Recognition: unknown
Visual Implicit Autoregressive Modeling
Pith reviewed 2026-05-09 15:17 UTC · model grok-4.3
The pith
VIAR embeds an implicit equilibrium layer in next-scale autoregressive generation to match VAR quality with 38% of the parameters and flexible inference compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VIAR is a next-scale autoregressive generator that places an implicit equilibrium layer between shallow pre- and post-processing blocks. The layer is trained end-to-end with Jacobian-Free Backpropagation, which yields constant training memory. At inference the layer can be unrolled for an arbitrary number of steps per scale, exposing a direct knob on compute budget. The approach attains FID 2.16 and sFID 8.07 on ImageNet 256x256 with 38.4% of VAR's parameters and remains competitive with large diffusion models.
What carries the argument
Implicit equilibrium layer placed between shallow pre/post blocks and trained with Jacobian-Free Backpropagation; it converges to a fixed point whose iteration count can be chosen independently at inference.
Load-bearing premise
The implicit equilibrium layer converges reliably under Jacobian-Free Backpropagation and that the per-scale iteration count can be varied post-training without degrading the learned fixed point.
What would settle it
Running the trained VIAR model with iteration counts both higher and lower than those used during training and checking whether FID and sFID remain stable or improve; a large degradation would indicate that the fixed point is not robust to post-training changes in iteration depth.
Figures







read the original abstract
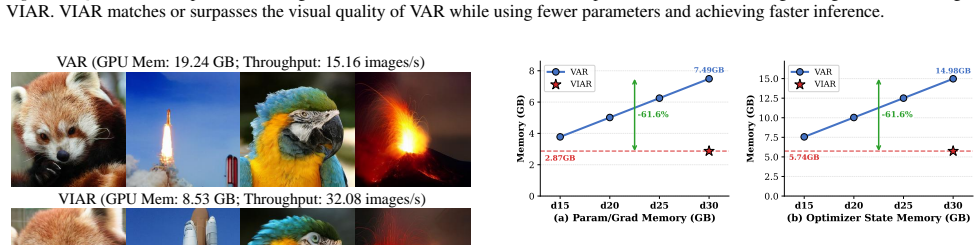
Visual Autoregressive Modeling (VAR) based on next-scale prediction achieves strong generation quality, but their explicit deep stacks fix the amount of computation per scale and inflate memory at high resolutions. We introduce Visual Implicit Autoregressive Modeling (VIAR), a next-scale autoregressive generator that embeds an implicit equilibrium layer between shallow pre/post blocks. The implicit layer is trained with Jacobian-Free Backpropagation, yielding constant training memory, while inference exposes a per-scale iteration knob that enables compute control. On ImageNet 256x256 benchmark, VIAR attains FID 2.16, and sFID 8.07 with only 38.4% parameters of VAR, matching or surpassing strong AR baselines and remaining competitive with large diffusion models. By controlling the per-scale knob, VIAR can reduce peak memory from 19.24 GB to 8.53 GB and doubles throughput from 15.16 to 32.08 images/s on a single RTX 4090, without retraining. Ablations show that fewer steps are sufficient for fixed-point iterations to converge and that VIAR consistently dominates VAR across quality efficiency operating points. In zero shot in-painting and class-conditional editing, VIAR produces sharper details and smoother boundaries while preserving global structure, validating the benefits of implicit equilibria and per-scale compute control for practical, deployable visual generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Visual Implicit Autoregressive Modeling (VIAR), extending next-scale Visual Autoregressive Modeling (VAR) by inserting an implicit equilibrium layer between shallow pre- and post-processing blocks. The layer is trained via Jacobian-Free Backpropagation to keep training memory constant, while inference exposes a tunable per-scale iteration count for compute-quality trade-offs. On ImageNet 256×256 the model reports FID 2.16 and sFID 8.07 at 38.4 % of VAR’s parameter count, together with memory reduction (19.24 GB → 8.53 GB) and doubled throughput (15.16 → 32.08 img/s) on a single RTX 4090 without retraining. Ablations and zero-shot inpainting/editing results are presented to support the benefits of implicit equilibria and per-scale control.
Significance. If the implicit fixed-point convergence and post-training iteration flexibility hold, VIAR would provide a practical mechanism for dynamic compute allocation in autoregressive image generators, improving deployability while remaining competitive with both AR and diffusion baselines. The reported parameter efficiency and memory/throughput gains would constitute a meaningful advance for high-resolution visual generation.
major comments (2)
- [Experiments / Ablations] The central efficiency claims (memory reduction from 19.24 GB to 8.53 GB and throughput doubling) rest on the assumption that the implicit equilibrium layer, trained with Jacobian-Free Backpropagation, reaches a stable fixed point whose quality is insensitive to the number of inference iterations chosen after training. No explicit fixed-point residual curves, convergence-rate analysis, or ablation on iteration-budget sensitivity appear in the reported experiments, leaving the weakest assumption identified in the stress-test note unaddressed.
- [Experiments / Main Results] The headline ImageNet numbers (FID 2.16, sFID 8.07) are presented without the full set of training curves, exact baseline re-implementations, or statistical significance tests that would be required to substantiate the claim of matching or surpassing strong AR baselines at reduced parameter count. The moderate soundness rating in the reader’s assessment follows directly from this omission.
minor comments (2)
- [Abstract] The phrase “zero shot in-painting” in the abstract should be hyphenated as “zero-shot inpainting” for standard terminology.
- [Method] Notation for the implicit layer (e.g., the equilibrium operator and the per-scale iteration variable) should be introduced once in the method section and used consistently thereafter to avoid ambiguity when discussing the inference knob.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential practical benefits of VIAR for controllable inference. We address each major comment below and will incorporate revisions to strengthen the experimental support.
read point-by-point responses
-
Referee: [Experiments / Ablations] The central efficiency claims (memory reduction from 19.24 GB to 8.53 GB and throughput doubling) rest on the assumption that the implicit equilibrium layer, trained with Jacobian-Free Backpropagation, reaches a stable fixed point whose quality is insensitive to the number of inference iterations chosen after training. No explicit fixed-point residual curves, convergence-rate analysis, or ablation on iteration-budget sensitivity appear in the reported experiments, leaving the weakest assumption identified in the stress-test note unaddressed.
Authors: We agree that explicit visualization of fixed-point convergence would directly substantiate the core assumption. The current manuscript already states that 'fewer steps are sufficient for fixed-point iterations to converge' and reports quality-efficiency trade-offs, but we will add (i) per-scale residual curves ||f(x) - x|| over inference iterations, (ii) convergence-rate analysis across scales, and (iii) an ablation table showing FID/sFID as a function of iteration budget (e.g., 1, 3, 5, 10 iterations). These additions will be placed in a new subsection of the experiments and will confirm that quality stabilizes well before the default iteration count used for the headline numbers. revision: yes
-
Referee: [Experiments / Main Results] The headline ImageNet numbers (FID 2.16, sFID 8.07) are presented without the full set of training curves, exact baseline re-implementations, or statistical significance tests that would be required to substantiate the claim of matching or surpassing strong AR baselines at reduced parameter count. The moderate soundness rating in the reader’s assessment follows directly from this omission.
Authors: We acknowledge the value of additional transparency. In the revision we will (i) include training curves (loss and FID) for both VIAR and the VAR baseline in the appendix, (ii) provide exact hyper-parameter tables and code references for all re-implemented baselines, and (iii) report standard deviations from three independent runs for the main VIAR configuration. Full multi-seed statistical tests across every baseline remain computationally expensive; we will therefore note this limitation while still adding the requested curves and variance estimates to support the reported gains. revision: partial
Circularity Check
No significant circularity; derivation relies on new architecture and empirical results
full rationale
The paper defines VIAR via an explicit new component—an implicit equilibrium layer inserted between shallow pre/post blocks, trained with Jacobian-Free Backpropagation to achieve constant memory and expose a post-training per-scale iteration knob. Performance metrics (FID 2.16, sFID 8.07, memory/throughput gains) are presented as direct empirical outcomes on ImageNet 256x256 against VAR baselines and diffusion models, with ablations confirming convergence behavior. No equation, claim, or result in the abstract or described chain reduces a reported prediction or fixed-point quality to a fitted parameter, self-citation, or ansatz imported from the authors' prior work; the central claims remain independent of their inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-scale iteration count
axioms (1)
- domain assumption The implicit layer reaches a stable fixed-point equilibrium under the chosen iteration budget.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[2]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Y ., Zhang, H., Pang, R., Qin, J., Ku, A., Xu, Y ., Baldridge, J., and Wu, Y
Vector-quantized image modeling with improved vqgan , author=. arXiv preprint arXiv:2110.04627 , year=
-
[7]
Advances in neural information processing systems , volume=
Generating diverse high-fidelity images with vq-vae-2 , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Autoregressive image generation using residual quantization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Scaling autoregressive models for content-rich text-to-image generation , author=. arXiv preprint arXiv:2206.10789 , volume=
work page internal anchor Pith review arXiv
-
[10]
Advances in neural information processing systems , volume=
Conditional image generation with pixelcnn decoders , author=. Advances in neural information processing systems , volume=
-
[11]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[12]
Advances in neural information processing systems , volume=
Deep equilibrium models , author=. Advances in neural information processing systems , volume=
-
[13]
Advances in neural information processing systems , volume=
Multiscale deep equilibrium models , author=. Advances in neural information processing systems , volume=
-
[14]
arXiv preprint arXiv:2310.18605 , year=
Torchdeq: A library for deep equilibrium models , author=. arXiv preprint arXiv:2310.18605 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
On training implicit models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Jfb: Jacobian-free backpropagation for implicit networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Fixed point diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Advances in Neural Information Processing Systems , volume=
Deep equilibrium approaches to diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
One-step diffusion distillation via deep equilibrium models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Collaborative decoding makes visual auto-regressive modeling efficient , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[21]
arXiv preprint arXiv:2503.23367 , year=
Fastvar: Linear visual autoregressive modeling via cached token pruning , author=. arXiv preprint arXiv:2503.23367 , year=
-
[22]
Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding , author=. arXiv preprint arXiv:2410.01699 , year=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Grouped speculative decoding for autoregressive image generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
MC-SJD: Maximal Coupling Speculative Jacobi Decoding for Autoregressive Visual Generation Acceleration , author=. arXiv preprint arXiv:2510.24211 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2510.08994 , year=
Speculative Jacobi-Denoising Decoding for Accelerating Autoregressive Text-to-image Generation , author=. arXiv preprint arXiv:2510.08994 , year=
-
[26]
arXiv preprint arXiv:2512.16483 , year=
StageVAR: Stage-Aware Acceleration for Visual Autoregressive Models , author=. arXiv preprint arXiv:2512.16483 , year=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Frequency-aware autoregressive modeling for efficient high-resolution image synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
arXiv preprint arXiv:2506.08908 , year=
SkipVAR: Accelerating Visual Autoregressive Modeling via Adaptive Frequency-Aware Skipping , author=. arXiv preprint arXiv:2506.08908 , year=
-
[29]
arXiv preprint arXiv:2505.19602 , year=
Memory-Efficient Visual Autoregressive Modeling with Scale-Aware KV Cache Compression , author=. arXiv preprint arXiv:2505.19602 , year=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deep equilibrium optical flow estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[32]
Advances in neural information processing systems , volume=
Improved techniques for training gans , author=. Advances in neural information processing systems , volume=
-
[33]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[34]
2024 , note=
Large-DiT-ImageNet , howpublished=. 2024 , note=
2024
-
[35]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.