Recognition: unknown
To Do or Not to Do: Ensuring the Safety of Visuomotor Policies Learned from Demonstrations
Pith reviewed 2026-05-09 14:57 UTC · model grok-4.3
The pith
Execution guarantee ensures visuomotor imitation policies achieve maximum task success from identified safe state regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
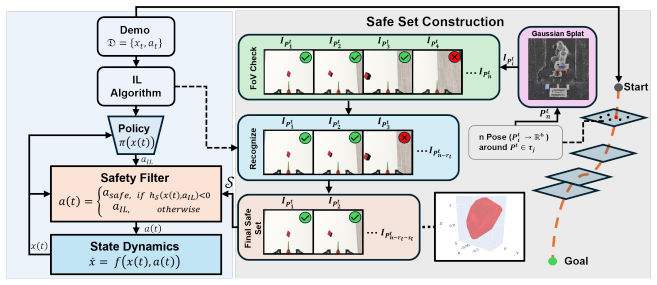
We propose execution guarantee, a policy-agnostic safety measure that guarantees the maximum task success for a visuomotor IL policy, despite minor run-time changes, from within a specific region in the state space. We leverage recent advances in view synthesis to identify such regions in the state space for an IL policy and explore a fundamental result on set invariance - namely, Nagumo's sub-tangentiality condition - to prove and operationalize execution guarantee from inside that region.
What carries the argument
Execution guarantee, proven and operationalized via Nagumo's sub-tangentiality condition for set invariance on state-space regions identified by view synthesis.
If this is right
- Policies can be selectively executed only from safe regions, preventing poor performance and increasing overall safety in field robotics.
- A recovery policy derived from the invariance analysis can return the system to the guaranteed region and improve net performance.
- The approach applies across different IL policies, allowing them to reach maximum task success with formal safety assurance.
- Selective execution based on the guarantee directly reduces the safety-performance tradeoff without changing the underlying policy.
Where Pith is reading between the lines
- The method could be extended to reinforcement learning policies if similar invariance conditions can be checked via view synthesis.
- Real-time view synthesis during execution might enable continuous safety monitoring rather than only initial checks.
- Integrating uncertainty estimates from the policy could enlarge the safe regions or yield probabilistic versions of the guarantee.
Load-bearing premise
View synthesis can reliably locate state-space regions where the learned policy satisfies Nagumo's sub-tangentiality condition for invariance under minor runtime changes.
What would settle it
Starting the policy inside a region identified by view synthesis as satisfying the invariance condition and observing failure to achieve maximum task success under only minor runtime perturbations.
Figures



read the original abstract
Task success has historically been the primary measure of policy performance in imitation learning (IL) research. This characteristics strictly limits the ubiquitous applications of IL algorithms in field robotics where safety assurance, in addition to task-success, is of paramount importance. It is often desirable for an IL-powered robot in the field not to roll out a policy, and hence score a poor performance, if the safety is not guaranteed. Although this trade-off between safety and performance is well investigated in classical control literature, policy safety is a heavily underexplored domain in IL research. There is no universal definition of safety in IL. To make things worst, many existing theoretical works on safety is notoriously difficult to extend to IL-powered robots in the field. This paper offers important insights on the safety and performance of IL policies. We propose execution guarantee, a policy-agnostic safety measure that guarantees the maximum task success for a visuomotor IL policy, despite minor run-time changes, from within a specific region in the state space. We leverage recent advances in view synthesis to identify such regions in the state space for an IL policy and explore a fundamental result on set invariance - namely, Nagumo's sub-tangentiality condition - to prove and operationalize execution guarantee from inside that region. Experiments with a Franka robot, both in simulation and real world, demonstrate how the proposed safety analysis allows various IL policies to achieve maximum task success with guarantee. We also demonstrate some interesting results on how a recovery policy - a by-product of the proposed safety analysis - can help to increase the policy performance and thereby mitigating the safety-performance tradeoff in IL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'execution guarantee' as a policy-agnostic safety measure for visuomotor imitation learning (IL) policies. It uses recent view-synthesis techniques to identify state-space regions S in which the learned policy satisfies Nagumo's sub-tangentiality condition with respect to the closed-loop dynamics, thereby rendering S positively invariant and guaranteeing maximum task success despite minor runtime changes. A recovery policy is derived as a byproduct. The approach is validated through experiments with a Franka robot arm in both simulation and real-world settings.
Significance. If the claimed invariance guarantee can be made rigorous, the work would meaningfully advance safe deployment of learned visuomotor policies in robotics by linking imitation learning with classical set-invariance theory. The combination of view synthesis for region identification with Nagumo's condition is a novel practical bridge, and the real-robot experiments plus recovery-policy results provide concrete evidence of utility in mitigating the safety-performance tradeoff.
major comments (2)
- [Method/Theoretical section] Method/Theoretical section (around the definition of execution guarantee and Nagumo application): The argument that view synthesis identifies a region S where Nagumo's sub-tangentiality condition holds for the entire boundary ∂S rests on finite sampled synthetic views. For a black-box neural policy there is no analytic expression or dense covering argument showing the supporting-hyperplane condition is satisfied everywhere on ∂S; sampled checks leave open the possibility that the condition fails on a positive-measure subset, so minor runtime perturbations can drive trajectories out of S without violating the sampled verification.
- [Experiments section] Experiments section (simulation and real-world results): The reported task-success rates and recovery-policy improvements are presented without quantitative verification that closed-loop trajectories remain inside the identified invariant set (e.g., distance-to-boundary statistics, failure cases near ∂S, or sensitivity to lighting/calibration drift). This makes it impossible to assess whether the claimed guarantee is actually operationalized or merely correlated with success in the tested conditions.
minor comments (3)
- [Abstract] Abstract: 'to make things worst' should read 'worse'.
- [Introduction/Method] Notation and definitions: The precise mathematical statement of 'execution guarantee' (the set S, the vector field f(π(x)), and the exact form of the Nagumo condition used) should be stated explicitly with equation numbers rather than described only in prose.
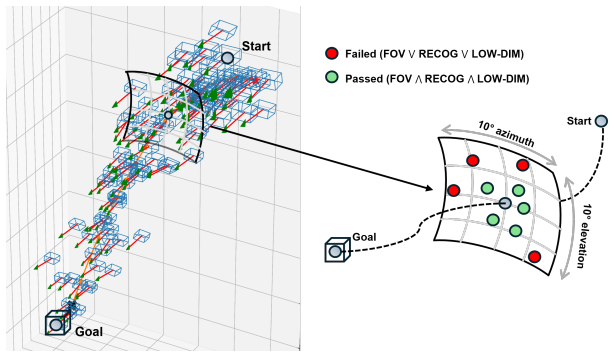
- [Figures] Figures: The visualizations of identified state-space regions and view-synthesis outputs would benefit from explicit boundary annotations and scale bars to allow readers to judge sampling density.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of rigor in the theoretical claims and empirical validation of execution guarantee. We address each major comment below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method/Theoretical section] Method/Theoretical section (around the definition of execution guarantee and Nagumo application): The argument that view synthesis identifies a region S where Nagumo's sub-tangentiality condition holds for the entire boundary ∂S rests on finite sampled synthetic views. For a black-box neural policy there is no analytic expression or dense covering argument showing the supporting-hyperplane condition is satisfied everywhere on ∂S; sampled checks leave open the possibility that the condition fails on a positive-measure subset, so minor runtime perturbations can drive trajectories out of S without violating the sampled verification.
Authors: We agree that the verification of Nagumo's sub-tangentiality condition relies on finite sampling of synthetic views generated by the view-synthesis module, and that the black-box nature of the neural policy precludes an analytic expression or exhaustive dense covering of ∂S. The manuscript operationalizes the guarantee through dense empirical sampling combined with the continuity of the learned policy and the closed-loop dynamics, with experiments showing consistent invariance in practice. However, we acknowledge that this does not constitute a strict pointwise guarantee for every point on the boundary. In the revision we will add a new subsection under the theoretical analysis that explicitly discusses the sampling strategy, the role of policy continuity, the empirical density achieved, and the resulting limitations (including the possibility of violations on a measure-zero or low-probability set). We will also clarify that the execution guarantee is therefore a practical, high-confidence operationalization rather than a fully analytic proof. revision: partial
-
Referee: [Experiments section] Experiments section (simulation and real-world results): The reported task-success rates and recovery-policy improvements are presented without quantitative verification that closed-loop trajectories remain inside the identified invariant set (e.g., distance-to-boundary statistics, failure cases near ∂S, or sensitivity to lighting/calibration drift). This makes it impossible to assess whether the claimed guarantee is actually operationalized or merely correlated with success in the tested conditions.
Authors: We appreciate this observation. The current experiments focus on task-success rates and recovery-policy benefits but do not include explicit quantitative checks confirming that trajectories stay inside S. In the revised manuscript we will augment the Experiments section with additional metrics: (i) time-series and aggregate statistics of the distance from each trajectory point to the identified boundary ∂S, (ii) analysis of any observed failures or near-boundary excursions, and (iii) sensitivity tests under controlled lighting changes and calibration perturbations in both simulation and real-robot settings. These additions will directly demonstrate that the invariance property is realized in the reported trials. revision: yes
Circularity Check
No significant circularity: derivation applies external Nagumo theorem to view-synthesis-identified regions without reducing to fitted inputs or self-citation.
full rationale
The paper defines execution guarantee via Nagumo's sub-tangentiality condition (an independent mathematical result on set invariance) applied to regions identified by view synthesis. No quoted step shows the guarantee reducing by construction to the IL policy's training data, a fitted parameter, or a self-citation chain. The central claim remains non-tautological and relies on external benchmarks (Nagumo condition, view-synthesis methods) rather than re-labeling its own inputs as predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nagumo's sub-tangentiality condition can be verified or enforced for the regions located by view synthesis with respect to the IL policy dynamics
Reference graph
Works this paper leans on
-
[1]
Brunke, M
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learn- ing in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5(1):411–444, 2022
2022
-
[2]
Bansal, M
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2242–2253. IEEE, 2017
2017
-
[3]
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada. Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8):3861– 3876, 2017
2017
-
[4]
Wabersich and M
J. Wabersich and M. N. Zeilinger. Predictive safety filter: A modular safety layer for learning- based control.IEEE Transactions on Automatic Control, 2022. Early Access
2022
-
[5]
W. Xiao, T.-H. Wang, C. Gan, and D. Rus. Safediffuser: Safe planning with diffusion proba- bilistic models.arXiv preprint arXiv:2306.00148, 2023
-
[6]
K. Nakamura, L. Peters, and A. Bajcsy. Generalizing safety beyond collision-avoidance via latent-space reachability analysis.arXiv preprint arXiv:2502.00935, 2025
-
[7]
J. P. Fisac, A. K. Akametalu, M. N. Zeilinger, W. Huang, and C. J. Tomlin. A general safety framework for learning in uncertain robotic environments. InProc. IEEE Conf. on Decision and Control (CDC), pages 2735–2742, 2018
2018
-
[8]
Alshiekh, R
M. Alshiekh, R. Bloem, R. Ehlers, M. J. Kochenderfer, U. Topcu, and M. Y . Vardi. Safe reinforcement learning via shielding. InProc. AAAI Conf. on Artificial Intelligence, pages 2669–2678, 2018
2018
-
[9]
Berkenkamp, M
F. Berkenkamp, M. P. Turchetta, A. P. Schoellig, and A. Krause. Safe model-based reinforce- ment learning with stability guarantees. InAdvances in Neural Information Processing Systems (NeurIPS), pages 908–918, 2017
2017
-
[10]
G. Kahn, A. Villaflor, V . P. Ding, P. Abbeel, and S. Levine. Uncertainty-aware reinforcement learning for collision avoidance. InProc. IEEE Int. Conf. on Robotics and Automation (ICRA), pages 316–323, 2017
2017
-
[11]
M. Nagumo. ¨Uber die lage der integralkurven gew¨ohnlicher differentialgleichungen.Proceed- ings of the Physico-Mathematical Society of Japan. 3rd Series, 24:551–559, 1942
1942
-
[12]
Bicer, A
Y . Bicer, A. Alizadeh, N. K. Ure, A. Erdogan, and O. Kizilirmak. Sample efficient interactive end-to-end deep learning for self-driving cars with selective multi-class safe dataset aggrega- tion. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2629–2634. IEEE, 2019
2019
- [13]
-
[14]
Blanchini
F. Blanchini. Set invariance in control.Automatica, 35(11):1747–1767, 1999
1999
- [15]
- [16]
-
[17]
Xiao, T.-H
W. Xiao, T.-H. Wang, R. Hasani, M. Chahine, A. Amini, X. Li, and D. Rus. Barriernet: Differentiable control barrier functions for learning of safe robot control.IEEE Transactions on Robotics, 39(3):2289–2307, 2023
2023
-
[18]
K. P. Wabersich, A. J. Taylor, J. J. Choi, K. Sreenath, C. J. Tomlin, A. D. Ames, and M. N. Zeilinger. Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems.IEEE Control Systems Magazine, 43(5):137– 177, 2023
2023
-
[19]
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, J. Peters, et al. An algorithmic perspective on imitation learning.Foundations and Trends in Robotics, 7(1-2):1–179, 2018
2018
-
[20]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[21]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review arXiv 2021
-
[22]
Blanchini, S
F. Blanchini, S. Miani, et al.Set-theoretic methods in control, volume 78. Springer, 2008
2008
-
[23]
Sojib and M
N. Sojib and M. Begum. Self supervised detection of incorrect human demonstrations: A path toward safe imitation learning by robots in the wild. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2862–2869. IEEE, 2024
2024
-
[24]
Arnab, M
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid. Vivit: A video vision transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021
2021
-
[25]
X. Li, V . Belagali, J. Shang, and M. S. Ryoo. Crossway diffusion: Improving diffusion-based visuomotor policy via self-supervised learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16841–16849, 2024. 10 Figure 5: Candidate Pose Filtering A Safe set Construction A.1 Field-of-View Constraint TheF OV(x)term evaluates whe...
2024
-
[26]
Letd(x eef, g) =∥x eef −g∥ 2
Proximity Constraint.The end-effector must lie within a task-relevant distance range from the goal object. Letd(x eef, g) =∥x eef −g∥ 2. A candidate state is retained only if: dmin ≤d(x eef, g)≤d max,(9) with boundsd min andd max estimated from empirical statistics over the demonstration trajectories, and margins added for robustness
-
[27]
Table Clearance Constraint.To prevent collision with the workspace surface, the vertical position of the end-effector must exceed a minimum clearance: zeef ≥z table +ϵ,(10) wherez table is the known table height andϵis a tunable buffer
-
[28]
Leta eef ∈R 3 be the local x-axis of the gripper (expressed in world coordinates), anda world = [0,0,−1] ⊤
Orientation Alignment Constraint.The end-effector’s approach direction is constrained to remain near the world’s downward axis. Leta eef ∈R 3 be the local x-axis of the gripper (expressed in world coordinates), anda world = [0,0,−1] ⊤. We require: arccos a⊤ eefaworld ≤θ max,(11) whereθ max is set based on the maximum deviation observed in demonstrations. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.