Recognition: unknown
Lost in the Tower of Babel: The Adverse Effects of Incidental Multilingualism in LLMs
Pith reviewed 2026-05-09 15:14 UTC · model grok-4.3
The pith
LLMs appear multilingual only because of uneven web training data, producing unreliable behavior across languages
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contemporary multilingual NLP has converged on a fragile paradigm of incidental multilingualism: LLMs appear multilingual largely because they are trained on massive, uneven web corpora, not because multilingual or multicultural competence has been treated as a core design objective. This paradigm systematically produces unequal, brittle, and opaque behavior across languages, with severe consequences in real-world and agentic deployments where models must reason, plan, and act across multiple linguistic contexts.
What carries the argument
Incidental multilingualism: multilingual capability that emerges from training on uneven web-scale data collections without any explicit objective for equitable performance or cultural grounding across languages
If this is right
- Models will continue to produce unpredictable or unsafe outputs in any deployment that requires consistent reasoning when the language of input changes.
- Agentic systems that plan and act across linguistic contexts will inherit hidden assumptions about language that can be triggered by simple prompt shifts.
- Self-reported language lists in model documentation will remain unreliable indicators of actual capability.
- Research must prioritize equitable multilingual performance, cultural grounding, and cross-lingual behavioral understanding as first-class goals in every stage of the model pipeline.
Where Pith is reading between the lines
- Balanced data curation at training time may be required to reduce the brittleness that incidental web-scale data produces.
- Application developers should verify actual language behavior through targeted tests instead of trusting model self-descriptions.
- The same incidental-training pattern could create parallel problems in other modalities such as vision-language models trained on uneven image-text pairs.
Load-bearing premise
That the observed gaps between self-reported language support and actual model behavior are caused primarily by incidental data imbalance rather than by architecture, training methods, or other factors.
What would settle it
An experiment that trains an otherwise identical model on deliberately balanced multilingual data and measures whether performance equalizes and language-change attacks lose their effect.
Figures


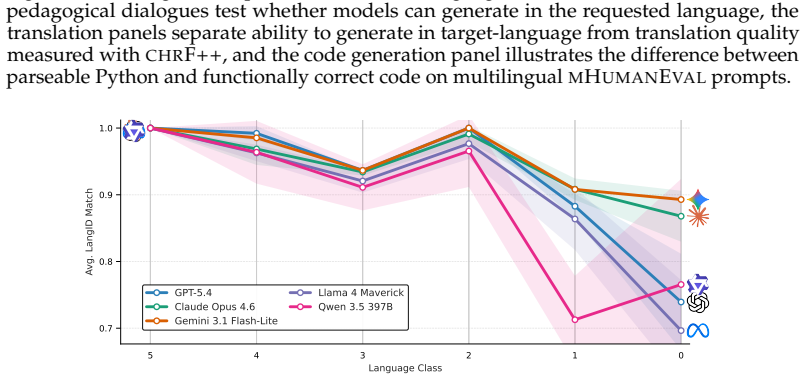




read the original abstract
This paper argues that contemporary multilingual NLP has converged on a fragile and misleading paradigm of incidental multilingualism. Today's LLMs appear multilingual largely because they are trained on massive, uneven web corpora, not because multilingual or multicultural competence has been treated as a core design objective. We contend that this paradigm systematically produces unequal, brittle, and opaque behavior across languages, with severe consequences in real-world and agentic deployments where models must reason, plan, and act across multiple linguistic contexts. We report a focused empirical study of two practical questions: which languages models self-report as supported and which languages they actually respond in across multilingual prompts. We additionally demonstrate how even a simple language-change attack can surface these failures and expose hidden assumptions about language in LLM-based systems. To address this, we call for a shift toward multilingualism by design: a research agenda that treats equitable multilingual performance, cultural grounding, and cross-lingual behavioral understanding as first-class goals in all aspects of the model pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contemporary LLMs exhibit multilingual capabilities primarily due to incidental training on massive, uneven web corpora rather than deliberate design for multilingual or multicultural competence. This 'incidental multilingualism' paradigm is argued to systematically produce unequal, brittle, and opaque behavior across languages, with severe consequences for real-world and agentic deployments. The authors support this via a focused empirical study comparing models' self-reported language support to their actual response languages under multilingual prompts, plus demonstrations of simple language-change attacks that expose hidden assumptions. They conclude by calling for a shift to 'multilingualism by design' treating equitable performance, cultural grounding, and cross-lingual understanding as first-class objectives.
Significance. If the central empirical claims hold after strengthening controls, the work would have notable significance for multilingual NLP by providing concrete evidence of practical failures and advocating a deliberate research agenda shift away from data-imbalance reliance. The focused study on self-report vs. actual use and the attack surface demonstrations are useful contributions that could inform safer agentic systems. The paper's strength is its clear framing of the issue and call for pipeline-wide changes, though this depends on isolating the causal role of incidental data.
major comments (2)
- [Empirical Study] Empirical Study section: The reported study on self-reported versus actual language use and language-change attacks demonstrates failures but provides no ablation studies, comparisons to balanced-data variants, multilingual-pretrained baselines, or architecture-matched controls. This leaves the attribution of unequal/brittle/opaque behavior specifically to incidental multilingualism from uneven web corpora unisolated, which is load-bearing for the central claim that the current paradigm 'systematically produces' these issues and necessitates a full 'by design' shift.
- [Discussion] Discussion/Implications section: The assertion of 'severe consequences in real-world and agentic deployments' where models must reason/plan/act across languages is not supported by specific quantitative impact measures, case studies, or tests beyond the attack demonstrations; without this, the load-bearing claim of systematic real-world harm remains under-evidenced.
minor comments (3)
- [Abstract] Abstract: Include brief specifics on models tested, languages covered, quantitative metrics, and sample sizes from the empirical study to allow assessment of the findings' scale and generalizability.
- [Introduction] Terminology: Provide an explicit definition of 'incidental multilingualism' in the introduction to ensure consistent usage and distinguish it clearly from other factors like architecture or objectives.
- [Related Work] Related Work: Expand citations to include recent studies on multilingual data imbalances, cross-lingual transfer failures, and robustness attacks for better grounding.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, clarifying our approach and indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Empirical Study] Empirical Study section: The reported study on self-reported versus actual language use and language-change attacks demonstrates failures but provides no ablation studies, comparisons to balanced-data variants, multilingual-pretrained baselines, or architecture-matched controls. This leaves the attribution of unequal/brittle/opaque behavior specifically to incidental multilingualism from uneven web corpora unisolated, which is load-bearing for the central claim that the current paradigm 'systematically produces' these issues and necessitates a full 'by design' shift.
Authors: We acknowledge that our study is observational rather than a controlled causal experiment. All contemporary LLMs are trained under the incidental multilingualism paradigm on uneven web data, so balanced-data variants, dedicated multilingual baselines, or architecture-matched controls trained from scratch do not exist in the literature and would require new large-scale training runs outside the scope of this work. The empirical contribution instead lies in documenting consistent discrepancies between self-reported and actual language use, along with the success of simple language-change attacks, across multiple models. This pattern supports the claim that the prevailing incidental approach systematically yields the described behaviors. We will revise the Discussion to explicitly state this observational scope, note the practical barriers to stronger controls, and frame the results as evidence of outcomes under the current paradigm rather than a definitive isolation of causality. This will be a partial revision. revision: partial
-
Referee: [Discussion] Discussion/Implications section: The assertion of 'severe consequences in real-world and agentic deployments' where models must reason/plan/act across languages is not supported by specific quantitative impact measures, case studies, or tests beyond the attack demonstrations; without this, the load-bearing claim of systematic real-world harm remains under-evidenced.
Authors: The language-change attacks function as targeted case studies showing how incidental multilingualism produces brittle cross-lingual behavior, such as inconsistent reasoning or output failures when language context shifts—directly relevant to agentic systems that must operate across languages. While we do not include large-scale quantitative deployment metrics (which would require extensive real-world testing beyond this paper), the attacks provide concrete, reproducible demonstrations of the risks. We will expand the Implications section to elaborate on these consequences with additional examples drawn from the attacks and to explicitly call for future work on quantitative impact measures. This will be a partial revision. revision: partial
Circularity Check
No significant circularity; empirical critique is self-contained
full rationale
The paper advances a position argument supported by a focused empirical study on LLM language self-reporting, actual response behavior, and language-change attacks. It contains no mathematical derivations, equations, fitted parameters, or predictive claims that reduce to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises; the central contention that multilingual behavior arises incidentally from web data is framed as an interpretive critique rather than a derived result. The argument is therefore independent of the patterns that would trigger circularity under the specified criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multilingual capabilities in contemporary LLMs arise incidentally from training on massive, uneven web corpora rather than from treating multilingual or multicultural competence as a core design objective.
Reference graph
Works this paper leans on
-
[1]
Balachandran, Vidhisha and Pagnoni, Artidoro and Lee, Jay Yoon and Rajagopal, Dheeraj and Carbonell, Jaime and Tsvetkov, Yulia , booktitle=
-
[2]
Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics , pages=
Augmenting translation models with simulated acoustic confusions for improved spoken language translation , author=. Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[3]
Journal of Artificial Intelligence Research (JAIR) , volume=
Cross-lingual bridges with models of lexical borrowing , author=. Journal of Artificial Intelligence Research (JAIR) , volume=
-
[4]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Unsupervised Discovery of Implicit Gender Bias , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[5]
2017 , publisher=
Internet research ethics for the social age: New challenges, cases, and contexts , author=. 2017 , publisher=
2017
-
[6]
Beyond the
Vitak, Jessica and Shilton, Katie and Ashktorab, Zahra , booktitle=. Beyond the. 2016 , organization=
2016
-
[7]
Aberdeen: University of Aberdeen , year=
Social media research: A guide to ethics , author=. Aberdeen: University of Aberdeen , year=
-
[8]
A Practitioner’s Guide to Ethical Web Data Collection , url=. The Oxford Handbook of Networked Communication , author=. 2018 , month=. doi:10.1093/oxfordhb/9780190460518.013.27 , abstractNote=
-
[9]
Ethical decision-making and internet research: Version 2.0
Markham, Annette and Buchanan, Elizabeth , journal=. Ethical decision-making and internet research: Version 2.0. recommendations from the
-
[10]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Neural Machine Translation of Rare Words with Subword Units , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Balancing Training for Multilingual Neural Machine Translation
Wang, Xinyi and Tsvetkov, Yulia and Neubig, Graham. Balancing Training for Multilingual Neural Machine Translation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020
2020
-
[12]
Yulia Tsvetkov and Alan Black , title =
-
[13]
Graham Neubig and Yulia Tsvetkov and Alan Black , title =
-
[14]
Antonios Anastasopoulos , title =
-
[15]
Ranking Transfer Languages with Pragmatically-Motivated Features for Multilingual Sentiment Analysis , author=. Proc. EACL , year=
-
[16]
A Deep Reinforced Model for Cross-Lingual Summarization with Bilingual Semantic Similarity Reward , author =. Proc. WNGT , year =
-
[17]
Transactions of the Association for Computational Linguistics , year=
Native Language Cognate Effects on Second Language Lexical Choice , author=. Transactions of the Association for Computational Linguistics , year=
-
[18]
Demoting Racial Bias in Hate Speech Detection
Xia, Mengzhou and Field, Anjalie and Tsvetkov, Yulia. Demoting Racial Bias in Hate Speech Detection. Proceedings of the Eighth International Workshop on Natural Language Processing for Social Media. 2020
2020
-
[19]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Fortifying Toxic Speech Detectors Against Veiled Toxicity , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2020
-
[20]
Explaining Black Box Predictions and Unveiling Data Artifacts through Influence Functions , author =. Proc. ACL , year =
-
[21]
Proceedings of the Society for Computation in Linguistics ( SC i L ) 2020
What Code-Switching Strategies are Effective in Dialogue Systems? , author=. Proceedings of the Society for Computation in Linguistics ( SC i L ) 2020. 2020
2020
-
[22]
and Carbonell, Jaime G
Chaudhary, Aditi and Salesky, Elizabeth and Bhat, Gayatri and Mortensen, David R. and Carbonell, Jaime G. and Tsvetkov, Yulia , booktitle=
-
[23]
Measuring Bias in Contextualized Word Representations , author=. Proc. of Workshop on Gender Bias for NLP , year=
-
[24]
International Conference on Learning Representations , year=
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , author=. International Conference on Learning Representations , year=
-
[25]
International Conference on Learning Representations , year=
A Probabilistic Formulation of Unsupervised Text Style Transfer , author=. International Conference on Learning Representations , year=
-
[26]
and Artzi, Yoav , booktitle=
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q. and Artzi, Yoav , booktitle=
-
[27]
Kumar, Sachin and Tsvetkov, Yulia , booktitle=. Von. 2019 , month =
2019
-
[28]
Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017) , pages=
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I. Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017) , pages=
2017
-
[29]
International Conference on Machine Learning , pages=
Structured prediction energy networks , author=. International Conference on Machine Learning , pages=
-
[30]
International Conference on Machine Learning , pages=
End-to-End Learning for Structured Prediction Energy Networks , author=. International Conference on Machine Learning , pages=
-
[31]
Adversarial Semantic Collisions
Song, Congzheng and Rush, Alexander and Shmatikov, Vitaly. Adversarial Semantic Collisions. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.344
-
[32]
A Neural Algorithm of Artistic Style
A neural algorithm of artistic style , author=. arXiv preprint arXiv:1508.06576 , year=
-
[33]
and Sun, Yu and Kolkin, Nicholas I
Kusner, Matt J. and Sun, Yu and Kolkin, Nicholas I. and Weinberger, Kilian Q. , title =. Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37 , pages =. 2015 , publisher =
2015
-
[34]
Shakespearizing Modern Language Using Copy-Enriched Sequence to Sequence Models
Jhamtani, Harsh and Gangal, Varun and Hovy, Eduard and Nyberg, Eric. Shakespearizing Modern Language Using Copy-Enriched Sequence to Sequence Models. Proceedings of the Workshop on Stylistic Variation. 2017. doi:10.18653/v1/W17-4902
-
[35]
Towards Decoding as Continuous Optimisation in Neural Machine Translation
Hoang, Cong Duy Vu and Haffari, Gholamreza and Cohn, Trevor. Towards Decoding as Continuous Optimisation in Neural Machine Translation. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1014
-
[36]
International Conference on Machine Learning , pages=
Toward Controlled Generation of Text , author=. International Conference on Machine Learning , pages=
-
[37]
International Conference on Learning Representations , year=
Multiple-Attribute Text Rewriting , author=. International Conference on Learning Representations , year=
-
[38]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Style Transfer Through Back-Translation , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
International Conference on Machine Learning , pages=
On variational learning of controllable representations for text without supervision , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[40]
Riley, Parker and Constant, Noah and Guo, Mandy and Kumar, Girish and Uthus, David and Parekh, Zarana , journal=
-
[41]
Parameter-efficient transfer learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , journal=. Parameter-efficient transfer learning for
-
[42]
Simple, scalable adaptation for neural machine translation.arXiv preprint arXiv:1909.08478,
Simple, scalable adaptation for neural machine translation , author=. arXiv preprint arXiv:1909.08478 , year=
-
[43]
arXiv preprint arXiv:2006.09336 , year=
Ranking Transfer Languages with Pragmatically-Motivated Features for Multilingual Sentiment Analysis , author=. arXiv preprint arXiv:2006.09336 , year=
-
[44]
arXiv preprint arXiv:2012.01687 , year=
Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition , author=. arXiv preprint arXiv:2012.01687 , year=
-
[45]
International Conference on Learning Representations , year=
Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models , author=. International Conference on Learning Representations , year=
-
[46]
International Conference on Machine Learning , pages=
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[47]
Advances in Neural Information Processing Systems , pages=
Multi-task learning as multi-objective optimization , author=. Advances in Neural Information Processing Systems , pages=
-
[48]
Meta-Learning with Warped Gradient Descent , author=. Proc. ICLR , year=
-
[49]
Gradient surgery for multi-task learning,
Gradient surgery for multi-task learning , author=. arXiv preprint arXiv:2001.06782 , year=
-
[50]
and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , title =
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , title =. 2017 , doi =
2017
-
[51]
Characterizing and avoiding negative transfer , author=. Proc. CVPR , pages=
-
[52]
Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun and Htut, Phu Mon and Zhang, Xiaoyi and Pang, Richard Yuanzhe and Vania, Clara and Kann, Katharina and Bowman, Samuel R. Intermediate-Task Transfer Learning with Pretrained Language Models: When and Why Does It Work?. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020
2020
-
[53]
and Tsvetkov, Yulia
Wang, Zirui and Lipton, Zachary C. and Tsvetkov, Yulia. On Negative Interference in Multilingual Models: Findings and A Meta-Learning Treatment. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020
2020
-
[54]
Massively multilingual neural machine translation in the wild: Findings and challenges , author=
-
[55]
An Overview of Multi-Task Learning in Deep Neural Networks
An overview of multi-task learning in deep neural networks , author=. arXiv preprint arXiv:1706.05098 , year=
work page internal anchor Pith review arXiv
-
[56]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020
2020
-
[57]
How Multilingual is Multilingual
Pires, Telmo and Schlinger, Eva and Garrette, Dan , booktitle=. How Multilingual is Multilingual
-
[58]
Wu, Shijie and Dredze, Mark , booktitle=
-
[59]
Hu, Junjie and Ruder, Sebastian and Siddhant, Aditya and Neubig, Graham and Firat, Orhan and Johnson, Melvin , journal=
-
[60]
Minimally Supervised Morphological Analysis by Multimodal Alignment
Yarowsky, David and Wicentowski, Richard. Minimally Supervised Morphological Analysis by Multimodal Alignment. Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics. 2000. doi:10.3115/1075218.1075245
-
[61]
75 Languages, 1 Model: Parsing Universal Dependencies Universally
Kondratyuk, Dan and Straka, Milan. 75 Languages, 1 Model: Parsing Universal Dependencies Universally. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1279
-
[62]
arXiv preprint arXiv:1907.05774 , year=
Hello, It's GPT-2--How Can I Help You? Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems , author=. arXiv preprint arXiv:1907.05774 , year=
-
[63]
2020 , booktitle=
Language models are few-shot learners , author=. 2020 , booktitle=
2020
-
[64]
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[65]
Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation
Zhang, Biao and Williams, Philip and Titov, Ivan and Sennrich, Rico. Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.148
-
[66]
Advances in Neural Information Processing Systems , pages=
Probabilistic model-agnostic meta-learning , author=. Advances in Neural Information Processing Systems , pages=
-
[67]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks , author=
-
[68]
On the Cross-lingual Transferability of Monolingual Representations
Artetxe, Mikel and Ruder, Sebastian and Yogatama, Dani. On the Cross-lingual Transferability of Monolingual Representations. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.421
-
[69]
Leveraging translations for speech transcription in low-resource settings
Anastasopoulos, Antonios and Chiang, David. Leveraging translations for speech transcription in low-resource settings. Proc. INTERSPEECH. 2018
2018
-
[70]
Part-of-Speech Tagging on an Endangered Language: a Parallel Griko-Italian Resource
Anastasopoulos, Antonios and Lekakou, Marika and Quer, Josep and Zimianiti, Eleni and DeBenedetto, Justin and Chiang, David. Part-of-Speech Tagging on an Endangered Language: a Parallel Griko-Italian Resource. Proc. COLING. 2018
2018
-
[71]
2014 , publisher=
PHOIBLE online , author=. 2014 , publisher=
2014
-
[72]
Futrell, Richard and Dyer, William and Scontras, Greg. What determines the order of adjectives in E nglish? Comparing efficiency-based theories using dependency treebanks. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.181
-
[73]
A Hierarchical Phrase-Based Model for Statistical Machine Translation
Chiang, David. A Hierarchical Phrase-Based Model for Statistical Machine Translation. Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics ( ACL ' 05). 2005. doi:10.3115/1219840.1219873
-
[74]
Combining Character and Word Information in Neural Machine Translation Using a Multi-Level Attention
Chen, Huadong and Huang, Shujian and Chiang, David and Dai, Xinyu and Chen, Jiajun. Combining Character and Word Information in Neural Machine Translation Using a Multi-Level Attention. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 20...
-
[75]
Reversing Language Shift: Can
Anonby, Stan J , year=. Reversing Language Shift: Can
-
[76]
Finite-state morphology for K wak ' wala: A phonological approach
Littell, Patrick. Finite-state morphology for K wak ' wala: A phonological approach. Proceedings of the Workshop on Computational Modeling of Polysynthetic Languages. 2018
2018
-
[77]
Factor Graph Grammars
David Chiang and Darcey Riley. Factor Graph Grammars. Proc. Conference on Neural Information Processing Systems
-
[78]
Translating Recursive Probabilistic Programs to Factor Graph Grammars
David Chiang and Chung-Chieh Shan. Translating Recursive Probabilistic Programs to Factor Graph Grammars
-
[79]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Contextual Parameter Generation for Universal Neural Machine Translation , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[80]
Demographic Dialectal Variation in Social Media: A Case Study of A frican- A merican E nglish
Blodgett, Su Lin and Green, Lisa and O ' Connor, Brendan. Demographic Dialectal Variation in Social Media: A Case Study of A frican- A merican E nglish. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1120
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.