Recognition: unknown
EO-Gym: A Multimodal, Interactive Environment for Earth Observation Agents
Pith reviewed 2026-05-09 14:59 UTC · model grok-4.3
The pith
Earth Observation tasks require interactive tool use across time, space, and sensors that current general models handle poorly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
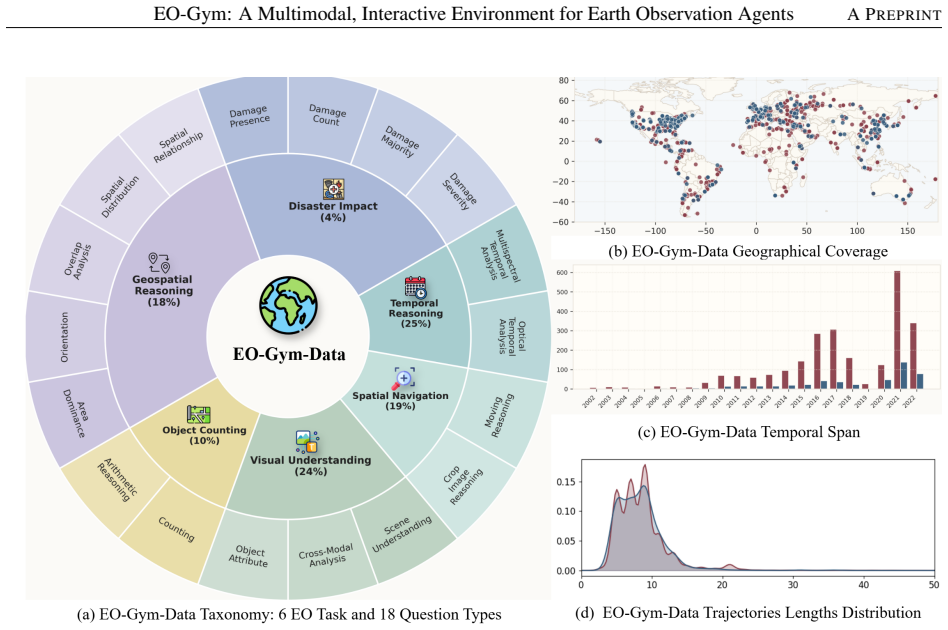
EO-Gym formulates EO analysis as a controlled local geospatial workspace backed by more than 660k multimodal files indexed by location, time, and sensor, equipped with 35 EO-specialized tools. On the resulting EO-Gym-Data benchmark of 9,078 trajectories and 34,604 reasoning steps, strong general-purpose models continue to struggle with interactive reasoning that spans temporal and cross-modal workflows; a reference model fine-tuned on the data improves Pass@3 from 0.49 to 0.74 in the main setting.
What carries the argument
A Gymnasium-style executable workspace with 35 EO-specialized tools that lets agents perform multi-step evidence gathering across geospatial, temporal, and sensing-modality dimensions.
If this is right
- Training agents on interactive EO trajectories produces measurable gains in multi-step Pass@3 performance.
- Benchmarks that collapse EO work into single-turn inputs will systematically underestimate the difficulty of realistic analysis.
- Planning across location, time, and modality becomes a learnable skill once an executable tool interface is supplied.
- Fine-tuning on grounded trajectories can close part of the gap between general-purpose vision-language models and domain-specific EO needs.
Where Pith is reading between the lines
- Environments of this kind could be adapted to train agents that combine satellite data with ground sensors for applications such as crop monitoring or flood mapping.
- The same trajectory-collection approach might reveal similar gaps in other data-rich scientific domains that require repeated evidence gathering, such as materials discovery or climate reanalysis.
- Future evaluations could measure whether agents trained here transfer to new satellite instruments or geographic regions not seen during construction of the benchmark.
Load-bearing premise
The 35 tools and 9,078 trajectories built from eight public datasets plus Landsat and Sentinel-2 imagery faithfully represent the essential interactive workflows and uncertainty-resolution steps used in real Earth Observation practice.
What would settle it
A controlled test in which models trained inside EO-Gym show no improvement over baselines when evaluated on a fresh collection of real analyst tasks that demand tool sequences or sensor combinations absent from the training trajectories.
Figures



read the original abstract
Earth Observation (EO) analysis is inherently interactive: resolving uncertainty often requires expanding the region of interest, retrieving historical observations, and switching across sensors such as optical and Synthetic Aperture Radar. However, most EO benchmarks collapse this process into fixed-input, single-turn tasks. To address this gap, we present EO-Gym, a controlled executable framework for multimodal, tool-using EO agents that formulates EO analysis as a Gymnasium-style local geospatial workspace backed by more than 660k multimodal files indexed by location, time, and sensor type, with 35 EO-specialized tools spanning six task families. Built on this environment, we construct EO-Gym-Data, a benchmark of 9,078 trajectories and 34,604 reasoning steps, and grounded in eight public EO datasets together with Landsat and Sentinel-2 imagery. Evaluating $10$ open and closed VLMs shows that strong general-purpose models still struggle with interactive EO reasoning, especially on temporal and cross-modal workflows. As a reference baseline, EO-Gym-4B, obtained by fine-tuning Qwen3-VL-4B-Instruct on EO-Gym-Data, improves overall Pass@3 from $0.49$ to $0.74$ under the main evaluation setting. O-Gym provides a reproducible environment for interactive EO agents, operationalizing EO as an evidence-gathering problem that requires planning across geospatial, temporal, and sensing modality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EO-Gym, a Gymnasium-style interactive environment for multimodal Earth Observation agents, featuring a local geospatial workspace backed by over 660k files indexed by location/time/sensor and 35 EO-specialized tools spanning six task families. It constructs EO-Gym-Data, a benchmark of 9,078 trajectories and 34,604 reasoning steps derived from eight public EO datasets plus Landsat/Sentinel-2 imagery. Evaluation of 10 open and closed VLMs shows general-purpose models achieve Pass@3 of 0.49, struggling especially on temporal and cross-modal workflows, while a fine-tuned EO-Gym-4B (based on Qwen3-VL-4B-Instruct) improves this to 0.74 under the main setting. The work positions EO analysis as an evidence-gathering problem requiring planning across geospatial, temporal, and modality dimensions.
Significance. If the trajectories and tools are representative, EO-Gym would be a meaningful contribution by supplying a reproducible, executable benchmark that operationalizes interactive EO reasoning rather than collapsing it to single-turn tasks. The fine-tuning baseline and public-data foundation are concrete strengths that could accelerate development of tool-using agents in remote sensing. The emphasis on Gymnasium compatibility and multimodal file indexing supports extensibility.
major comments (2)
- [EO-Gym-Data construction] In the EO-Gym-Data construction section: no expert annotation, coverage metrics, or comparison against real analyst logs is reported to validate that the 9,078 trajectories and six task families faithfully reproduce operational EO uncertainty-resolution steps (region expansion, historical retrieval, optical-SAR switching). This assumption is load-bearing for the central interpretation that low Pass@3 scores demonstrate struggles with interactive EO reasoning.
- [Evaluation and experiments] In the evaluation and experiments section: concrete details on trajectory generation pipeline, exact tool APIs, success criteria for Pass@3 (including partial credit for multimodal tool sequences), and statistical significance testing are not provided at a level that permits independent verification or reproduction of the reported 0.49-to-0.74 improvement.
minor comments (2)
- [Abstract] Abstract contains an apparent typo: 'O-Gym provides' should read 'EO-Gym provides'.
- [Evaluation] Clarify the precise definition of Pass@3 and any trajectory-level success thresholds in the main text to aid readers unfamiliar with the metric.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications on our methodology and commit to revisions that enhance validation and reproducibility.
read point-by-point responses
-
Referee: [EO-Gym-Data construction] In the EO-Gym-Data construction section: no expert annotation, coverage metrics, or comparison against real analyst logs is reported to validate that the 9,078 trajectories and six task families faithfully reproduce operational EO uncertainty-resolution steps (region expansion, historical retrieval, optical-SAR switching). This assumption is load-bearing for the central interpretation that low Pass@3 scores demonstrate struggles with interactive EO reasoning.
Authors: The 9,078 trajectories were constructed programmatically from the eight public EO datasets by defining task templates that require agents to resolve uncertainties through multi-step tool calls, such as expanding regions via spatial queries, retrieving historical observations using time-indexed files, and switching between optical and SAR sensors based on the 660k-file workspace. The six task families directly encode these operational patterns using the location/time/sensor indexing. While the manuscript does not include expert annotations or comparisons to real analyst logs, the benchmark is grounded in real public data to ensure the tasks reflect genuine EO workflows. We will add coverage metrics (e.g., trajectory distributions across task families, modalities, and temporal ranges) and a detailed description of the internal validation steps used during generation to the revised manuscript, thereby strengthening support for the interpretation of the Pass@3 results. revision: yes
-
Referee: [Evaluation and experiments] In the evaluation and experiments section: concrete details on trajectory generation pipeline, exact tool APIs, success criteria for Pass@3 (including partial credit for multimodal tool sequences), and statistical significance testing are not provided at a level that permits independent verification or reproduction of the reported 0.49-to-0.74 improvement.
Authors: The trajectory generation pipeline samples task goals from the public datasets and uses the EO-Gym environment to produce executable sequences of up to 34,604 reasoning steps. The 35 tool APIs are implemented as Gymnasium-compatible functions with defined inputs (e.g., bounding boxes, time ranges, sensor types) and outputs (e.g., file paths or metadata). Pass@3 success requires the agent to reach the task goal in at most three attempts, with partial credit for sequences that correctly invoke multimodal tools even if not exhaustive. We will expand the evaluation section with pseudocode for the pipeline, full API specifications, precise success criteria, and statistical significance tests (e.g., for the 0.49-to-0.74 Pass@3 lift) in the revised manuscript and supplementary material to enable full reproduction. revision: yes
Circularity Check
No circularity: benchmark and evaluation are self-contained from public sources
full rationale
The paper builds EO-Gym and EO-Gym-Data directly from eight public EO datasets plus Landsat/Sentinel-2 imagery, defines 35 tools and 9,078 trajectories without any fitted parameters or equations that would make evaluation metrics equivalent to construction choices. The reported Pass@3 scores (0.49 for general VLMs, 0.74 for the fine-tuned EO-Gym-4B) are measured on held-out trajectories, constituting a standard empirical comparison rather than a self-referential prediction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the environment or results; the derivation chain therefore remains independent of the authors' own fitting or definitional steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Joshi, N., Baumann, M., Ehammer, A., Fensholt, R., Grogan, K., Hostert, P., Jepsen, M.R., Kuemmerle, T., Meyfroidt, P., Mitchard, E.T.A., Reiche, J., Ryan, C.M., and Waske, B. (2016). A review of the application of optical and radar remote sensing data fusion to land use mapping and monitoring.Remote Sensing,8(1):70.https://doi.org/10.3390/rs8010070
-
[2]
Claverie, M., Ju, J., Masek, J.G., Dungan, J.L., Vermote, E.F., Roger, J.-C., Skakun, S.V ., and Justice, C. (2018). The harmonized Landsat and Sentinel-2 surface reflectance data set.Remote Sensing of Environment,219:145–161. https: //doi.org/10.1016/j.rse.2018.09.002
-
[3]
Ju, J., Zhou, Q., Freitag, B., Roy, D.P., Zhang, H.K., Sridhar, M., Mandel, J., Arab, S., Schmidt, G., Crawford, C.J., Gascon, F., Strobl, P.A., Masek, J.G., and Neigh, C.S.R. (2025). The harmonized Landsat and Sentinel-2 Version 2.0 surface reflectance dataset.Remote Sensing of Environment,324:114723.https://doi.org/10.1016/j.rse.2025.114723. 9 EO-Gym: A...
-
[4]
Wulder, M.A., White, J.C., Loveland, T.R., Woodcock, C.E., Belward, A.S., Cohen, W.B., Fosnight, E.A., Shaw, J., Masek, J.G., and Roy, D.P. (2016). The global Landsat archive: Status, consolidation, and direction.Remote Sensing of Environment, 185:271–283.https://doi.org/10.1016/j.rse.2015.11.032
-
[5]
Liu, S., Cheng, H., Liu, H., Zhang, H., Li, F., Ren, T., Zou, X., Yang, J., Su, H., Zhu, J., Zhang, L., Gao, J., and Li, C. (2024). LLaV A-Plus: Learning to Use Tools for Creating Multimodal Agents. InComputer Vision – ECCV 2024, pp. 126–142. https://doi.org/10.1007/978-3-031-72970-6_8
-
[6]
R., and Cao, Y
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . (2023). ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations. https://openreview.net/ forum?id=WE_vluYUL-X
2023
-
[7]
Qin, Y ., Liang, S., Ye, Y ., Zhu, K., Yan, L., Lu, Y ., Lin, Y ., Cong, X., Tang, X., Qian, B., Zhao, S., Hong, L., Tian, R., Xie, R., Zhou, J., Gerstein, M., Li, D., Liu, Z., and Sun, M. (2024). ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InThe Twelfth International Conference on Learning Representations. https://openre...
2024
-
[8]
Koh, J.Y ., Lo, R., Jang, L., Duvvur, V ., Lim, M., Huang, P.-Y ., Neubig, G., Zhou, S., Salakhutdinov, R., and Fried, D. (2024). VisualWebArena: Evaluating Multimodal Agents on Realistic Visually Grounded Web Tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 881–905. https://doi....
-
[9]
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y ., Xu, Y ., Zhou, S., Savarese, S., Xiong, C., Zhong, V ., and Yu, T. (2024). OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information Processing Systems,37:52040–52094. https: //doi.o...
-
[10]
Zhang, W., Cai, M., Zhang, T., Zhuang, Y ., and Mao, X. (2024). EarthGPT: A Universal Multimodal Large Language Model for Multisensor Image Comprehension in Remote Sensing Domain.IEEE Transactions on Geoscience and Remote Sensing, 62:1–20.https://doi.org/10.1109/TGRS.2024.3409624
-
[11]
Zhan, Y ., Xiong, Z., and Yuan, Y . (2025). SkyEyeGPT: Unifying remote sensing vision-language tasks via instruction tuning with large language model.ISPRS Journal of Photogrammetry and Remote Sensing,221:64–77. https://doi.org/10. 1016/j.isprsjprs.2025.01.020
2025
-
[12]
Li, X., Ding, J., and Elhoseiny, M. (2024). VRSBench: A versatile vision-language benchmark dataset for remote sensing image understanding. InAdvances in Neural Information Processing Systems,37:3229–3242. https://doi.org/10.52202/ 079017-0106
2024
-
[13]
Lacoste, A., Lehmann, N., Rodriguez, P., Sherwin, E., Kerner, H., L"utjens, B., Irvin, J., Dao, D., Alemohammad, H., Drouin, A., Gunturkun, M., Huang, G., Vazquez, D., Newman, D., Bengio, Y ., Ermon, S., and Zhu, X. (2023). GEO- Bench: Toward foundation models for Earth monitoring. InAdvances in Neural Information Processing Systems 36. https: //doi.org/1...
-
[14]
Soni, S., Dudhane, A., Debary, H., Fiaz, M., Munir, M.A., Danish, M.S., Fraccaro, P., Watson, C.D., Klein, L.J., Khan, F.S., and Khan, S. (2025). EarthDial: Turning multi-sensory Earth observations to interactive dialogues. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14303–14313.https://doi.org/10.1109/ CVPR527...
- [15]
-
[16]
Shabbir, A., Munir, M.A., Dudhane, A., Sheikh, M.U., Khan, M.H., Fraccaro, P., Moreno, J.B., Khan, F.S., and Khan, S. (2025). ThinkGeo: Evaluating Tool-Augmented Agents for Remote Sensing Tasks. arXiv preprint arXiv:2505.23752. https://doi.org/10.48550/arXiv.2505.23752
-
[17]
Feng, P., Lv, Z., Ye, J., Wang, X., Huo, X., Yu, J., Xu, W., Zhang, W., Bai, L., He, C., and Li, W. (2026). Earth-Agent: Unlocking the Full Landscape of Earth Observation with Agents. InThe Fourteenth International Conference on Learning Representations
2026
-
[18]
Shabbir, A., Munir, M.A., Sheikh, M.U., Hussain, S., Khan, M.H., Fraccaro, P., Moreno, J.B., Khan, F.S., and Khan, S. (2026). OpenEarthAgent: A Unified Framework for Tool-Augmented Geospatial Agents. https://doi.org/10.48550/arXiv. 2602.17665
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[19]
Zhao, S., Liu, F., Zhang, X., Chen, H., Gu, X., Jiang, Z., Ling, F., Fei, B., Zhang, W., Wang, J., Xuan, W., Xiao, P., Yokoya, N., and Bai, L. (2026). OpenEarth-Agent: From Tool Calling to Tool Creation for Open-Environment Earth Observation. https://doi.org/10.48550/arXiv.2603.22148
-
[20]
Brockman, G., Cheung, V ., Pettersson, L., Schneider, J., Schulman, J., Tang, J., and Zaremba, W. (2016). OpenAI Gym. https://doi.org/10.48550/arXiv.1606.01540
work page internal anchor Pith review doi:10.48550/arxiv.1606.01540 2016
-
[21]
Drusch, M., Del Bello, U., Carlier, S., Colin, O., Fernandez, V ., Gascon, F., Hoersch, B., Isola, C., Laberinti, P., Martimort, P., Meygret, A., Spoto, F., Sy, O., Marchese, F., and Bargellini, P. (2012). Sentinel-2: ESA’s optical high-resolution mission for GMES operational services.Remote Sensing of Environment,120:25–36. https://doi.org/10.1016/j.rse....
-
[22]
Torres, R., Snoeij, P., Geudtner, D., Bibby, D., Davidson, M., Attema, E., Potin, P., Rommen, B., Floury, N., Brown, M., Traver, I.N., Deghaye, P., Duesmann, B., Rosich, B., Miranda, N., Bruno, C., L’Abbate, M., Croci, R., Pietropaolo, A., Huchler, M., and Rostan, F. (2012). GMES Sentinel-1 mission.Remote Sensing of Environment,120:9–24. https: //doi.org/...
-
[23]
DigitalGlobe. (2014). WorldView-3 Data Sheet. DigitalGlobe. https://www.spaceimagingme.com/downloads/ sensors/datasheets/DG_WorldView3_DS_2014.pdf. Accessed: May 1, 2026
2014
-
[24]
Toutin, T., and Cheng, P. (2002). QuickBird—A Milestone for High Resolution Mapping.Earth Observation Magazine, 11(4):14–18
2002
-
[25]
Madden, M. (2009). GeoEye-1, the World’s highest resolution commercial satellite. InConference on Lasers and Electro- Optics/International Quantum Electronics Conference, OSA Technical Digest (CD), paper PWB4.https://doi.org/10. 1364/CLEO.2009.PWB4
2009
-
[26]
Huang, W., Sun, S., Jiang, H., Gao, C., and Zong, X. (2018). GF-2 Satellite 1m/4m Camera Design and In-Orbit Commissioning. Chinese Journal of Electronics,27(6):1316–1321.https://doi.org/10.1049/cje.2018.09.018
-
[27]
World Meteorological Organization. (2026). Satellite: Jilin-1. OSCAR: Observing Systems Capability Analysis and Review Tool.https://space.oscar.wmo.int/satellites/view/jilin_1. Accessed: May 1, 2026
2026
-
[28]
Cyclomedia. (2026). Aerial data. https://www.cyclomedia.com/en/producten/data-visualisatie/ aerial-data/. Accessed: May 1, 2026
2026
-
[29]
Mialon, G., Fourrier, C., Wolf, T., LeCun, Y ., and Scialom, T. (2024). GAIA: A benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations.https://openreview.net/forum?id=fibxvahvs3
2024
-
[30]
Wang, J., Ma, Z., Li, Y ., Zhang, S., Chen, C., Chen, K., and Le, X. (2024). GTA: A benchmark for general tool agents. In Advances in Neural Information Processing Systems,37:75749–75790.https://doi.org/10.52202/079017-2412
-
[31]
Nathani, D., Madaan, L., Roberts, N., Bashlykov, N., Menon, A., Moens, V ., Budhiraja, A., Magka, D., V orotilov, V ., Chaurasia, G., Hupkes, D., Cabral, R.S., Shavrina, T., Foerster, J., Bachrach, Y ., Wang, W.Y ., and Raileanu, R. (2025). MLGym: A new framework and benchmark for advancing AI research agents.https://doi.org/10.48550/arXiv.2502.14499
-
[32]
Jain, N., Singh, J., Shetty, M., Zheng, L., Sen, K., and Stoica, I. (2025). R2E-Gym: Procedural environments and hybrid verifiers for scaling open-weights SWE agents.https://doi.org/10.48550/arXiv.2504.07164
-
[33]
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y ., Fried, D., Alon, U., and Neubig, G. (2024). WebArena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations.https://openreview.net/forum?id=oKn9c6ytLx
2024
-
[34]
Li, B., Wang, Y ., Fei, H., Li, J., Ji, W., Lee, M.-L., and Hsu, W. (2025). FormFactory: An interactive benchmarking suite for multimodal form-filling agents.https://doi.org/10.48550/arXiv.2506.01520
-
[35]
Kulkarni, M., Rehberg, W., and Alexis, K. (2025). Aerial Gym Simulator: A framework for highly parallelized simulation of aerial robots.https://doi.org/10.48550/arXiv.2503.01471
-
[36]
Lam, D., Kuzma, R., McGee, K., Dooley, S., Laielli, M., Klaric, M., Bulatov, Y ., and McCord, B. (2018). xView: Objects in context in overhead imagery.https://doi.org/10.48550/arXiv.1802.07856
-
[37]
Xia, G.-S., Bai, X., Ding, J., Zhu, Z., Belongie, S., Luo, J., Datcu, M., Pelillo, M., and Zhang, L. (2018). DOTA: A large- scale dataset for object detection in aerial images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3974–3983.https://doi.org/10.1109/CVPR.2018.00418
-
[38]
Li, K., Wan, G., Cheng, G., Meng, L., and Han, J. (2020). Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS Journal of Photogrammetry and Remote Sensing,159:296–307. https://doi.org/10.1016/j. isprsjprs.2019.11.023
work page doi:10.1016/j 2020
-
[39]
Sun, X., Wang, P., Yan, Z., Xu, F., Wang, R., Diao, W., Chen, J., Li, J., Feng, Y ., Xu, T., Weinmann, M., Hinz, S., Wang, C., and Fu, K. (2022). FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS Journal of Photogrammetry and Remote Sensing,184:116–130. https://doi.org/10.1016/j.isprsjprs.2021. 12.004
-
[40]
Li, Y ., Li, X., Li, W., Hou, Q., Liu, L., Cheng, M.-M., and Yang, J. (2024). SARDet-100K: Towards open-source benchmark and toolkit for large-scale SAR object detection. InAdvances in Neural Information Processing Systems,37:128430–128461. https://doi.org/10.52202/079017-4079
-
[41]
Massey, M., Munia, N., and Imran, A.-A.-Z. (2025). EarthScape: A multimodal dataset for surficial geologic mapping and Earth surface analysis.https://doi.org/10.48550/arXiv.2503.15625
-
[42]
Stewart, A.J., Robinson, C., Corley, I.A., Ortiz, A., Ferres, J.M.L., and Banerjee, A. (2022). TorchGeo: Deep learning with geospatial data. InProceedings of the 30th International Conference on Advances in Geographic Information Systems, pp. 1–12.https://doi.org/10.1145/3557915.3560953
-
[43]
Mai, G., Lao, N., He, Y ., Song, J., and Ermon, S. (2023). CSP: Self-supervised contrastive spatial pre-training for geospatial- visual representations. InProceedings of the 40th International Conference on Machine Learning
2023
-
[44]
Rußwurm, M., and Körner, M. (2020). Self-attention for raw optical satellite time series classification.ISPRS Journal of Photogrammetry and Remote Sensing,169:421–435.https://doi.org/10.1016/j.isprsjprs.2020.06.006. 11 EO-Gym: A Multimodal, Interactive Environment for Earth Observation AgentsA PREPRINT
-
[45]
Sainte Fare Garnot, V ., and Landrieu, L. (2021). Panoptic segmentation of satellite image time series with convolutional temporal attention networks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4872–4881. https://doi.org/10.1109/ICCV48922.2021.00483
-
[46]
Abbas, A., Linardi, M., Vareille, E., Christophides, V ., and Paris, C. (2023). Towards Explainable AI4EO: An explainable deep learning approach for crop type mapping using satellite images time series. InIGARSS 2023 – 2023 IEEE International Geo- science and Remote Sensing Symposium, pp. 1088–1091.https://doi.org/10.1109/IGARSS52108.2023.10283125
-
[47]
Christie, G., Fendley, N., Wilson, J., and Mukherjee, R. (2018). Functional Map of the World. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.https://doi.org/10.1109/CVPR.2018.00646
-
[48]
Gupta, R., Goodman, B., Patel, N., Hosfelt, R., Sajeev, S., Heim, E., Doshi, J., Lucas, K., Choset, H., and Gaston, M. (2019). Creating xBD: A dataset for assessing building damage from satellite imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 10–17
2019
-
[49]
Wang, C., Lu, W., Li, X., Yang, J., and Luo, L. (2025). M4-SAR: A multi-resolution, multi-polarization, multi-scene, multi-source dataset and benchmark for optical-SAR object detection. https://doi.org/10.48550/arXiv.2505.10931
-
[50]
Rouse, J.W., Haas, R.H., Schell, J.A., and Deering, D.W. (1974). Monitoring vegetation systems in the Great Plains with ERTS. NASA Special Publication,351:309–317
1974
-
[51]
Gao, B.C. (1996). NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sensing of Environment,58(3):257–266.https://doi.org/10.1016/S0034-4257(96)00067-3
-
[52]
Gorelick, N., Hancher, M., Dixon, M., Ilyushchenko, S., Thau, D., and Moore, R. (2017). Google Earth Engine: Planetary-scale geospatial analysis for everyone.Remote Sensing of Environment,202:18–27. https://doi.org/10.1016/j.rse.2017. 06.031
-
[53]
Carion, N., Gustafson, L., Hu, Y .-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V ., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., et al. (2026). SAM 3: Segment anything with concepts.arXiv preprint, arXiv:2511.16719.https://doi.org/10.48550/arXiv.2511.16719
work page internal anchor Pith review doi:10.48550/arxiv.2511.16719 2026
-
[54]
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., Zhu, J., and Zhang, L. (2024). Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InComputer Vision – ECCV 2024, pp. 38–55.https://doi.org/10.1007/978-3-031-72970-6_3
-
[55]
OpenAI. (2025). GPT-4.1 model. OpenAI API documentation. Available athttps://developers.openai.com/api/docs/ models/gpt-4.1. Accessed: May 1, 2026
2025
-
[56]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., et al. (2025). OpenAI GPT-5 System Card.arXiv preprint, arXiv:2601.03267.https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
OpenAI, Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R.K., Bai, Y ., Baker, B., et al. (2025). gpt-oss-120b and gpt-oss-20b Model Card.arXiv preprint, arXiv:2508.10925.https://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
-
[58]
Song, Y ., Xiong, W., Zhao, X., Zhu, D., Wu, W., Wang, K., Li, C., Peng, W., and Li, S. (2024). AgentBank: Towards generalized LLM agents via fine-tuning on 50000+ interaction trajectories. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 2124–2141.https://doi.org/10.18653/v1/2024.findings-emnlp.116
-
[59]
Kang, M., Jeong, J., Lee, S., Cho, J., and Hwang, S.J. (2025). Distilling LLM agent into small models with retrieval and code tools. arXiv preprint arXiv:2505.17612.https://doi.org/10.48550/arXiv.2505.17612
-
[60]
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. (2022). LoRA: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations. https://openreview.net/ forum?id=nZeVKeeFYf9
2022
-
[61]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., et al. (2025). Qwen3-VL Technical Report.arXiv preprint, arXiv:2511.21631. https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Zhao, Y ., Huang, J., Hu, J., Wang, X., Mao, Y ., Zhang, D., Jiang, Z., Wu, Z., Ai, B., Wang, A., Zhou, W., and Chen, Y . (2025). SWIFT: A scalable lightweight infrastructure for fine-tuning.Proceedings of the AAAI Conference on Artificial Intelligence, 39(28):29733–29735.https://doi.org/10.1609/aaai.v39i28.35383
-
[63]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., et al. (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint, arXiv:2507.06261. https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Cohen, J. (1960). A coefficient of agreement for nominal scales.Educational and Psychological Measurement,20(1):37–46. https://doi.org/10.1177/001316446002000104
-
[65]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H.P.O., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. (2021). Evaluating Large Language Models Trained on Code.https://doi.org/10.48550/arXiv.2107.03374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[66]
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. (2023). Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=1PL1NIMMrw
2023
-
[67]
Wulder, M.A., Coops, N.C., Roy, D.P., White, J.C., and Hermosilla, T. (2019). Current status of Landsat program, science, and applications.Remote Sensing of Environment,225:127–147.https://doi.org/10.1016/j.rse.2019.02.015. 12 EO-Gym: A Multimodal, Interactive Environment for Earth Observation AgentsA PREPRINT
-
[68]
Teknium, R., Quesnelle, J., and Guang, C. (2024). Hermes 3 Technical Report.arXiv preprint, arXiv:2408.11857. https: //doi.org/10.48550/arXiv.2408.11857. A Controlled Executable Earth Observation Environment:EO-Gym A.1 Metadata-Drive Data Lake The EO-Gym environment operationalizes EO reasoning as an interactive evidence-acquisition process across space, ...
-
[69]
Did I already call a tool that directly observes the target object, region, change, or scene property?
-
[70]
If not, call the best matching available-modality tool now
-
[71]
Is my only reason for stopping that the paired image is missing or the first tool was unhelpful?
-
[72]
Try the next most relevant available tool
If yes, do not stop yet. Try the next most relevant available tool
-
[73]
After the last observation, what exact missing uncertainty remains? If one remains, do not answer yet
-
[74]
For counting or ratio questions, did I convert raw detections into the filtered count or calculation the question actually asks for?
-
[75]
If I am about to answer from a raw box/mask count, have I checked for duplicates, partial objects, low-confidence detections, and the requested date/modality?
-
[76]
cannot determine
If I am about to answer 0 or "cannot determine", do I have enough evidence that the target is truly absent or unsupported rather than merely missed by one detector call?
-
[77]
TBD", question_type=
Please brief the chain of thought before give the final answer. A.3.3 Skill vs All Tools The tool schema configuration determines the size and relevance of the action space exposed to the agent during execution. 18 EO-Gym: A Multimodal, Interactive Environment for Earth Observation AgentsA PREPRINT TheSkill toolssetting narrows the action space by exposin...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.