Recognition: unknown
Addressing Data Scarcity in Bangla Fake News Detection: An LLM-Based Dataset Augmentation Approach
Pith reviewed 2026-05-09 15:05 UTC · model grok-4.3
The pith
Augmenting only the minority class with high-rate language model samples and random subsampling improves Bangla fake news detection F1 from 0.85 to 0.88.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that generating synthetic Bangla news articles with a language model, applying semantic filtering to ensure quality, and then using high augmentation rates specifically on the minority class combined with random subsampling produces the strongest improvement in fake news detection performance, elevating the F1 score for identifying fake news from 0.85 to 0.88 while maintaining label consistency and dataset diversity.
What carries the argument
Large language model based synthetic article generation with semantic filtering and selective subsampling applied to the minority class to balance the dataset.
Load-bearing premise
The language model generated news articles preserve accurate labels and introduce no systematic biases or quality issues that would negatively affect the trained classifier.
What would settle it
A classifier trained on the augmented dataset showing equal or lower F1 score than on the original dataset, or independent verification revealing a high rate of label errors in the synthetic samples, would falsify the effectiveness of the approach.
Figures

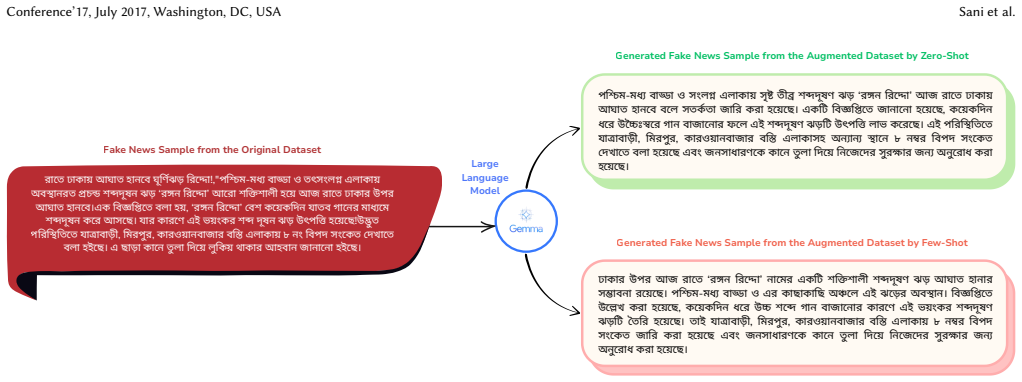
read the original abstract
The growing spread of misinformation in digital media highlights the need for reliable fake news detection systems, yet progress in under-resourced languages such as Bangla is limited by small and imbalanced datasets. This study investigates whether Large Language Model (LLM) based augmentation can effectively address this limitation and improve Bangla fake news classification. Existing datasets remain valuable but highly imbalanced, limiting model performance, and LLM based augmentation for Bangla has been scarcely explored. To fill this gap, we propose a systematic augmentation framework that generates synthetic Bangla news articles using the instruction tuned Gemma 3 27B IT model, supported by semantic filtering and controlled subsampling to preserve label consistency and diversity. We compare zero shot and few shot prompting, evaluate multiple augmentation rates, and examine random versus similarity-based selection strategies. Our experiments show that augmenting only the minority class with a high augmentation rate and random subsampling yields the strongest gains, raising the Fake News F1 score from 0.85 to 0.88. To support reproducibility and further research in this low-resource domain, we publicly release 4,545 synthetically generated Bangla fake news samples along with our full implementation. These findings demonstrate that well-designed LLM-driven augmentation can significantly improve fake news detection in low resource settings and provide a practical foundation for advancing multilingual misinformation research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an LLM-driven augmentation framework using the instruction-tuned Gemma-3-27B-IT model to generate synthetic Bangla news articles for addressing data scarcity and class imbalance in fake news detection. It evaluates zero-shot versus few-shot prompting, multiple augmentation rates, and random versus similarity-based subsampling strategies, with semantic filtering to maintain label consistency. The central empirical finding is that augmenting only the minority (fake news) class at a high rate with random subsampling yields the largest gains, improving Fake News F1 from 0.85 to 0.88 on the downstream classifier. The authors publicly release 4,545 synthetic samples and their implementation code.
Significance. If the reported gains prove robust, the work provides a practical, reproducible template for LLM augmentation in low-resource languages where labeled data for misinformation tasks is scarce. The public release of the synthetic dataset is a clear strength that supports community validation and extension to other languages or tasks.
major comments (2)
- [Augmentation Framework and Experimental Setup] The augmentation framework (described in the methods and abstract) relies on the untested assumption that Gemma-3-27B-IT outputs preserve original label semantics and introduce no systematic artifacts (repetitive phrasing, unnatural syntax, or hallucinated entities). No human validation, inter-annotator agreement scores, perplexity comparisons, or embedding similarity metrics to real Bangla news are reported, which is load-bearing for the claim that the F1 lift is due to genuine data enrichment rather than exploitable cues.
- [Experimental Results] The headline result (F1 0.85 → 0.88) is presented without statistical significance tests, confidence intervals, or full ablation tables isolating the contributions of prompting strategy, augmentation rate, and selection method. This omission makes it impossible to determine whether the gains are reliable or sensitive to unstated factors such as the base classifier architecture or train/test split.
minor comments (1)
- [Abstract] The abstract states that existing datasets are 'highly imbalanced' but does not name the specific source dataset(s) or report their original class distribution and size; adding this information would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment point by point below, providing the strongest honest defense of the work while acknowledging where revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [Augmentation Framework and Experimental Setup] The augmentation framework (described in the methods and abstract) relies on the untested assumption that Gemma-3-27B-IT outputs preserve original label semantics and introduce no systematic artifacts (repetitive phrasing, unnatural syntax, or hallucinated entities). No human validation, inter-annotator agreement scores, perplexity comparisons, or embedding similarity metrics to real Bangla news are reported, which is load-bearing for the claim that the F1 lift is due to genuine data enrichment rather than exploitable cues.
Authors: We appreciate this observation. The manuscript describes semantic filtering via embedding similarity to preserve label consistency (Section 3), which provides a quantitative check against label drift. However, we did not report human validation, inter-annotator agreement, perplexity, or explicit embedding similarity distributions between synthetic and real samples. We will revise the paper to include these embedding similarity metrics and a dedicated limitations subsection discussing potential artifacts. Human evaluation was not performed due to resource constraints in the original study; we will explicitly note this as a limitation and recommend it for future extensions rather than claiming the current evidence is exhaustive. revision: partial
-
Referee: [Experimental Results] The headline result (F1 0.85 → 0.88) is presented without statistical significance tests, confidence intervals, or full ablation tables isolating the contributions of prompting strategy, augmentation rate, and selection method. This omission makes it impossible to determine whether the gains are reliable or sensitive to unstated factors such as the base classifier architecture or train/test split.
Authors: We agree that statistical rigor and detailed ablations are necessary. The reported improvement comes from controlled experiments varying prompting, rate, and subsampling, but we did not include significance tests or full isolation tables. In the revised manuscript we will add paired statistical tests (e.g., McNemar’s test or bootstrap confidence intervals) for the F1 gains, report 95% confidence intervals, and expand the results with complete ablation tables that separately quantify the contribution of each factor. We will also clarify the base classifier architecture and train/test split details to address sensitivity concerns. revision: yes
Circularity Check
No circularity: purely empirical comparison of augmentation strategies
full rationale
The paper reports an empirical study that generates synthetic Bangla news via Gemma-3-27B-IT, applies semantic filtering and subsampling, then measures downstream classifier F1 on real test data. The headline result (F1 0.85 → 0.88) is obtained by direct experiment across prompting and sampling variants; no equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the described chain. All performance numbers are externally observable on held-out real data and do not reduce to the augmentation procedure by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- augmentation rate
- selection strategy
axioms (1)
- domain assumption The instruction-tuned Gemma 3 27B IT model can produce Bangla news text whose semantic content matches the intended fake or real label.
Reference graph
Works this paper leans on
-
[1]
Ajwad Abrar, Farzana Tabassum, and Sabbir Ahmed. 2024. Performance Evalua- tion of Large Language Models in Bangla Consumer Health Query Summarization. In2024 27th International Conference on Computer and Information Technology (ICCIT). IEEE, 2748–2753
2024
-
[2]
Emil Ahlbäck and Max Dougly. 2023. Can Large Language Models Enhance Fake News Detection?: Improving Fake News Detection With Data Augmentation
2023
-
[3]
Jawaher Alghamdi, Suhuai Luo, and Yuqing Lin. 2024. A comprehensive survey on machine learning approaches for fake news detection.Multimedia Tools and Applications83, 17 (2024), 51009–51067
2024
-
[4]
Hunt Allcott and Matthew Gentzkow. 2017. Social media and fake news in the 2016 election.Journal of Economic Perspectives31, 2 (2017), 211–236
2017
-
[5]
Alnabhan and Paula Branco
Mohammad Q. Alnabhan and Paula Branco. 2024. Fake news detection using deep learning: a systematic literature review.IEEE Access(2024)
2024
-
[6]
Santiago Alonso García, Gerardo Gómez García, Mariano Sanz Prieto, Anto- nio José Moreno Guerrero, and Carmen Rodríguez Jiménez. 2020. The impact of term fake news on the scientific community. Scientific performance and mapping in web of science.Social Sciences9, 5 (2020), 73
2020
-
[7]
Muhammad Amjad, Grigori Sidorov, and Anna Zhila. 2020. Data augmentation using machine translation for fake news detection in the Urdu language. In Proceedings of the 12th Language Resources and Evaluation Conference. 2537–2542
2020
-
[8]
Nadia Ashraf, Sana Butt, Grigori Sidorov, and Alexander Gelbukh. 2021. CIC at CheckThat! 2021: Fake news detection using machine learning and data augmen- tation. InCLEF (Working Notes). 446–454
2021
-
[9]
Amirsiavosh Bashardoust, Stefan Feuerriegel, and Yash Raj Shrestha. 2024. Com- paring the willingness to share for human-generated vs. AI-generated fake news. Proceedings of the ACM on Human-Computer Interaction8, CSCW2 (2024), 1–21
2024
-
[10]
Markus Bayer, Marc-André Kaufhold, and Christian Reuter. 2022. A survey on data augmentation for text classification.Comput. Surveys55, 7 (2022), 1–39
2022
-
[11]
Razieh Chalehchaleh, Reza Farahbakhsh, and Noel Crespi. 2025. Addressing data scarcity in multilingual fake news detection: an LLM-based dataset augmentation approach.Social Network Analysis and Mining15 (2025), 92
2025
-
[12]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[14]
Bosheng Ding, Chengwei Qin, Ruobing Zhao, Tianyu Luo, Xinze Li, Chengguang Ma, Yunsen Chen, Shijue Chen, Qinqin Zeng, Chenghua Lou, et al. 2024. Data augmentation using LLMs: Data perspectives, learning paradigms and challenges. InFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, 1679–1705
2024
-
[15]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[16]
Arianna D’ulizia, Maria Chiara Caschera, Fernando Ferri, and Patrizia Grifoni
-
[17]
Fake news detection: a survey of evaluation datasets.PeerJ Computer Science7 (2021), e518
2021
-
[18]
Stefan Feuerriegel, Renée DiResta, and Joseph A Goldstein. 2023. Research can help to tackle AI-generated disinformation.Nature Human Behaviour7, 11 (2023), 1818–1821
2023
-
[19]
Stefan Feuerriegel, Jochen Hartmann, Christian Janiesch, and Patrick Zschech
-
[20]
Generative AI.Business & Information Systems Engineering66, 1 (2024), 111–126
2024
-
[21]
Elia Gabarron, Sunday Oluwafemi Oyeyemi, and Rolf Wynn. 2021. COVID-19- related misinformation on social media: a systematic review.Bulletin of the World Health Organization99, 6 (2021), 455
2021
-
[22]
Nir Grinberg, Kenneth Joseph, Lisa Friedland, Briony Swire-Thompson, and David Lazer. 2019. Fake news on Twitter during the 2016 US presidential election. Addressing Data Scarcity in Bangla Fake News Detection: An LLM-Based Dataset Augmentation Approach Conference’17, July 2017, Washington, DC, USA Science363, 6425 (2019), 374–378
2019
-
[23]
Hamed, Mohd Juzaiddin Ab Aziz, and Mohd Riduwan Yaakub
Sherief K. Hamed, Mohd Juzaiddin Ab Aziz, and Mohd Riduwan Yaakub. 2023. A review of fake news detection approaches: a critical analysis of relevant studies and highlighting key challenges associated with the dataset, feature representa- tion, and data fusion.Heliyon(2023)
2023
-
[24]
Zobaer Hossain, Md
Md. Zobaer Hossain, Md. Ashikur Rahman, Md. Saiful Islam, and Saikat Kar. 2020. BanFakeNews: A Dataset for Detecting Fake News in Bangla. InProceedings of the 12th Language Resources and Evaluation Conference (LREC). European Language Resources Association, 2862–2871
2020
-
[25]
Beizhen Hu, Quan Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Liu, and Peng Qi. 2024. Bad Actor, Good Advisor: Exploring the Role of Large Language Models in Fake News Detection. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 22105–22113
2024
-
[26]
Jiaxin Hua, Xirong Cui, Xiaoyu Li, Kai Tang, and Lanjun Zhu. 2023. Multimodal fake news detection through data augmentation-based contrastive learning.Ap- plied Soft Computing136 (2023), 110125
2023
- [27]
-
[28]
Juraj Kapusta, David Držík, Karol Šteflovivc, and Marek Hudák. 2024. Text data augmentation techniques for word embeddings in fake news classification.IEEE Access12 (2024), 31538–31550
2024
-
[29]
Ashraf Wadud, Md Mridha, Mohammed Alatiyyah, and Md Abdul Hamid
Anika Jain Keya, Md. Ashraf Wadud, Md Mridha, Mohammed Alatiyyah, and Md Abdul Hamid. 2022. AugFake-BERT: Handling imbalance through aug- mentation of fake news using BERT to enhance the performance of fake news classification.Applied Sciences12, 17 (2022), 8398
2022
- [30]
-
[31]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Seyed Minaee, Tomas Mikolov, Nima Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: a survey.arXiv preprint arXiv:2402.06196(2024)
work page internal anchor Pith review arXiv 2024
-
[33]
Femi Olan, Uchitha Jayawickrama, Etuate O Arakpogun, Juliana Suklan, and Shaofeng Liu. 2024. Fake news on social media: the impact on society.Information Systems Frontiers26, 2 (2024), 443–458
2024
-
[34]
Fabio Pierri, Luca Luceri, Nitin Jindal, and Emilio Ferrara. 2023. Propaganda and misinformation on Facebook and Twitter during the Russian invasion of Ukraine. InProceedings of the 15th ACM Web Science Conference 2023. 65–74
2023
-
[35]
Inggrid Yanuar Risca Pratiwi, Rosa Andrie Asmara, and Faisal Rahutomo. 2017. Study of hoax news detection using naïve bayes classifier in Indonesian language. In2017 11th International Conference on Information & Communication Technology and System (ICTS). IEEE, 73–78
2017
-
[36]
Yasmim Mendes Rocha, Gabriel Acácio De Moura, Gabriel Alves Desidério, Car- los Henrique De Oliveira, Francisco Dantas Lourenço, and Larissa Deadame de Figueiredo Nicolete. 2023. The impact of fake news on social media and its influ- ence on health during the COVID-19 pandemic: A systematic review.Journal of Public Health31, 7 (2023), 1007–1016
2023
-
[37]
Rosa María Sánchez del Vas and Javier Tuñón Navarro. 2024. Disinformation on the covid-19 pandemic and the Russia–Ukraine war: two sides of the same coin? Humanities and Social Sciences Communications11, 1 (2024), 1–9
2024
-
[38]
Arif Shahriar and Denilson Barbosa. 2024. Improving Bengali and Hindi large language models. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 8719–8731
2024
-
[39]
Aubin and Julia Liedke
Chelsea St. Aubin and Julia Liedke. 2024. News Platform Fact Sheet. https: //www.pewresearch.org/journalism/fact-sheet/news-platform-fact-sheet/
2024
-
[40]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[41]
Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. 2020. Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (csur)53, 3 (2020), 1–34
2020
-
[42]
Yike Wu, Yang Xiao, Mengting Hu, Mengying Liu, Pengcheng Wang, and Ming- ming Liu. 2024. Towards robust evidence-aware fake news detection via improv- ing semantic perception. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 16607–16618
2024
-
[43]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yiqun Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.18223(2023)
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.