Recognition: unknown
Quantifying and Predicting Disagreement in Graded Human Ratings
Pith reviewed 2026-05-09 18:33 UTC · model grok-4.3
The pith
Textual features allow moderate prediction of disagreement levels in human ratings of offensive and toxic language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Annotation variance in graded ratings of offensive, hate, and toxic language can be quantified by the Opposition Index and predicted from textual features, yielding a moderate positive correlation with observed variance; direct variance regression and distribution-based estimation achieve comparable accuracy, while high-opposition items remain more difficult to predict and are frequently underestimated.
What carries the argument
The Opposition Index, a metric that quantifies the degree of perspective opposition among annotators on a single rated item.
If this is right
- Direct prediction of variance and estimation from predicted rating distributions produce comparable accuracy.
- Items with high Opposition Index values are harder for models to predict correctly.
- Models tend to underestimate disagreement on high-opposition items.
- Textual features alone capture a detectable portion of annotation variation in these tasks.
Where Pith is reading between the lines
- Flagging high-opposition items during dataset creation could reduce label noise in downstream training.
- Incorporating annotator background information might further improve variance estimates beyond text-only models.
- The approach could extend to other subjective tasks such as sentiment or toxicity detection in different languages.
Load-bearing premise
Disagreement among raters is driven mainly by properties of the text itself rather than by who the annotators are or by details of the rating guidelines.
What would settle it
A new dataset of graded ratings on similar language items where the correlation between text-based predictions and actual observed variance is near zero or negative.
Figures

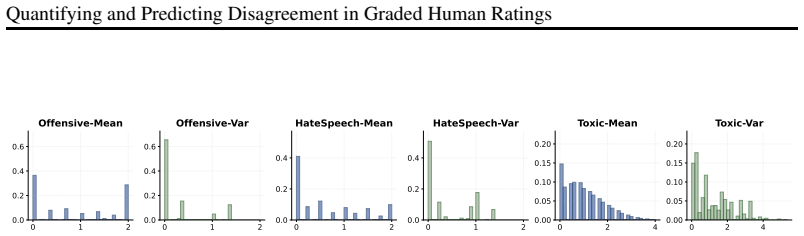
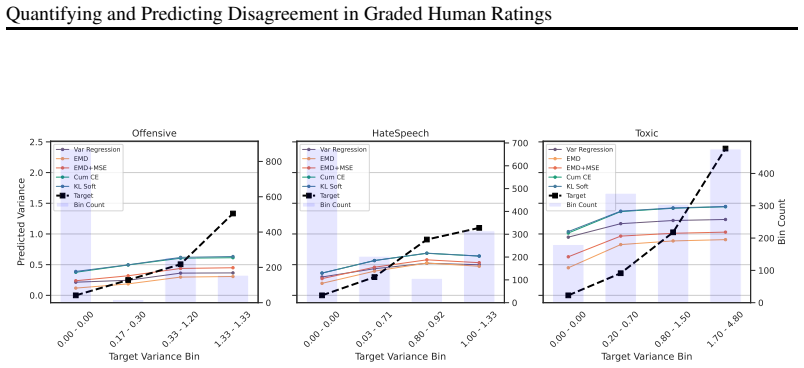

read the original abstract
It is increasingly recognized that human annotators do not always agree, and such disagreement is inherent in many annotation tasks. However, not all instances in a given task elicit the same degree of opinion divergence. In this paper, we investigate annotation variation patterns in graded human ratings for inappropriate languages, including offensive language, hate speech, and toxic language perception. We examine whether the degree of annotation disagreement can be predicted from textual features. We further propose the Opposition Index, a metric that quantifies perspective opposition among annotators on a given item, and investigate the predictability of instances with potentially opposing human opinions. Our results show a moderate positive correlation between estimated and observed annotation variance. We find that two approaches achieve comparable performance in variance prediction: directly predicting the variance value and estimating it from predicted annotation distributions. Our results on opposition perspective prediction show that items with high opposition index values are more difficult to predict and are often underestimated by models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates annotation disagreement patterns in graded human ratings for inappropriate language tasks (offensive language, hate speech, toxic language perception). It proposes the Opposition Index as a metric for quantifying perspective opposition among annotators on individual items and tests whether textual features alone can predict annotation variance (via direct regression or by estimating from predicted distributions) as well as identify high-opposition items. The central empirical claims are a moderate positive correlation between estimated and observed variance, comparable performance of the two variance-prediction approaches, and greater difficulty (with underestimation) in predicting high-opposition-index items.
Significance. If the reported correlations and comparative results hold under proper statistical controls and baselines, the work offers a practical contribution to handling inherent disagreement in subjective NLP annotation tasks. The Opposition Index provides a concrete, quantifiable way to flag contentious items that may require special handling in dataset curation or model evaluation. This aligns with growing interest in moving beyond single gold labels toward modeling annotator variation directly from text.
major comments (2)
- [§4] §4 (Experimental Setup): the paper reports a moderate positive correlation and comparable performance of the two variance-prediction methods but supplies no numerical coefficient, p-value, confidence intervals, or comparison against a simple baseline (e.g., mean-variance predictor or lexical-only features). Without these, the central claim that textual features suffice for variance prediction cannot be properly evaluated.
- [§5.2] §5.2 (Opposition Index results): the finding that high-opposition items are more difficult to predict and often underestimated is load-bearing for the utility of the proposed metric, yet the section does not report the exact model architecture, feature set, or error analysis (e.g., which textual cues are missed). This leaves open whether the difficulty stems from the index itself or from limitations in the text-only modeling assumption.
minor comments (3)
- [Abstract] Abstract: the phrase 'moderate positive correlation' should be replaced by the actual Pearson or Spearman value and its significance level for precision.
- [§3] Notation: the definition of the Opposition Index should be given as an explicit formula (with variables for rating values and annotator counts) rather than described only in prose.
- [§2] Related Work: a brief comparison to existing disagreement metrics (e.g., entropy-based or Krippendorff’s alpha variants) would help situate the Opposition Index.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight opportunities to enhance the statistical transparency and analytical depth of the manuscript, and we will revise accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): the paper reports a moderate positive correlation and comparable performance of the two variance-prediction methods but supplies no numerical coefficient, p-value, confidence intervals, or comparison against a simple baseline (e.g., mean-variance predictor or lexical-only features). Without these, the central claim that textual features suffice for variance prediction cannot be properly evaluated.
Authors: We acknowledge that while the abstract and §4 describe the correlation as moderate and note comparable performance between the two variance-prediction approaches, the main text does not report the exact coefficient, p-value, confidence intervals, or explicit baseline comparisons. We will revise §4 to include these details (e.g., Pearson r, p-value, 95% CI) and add comparisons against a mean-variance predictor as well as a lexical-only baseline using TF-IDF or n-gram features. This will provide the necessary quantitative support for evaluating the claim that textual features can predict annotation variance. revision: yes
-
Referee: [§5.2] §5.2 (Opposition Index results): the finding that high-opposition items are more difficult to predict and often underestimated is load-bearing for the utility of the proposed metric, yet the section does not report the exact model architecture, feature set, or error analysis (e.g., which textual cues are missed). This leaves open whether the difficulty stems from the index itself or from limitations in the text-only modeling assumption.
Authors: We agree that greater specificity is required to substantiate this key result. In the revision, we will explicitly describe the model architecture and full feature set used for Opposition Index prediction in §5.2. We will also incorporate an error analysis identifying textual cues (e.g., ambiguity markers, specific lexical patterns) associated with underestimation on high-opposition items. This will help isolate whether the observed difficulty arises primarily from the metric or from the text-only modeling choice. We view the text-only setup as a deliberate test of predictability from content alone and will expand the discussion of its assumptions and limitations. revision: yes
Circularity Check
No significant circularity detected in empirical claims
full rationale
The paper presents an empirical investigation into predicting annotation disagreement from textual features alone, along with a proposed Opposition Index metric for quantifying perspective opposition. No derivation chain, equations, or first-principles results are described that reduce by construction to fitted inputs, self-definitions, or self-citations. Reported results consist of standard model evaluations (correlations between predicted and observed variance, comparative performance of direct vs. distribution-based variance prediction) against data, with no evidence that any 'prediction' is statistically forced or that the metric is defined in terms of the outcomes it is used to analyze. The work is self-contained as a test of predictability from text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Seventeenth Symposium on Usable Privacy and Security (SOUPS 2021) , pages=
Designing toxic content classification for a diversity of perspectives , author=. Seventeenth Symposium on Usable Privacy and Security (SOUPS 2021) , pages=
2021
-
[3]
doi: 10.18653/v1/2022.emnlp-main.124
Baan, Joris and Aziz, Wilker and Plank, Barbara and Fernandez, Raquel. Stop Measuring Calibration When Humans Disagree. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.124
-
[5]
Cognitive psychology , volume=
Natural categories , author=. Cognitive psychology , volume=. 1973 , publisher=
1973
-
[6]
Cognitive development and acquisition of language , pages=
On the internal structure of perceptual and semantic categories , author=. Cognitive development and acquisition of language , pages=. 1973 , publisher=
1973
-
[7]
Annual review of sociology , volume=
Birds of a feather: Homophily in social networks , author=. Annual review of sociology , volume=. 2001 , publisher=
2001
-
[8]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) , pages=
Proposal: From One-Fit-All to Perspective Aware Modeling , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) , pages=
-
[9]
Modular pluralism: P luralistic alignment via multi- LLM collaboration
Feng, Shangbin and Sorensen, Taylor and Liu, Yuhan and Fisher, Jillian and Park, Chan Young and Choi, Yejin and Tsvetkov, Yulia. Modular Pluralism: Pluralistic Alignment via Multi- LLM Collaboration. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.240
-
[11]
Mobile DNA , volume=
Transposable element subfamily annotation has a reproducibility problem , author=. Mobile DNA , volume=. 2021 , publisher=
2021
-
[12]
arXiv preprint arXiv:2109.13563 , year=
Agreeing to disagree: Annotating offensive language datasets with annotators' disagreement , author=. arXiv preprint arXiv:2109.13563 , year=
-
[13]
CEUR WORKSHOP PROCEEDINGS , volume=
Annotating hate speech: Three schemes at comparison , author=. CEUR WORKSHOP PROCEEDINGS , volume=. 2019 , organization=
2019
-
[14]
Disaggreghate it corpus: A disaggregated italian dataset of hate speech , author=
-
[15]
European Conference on Information Retrieval , pages=
Overview of exist 2023: sexism identification in social networks , author=. European Conference on Information Retrieval , pages=. 2023 , organization=
2023
-
[16]
Working Notes of CLEF , year=
Concatenated transformer models based on levels of agreements for sexism detection , author=. Working Notes of CLEF , year=
-
[17]
Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives)@ LREC-COLING 2024 , pages=
Is a picture of a bird a bird? A mixed-methods approach to understanding diverse human perspectives and ambiguity in machine vision models , author=. Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives)@ LREC-COLING 2024 , pages=
2024
-
[18]
Proceedings of the 9th ACM Multimedia Systems Conference , pages=
Subdiv17: a dataset for investigating subjectivity in the visual diversification of image search results , author=. Proceedings of the 9th ACM Multimedia Systems Conference , pages=
-
[19]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Earth observation image semantic bias: A collaborative user annotation approach , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2017 , publisher=
2017
-
[20]
In Search of Basic Units of Spoken Language , pages=
Segmentation and analysis of the two English excerpts: The Brazilian team proposal , author=. In Search of Basic Units of Spoken Language , pages=. 2020 , publisher=
2020
-
[21]
, author=
Towards an Annotation Scheme for Complex Laughter in Speech Corpora. , author=. Interspeech , pages=
-
[22]
Neural Computing and Applications , volume=
Automatic chord label personalization through deep learning of shared harmonic interval profiles , author=. Neural Computing and Applications , volume=. 2020 , publisher=
2020
-
[23]
Journal of New Music Research , volume=
Annotator subjectivity in harmony annotations of popular music , author=. Journal of New Music Research , volume=. 2019 , publisher=
2019
-
[24]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
AGB-DE: A Corpus for the Automated Legal Assessment of Clauses in German Consumer Contracts , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Overview of the ImageCLEFmed 2007 medical retrieval and medical annotation tasks , author=. Advances in Multilingual and Multimodal Information Retrieval: 8th Workshop of the Cross-Language Evaluation Forum, CLEF 2007, Budapest, Hungary, September 19-21, 2007, Revised Selected Papers 8 , pages=. 2008 , organization=
2007
-
[26]
Essentials of language documentation , volume=
Linguistic annotation , author=. Essentials of language documentation , volume=. 2006 , publisher=
2006
-
[27]
Computational linguistics , volume=
Inter-coder agreement for computational linguistics , author=. Computational linguistics , volume=. 2008 , publisher=
2008
-
[28]
Finding Patterns in Noisy Crowds: Regression-based Annotation Aggregation for Crowdsourced Data
Parde, Natalie and Nielsen, Rodney. Finding Patterns in Noisy Crowds: Regression-based Annotation Aggregation for Crowdsourced Data. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1204
-
[29]
Proceedings of The Web Conference 2020 , pages=
Modeling and aggregation of complex annotations via annotation distances , author=. Proceedings of The Web Conference 2020 , pages=
2020
-
[30]
arXiv preprint arXiv:2412.02368 , year=
ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation? , author=. arXiv preprint arXiv:2412.02368 , year=
-
[31]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[32]
The state-of-the-art in
Zimbra, David and Abbasi, Ahmed and Zeng, Daniel and Chen, Hsinchun , journal=. The state-of-the-art in. 2018 , publisher=
2018
-
[33]
Procedia Computer Science , volume=
Spam email detection using deep learning techniques , author=. Procedia Computer Science , volume=. 2021 , publisher=
2021
-
[34]
Solving Label Variation in Scientific Information Extraction via Multi-Task Learning
Pham, Dong and Ho, Xanh and Ha, Quang Thuy and Aizawa, Akiko. Solving Label Variation in Scientific Information Extraction via Multi-Task Learning. Proceedings of the 37th Pacific Asia Conference on Language, Information and Computation. 2023
2023
-
[35]
In Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives)@ LREC-COLING 2024 , pages=
An overview of recent approaches to enable diversity in large language models through aligning with human perspectives , author=. In Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives)@ LREC-COLING 2024 , pages=. 2024 , organization=
2024
-
[36]
arXiv preprint arXiv:2410.08820 , year=
Which Demographics do LLMs Default to During Annotation? , author=. arXiv preprint arXiv:2410.08820 , year=
-
[37]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
EPIC: multi-perspective annotation of a corpus of irony , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
arXiv preprint arXiv:2502.13853 , year=
Fine-grained Fallacy Detection with Human Label Variation , author=. arXiv preprint arXiv:2502.13853 , year=
-
[39]
arXiv preprint arXiv:2305.13788 , year=
Can large language models capture dissenting human voices? , author=. arXiv preprint arXiv:2305.13788 , year=
-
[40]
Proceedings of the Third Workshop on Understanding Implicit and Underspecified Language , pages=
More labels or cases? assessing label variation in natural language inference , author=. Proceedings of the Third Workshop on Understanding Implicit and Underspecified Language , pages=
-
[41]
Transactions of the Association for Computational Linguistics , volume=
Inherent disagreements in human textual inferences , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[42]
Transactions of the Association for Computational Linguistics , volume=
Collective human opinions in semantic textual similarity , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[43]
arXiv preprint arXiv:2403.04085 , year=
Don't Blame the Data, Blame the Model: Understanding Noise and Bias When Learning from Subjective Annotations , author=. arXiv preprint arXiv:2403.04085 , year=
-
[44]
arXiv preprint arXiv:2304.14803 , year=
SemEval-2023 task 11: Learning with disagreements (LeWiDi) , author=. arXiv preprint arXiv:2304.14803 , year=
-
[45]
Computational Linguistics , volume=
Squibs: From annotator agreement to noise models , author=. Computational Linguistics , volume=
-
[46]
Transactions of the Association for Computational Linguistics , volume=
Ambifc: Fact-checking ambiguous claims with evidence , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[47]
Computational Linguistics , volume=
Annotation error detection: Analyzing the past and present for a more coherent future , author=. Computational Linguistics , volume=. 2023 , publisher=
2023
-
[48]
Language resources and evaluation , volume=
Annotating expressions of opinions and emotions in language , author=. Language resources and evaluation , volume=. 2005 , publisher=
2005
-
[49]
Learning with Annotation Noise
Beigman, Eyal and Beigman Klebanov, Beata. Learning with Annotation Noise. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. 2009
2009
-
[50]
NLP ositionality: Characterizing Design Biases of Datasets and Models
Santy, Sebastin and Liang, Jenny and Le Bras, Ronan and Reinecke, Katharina and Sap, Maarten. NLP ositionality: Characterizing Design Biases of Datasets and Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.505
-
[51]
Transactions of the Association for Computational Linguistics , volume=
Bridging the gap: A survey on integrating (human) feedback for natural language generation , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[52]
L a MP : When Large Language Models Meet Personalization
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed. L a MP : When Large Language Models Meet Personalization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.399
-
[53]
Alfonso and Martin, Maite
Plaza del Arco, Flor Miriam and Strapparava, Carlo and Urena Lopez, L. Alfonso and Martin, Maite. E mo E vent: A Multilingual Emotion Corpus based on different Events. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[54]
arXiv preprint arXiv:2301.10684 , year=
Consistency is key: Disentangling label variation in natural language processing with intra-annotator agreement , author=. arXiv preprint arXiv:2301.10684 , year=
-
[55]
Disagreement in Argumentation Annotation
Lindahl, Anna. Disagreement in Argumentation Annotation. Proceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives) @ LREC-COLING 2024. 2024
2024
-
[56]
arXiv preprint arXiv:2306.06826 , year=
When do annotator demographics matter? measuring the influence of annotator demographics with the popquorn dataset , author=. arXiv preprint arXiv:2306.06826 , year=
-
[57]
Victoria and Herrera, Francisco
Rodr \'i guez-Barroso, Nuria and C \'a mara, Eugenio Mart \'i nez and Collados, Jose Camacho and Luz \'o n, M. Victoria and Herrera, Francisco. Federated Learning for Exploiting Annotators' Disagreements in Natural Language Processing. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00664
-
[58]
Proceedings of the 1st workshop on benchmarking: past, present and future , pages=
We need to consider disagreement in evaluation , author=. Proceedings of the 1st workshop on benchmarking: past, present and future , pages=. 2021 , organization=
2021
-
[59]
Sensitivity, Performance, Robustness: Deconstructing the Effect of Sociodemographic Prompting
Beck, Tilman and Schuff, Hendrik and Lauscher, Anne and Gurevych, Iryna. Sensitivity, Performance, Robustness: Deconstructing the Effect of Sociodemographic Prompting. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[60]
Quantifying the Persona Effect in LLM Simulations
Hu, Tiancheng and Collier, Nigel. Quantifying the Persona Effect in LLM Simulations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.554
-
[61]
Proceedings of the ACM on Human-Computer Interaction , volume=
Is your toxicity my toxicity? exploring the impact of rater identity on toxicity annotation , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2022 , publisher=
2022
-
[62]
PloS one , volume=
Hate speech detection: Challenges and solutions , author=. PloS one , volume=. 2019 , publisher=
2019
-
[63]
Journal of Communication Inquiry , volume=
Towards a definition of hate speech—With a focus on online contexts , author=. Journal of Communication Inquiry , volume=. 2023 , publisher=
2023
-
[64]
Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media , pages=
Reconsidering annotator disagreement about racist language: Noise or signal? , author=. Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media , pages=
-
[65]
Annotating
Desmond, Patton and Philipp, Blandfort and William, Frey and Michael, Gaskell and Svebor, Karaman , year=. Annotating
-
[66]
Proceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024) , pages=
Leveraging Annotator Disagreement for Text Classification , author=. Proceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024) , pages=
2024
-
[67]
Proceedings of the 15th ACM Web Science Conference 2023 , pages=
Understanding misogynoir: A study of annotators’ perspectives , author=. Proceedings of the 15th ACM Web Science Conference 2023 , pages=
2023
-
[68]
1st Workshop on Perspectivist Approaches to NLP , pages=
Disagreement space in argument analysis , author=. 1st Workshop on Perspectivist Approaches to NLP , pages=. 2022 , organization=
2022
-
[69]
Text Structure and Its Ambiguities: Corpus Annotation as a Helpful Guide , author=
-
[70]
Dialogue & Discourse , volume=
Examples and specifications that prove a point: Identifying elaborative and argumentative discourse relations , author=. Dialogue & Discourse , volume=
-
[71]
Exploiting ` Subjective ' Annotations
Reidsma, Dennis and op den Akker, Rieks. Exploiting ` Subjective ' Annotations. Coling 2008: Proceedings of the workshop on Human Judgements in Computational Linguistics. 2008
2008
-
[72]
Language Resources and Evaluation , pages=
Perspectivist approaches to natural language processing: a survey , author=. Language Resources and Evaluation , pages=. 2024 , publisher=
2024
-
[73]
The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels
Fleisig, Eve and Blodgett, Su Lin and Klein, Dan and Talat, Zeerak. The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024
2024
-
[74]
Proceedings of LAW X: The 10th Linguistic Annotation Workshop , pages=
Supersense tagging with inter-annotator disagreement , author=. Proceedings of LAW X: The 10th Linguistic Annotation Workshop , pages=. 2016 , organization=
2016
-
[75]
Annotate
Ge, Sijia and Li, Zilong and Chen, Alvin Po-Chun and Wang, Guanchao , booktitle=. Annotate
-
[76]
Language Resources and Evaluation , volume=
Multiplicity and word sense: evaluating and learning from multiply labeled word sense annotations , author=. Language Resources and Evaluation , volume=. 2012 , publisher=
2012
-
[77]
Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Embracing ambiguity: A comparison of annotation methodologies for crowdsourcing word sense labels , author=. Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2013
-
[78]
arXiv preprint arXiv:2402.01423 , year=
Different Tastes of Entities: Investigating Human Label Variation in Named Entity Annotations , author=. arXiv preprint arXiv:2402.01423 , year=
-
[79]
Heinisch, Philipp and Orlikowski, Matthias and Romberg, Julia and Cimiano, Philipp. Architectural Sweet Spots for Modeling Human Label Variation by the Example of Argument Quality: It`s Best to Relate Perspectives!. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.687
-
[80]
Journal of Information Processing , volume=
Geographical entity annotated corpus of Japanese microblogs , author=. Journal of Information Processing , volume=. 2017 , publisher=
2017
-
[81]
Proceedings of the AAAI Conference on Human Computation and Crowdsourcing , volume=
Capturing ambiguity in crowdsourcing frame disambiguation , author=. Proceedings of the AAAI Conference on Human Computation and Crowdsourcing , volume=
-
[82]
The Importance of Modeling Social Factors of Language: Theory and Practice
Hovy, Dirk and Yang, Diyi. The Importance of Modeling Social Factors of Language: Theory and Practice. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.49
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.