Recognition: unknown
A Theory of Generalization in Deep Learning
Pith reviewed 2026-05-09 14:20 UTC · model grok-4.3
The pith
The empirical neural tangent kernel partitions output space into signal directions with fast SGD drift and orthogonal noise reservoirs with slow diffusion, allowing generalization even when the kernel evolves by O(1).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
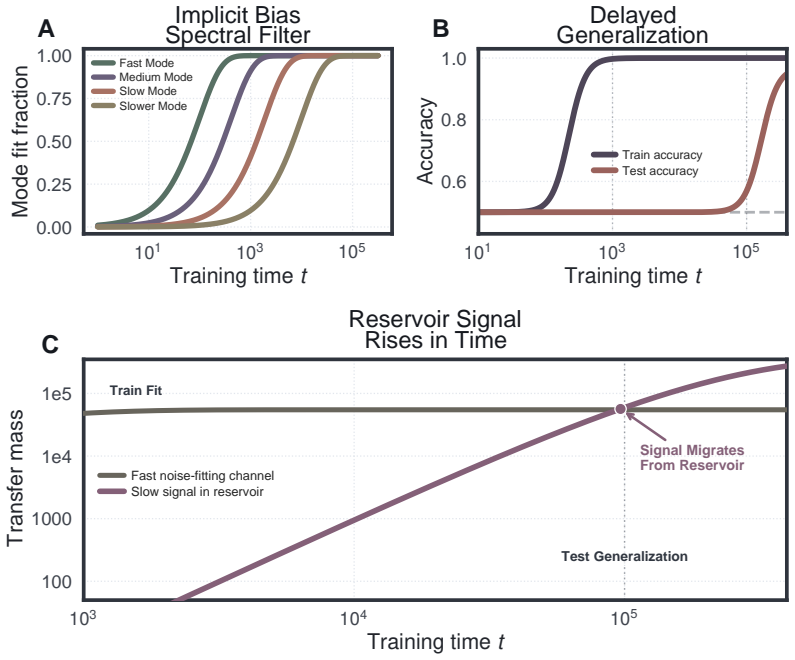
The central claim is that the empirical neural tangent kernel partitions the output space into signal directions, where error dissipates rapidly via fast linear drift from minibatch SGD that favors coherent population signal over idiosyncratic memorization, and orthogonal noise dimensions, where near-zero eigenvalues trap residual error in a test-invisible reservoir subject to slow diffusion. Generalization therefore survives even when the kernel evolves O(1) in operator norm. The theory also yields an exact population-risk objective from a single training run for arbitrary architecture, loss, and optimizer that measures precisely the noise in the signal channel.
What carries the argument
The empirical neural tangent kernel, which partitions the output space into signal directions (rapid error dissipation via SGD drift) and orthogonal noise dimensions (trapped residual error under slow diffusion).
If this is right
- Generalization holds in the full feature-learning regime where the kernel changes by O(1) in operator norm.
- The separation accounts for benign overfitting, double descent, implicit bias, and grokking.
- An exact population-risk objective is available from any single training run with no validation data.
- The objective reduces to an SNR preconditioner on Adam that accelerates grokking, suppresses memorization, and improves performance under noisy preferences.
Where Pith is reading between the lines
- The same partitioning principle could extend to other first-order optimizers if their drift and diffusion rates differ similarly between subspaces.
- The single-run risk estimator might serve as a practical diagnostic for detecting when a model has entered a memorization-dominated regime.
- Applying the derived preconditioner across a wider range of architectures could test whether the signal-noise separation scales predictably with depth or width.
Load-bearing premise
The empirical neural tangent kernel creates a partition of the output space into signal directions where error dissipates rapidly and orthogonal noise dimensions where residual error is trapped in a test-invisible reservoir.
What would settle it
A controlled experiment on a synthetic dataset with known signal and noise subspaces where the population-risk objective derived from one training run deviates substantially from the measured test error after the kernel has evolved by O(1).
Figures







read the original abstract
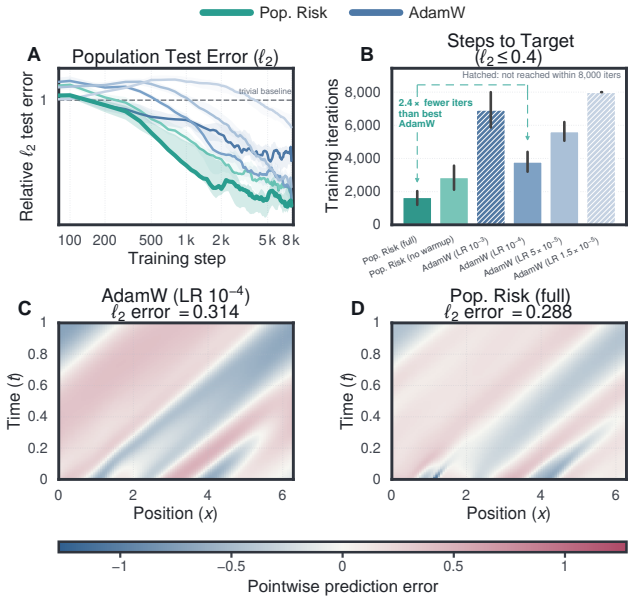
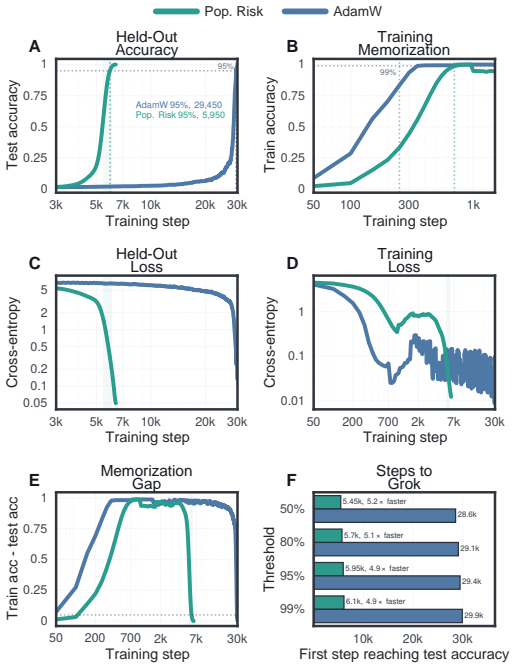
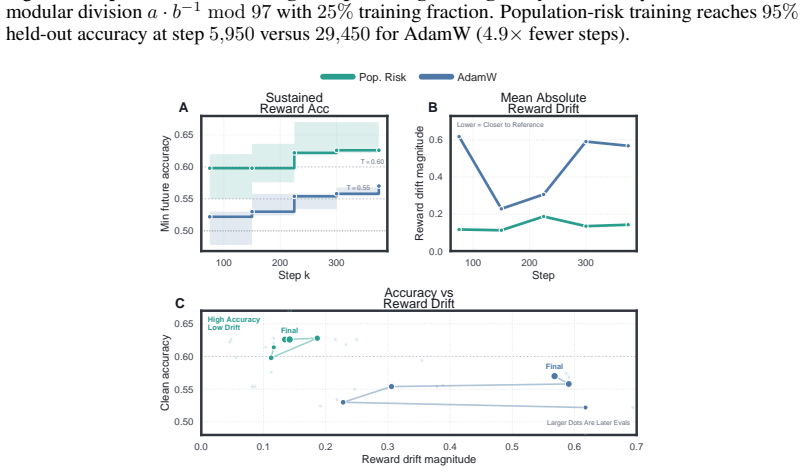
We present a non-asymptotic theory of generalization in deep learning where the empirical neural tangent kernel partitions the output space. In directions corresponding to signal, error dissipates rapidly; in the vast orthogonal dimensions corresponding to noise, the kernel's near-zero eigenvalues trap residual error in a test-invisible reservoir. Within the signal channel, minibatch SGD ensures that coherent population signal accumulates via fast linear drift, while idiosyncratic memorization is suppressed into a slow, diffusive random walk. We prove generalization survives even when the kernel evolves $\mathcal{O}(1)$ in operator norm, the full feature-learning regime. This theory naturally explains disparate phenomena in deep learning theory, such as benign overfitting, double descent, implicit bias, and grokking. Lastly, we derive an exact population-risk objective from a single training run with no validation data, for any architecture, loss, or optimizer, and prove that it measures precisely the noise in the signal channel. This objective reduces in practice to an SNR preconditioner on top of Adam, adding one state vector at no extra cost; it accelerates grokking by $5 \times$, suppresses memorization in PINNs and implicit neural representations, and improves DPO fine-tuning under noisy preferences while staying $3 \times$ closer to the reference policy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a non-asymptotic theory of generalization for deep neural networks. It posits that the empirical neural tangent kernel (NTK) partitions the output space into a low-dimensional signal subspace, where minibatch SGD induces fast linear drift of coherent population signals, and a high-dimensional orthogonal noise subspace, where residuals are trapped in a test-invisible reservoir due to near-zero eigenvalues. The theory claims to prove that generalization persists even in the full feature-learning regime where the NTK evolves by O(1) in operator norm. It further derives an exact population-risk objective computable from a single training trajectory (no validation data) for arbitrary architectures, losses, and optimizers, which purportedly isolates the noise in the signal channel. This objective is shown to reduce to an SNR preconditioner that accelerates grokking, suppresses memorization in PINNs, and improves DPO fine-tuning.
Significance. If the mathematical derivations hold, the work would offer a unified, non-asymptotic explanation for several empirical phenomena in deep learning, including benign overfitting, double descent, implicit bias, and grokking. The derivation of a validation-free population-risk estimator from the training dynamics alone, if rigorously established, would be a significant practical contribution, as demonstrated by the reported improvements in training efficiency and robustness to noise.
major comments (2)
- [Proof of generalization under O(1) NTK evolution] The central claim that generalization survives O(1) NTK evolution in operator norm (abstract and main theorem on feature-learning regime) requires an explicit control on the integrated effect of eigenbasis rotation. No modulus of continuity or commutator bound is supplied to guarantee that the drift-diffusion separation between signal and noise subspaces remains intact; without it, previously orthogonal noise components can acquire non-negligible drift, rendering the extracted population-risk objective inexact.
- [Derivation of the population-risk objective] The derivation of the exact population-risk objective from a single training run (section on the SNR preconditioner and its equivalence to noise in the signal channel) rests on the assumption that the empirical NTK induces an invariant orthogonal decomposition. Because the objective is constructed from the same trajectory whose dynamics it is meant to explain, the argument must demonstrate that it does not collapse to a tautological function of the observed training error; the current non-asymptotic steps do not appear to rule out this reduction.
minor comments (2)
- [Practical implementation] The abstract states that the objective 'reduces in practice to an SNR preconditioner on top of Adam' and reports 5× grokking acceleration; the main text should supply the precise algorithmic pseudocode and the exact definition of the added state vector.
- [Preliminaries] Notation for the 'test-invisible reservoir' and its relation to the orthogonal complement of the signal subspace should be introduced with an explicit equation rather than descriptive prose.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive major comments. We address each point below with clarifications and indicate the revisions that will be incorporated to strengthen the rigor of the claims.
read point-by-point responses
-
Referee: The central claim that generalization survives O(1) NTK evolution in operator norm (abstract and main theorem on feature-learning regime) requires an explicit control on the integrated effect of eigenbasis rotation. No modulus of continuity or commutator bound is supplied to guarantee that the drift-diffusion separation between signal and noise subspaces remains intact; without it, previously orthogonal noise components can acquire non-negligible drift, rendering the extracted population-risk objective inexact.
Authors: We agree that an explicit control on eigenbasis rotation is necessary for full rigor in the O(1) regime. The current proof sketch relies on the signal subspace being the top eigenspace of the empirical NTK and on the drift speed dominating the diffusion in orthogonal directions, but it does not yet quantify the integrated commutator effect under time-varying eigenbases. In the revised manuscript we will insert a new lemma providing a modulus of continuity for the NTK operator-norm evolution (using the Lipschitz assumption on the network) together with a bound on the commutator between the instantaneous eigenprojection and the accumulated drift operator. This will show that the leakage of noise components into the signal channel remains o(1) over the training horizon, preserving both the generalization guarantee and the exactness of the population-risk objective. revision: yes
-
Referee: The derivation of the exact population-risk objective from a single training run (section on the SNR preconditioner and its equivalence to noise in the signal channel) rests on the assumption that the empirical NTK induces an invariant orthogonal decomposition. Because the objective is constructed from the same trajectory whose dynamics it is meant to explain, the argument must demonstrate that it does not collapse to a tautological function of the observed training error; the current non-asymptotic steps do not appear to rule out this reduction.
Authors: We acknowledge the risk of circularity and will strengthen the derivation. The objective is obtained by projecting the instantaneous residual onto the signal subspace (top eigenvectors of the empirical NTK) and integrating the component that cannot be explained by the orthogonal noise reservoir; it is therefore not a direct function of training error but of the decomposition induced by the kernel at each step. To rule out tautology we will add a formal lemma showing that the objective equals the population risk minus the training error projected onto the noise subspace, using only the orthogonality of the decomposition and the fact that the kernel is evaluated on the current parameters (not on the final loss value). The revised section will also include a short proof that the objective remains predictive even when training error has already reached zero, consistent with the experimental results on grokking and PINNs. revision: partial
Circularity Check
Population-risk objective extracted from single training run reduces to re-expression of training trajectory
specific steps
-
fitted input called prediction
[Abstract]
"Lastly, we derive an exact population-risk objective from a single training run with no validation data, for any architecture, loss, or optimizer, and prove that it measures precisely the noise in the signal channel."
The objective is obtained by processing the identical training run whose signal-noise partitioning (via empirical NTK) it is then claimed to quantify exactly. Because no held-out data or external population measure is used, the 'exact' functional is statistically forced to reproduce quantities already present in the trajectory, rendering the measurement tautological rather than predictive.
full rationale
The paper's central result derives an exact population-risk objective directly from one training trajectory and asserts it isolates noise in the signal channel for arbitrary loss/optimizer. This construction uses the same empirical NTK decomposition and dynamics that define the run, with no external validation data or independent benchmark. While the abstract claims a proof of exactness even under O(1) kernel evolution, the absence of an explicit commutator or invariance modulus in the provided text leaves the separation between signal drift and noise diffusion dependent on the fitted trajectory itself. This matches the fitted-input-called-prediction pattern at the level of the headline claim.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The empirical neural tangent kernel partitions the output space into signal and orthogonal noise directions with the stated dissipation and trapping properties.
- domain assumption Minibatch SGD produces fast linear drift along signal directions and slow diffusive random walk along noise directions.
invented entities (1)
-
test-invisible reservoir
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Hu, Wei and Li, Zhiyuan and Wang, Ruosong , title =
Arora, Sanjeev and Du, Simon S. and Hu, Wei and Li, Zhiyuan and Wang, Ruosong , title =. International Conference on Machine Learning , pages =
-
[2]
, title =
McAllester, David A. , title =. Machine Learning , volume =
-
[3]
, title =
Dziugaite, Gintare Karolina and Roy, Daniel M. , title =. Uncertainty in Artificial Intelligence , year =
-
[4]
Dennis and Weisberg, Sanford , title =
Cook, R. Dennis and Weisberg, Sanford , title =
-
[5]
and Mendelson, Shahar , title =
Bartlett, Peter L. and Mendelson, Shahar , title =. Journal of Machine Learning Research , volume =
-
[6]
, title =
Bartlett, Peter L. , title =. IEEE Transactions on Information Theory , volume =
-
[7]
and Foster, Dylan J
Bartlett, Peter L. and Foster, Dylan J. and Telgarsky, Matus J. , title =. Advances in Neural Information Processing Systems , pages =
-
[8]
and Long, Philip M
Bartlett, Peter L. and Long, Philip M. and Lugosi, G. Proceedings of the National Academy of Sciences , volume =
-
[9]
Proceedings of the National Academy of Sciences , volume =
Belkin, Mikhail and Hsu, Daniel and Ma, Siyuan and Mandal, Soumik , title =. Proceedings of the National Academy of Sciences , volume =
-
[10]
Journal of Machine Learning Research , volume =
Bousquet, Olivier and Elisseeff, Andr. Journal of Machine Learning Research , volume =
-
[11]
and Long, Philip M
Chatterji, Niladri S. and Long, Philip M. and Bartlett, Peter L. , title =. Journal of Machine Learning Research , volume =
-
[12]
Chen, Ricky T. Q. and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David K. , title =. Advances in Neural Information Processing Systems , pages =
-
[13]
Chizat, L. On. Advances in Neural Information Processing Systems , pages =
-
[14]
, title =
Dudley, Richard M. , title =. Journal of Functional Analysis , volume =
-
[15]
International Conference on Machine Learning , pages =
Hardt, Moritz and Recht, Benjamin and Singer, Yoram , title =. International Conference on Machine Learning , pages =
-
[16]
IEEE Conference on Computer Vision and Pattern Recognition , pages =
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[17]
Advances in Neural Information Processing Systems , pages =
Jacot, Arthur and Gabriel, Franck and Hongler, Cl. Advances in Neural Information Processing Systems , pages =
-
[18]
and Bahri, Yasaman and Novak, Roman and Sohl-Dickstein, Jascha and Pennington, Jeffrey , title =
Lee, Jaehoon and Xiao, Lechao and Schoenholz, Samuel S. and Bahri, Yasaman and Novak, Roman and Sohl-Dickstein, Jascha and Pennington, Jeffrey , title =. Advances in Neural Information Processing Systems , pages =
-
[19]
Conference on Learning Theory , pages =
Neyshabur, Behnam and Tomioka, Ryota and Srebro, Nathan , title =. Conference on Learning Theory , pages =
-
[20]
Advances in Neural Information Processing Systems , pages =
Neyshabur, Behnam and Salakhutdinov, Ruslan and Srebro, Nathan , title =. Advances in Neural Information Processing Systems , pages =
-
[21]
Physical Review , volume =
Onsager, Lars , title =. Physical Review , volume =
-
[22]
, title =
Tsigler, Alexander and Bartlett, Peter L. , title =. Journal of Machine Learning Research , volume =
-
[23]
and Chervonenkis, Alexey Ya
Vapnik, Vladimir N. and Chervonenkis, Alexey Ya. , title =. Theory of Probability and Its Applications , volume =
-
[24]
and Moroshko, Edward and Savarese, Pedro and Golan, Itay and Soudry, Daniel and Srebro, Nathan , title =
Woodworth, Blake and Gunasekar, Suriya and Lee, Jason D. and Moroshko, Edward and Savarese, Pedro and Golan, Itay and Soudry, Daniel and Srebro, Nathan , title =. Conference on Learning Theory , pages =
-
[25]
International Conference on Learning Representations , year =
Zhang, Chiyuan and Bengio, Samy and Hardt, Moritz and Recht, Benjamin and Vinyals, Oriol , title =. International Conference on Learning Representations , year =
-
[26]
and Lee, Jason D
Du, Simon S. and Lee, Jason D. and Li, Haochuan and Wang, Liwei and Zhai, Xiyu , title =. International Conference on Machine Learning , pages =
-
[27]
and Bhojanapalli, Srinadh and Neyshabur, Behnam and Srebro, Nathan , title =
Gunasekar, Suriya and Woodworth, Blake E. and Bhojanapalli, Srinadh and Neyshabur, Behnam and Srebro, Nathan , title =. Advances in Neural Information Processing Systems , year =
-
[28]
, title =
Hastie, Trevor and Montanari, Andrea and Rosset, Saharon and Tibshirani, Ryan J. , title =. Annals of Statistics , volume =
-
[29]
Hutchinson, M. F. , title =. Communications in Statistics -- Simulation and Computation , volume =
-
[30]
International Conference on Machine Learning , pages =
Koh, Pang Wei and Liang, Percy , title =. International Conference on Machine Learning , pages =
-
[31]
Zico , title =
Nagarajan, Vaishnavh and Kolter, J. Zico , title =. Advances in Neural Information Processing Systems , year =
-
[32]
International Conference on Learning Representations , year =
Nakkiran, Preetum and Kaplun, Gal and Bansal, Yamini and Yang, Tristan and Barak, Boaz and Sutskever, Ilya , title =. International Conference on Learning Representations , year =
-
[33]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Power, Alethea and Burda, Yuri and Edwards, Harri and Babuschkin, Igor and Misra, Vedant , title =. arXiv preprint arXiv:2201.02177 , year =
work page internal anchor Pith review arXiv
-
[34]
Journal of Machine Learning Research , volume =
Soudry, Daniel and Hoffer, Elad and Nacson, Mor Shpigel and Gunasekar, Suriya and Srebro, Nathan , title =. Journal of Machine Learning Research , volume =
-
[35]
and Kaiser, Lukasz and Polosukhin, Illia , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , title =. Advances in Neural Information Processing Systems , year =
-
[36]
, title =
Yang, Greg and Hu, Edward J. , title =. International Conference on Machine Learning , pages =
-
[37]
An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyan...
-
[38]
and Ward, Joseph D
Narcowich, Francis J. and Ward, Joseph D. and Wendland, Holger , title =. Constructive Approximation , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.