Recognition: unknown
Decision-Induced Ranking Explains Prediction Inflation and Excessive Turnover in SPO-Based Portfolio Optimization
Pith reviewed 2026-05-10 15:54 UTC · model grok-4.3
The pith
SPO-based portfolio optimization inflates return predictions and drives excessive turnover because decisions reduce to ranking over risk- and transaction-cost-adjusted marginal scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Portfolio decisions under SPO-based decision-focused learning can be interpreted, via KKT conditions, as a ranking over risk- and transaction-cost-adjusted marginal scores. This ranking mechanism produces inflated return predictions and high turnover because small shifts in the adjusted scores change the selected set and therefore the loss signal sent back to the predictor. Clipping, min-max rescaling, and partial adjustment reduce both inflation and turnover while preserving implementability of the resulting strategies.
What carries the argument
The KKT-based reduction of portfolio decisions to ranking over risk- and transaction-cost-adjusted marginal scores.
If this is right
- Predictors learn to amplify marginal scores because only the top-ranked items affect the portfolio loss.
- Small changes in risk or cost estimates flip rankings and therefore trigger large reallocations.
- Clipping and rescaling limit score exaggeration before ranking occurs.
- Partial adjustment caps turnover by limiting how many positions can change in each period.
Where Pith is reading between the lines
- The same ranking-induced bias is likely to appear in other decision-focused learning settings that embed a combinatorial selection step.
- Predictors could be regularized explicitly against the ranking operator to reduce inflation without post-hoc fixes.
- Out-of-sample tests that include realistic transaction-cost schedules would quantify how much stabilization improves net performance.
Load-bearing premise
The prediction inflation and excessive turnover are caused primarily by this decision-induced ranking rather than by other modeling choices, data features, or optimization details.
What would settle it
Demonstrating no inflation or low turnover in an SPO-trained portfolio when the ranking step is replaced by an optimization formulation that does not induce explicit ranking over adjusted marginal scores.
Figures

read the original abstract
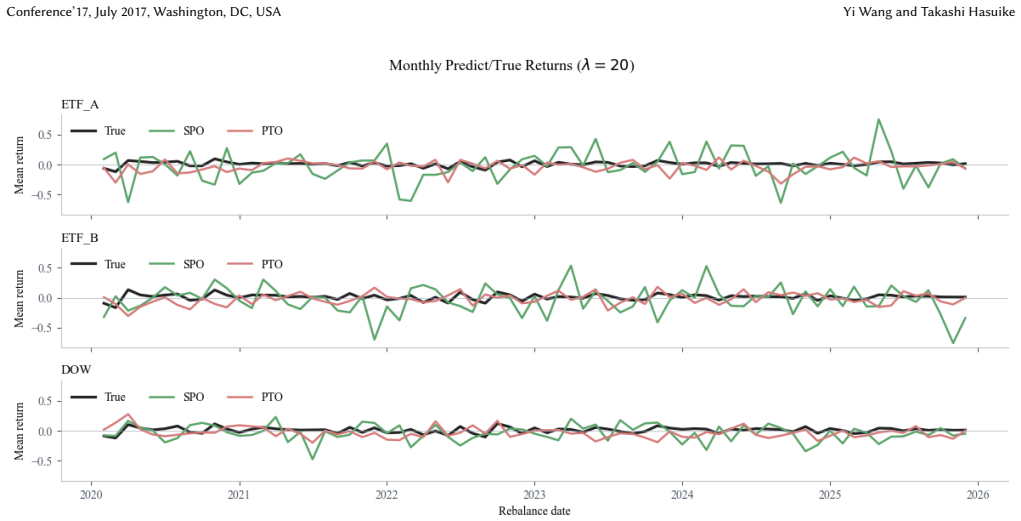
Decision-focused learning (DFL) is attractive for portfolio optimization because it trains predictors according to downstream decision quality rather than prediction accuracy alone. However, SPO(Smart, Predict then Optimize surrogate)-based DFL may produce inflated return signals and unstable portfolio reallocations. This study provides a KKT-based interpretation showing that portfolio decisions can be viewed as ranking over risk- and transaction-cost-adjusted marginal scores. Empirically, we examine prediction inflation and excessive turnover in SPO-trained portfolios, and evaluate clipping, min-max rescaling, and partial portfolio adjustment as practical stabilization mechanisms. The results suggest that realistic output constraints and portfolio-level turnover control improve the implementability of SPO-based portfolio strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SPO-based decision-focused learning for portfolio optimization induces a ranking over risk- and transaction-cost-adjusted marginal scores (via KKT conditions), which mechanistically explains observed prediction inflation and excessive turnover. It derives this interpretation theoretically and empirically evaluates stabilization techniques (clipping, min-max rescaling, partial portfolio adjustment), concluding that realistic output constraints and turnover controls improve implementability of the resulting strategies.
Significance. If the KKT ranking interpretation holds and the empirical attribution is isolated from confounding factors, the work supplies a concrete mechanistic account of why DFL can degrade in finance applications and identifies practical mitigations. This could inform surrogate design and post-processing in decision-focused portfolio methods, provided the claims survive controls for surrogate loss, constraints, and data properties.
major comments (2)
- [§3] §3 (KKT Interpretation): The claim that the ranking view directly induces prediction inflation requires an explicit derivation showing how the marginal-score ordering produces upward bias in the learned predictor, rather than merely re-describing the decision rule; without this, the interpretation risks being tautological with the fitted parameters of the SPO surrogate.
- [§4] §4 (Empirical Tests): The central attribution of inflation and turnover to the decision-induced ranking is not isolated from other SPO components. Experiments must control for surrogate-loss details, constraint tightness, and return non-stationarity (e.g., via ablation against non-SPO baselines or synthetic stationary data); absent such controls, the causal claim remains unsupported.
minor comments (2)
- [Abstract and §4] The abstract and methods should explicitly state the dataset(s), prediction models, and statistical tests used to quantify inflation and turnover, including any significance levels or robustness checks.
- [§2-3] Notation for the adjusted marginal scores (risk- and cost-adjusted) should be introduced once with a clear equation reference and used consistently thereafter.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which identifies key opportunities to strengthen the theoretical and empirical foundations of our work. We address each major comment point by point below, outlining specific revisions that will be incorporated into the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (KKT Interpretation): The claim that the ranking view directly induces prediction inflation requires an explicit derivation showing how the marginal-score ordering produces upward bias in the learned predictor, rather than merely re-describing the decision rule; without this, the interpretation risks being tautological with the fitted parameters of the SPO surrogate.
Authors: We agree that an explicit derivation is required to establish the causal link from marginal-score ranking to prediction inflation. In the revised manuscript, we will expand §3 with a step-by-step derivation: starting from the KKT conditions of the portfolio optimization, we show that the subgradient of the SPO loss with respect to the predicted returns contains a term proportional to the dual variables on the ranking constraints, which systematically encourages higher predictions for assets that rank favorably on risk- and cost-adjusted scores. This produces an upward bias in the learned predictor that is distinct from standard regression fitting. We will also include a small analytical example contrasting the SPO gradient with a pure prediction loss to demonstrate the mechanism is not tautological. revision: yes
-
Referee: [§4] §4 (Empirical Tests): The central attribution of inflation and turnover to the decision-induced ranking is not isolated from other SPO components. Experiments must control for surrogate-loss details, constraint tightness, and return non-stationarity (e.g., via ablation against non-SPO baselines or synthetic stationary data); absent such controls, the causal claim remains unsupported.
Authors: We acknowledge that stronger isolation is needed to support the causal attribution. While the current experiments include sensitivity checks on the SPO surrogate and comparisons to prediction-only baselines, these do not fully control for non-stationarity or constraint effects. In the revision we will add: (i) experiments on synthetic stationary Gaussian returns to remove non-stationarity confounds, (ii) systematic ablations varying constraint tightness (e.g., tighter risk budgets) and surrogate loss hyperparameters, and (iii) direct comparisons against non-SPO decision-focused methods. These controls will be reported in an expanded §4 to isolate the contribution of the decision-induced ranking. revision: yes
Circularity Check
No significant circularity; KKT derivation follows from standard optimality conditions
full rationale
The paper derives a KKT-based view of portfolio decisions as ranking over risk- and transaction-cost-adjusted marginal scores directly from the optimality conditions of the underlying convex optimization problem. This is a standard mathematical reinterpretation independent of any fitted parameters, data, or self-referential definitions in the SPO surrogate. The empirical examination of prediction inflation and excessive turnover, along with evaluation of stabilization mechanisms such as clipping and rescaling, is presented as observational analysis rather than a prediction forced by construction from inputs. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results are evident in the derivation chain, rendering the overall argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hassan T. Anis and Roy H. Kwon. 2025. End-to-end, decision-based, cardinality- constrained portfolio optimization.European Journal of Operational Research322, 1 (2025), 273–288. doi:10.1016/j.ejor.2024.08.026
-
[2]
Jyotirmayee Behera and Pankaj Kumar. 2025. Optimizing mean conditional value- at-risk portfolios through deep neural network stock prediction.Engineering Applications of Artificial Intelligence161 (2025), 112198. doi:10.1016/j.engappai. 2025.112198
- [3]
- [4]
-
[5]
Guido J. Deboeck. 1994.Trading on the Edge: Neural, Genetic, and Fuzzy Systems for Chaotic Financial Markets. Wiley
1994
-
[6]
Predict, then Optimize
Adam N. Elmachtoub and Paul Grigas. 2022. Smart “Predict, then Optimize”. Management Science68, 1 (2022), 9–26
2022
-
[7]
Freitas, Adriano F
Fabio D. Freitas, Adriano F. De Souza, and Ailson R. de Almeida. 2009. Prediction- based portfolio optimization model using neural networks.Neurocomputing72, 10–12 (2009), 2155–2170
2009
-
[8]
Juhyeong Kim. 2025. Semi-Decision-Focused Learning with Deep Ensembles: A Practical Framework for Robust Portfolio Optimization. InWorkshop on Ad- vances in Financial AI: Opportunities, Innovations, and Responsible AI, International Conference on Learning Representations. https://iclr.cc/virtual/2025/33863
2025
-
[9]
Juchan Kim, Inwoo Tae, and Yongjae Lee. 2025. Estimating Covariance for Global Minimum Variance Portfolio: A Decision-Focused Learning Approach. In Proceedings of the 6th ACM International Conference on AI in Finance. Association for Computing Machinery. doi:10.1145/3768292.3770378
-
[10]
Christopher Krauss, Xuan Anh Do, and Nicolas Huck. 2017. Deep neural networks, gradient-boosted trees, random forests: Statistical arbitrage on the S&P 500. European Journal of Operational Research259, 2 (2017), 689–702
2017
-
[11]
Junhyeong Lee, Haeun Jeon, Hyunglip Bae, and Yongjae Lee. 2025. Return Pre- diction for Mean-Variance Portfolio Selection: How Decision-Focused Learning Shapes Forecasting Models. InProceedings of the 6th ACM International Conference on AI in Finance. 114–122. doi:10.1145/3768292.3770423
-
[12]
Yuhong Ma, Ruizhe Han, and Weijie Wang. 2021. Portfolio optimization with return prediction using deep learning and machine learning.Expert Systems with Applications165 (2021), 113973
2021
-
[13]
Jayanta Mandi, Víctor Bucarey, Maxime Mulamba, and Tias Guns. 2022. Decision- Focused Learning: Through the Lens of Learning to Rank. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162). PMLR, 14935–14947
2022
-
[14]
Jayanta Mandi, James Kotary, Senne Berden, Maxime Mulamba, Víctor Bucarey, Tias Guns, and Ferdinando Fioretto. 2024. Decision-focused learning: Founda- tions, state of the art, benchmark and future opportunities.Journal of Artificial Intelligence Research80 (2024), 1623–1701
2024
-
[15]
Harry Markowitz. 1952. Portfolio Selection.The Journal of Finance7, 1 (1952), 77–91
1952
-
[16]
Paiva, Rafael T
Filipe D. Paiva, Rafael T. N. Cardoso, Gustavo P. Hanaoka, and Wiliam M. Duarte
-
[17]
Decision-making for financial trading: A fusion approach of machine learning and portfolio selection.Expert Systems with Applications115 (2019), 635–655
2019
-
[18]
Bryan Wilder, Bistra Dilkina, and Milind Tambe. 2019. Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 1658–1665
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.