Recognition: unknown
Degradation-Aware Adaptive Context Gating for Unified Image Restoration
Pith reviewed 2026-05-09 15:07 UTC · model grok-4.3
The pith
A degradation-aware gating mechanism lets one model restore images under many different degradation types by dynamically adjusting its features layer by layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DACG-IR constructs degradation-aware contextual representations from the input to modulate attention distribution, frequency-domain features, and feature aggregation. A lightweight multi-scale degradation-aware module extracts coarse degradation information and generates layer-wise prompts that guide attention temperature and output gating in encoder and decoder blocks. A spatial-channel dual-gated adaptive fusion mechanism refines encoder features to suppress noise propagation from shallow to deep layers.
What carries the argument
Degradation-Aware Adaptive Context Gating (DACG), which uses prompts from a multi-scale module to control attention temperature, output gating, and dual-gated spatial-channel fusion at each network layer.
If this is right
- A single model can handle single-task restoration, all-in-one restoration, adverse weather removal, and composite degradations without task interference.
- Layer-wise prompts derived from coarse degradation cues suppress noise propagation through encoder features.
- The same architecture improves frequency-domain feature handling and attention distribution for each input.
- Performance exceeds prior state-of-the-art methods across the evaluated restoration settings.
Where Pith is reading between the lines
- Practical camera or video pipelines could use one restoration network instead of switching among several specialized models when degradation type is unknown in advance.
- The prompt-generation idea might transfer to other conditional multi-task vision settings where the model must adapt its behavior without explicit task labels.
- If the coarse degradation extractor proves robust to unseen degradation combinations, it reduces the need for exhaustive task-specific training data in unified models.
Load-bearing premise
The lightweight multi-scale degradation-aware module can reliably extract coarse degradation information from arbitrary inputs and generate effective layer-wise prompts without introducing new artifacts or needing task-specific supervision.
What would settle it
Remove the degradation-aware module and prompts entirely, then retrain and re-evaluate on the same all-in-one and composite-degradation test sets; if performance falls to the level of standard unified baselines without any gain, the gating contribution is not essential.
Figures





read the original abstract
Unified image restoration using a single model often faces task interference due to diverse degradations. To address this, we propose DACG-IR (Degradation-Aware Adaptive Context Gating), which enables explicit perception of degradation characteristics to dynamically modulate feature representations. Our method constructs degradation-aware contextual representations from the input to modulate attention distribution, frequency-domain features, and feature aggregation. Specifically, a lightweight multi-scale degradation-aware module extracts coarse degradation information and generates layer-wise prompts. These prompts guide attention temperature and output gating in encoder and decoder blocks for adaptive feature extraction. Additionally, a spatial-channel dual-gated adaptive fusion mechanism refines encoder features, suppressing noise propagation from shallow to deep layers. This design effectively suppresses degradation-induced noise while preserving informative structures. Experiments show DACG-IR outperforms state-of-the-art methods in single-task, all-in-one, adverse weather removal, and composite degradation settings. Code: https://github.com/HlHomes/DACG-IR-code
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DACG-IR, a unified image restoration architecture that employs a lightweight multi-scale degradation-aware module to extract coarse degradation characteristics from input images and generate layer-wise prompts. These prompts adaptively modulate attention temperature, output gating in encoder/decoder blocks, and a spatial-channel dual-gated fusion mechanism to suppress noise while preserving structures. The method is evaluated on single-task restoration, all-in-one restoration, adverse weather removal, and composite degradation scenarios, where it is reported to outperform existing state-of-the-art approaches.
Significance. If the reported gains are reproducible and attributable to the proposed degradation-aware gating rather than training artifacts or dataset biases, the work could meaningfully advance unified restoration models by providing an explicit, lightweight mechanism for handling diverse and mixed degradations without task-specific supervision. The public code release supports reproducibility and is a clear strength.
major comments (2)
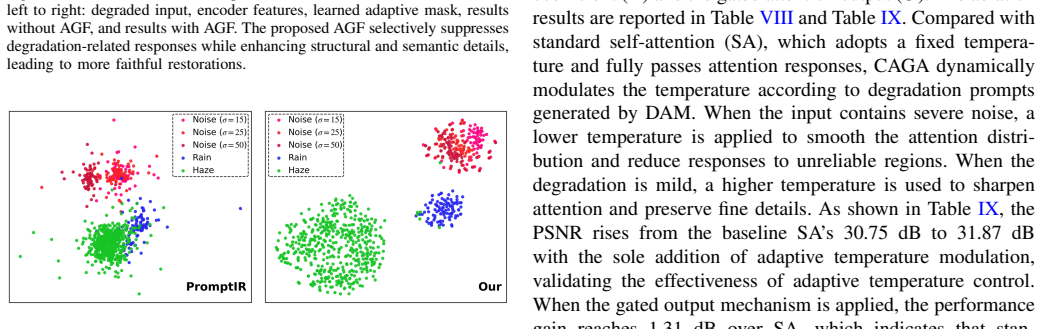
- [§3.1] §3.1 (Degradation-Aware Module): The central outperformance claim across all-in-one and composite settings depends on the module reliably extracting usable coarse degradation information and producing artifact-free layer-wise prompts for arbitrary inputs. The manuscript describes the architecture but provides no ablation isolating prompt quality, no failure-case analysis for composite degradations, and no visualization of generated prompts, leaving open the possibility that gains arise from other components or training choices rather than this module.
- [§4] §4 (Experiments): While quantitative results are presented for multiple settings, the paper does not report statistical significance tests, variance across multiple runs, or controls for hyperparameter tuning differences versus baselines, which weakens the strength of the cross-setting superiority claim.
minor comments (2)
- Notation for the prompt generation and gating operations could be more explicitly defined with equations to improve clarity for readers implementing the method.
- Figure captions for qualitative results should explicitly state the degradation types and input conditions shown to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, outlining the revisions we will make to strengthen the manuscript while maintaining scientific honesty.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Degradation-Aware Module): The central outperformance claim across all-in-one and composite settings depends on the module reliably extracting usable coarse degradation information and producing artifact-free layer-wise prompts for arbitrary inputs. The manuscript describes the architecture but provides no ablation isolating prompt quality, no failure-case analysis for composite degradations, and no visualization of generated prompts, leaving open the possibility that gains arise from other components or training choices rather than this module.
Authors: We acknowledge the validity of this concern. The current manuscript relies on overall performance gains without direct evidence isolating the degradation-aware module's contribution. In the revised manuscript, we will add visualizations of the generated prompts for single and composite degradations to demonstrate their structure and artifact-free properties. We will also include a new ablation study replacing the learned prompts with fixed or random alternatives to quantify their impact. Additionally, we will present failure-case examples for challenging composite degradations with qualitative analysis. These changes will provide stronger attribution of gains to the proposed module. revision: yes
-
Referee: [§4] §4 (Experiments): While quantitative results are presented for multiple settings, the paper does not report statistical significance tests, variance across multiple runs, or controls for hyperparameter tuning differences versus baselines, which weakens the strength of the cross-setting superiority claim.
Authors: We agree that reporting variability and statistical tests would improve the robustness of the claims. In the revision, we will rerun the primary experiments across multiple random seeds (reporting mean and standard deviation) and include statistical significance tests such as paired t-tests or Wilcoxon signed-rank tests against baselines. Regarding hyperparameter controls, we used the official implementations and recommended settings from the baseline papers to ensure fairness; however, performing exhaustive tuning for every baseline is computationally prohibitive. We will expand the experimental section with a clearer description of training protocols and note this limitation explicitly. revision: partial
Circularity Check
Empirical architectural proposal with no derivations or self-referential reductions
full rationale
The paper is a standard deep-learning architecture proposal for unified image restoration. It introduces DACG-IR with components such as a lightweight multi-scale degradation-aware module and spatial-channel dual-gated adaptive fusion, then reports experimental outperformance on single-task, all-in-one, adverse-weather, and composite-degradation benchmarks. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. Performance claims rest on empirical comparisons rather than any reduction of outputs to inputs by construction. No self-citations are used as load-bearing premises. The work is therefore self-contained against external benchmarks and exhibits no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on all-in- one image restoration: Taxonomy, evaluation and future trends,
J. Jiang, Z. Zuo, G. Wu, K. Jiang, and X. Liu, “A survey on all-in- one image restoration: Taxonomy, evaluation and future trends,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 12, pp. 11 892–11 911, 2025
2025
-
[2]
Desnownet: Context-aware deep network for snow removal,
Y .-F. Liu, D.-W. Jaw, S.-C. Huang, and J.-N. Hwang, “Desnownet: Context-aware deep network for snow removal,”IEEE Transactions on Image Processing, vol. 27, no. 6, pp. 3064–3073, 2018
2018
-
[3]
All snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and con- tradict channel loss,
W.-T. Chen, H.-Y . Fang, C.-L. Hsieh, C.-C. Tsai, I.-H. Chen, J.-J. Ding, and S.-Y . Kuo, “All snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and con- tradict channel loss,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 4196–4205
2021
-
[4]
Uformer: A general u-shaped transformer for image restoration,
Z. Wang, X. Cun, J. Bao, W. Zhou, J. Liu, and H. Li, “Uformer: A general u-shaped transformer for image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 17 683–17 693
2022
-
[5]
Vision transformers for single image dehazing,
Y . Song, Z. He, H. Qian, and X. Du, “Vision transformers for single image dehazing,”IEEE Transactions on Image Processing, vol. 32, pp. 1927–1941, 2023
1927
-
[6]
Deformation models for image recognition,
D. Keysers, T. Deselaers, C. Gollan, and H. Ney, “Deformation models for image recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 8, pp. 1422–1435, 2007
2007
-
[7]
Object detection in 20 years: A survey,
Z. Zou, K. Chen, Z. Shi, Y . Guo, and J. Ye, “Object detection in 20 years: A survey,”Proceedings of the IEEE, vol. 111, no. 3, pp. 257–276, 2023
2023
-
[8]
Dancetrack: Multi-object tracking in uniform appearance and diverse motion,
P. Sun, J. Cao, Y . Jiang, Z. Yuan, S. Bai, K. Kitani, and P. Luo, “Dancetrack: Multi-object tracking in uniform appearance and diverse motion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 20 993–21 002
2022
-
[9]
Deep joint rain detection and removal from a single image,
W. Yang, R. T. Tan, J. Feng, J. Liu, Z. Guo, and S. Yan, “Deep joint rain detection and removal from a single image,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017, pp. 1357–1366. 12
2017
-
[10]
Benchmarking single-image dehazing and beyond,
B. Li, W. Ren, D. Fu, D. Tao, D. Feng, W. Zeng, and Z. Wang, “Benchmarking single-image dehazing and beyond,”IEEE Transactions on Image Processing, vol. 28, no. 1, pp. 492–505, 2019
2019
-
[11]
A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,
D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” inProceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, vol. 2, 2001, pp. 416–423
2001
-
[12]
Delta denoising score,
A. Hertz, K. Aberman, and D. Cohen-Or, “Delta denoising score,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 2328–2337
2023
-
[13]
Deep Retinex Decomposition for Low-Light Enhancement
C. Wei, W. Wang, W. Yang, and J. Liu, “Deep retinex decomposition for low-light enhancement,”arXiv preprint arXiv:1808.04560, 2018
work page Pith review arXiv 2018
-
[14]
Deblurgan: Blind motion deblurring using conditional adversarial net- works,
O. Kupyn, V . Budzan, M. Mykhailych, D. Mishkin, and J. Matas, “Deblurgan: Blind motion deblurring using conditional adversarial net- works,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
2018
-
[15]
Spatial attentive single-image deraining with a high quality real rain dataset,
T. Wang, X. Yang, K. Xu, S. Chen, Q. Zhang, and R. W. Lau, “Spatial attentive single-image deraining with a high quality real rain dataset,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12 270–12 279
2019
-
[16]
M2restore: Mixture-of-experts-based mamba-cnn fusion framework for all-in-one image restoration,
Y . Wang, Y . Li, Z. Zheng, X.-P. Zhang, and M. Wei, “M2restore: Mixture-of-experts-based mamba-cnn fusion framework for all-in-one image restoration,”IEEE Transactions on Image Processing, vol. 34, pp. 8086–8100, 2025
2025
-
[17]
Perceive-ir: Learning to perceive degradation better for all-in-one image restoration,
X. Zhang, J. Ma, G. Wang, Q. Zhang, H. Zhang, and L. Zhang, “Perceive-ir: Learning to perceive degradation better for all-in-one image restoration,”IEEE Transactions on Image Processing, vol. 35, pp. 2018– 2033, 2026
2018
-
[18]
Complexity experts are task-discriminative learners for any image restoration,
E. Zamfir, Z. Wu, N. Mehta, Y . Tan, D. P. Paudel, Y . Zhang, and R. Timofte, “Complexity experts are task-discriminative learners for any image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 12 753–12 763
2025
-
[19]
Degradation-aware feature perturbation for all-in-one image restoration,
X. Tian, X. Liao, X. Liu, M. Li, and C. Ren, “Degradation-aware feature perturbation for all-in-one image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 28 165–28 175
2025
-
[20]
Learning dynamic prompts for all-in-one image restoration,
G. Wu, J. Jiang, K. Jiang, X. Liu, and L. Nie, “Learning dynamic prompts for all-in-one image restoration,”IEEE Transactions on Image Processing, vol. 34, pp. 3997–4010, 2025
2025
-
[21]
Degradation-aware residual- conditioned optimal transport for unified image restoration,
X. Tang, X. Gu, X. He, X. Hu, and J. Sun, “Degradation-aware residual- conditioned optimal transport for unified image restoration,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 8, pp. 6764–6779, 2025
2025
-
[22]
Transweather: Transformer-based restoration of images degraded by adverse weather conditions,
J. M. J. Valanarasu, R. Yasarla, and V . M. Patel, “Transweather: Transformer-based restoration of images degraded by adverse weather conditions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 2353–2363
2022
-
[23]
Image restoration via frequency selection,
Y . Cui, W. Ren, X. Cao, and A. Knoll, “Image restoration via frequency selection,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 46, no. 2, pp. 1093–1108, 2024
2024
-
[24]
Promptir: Prompting for all-in-one image restoration,
V . Potlapalli, S. W. Zamir, S. H. Khan, and F. Shahbaz Khan, “Promptir: Prompting for all-in-one image restoration,” inAdvances in neural information processing systems, vol. 36, 2023, pp. 71 275–71 293
2023
-
[25]
All-in-one image restoration for unknown corruption,
B. Li, X. Liu, P. Hu, Z. Wu, J. Lv, and X. Peng, “All-in-one image restoration for unknown corruption,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 17 452–17 462
2022
-
[26]
Single image super-resolution from transformed self-exemplars,
J.-B. Huang, A. Singh, and N. Ahuja, “Single image super-resolution from transformed self-exemplars,” inProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 5197–5206
2015
-
[27]
Darkir: Robust low-light image restoration,
D. Feijoo, J. C. Benito, A. Garcia, and M. V . Conde, “Darkir: Robust low-light image restoration,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 10 879–10 889
2025
-
[28]
Dehazenet: An end-to-end system for single image haze removal,
B. Cai, X. Xu, K. Jia, C. Qing, and D. Tao, “Dehazenet: An end-to-end system for single image haze removal,”IEEE transactions on image processing, vol. 25, no. 11, pp. 5187–5198, 2016
2016
-
[29]
Attentive generative adversarial network for raindrop removal from a single image,
R. Qian, R. T. Tan, W. Yang, J. Su, and J. Liu, “Attentive generative adversarial network for raindrop removal from a single image,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2482–2491
2018
-
[30]
Simple baselines for image restoration,
L. Chen, X. Chu, X. Zhang, and J. Sun, “Simple baselines for image restoration,” inEuropean conference on computer vision. Springer, 2022, pp. 17–33
2022
-
[31]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 5728–5739
2022
-
[32]
Stripformer: Strip transformer for fast image deblurring,
F.-J. Tsai, Y .-T. Peng, Y .-Y . Lin, C.-C. Tsai, and C.-W. Lin, “Stripformer: Strip transformer for fast image deblurring,” inEuropean conference on computer vision. Springer, 2022, pp. 146–162
2022
-
[33]
Hierarchical integration diffusion model for realistic image deblurring,
Z. Chen, Y . Zhang, D. Liu, J. Gu, L. Kong, X. Yuanet al., “Hierarchical integration diffusion model for realistic image deblurring,” inAdvances in neural information processing systems, vol. 36, 2023, pp. 29 114– 29 125
2023
-
[34]
Multi-stage progressive image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 14 821–14 831
2021
-
[35]
Instructir: High-quality image restoration following human instructions,
M. V . Conde, G. Geigle, and R. Timofte, “Instructir: High-quality image restoration following human instructions,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1–21
2024
-
[36]
Gated fusion network for single image dehazing,
W. Ren, L. Ma, J. Zhang, J. Pan, X. Cao, W. Liu, and M.-H. Yang, “Gated fusion network for single image dehazing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3253–3261
2018
-
[37]
Learning a sparse transformer network for effective image deraining,
X. Chen, H. Li, M. Li, and J. Pan, “Learning a sparse transformer network for effective image deraining,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 5896–5905
2023
-
[38]
Multi-scale progressive fusion network for single image deraining,
K. Jiang, Z. Wang, P. Yi, C. Chen, B. Huang, Y . Luo, J. Ma, and J. Jiang, “Multi-scale progressive fusion network for single image deraining,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8346–8355
2020
-
[39]
From fidelity to perceptual quality: A semi-supervised approach for low-light image en- hancement,
W. Yang, S. Wang, Y . Fang, Y . Wang, and J. Liu, “From fidelity to perceptual quality: A semi-supervised approach for low-light image en- hancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3063–3072
2020
-
[40]
Mwformer: Multi- weather image restoration using degradation-aware transformers,
R. Zhu, Z. Tu, J. Liu, A. C. Bovik, and Y . Fan, “Mwformer: Multi- weather image restoration using degradation-aware transformers,”IEEE Transactions on Image Processing, vol. 33, pp. 6790–6805, 2024
2024
-
[41]
Bio-inspired image restoration,
Y . Cui, W. Ren, and A. Knoll, “Bio-inspired image restoration,” in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[42]
Learning a low-level vision generalist via visual task prompt,
X. Chen, Y . Liu, Y . Pu, W. Zhang, J. Zhou, Y . Qiao, and C. Dong, “Learning a low-level vision generalist via visual task prompt,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 2671–2680
2024
-
[43]
Controlling vision-language models for multi-task image restoration,
Z. Luo, F. K. Gustafsson, Z. Zhao, J. Sj ¨olund, and T. B. Sch ¨on, “Controlling vision-language models for multi-task image restoration,” arXiv preprint arXiv:2310.01018, 2023
-
[44]
Conditional prompt learning for vision-language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learning for vision-language models,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16 816–16 825
2022
-
[45]
Adair: Adaptive all-in-one image restoration via frequency mining and modulation,
Y . Cui, S. W. Zamir, S. Khan, A. Knoll, M. Shah, and F. S. Khan, “Adair: Adaptive all-in-one image restoration via frequency mining and modulation,” in13th international conference on learning representa- tions(ICLR), 2025, pp. 57 335–57 356
2025
-
[46]
Gate-variants of gated recurrent unit (gru) neural networks,
R. Dey and F. M. Salem, “Gate-variants of gated recurrent unit (gru) neural networks,” in2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS). IEEE, 2017, pp. 1597–1600
2017
-
[47]
GLU Variants Improve Transformer
N. Shazeer, “Glu variants improve transformer,”arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review arXiv 2002
-
[48]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Z. Qiu, Z. Wang, B. Zheng, Z. Huang, K. Wen, S. Yang, R. Men, L. Yu, F. Huang, S. Huanget al., “Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free,”arXiv preprint arXiv:2505.06708, 2025
work page internal anchor Pith review arXiv 2025
-
[49]
Contour detection and hierarchical image segmentation,
P. Arbel ´aez, M. Maire, C. Fowlkes, and J. Malik, “Contour detection and hierarchical image segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 5, pp. 898–916, 2011
2011
-
[50]
Waterloo exploration database: New challenges for image quality assessment models,
K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and L. Zhang, “Waterloo exploration database: New challenges for image quality assessment models,”IEEE Transactions on Image Processing, vol. 26, no. 2, pp. 1004–1016, 2016
2016
-
[51]
Deep multi-scale convolutional neural network for dynamic scene deblurring,
S. Nah, T. Hyun Kim, and K. Mu Lee, “Deep multi-scale convolutional neural network for dynamic scene deblurring,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 3883–3891
2017
-
[52]
Kodak lossless true color image suite,
R. Franzen, “Kodak lossless true color image suite,” http://r0k.us/ graphics/kodak/, 1999, accessed: Oct. 24, 2021. 13
1999
-
[53]
All in one bad weather removal using architectural search,
R. Li, R. T. Tan, and L.-F. Cheong, “All in one bad weather removal using architectural search,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3175– 3185
2020
-
[54]
Onerestore: A universal restoration framework for composite degradation,
Y . Guo, Y . Gao, Y . Lu, H. Zhu, R. W. Liu, and S. He, “Onerestore: A universal restoration framework for composite degradation,” inEuropean conference on computer vision. Springer, 2024, pp. 255–272
2024
-
[55]
Mambair: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “Mambair: A simple baseline for image restoration with state-space model,” in European conference on computer vision. Springer, 2024, pp. 222– 241
2024
-
[56]
Neural degradation representation learning for all-in-one image restoration,
M. Yao, R. Xu, Y . Guan, J. Huang, and Z. Xiong, “Neural degradation representation learning for all-in-one image restoration,”IEEE Transac- tions on Image Processing, vol. 33, pp. 5408–5423, 2024
2024
-
[57]
Retinex- former: One-stage retinex-based transformer for low-light image en- hancement,
Y . Cai, H. Bian, J. Lin, H. Wang, R. Timofte, and Y . Zhang, “Retinex- former: One-stage retinex-based transformer for low-light image en- hancement,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 12 504–12 513
2023
-
[58]
Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions,
Y . Zhu, T. Wang, X. Fu, X. Yang, X. Guo, J. Dai, Y . Qiao, and X. Hu, “Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 21 747–21 758
2023
-
[59]
Restoring vision in adverse weather conditions with patch-based denoising diffusion models,
O. ¨Ozdenizci and R. Legenstein, “Restoring vision in adverse weather conditions with patch-based denoising diffusion models,”IEEE Trans- actions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 10 346–10 357, 2023
2023
-
[60]
Self-guided image dehazing using progressive feature fusion,
H. Bai, J. Pan, X. Xiang, and J. Tang, “Self-guided image dehazing using progressive feature fusion,”IEEE Transactions on Image Processing, vol. 31, pp. 1217–1229, 2022
2022
-
[61]
Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions,
T. Wang, K. Zhang, Z. Shao, W. Luo, B. Stenger, T. Lu, T.-K. Kim, W. Liu, and H. Li, “Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions,” International journal of computer vision, vol. 132, no. 10, pp. 4541– 4563, 2024
2024
-
[62]
Heavy rain image restoration: Integrating physics model and conditional adversarial learning,
R. Li, L.-F. Cheong, and R. T. Tan, “Heavy rain image restoration: Integrating physics model and conditional adversarial learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 1633–1642
2019
-
[63]
Swinir: Image restoration using swin transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “Swinir: Image restoration using swin transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, October 2021, pp. 1833–1844
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.