Recognition: unknown
S³-R1: Learning to Retrieve and Answer Step-by-Step with Synthetic Data
Pith reviewed 2026-05-09 15:05 UTC · model grok-4.3
The pith
Coupling synthetic multi-hop questions with rewards for search steps and answers enables models to learn effective retrieval strategies and generalize up to 10% better out of domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
S^3-R1 couples a data-centric synthetic generation pipeline that programmatically derives diverse multi-hop questions from documents with a retrieval-based verification to isolate intermediate difficulty ones, together with a reward structure evaluating both intermediate search quality and final answer correctness, enabling models to learn more effective search and synthesis strategies and achieve improved robust generalization on out-of-domain datasets.
What carries the argument
The synthetic generation and curation pipeline combined with the dual-component reward function that evaluates search quality and answer correctness.
If this is right
- Models learn to conduct deeper searches to collect evidence rather than relying on superficial answers.
- Training data covers questions of varying hardness, preventing collapse to simple strategies.
- Credit assignment improves because intermediate steps receive feedback.
- Performance gains appear in out-of-domain settings, indicating better generalization of search strategies.
- Up to 10% improvement in robust generalization metrics.
Where Pith is reading between the lines
- Applying the same synthetic pipeline to other agentic tasks like code generation or planning could yield similar gains in step-wise reasoning.
- Future work might test whether the intermediate difficulty filter is crucial by comparing to unfiltered synthetic data.
- The approach suggests that reward design focused on process rather than only outcome can stabilize RL for long-horizon tool use.
- Testing on real user queries with known distribution shifts would validate transfer.
Load-bearing premise
The synthetic questions generated and verified are genuinely of intermediate difficulty and do not introduce distribution shifts or artifacts that fail to represent real user queries.
What would settle it
Evaluating the trained model on a held-out set of real human-generated multi-hop questions and finding no improvement over baselines or no evidence of deeper search behavior.
Figures


read the original abstract
Reinforcement learning (RL) post-training has enabled newer capabilities in models, such as agentic tool-use for search. However, these models struggle primarily due to limitations with sparse outcome-based rewards and a lack of training data that encapsulates questions of differing hardness, which results in models not performing deeper searches with tools to collect evidence for question-answering. To address these limitations, we introduce S^3-R1 (Synthetic data and stabilized Search R1), a framework that couples a data-centric approach with denser learning signals. We first develop a synthetic generation and curation pipeline that programmatically derives diverse, multi-hop questions from existing documents. This pipeline incorporates a retrieval-based verification step to specifically isolate questions of intermediate difficulty. We then pair this expanded training set with a reward structure that evaluates both intermediate search quality and the correctness of the final answer. This setup directly mitigates the credit assignment problems inherent to sparse rewards. Our evaluations show that S^3-R1 outperforms existing baselines by learning more effective search and synthesis strategies, yielding up to a 10% improvement in robust generalization on out-of-domain datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S^3-R1, a framework that combines a synthetic data generation pipeline for creating diverse multi-hop questions from documents (with retrieval-based verification to isolate intermediate-difficulty examples) and a denser reward structure evaluating both intermediate search quality and final answer correctness. This is applied to RL post-training of language models for agentic retrieval and QA tasks. The central claim is that the approach mitigates sparse rewards and limited hardness variation, enabling more effective search and synthesis strategies that yield up to 10% improvement in robust generalization on out-of-domain datasets relative to baselines.
Significance. If the empirical results hold after verification of the experimental details, this work offers a practical data-centric method to improve credit assignment in RL for tool-using models, addressing a key bottleneck in scaling agentic capabilities. The combination of programmatically generated multi-hop questions and intermediate rewards is a concrete contribution that could generalize beyond the specific QA setting, particularly for tasks requiring evidence synthesis. The focus on out-of-domain robustness is a strength, as is the explicit attempt to control question difficulty via retrieval verification.
major comments (2)
- [Evaluations] Evaluations section: The headline claim of up to 10% improvement on out-of-domain datasets is presented without specifying the exact baselines, number of runs, statistical significance testing, or the precise mathematical formulation of the combined reward (intermediate search quality plus final answer). These omissions make it impossible to assess whether the gains are robust or attributable to the proposed pipeline rather than implementation details.
- [Synthetic data generation pipeline] Synthetic data generation pipeline: The retrieval-based verification step is asserted to isolate questions of intermediate difficulty that transfer without distribution shift or artifacts, but no supporting analysis (e.g., entity-overlap statistics, reasoning-chain predictability metrics, or human validation comparing synthetic vs. real user queries) is provided. If this step systematically favors high-overlap or predictable chains, the denser reward could exploit synthetic regularities rather than learn genuine search strategies, undermining the generalization claim.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the reward function components (e.g., how intermediate search quality is scored) to allow readers to immediately grasp the denser signal mechanism.
- [Method] Notation for the synthetic pipeline components (e.g., question generator, verifier) should be introduced consistently with a diagram or pseudocode to improve clarity of the multi-step curation process.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript would benefit from greater clarity in the evaluations and additional supporting analysis for the synthetic data pipeline. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluations] Evaluations section: The headline claim of up to 10% improvement on out-of-domain datasets is presented without specifying the exact baselines, number of runs, statistical significance testing, or the precise mathematical formulation of the combined reward (intermediate search quality plus final answer). These omissions make it impossible to assess whether the gains are robust or attributable to the proposed pipeline rather than implementation details.
Authors: We agree that the evaluations section requires more explicit details for full reproducibility and assessment. In the revised manuscript, we will specify all baselines (including model versions and training configurations), report results over multiple independent runs with standard deviations, include statistical significance testing, and provide the exact mathematical formulation of the combined reward. These changes will clarify that the reported gains are attributable to the S^3-R1 pipeline rather than implementation specifics. revision: yes
-
Referee: [Synthetic data generation pipeline] Synthetic data generation pipeline: The retrieval-based verification step is asserted to isolate questions of intermediate difficulty that transfer without distribution shift or artifacts, but no supporting analysis (e.g., entity-overlap statistics, reasoning-chain predictability metrics, or human validation comparing synthetic vs. real user queries) is provided. If this step systematically favors high-overlap or predictable chains, the denser reward could exploit synthetic regularities rather than learn genuine search strategies, undermining the generalization claim.
Authors: We acknowledge that the original submission lacked explicit supporting analysis for the retrieval-based verification step. In the revised manuscript, we will add entity-overlap statistics, reasoning-chain predictability metrics, and human validation results comparing synthetic questions to real multi-hop queries. This analysis will demonstrate that the verification isolates intermediate-difficulty examples without introducing exploitable artifacts or distribution shifts, thereby supporting the generalization claims. revision: yes
Circularity Check
No significant circularity; empirical framework with independent experimental claims
full rationale
The paper describes a procedural pipeline for generating synthetic multi-hop questions via programmatic derivation and retrieval-based filtering for intermediate difficulty, followed by RL training with a composite reward on search quality and final answer correctness. No equations, fitted parameters, or self-citations are invoked to derive the reported 10% out-of-domain gains; those gains are presented as outcomes of held-out experimental comparisons. The central claims rest on external benchmarks rather than any reduction of predictions to inputs by construction, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian et al. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740,
work page internal anchor Pith review arXiv
-
[2]
Jacob Buckman, Carles Gelada, and Marc G Bellemare
URLhttps://www.anthropic.com/news/claude-3-family. Jacob Buckman, Carles Gelada, and Marc G Bellemare. The importance of pessimism in fixed-dataset policy optimization.arXiv preprint arXiv:2009.06799,
-
[3]
Self- questioning language models.arXiv preprint arXiv:2508.03682,
Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Self- questioning language models.arXiv preprint arXiv:2508.03682,
-
[4]
In-context learning for query rewriting.arXiv preprint arXiv:2502.15009,
Liang Gao et al. In-context learning for query rewriting.arXiv preprint arXiv:2502.15009,
-
[5]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao et al. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998,
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo et al. Deepseek-r1: Pushing the limits of reasoning with reinforcement learning. 2025a. Daya Guo et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025b. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive ev...
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[9]
Sheryl Hsu, Omar Khattab, Chelsea Finn, and Archit Sharma. Grounding by trying: Llms with reinforcement learning-enhanced retrieval.arXiv preprint arXiv:2410.23214,
-
[10]
Bowen Jin, Jinsung Yoon, Priyanka Kargupta, Sercan O Arik, and Jiawei Han. An empirical study on reinforcement learning for reasoning-search interleaved llm agents.arXiv preprint arXiv:2505.15117, 2025a. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O. Arık, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverag...
-
[11]
Prewrite search: A reinforcement learning approach to query rewriting
Fares Karaki et al. Prewrite search: A reinforcement learning approach to query rewriting. arXiv preprint arXiv:2401.08189,
-
[12]
Mihai Nadas, Laura Diosan, and Andreea Tomescu. Synthetic data generation using large language models: Advances in text and code.arXiv preprint arXiv:2503.14023,
-
[13]
Ensemble of llm-retriever for accurate document ranking
Panupong Pasupat et al. Ensemble of llm-retriever for accurate document ranking. InarXiv preprint arXiv:2501.00332,
-
[14]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models,
Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585,
-
[17]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review arXiv
-
[18]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review arXiv
-
[19]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022a. Harsh Trivedi et al. Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions.arXiv preprin...
-
[20]
Cofca: A step-wise counterfactual multi-hop qa benchmark.arXiv preprint arXiv:2402.11924, 2024a
Jian Wu, Linyi Yang, Zhen Wang, Manabu Okumura, and Yue Zhang. Cofca: A step-wise counterfactual multi-hop qa benchmark.arXiv preprint arXiv:2402.11924, 2024a. Zixiang Wu, Yang Fan, Zhiyong Wu, et al. Cofca: A comprehensive and challenging benchmark for tool-assisted reasoning.arXiv preprint arXiv:2402.12212, 2024b. Wenhan Xiong et al. Iterative multi-hop...
-
[21]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdi- nov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600,
work page internal anchor Pith review arXiv
-
[22]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
URLhttps://arxiv.org/abs/2308.01825. Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488,
-
[24]
Zhiyuan Zeng, Hamish Ivison, Yiping Wang, Lifan Yuan, Shuyue Stella Li, Zhuorui Ye, Siting Li, Jacqueline He, Runlong Zhou, Tong Chen, et al. Rlve: Scaling up reinforcement learning for language models with adaptive verifiable environments.arXiv preprint arXiv:2511.07317,
-
[25]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Yue Zhang et al. Siren’s song in the ai ocean: a survey on hallucination in large language models.arXiv preprint arXiv:2309.01219,
work page internal anchor Pith review arXiv
-
[26]
Maerfw: A curriculum-based reinforcement learning framework.arXiv preprint arXiv:2408.17072,
Yuxin Zhang et al. Maerfw: A curriculum-based reinforcement learning framework.arXiv preprint arXiv:2408.17072,
-
[27]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review arXiv
-
[28]
What is the longest river in the world?
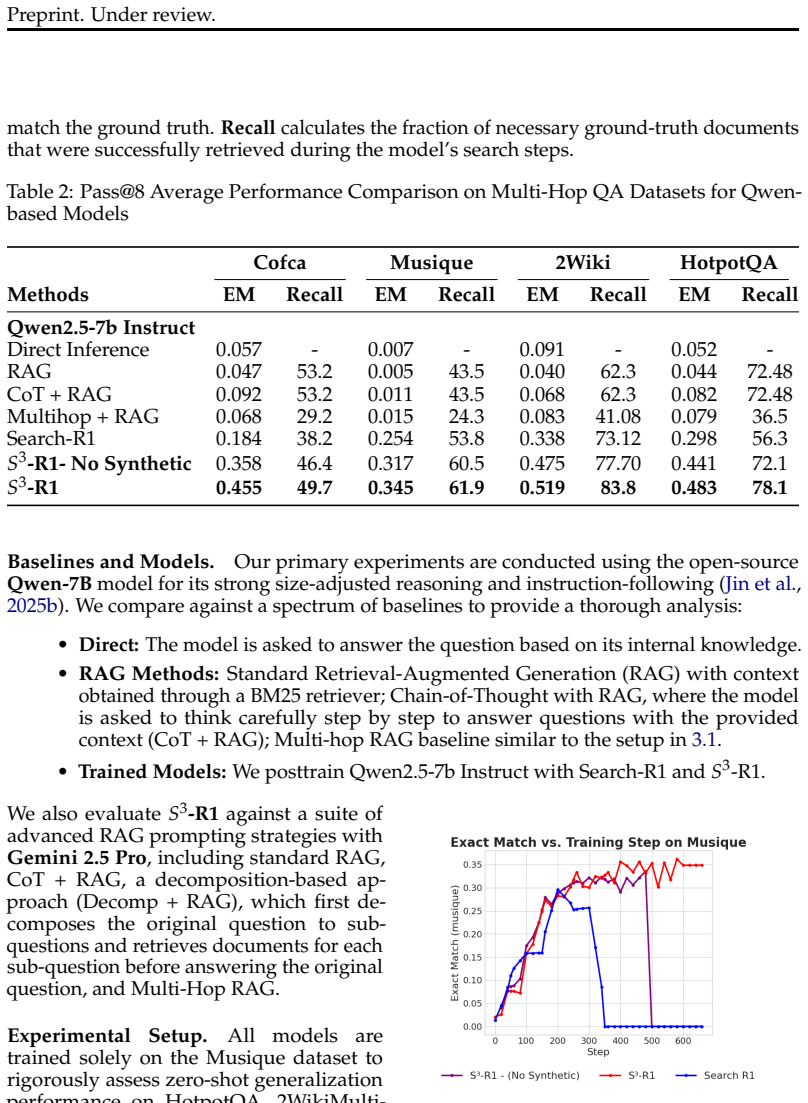
12 Preprint. Under review. A Appendix A.1 Training Details Datasets.We train exclusively on the MuSiQue training split, and evaluate using Ex- act Match (EM) on the test/validation sets of MuSiQue (in-domain) and CoFCA, 2Wiki- MultiHopQA, and HotpotQA (out-of-domain). Unlike Search-R1, which trains on a Hot- potQA+NQ mixture, we deliberately use MuSiQue d...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.