Mandar and Choi, Eunsol and Weld, Daniel S. and Zettlemoyer, Luke , booktitle =
-
[15]
Omni-embed-nemotron: A unified multimodal retrieval model for text, image, audio, and video, 2025
Mengyao Xu and Wenfei Zhou and Yauhen Babakhin and Gabriel Moreira and Ronay Ak and Radek Osmulski and Bo Liu and Even Oldridge and Benedikt Schifferer , year=. 2510.03458 , archivePrefix=
-
[16]
2019 , organization=
Poole, Ben and Ozair, Sherjil and Van Den Oord, Aaron and Alemi, Alex and Tucker, George , booktitle=. 2019 , organization=
2019
-
[17]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Qing Jiang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang , year=. 2303.05499 , archivePrefix=
work page internal anchor Pith review arXiv
-
[18]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord and Yazhe Li and Oriol Vinyals , year=. 1807.03748 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
NVIDIA and : and Amala Sanjay Deshmukh and Kateryna Chumachenko and Tuomas Rintamaki and Matthieu Le and Tyler Poon and Danial Mohseni Taheri and Ilia Karmanov and Guilin Liu and Jarno Seppanen and Guo Chen and Karan Sapra and Zhiding Yu and Adi Renduchintala and Charles Wang and Peter Jin and Arushi Goel and Mike Ranzinger and Lukas Voegtle and Philipp F...
-
[20]
2021 , organization=
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others , booktitle=. 2021 , organization=
2021
-
[21]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin and Atabak Ashfaq and Adam Atkinson and others , year=. 2503.01743 , archivePrefix=
work page internal anchor Pith review arXiv
-
[22]
2021 , url =
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya , booktitle =. 2021 , url =
2021
-
[23]
2022 , url =
Elizalde, Benjamin and Deshmukh, Soham and Al Ismail, Mahmoud and Wang, Huaming , journal =. 2022 , url =
2022
-
[24]
2023 , url =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , journal =. 2023 , url =
2023
-
[25]
2024 , url =
Tao, Chongyang and Shen, Tao and Gao, Shen and Zhang, Junshuo and Li, Zhen and Tao, Zhengwei and Ma, Shuai , journal =. 2024 , url =
2024
-
[26]
arXiv preprint arXiv:2412.00591 , year =
Lanzend. arXiv preprint arXiv:2412.00591 , year =
-
[27]
arXiv preprint arXiv:2408.04072 , year =
Gr. arXiv preprint arXiv:2408.04072 , year =
-
[28]
arXiv preprint arXiv:2409.16793 , year =
Heine, Lukas and H. arXiv preprint arXiv:2409.16793 , year =
-
[29]
Liang, Victor Weixin and Zhang, Yuhui and Kwon, Yongchan and Yeung, Serena and Zou, James Y , journal=
-
[30]
and Hinton, Geoffrey E
Shazeer, Noam and Mirhoseini, Azalia and Maziarz, Krzysztof and Davis, Andy and Le, Quoc V. and Hinton, Geoffrey E. and Dean, Jeff , booktitle =. 2017 , url =
2017
-
[31]
2022 , url =
Zhou, Yanqi and Lei, Tao and Liu, Hanxiao and Du, Nan and Huang, Yanping and Zhao, Vincent and Dai, Andrew and Chen, Zhifeng and Le, Quoc and Laudon, James , booktitle =. 2022 , url =
2022
-
[32]
2022 , url =
Clark, Aidan and de las Casas, Diego and Guy, Aurelia and Mensch, Arthur and Paganini, Michela and Hoffmann, Jordan and Damoc, Bogdan and Hechtman, Blake and Cai, Trevor and Borgeaud, Sebastian and van den Driessche, George and Rutherford, Eliza and Hennigan, Tom and Johnson, Matthew and Millican, Katie and Cassirer, Albin and Jones, Chris and Buchatskaya...
2022
-
[33]
2024 , url =
Cai, Weilin and Jiang, Juyong and Wang, Fan and Tang, Jing and Kim, Sunghun and Huang, Jiayi , journal =. 2024 , url =
2024
-
[34]
2024 , url =
Raposo, David and Ritter, Samuel and Richards, Brandon and Lillicrap, Timothy and Humphreys, Peter and Santoro, Adam , journal =. 2024 , url =
2024
-
[35]
, booktitle =
Wang, Xin and Yu, Fisher and Dou, Zi-Yi and Darrell, Trevor and Gonzalez, Joseph E. , booktitle =. 2018 , url =
2018
-
[36]
2019 , url =
Chen, Zhourong and Li, Yang and Bengio, Samy and Si, Si , booktitle =. 2019 , url =
2019
-
[37]
and Shrestha, Manil and Xu, Kaidi and Kim, Edward and Stamm, Matthew C
Azizpour, Aref and Nguyen, Tai D. and Shrestha, Manil and Xu, Kaidi and Kim, Edward and Stamm, Matthew C. , booktitle =. 2024 , url =
2024
-
[38]
and Dinu, Georgiana and Karypis, George , booktitle =
Romero Calvo, Miguel and Ding, Shuoyang and Barrett, Corey D. and Dinu, Georgiana and Karypis, George , booktitle =. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.1168 , url =
-
[39]
and Khomtchouk, Bohdan , journal =
Hallee, Logan and Kapur, Rohan and Patel, Arjun and Gleghorn, Jason P. and Khomtchouk, Bohdan , journal =. 2024 , url =
2024
-
[40]
2019 , url =
Carter, Brandon and Mueller, Jonas and Jain, Siddhartha and Gifford, David , booktitle =. 2019 , url =
2019
-
[41]
2023 , url =
Gadre, Samir Yitzhak and others , booktitle =. 2023 , url =
2023
-
[42]
2025 , doi =
Leopold, Mario and Tashtarian, Farzad and Schoeffmann, Klaus , booktitle =. 2025 , doi =
2025
-
[43]
2025 , url =
Epperson, Will and Mathur, Arpit and Perer, Adam and Moritz, Dominik , journal =. 2025 , url =
2025
-
[44]
2023 , url =
Radenovic, Filip and Dubey, Abhimanyu and Kadian, Abhishek and Mihaylov, Todor and Vandenhende, Simon and Patel, Yash and Wen, Yi and Ramanathan, Vignesh and Mahajan, Dhruv , booktitle =. 2023 , url =
2023
-
[45]
Moreira, Gabriel de Souza P and Osmulski, Radek and Xu, Mengyao and Ak, Ronay and Schifferer, Benedikt and Oldridge, Even , journal=
-
[46]
Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan , booktitle=
-
[47]
2025 , organization=
Munakata, Hokuto and Nishimura, Taichi and Nakada, Shota and Komatsu, Tatsuya , booktitle=. 2025 , organization=
2025
-
[48]
Moon, WonJun and Hyun, Sangeek and Lee, SuBeen and Heo, Jae-Pil , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.