Recognition: unknown
Alikhanov-XfPINNs: Adaptive Physics-Informed Learning for Nonlinear Fractional PDEs on Nonuniform Meshes
Pith reviewed 2026-05-09 18:33 UTC · model grok-4.3
The pith
The Alikhanov-XfPINNs architecture embeds high-order time discretization on nonuniform meshes into neural network training to solve nonlinear fractional PDEs accurately despite initial singularities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that the XfPINNs framework, built by extending fractional PINNs with the Alikhanov variational loss on adaptive nonuniform meshes, successfully approximates solutions to general nonlinear fractional PDEs. It supports both forward simulations and inverse parameter identification, and numerical tests confirm that accuracy tracks the temporal mesh refinement while training remains stable and efficient.
What carries the argument
The Alikhanov-extended fractional PINNs (XfPINNs) architecture that constructs a variational loss from the high-order Alikhanov time-stepping scheme applied on nonuniform grids and trains the network to minimize it while enforcing initial and boundary conditions through hard and soft penalties.
If this is right
- Solutions to nonlinear fPDEs can be reconstructed from data even when the exact form is unknown.
- Parameter estimation in inverse problems becomes feasible with the same trained architecture.
- Computational efficiency improves substantially through CPU time reductions on nonuniform meshes compared to uniform ones.
- Temporal convergence rates can be isolated and verified independently of neural network optimization errors.
Where Pith is reading between the lines
- This approach might generalize to other singular fractional models in physics and engineering if the nonuniform grid strategy adapts well.
- By auditing discretization separately, it provides a template for testing other hybrid numerical-ML methods for PDEs.
- Future work could explore making the mesh adaptation fully learnable within the network to further optimize accuracy.
Load-bearing premise
Embedding the Alikhanov variational loss into the neural network training along with hard and soft constraints for conditions ensures that solution accuracy is governed mainly by the choice of temporal discretization rather than by issues in the optimization process or data sampling on nonuniform meshes.
What would settle it
An experiment showing that refining the nonuniform time grid does not reduce the overall error below a certain level set by training tolerances, or that increasing network capacity fails to improve results when the mesh is fixed, would indicate the claim does not hold.
Figures








read the original abstract
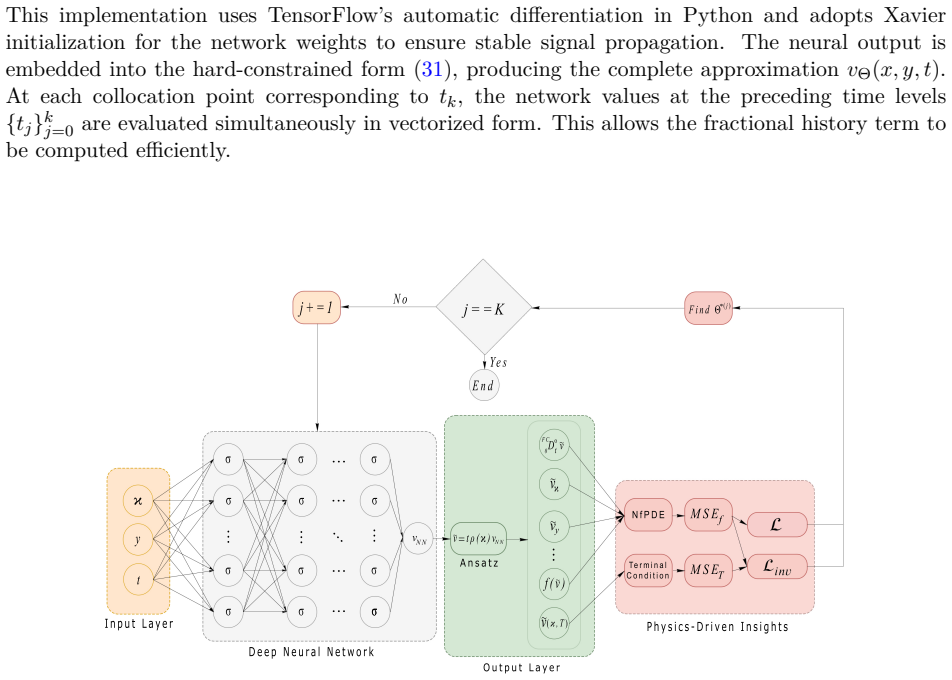
To address the initial singularity inherent in solutions to fractional partial differential equations (fPDEs), we propose an accelerated Alikhanov discretization formulation implemented on nonuniform time grids. Based on the physics-informed neural networks (PINNs) framework, we introduce an Alikhanov-extended fractional PINNs (XfPINNs) architecture that combines high-order temporal discretization and deep learning. The nonlocal memory term in fPDEs leads to high computational cost, while the weak singularity near $t\to 0^+$ can deteriorate accuracy on uniform meshes. To separate temporal discretization effects from optimization and sampling errors, we further develop an auxiliary time-marching configuration that enables auditable temporal-convergence studies under controlled training tolerances. This architecture can solve general nonlinear fPDEs. The XfPINNs approach is designed for forward and inverse problems, allowing for data-driven solution reconstruction and parameter estimation. First, the neural network approximates the solution of nonlinear fPDEs; then, an adaptive activation function accelerates convergence and enhances training efficiency. The optimization framework embeds a variational loss function constructed from the Alikhanov scheme, where the initial and boundary conditions are imposed using a combination of hard and soft constraints. Numerical experiments, including cases with known and unknown exact solutions which demonstrate the robustness, computational efficiency, and significant CPU time savings of the Alikhanov-XfPINNs method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Alikhanov-XfPINNs, which embeds an accelerated Alikhanov discretization on nonuniform time grids into the PINNs framework to solve nonlinear fractional PDEs while addressing the initial singularity at t=0+. An auxiliary time-marching configuration is introduced to separate temporal discretization effects from optimization and sampling errors, enabling controlled convergence studies. The architecture uses adaptive activation functions, a variational loss derived from the Alikhanov scheme, and a mix of hard and soft constraints for IC/BCs. It is applied to both forward and inverse problems, with numerical experiments claimed to demonstrate robustness, computational efficiency, and substantial CPU time savings.
Significance. If the error-separation claim holds and the attained training residuals remain below the O(τ^{2-α}) discretization error on graded meshes, the work would provide a practical hybrid method for nonlocal fPDEs that combines high-order temporal accuracy with the flexibility of neural networks for data-driven forward and inverse tasks, potentially offering measurable CPU savings over purely mesh-based or standard PINN approaches.
major comments (2)
- [auxiliary time-marching configuration] The central claim that accuracy is limited primarily by the temporal discretization rather than by optimization or sampling artifacts rests on the auxiliary time-marching configuration. No explicit verification is supplied showing that the minimized loss is smaller than the expected discretization error independently of mesh grading, network capacity, or the strength of the singularity at t=0+. This verification is load-bearing for the robustness and auditable-convergence assertions.
- [numerical experiments] Numerical experiments section: while the abstract states that experiments demonstrate robustness, efficiency, and CPU savings, the visible description provides no quantitative error tables, observed convergence rates, or direct baseline comparisons (e.g., against standard PINNs or graded-mesh finite-difference schemes). Without these, the efficiency claims cannot be assessed against the asserted O(τ^{2-α}) behavior.
minor comments (1)
- [methods] The notation for the variational loss and the precise definition of the adaptive activation function should be stated explicitly with equation numbers for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and will revise the manuscript to strengthen the presentation and supporting evidence.
read point-by-point responses
-
Referee: [auxiliary time-marching configuration] The central claim that accuracy is limited primarily by the temporal discretization rather than by optimization or sampling artifacts rests on the auxiliary time-marching configuration. No explicit verification is supplied showing that the minimized loss is smaller than the expected discretization error independently of mesh grading, network capacity, or the strength of the singularity at t=0+. This verification is load-bearing for the robustness and auditable-convergence assertions.
Authors: We agree that explicit verification is essential to support the central claim regarding the auxiliary time-marching configuration. The manuscript introduces this configuration specifically to enable controlled temporal-convergence studies by separating discretization effects from optimization and sampling errors. However, we acknowledge that additional checks demonstrating the minimized loss remains below the O(τ^{2-α}) discretization error—independent of mesh grading, network capacity, and singularity strength—are not sufficiently detailed. In the revised manuscript, we will add targeted numerical verifications, including comparative results across these factors, to make the auditable-convergence assertions more robust. revision: yes
-
Referee: [numerical experiments] Numerical experiments section: while the abstract states that experiments demonstrate robustness, efficiency, and CPU savings, the visible description provides no quantitative error tables, observed convergence rates, or direct baseline comparisons (e.g., against standard PINNs or graded-mesh finite-difference schemes). Without these, the efficiency claims cannot be assessed against the asserted O(τ^{2-α}) behavior.
Authors: We accept this criticism of the numerical experiments section. Although the manuscript describes experiments on forward and inverse problems with known and unknown solutions and asserts robustness, efficiency, and CPU savings, we recognize that quantitative error tables, explicit convergence rates, and direct baseline comparisons are not provided in sufficient detail. In the revision, we will expand the section to include comprehensive error tables, plots of observed convergence rates verifying the O(τ^{2-α}) behavior on graded meshes, and comparisons against standard PINNs and graded-mesh finite-difference schemes to allow proper assessment of the efficiency claims. revision: yes
Circularity Check
No circularity: derivation relies on external Alikhanov scheme and standard PINN loss without self-referential reduction
full rationale
The paper constructs XfPINNs by embedding the known Alikhanov variational discretization (a prior external scheme) into a standard physics-informed neural network loss, augmented with adaptive activations, hard/soft constraints, and an auxiliary time-marching setup for controlled convergence studies. No equation or claim reduces the asserted accuracy, efficiency, or error control to a fitted parameter or quantity defined by the method itself; the auxiliary configuration is an independent design choice to isolate discretization order from optimization artifacts, and numerical experiments provide external validation rather than tautological confirmation. The architecture therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Alikhanov discretization provides a consistent high-order approximation to the fractional derivative on nonuniform meshes with controlled truncation error near t=0.
- domain assumption A neural network with adaptive activation can approximate the solution of the nonlinear fPDE sufficiently well that the embedded discretization error dominates the total error.
Reference graph
Works this paper leans on
-
[1]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Adv. Neural Process. Syst. (2012) 1097-1105
2012
-
[2]
B. M. Lake, R. Salakhutdinov, J. B. Tenenbaum, Human-level concept learning through prob- abilistic program induction, Science 350 (2015) 1332-1338
2015
-
[3]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learn- ing framework for solving forward and inverse problem involving nonlinear partial differential equations, J. Comput. Phys. 378 (2019) 686-707. 29
2019
-
[4]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, L. Yang, Physics-informed machine learning, Nat. Rev. Phys. 3(6) (2021) 422-440
2021
-
[5]
X. Jin, S. Cai, H. Li, G. E. Karniadakis, NSFnets (Navier-Stokes flow nets): Physics-informed neural networks for the incompressible Navier-Stokes equations, J. Comput. Phys. 426 (2021) 109951
2021
-
[6]
Raissi, Z
M. Raissi, Z. Wang, M. S. Triantafyllou, G. E. Karniadakis, Deep learning of vortex-induced vibrations, J. Fluid Mech. 861 (2019) 119-137
2019
-
[7]
D. Liu, Y. Wang, Multi-fidelity physics-constrained neural network and its application in ma- terial modeling, J. Mech. Des. 141(12) (2019) 121403
2019
-
[8]
Kissas, Y
G. Kissas, Y. Yang, E. Hwuang, W. R. Witschey, J. A. Detre, P. Perdikaris, Machine learning in cardiovascular flows modeling: predicting arterial blood pressure from non-invasive 4D flow MRI data using physics-informed neural networks, Comput. Methods Appl. Mech. Eng. 358 (2020) 112623
2020
-
[9]
Sirignano, K
J. Sirignano, K. Spiliopoulos, DGM: A deep learning algorithm for solving partial differential equations, J. Comput. Phys. 375 (2018) 1339-1364
2018
-
[10]
L. Lu, X. Meng, Z. Mao, G. E. Karniadakis, DeepXDE: a deep learning library for solving differential equations, SIAM Rev. 63(1) (2021) 208-228
2021
-
[11]
S. Wang, S. Sankaran, P. Perdikaris, Respecting causality for training physics-informed neural networks, Comput. Methods Appl. Mech. Eng Phys. 421 (2024) 116813
2024
-
[12]
Basdevant, M
C. Basdevant, M. Deville, P. Haldenwang, J. Lacorix, J. Ouazzani, R. Peyret, P. Orlandi, A. Patera, Spectral and finite difference solutions of the Burgers’ equation, Comput. Fluids. 14 (1986) 23-41
1986
-
[13]
Z. Sun, G. Gao, Fractional differential equations: finite difference methods, De Gruyter, Berlin (2020)
2020
-
[14]
B. Jin, R. Lazarov, Z. Zhou, An analysis of the L1 scheme for the subdiffusion equation with nonsmooth data, IMA J. Numer. Anal. 36 (2016) 197–221
2016
-
[15]
Stynes, E
M. Stynes, E. O´Riordan, J. Gracia, Error analysis of a finite difference method on graded meshes for a time-fractional diffusion equation, SIAM J. Numer. Anal. 55(2) (2017) 1057– 1079
2017
-
[16]
McLean, Regularity of solutions to a time-fractional diffusion equation, ANZIAM J
W. McLean, Regularity of solutions to a time-fractional diffusion equation, ANZIAM J. 52 (2010) 123–138
2010
-
[17]
H. Chen, M. Stynes, Error analysis of a second-order method on fitted meshes for a time- fractional diffusion problem, J. Sci. Comput. 79(1) (2019) 624–647
2019
-
[18]
Jiang, J
S. Jiang, J. Zhang, Q. Zhang, Z. Zhang, Fast evaluation of the Caputo fractional derivative and its applications to fractional differential equations, Commun. Comput. Phys. 21(3) (2017). 650-678. 30
2017
-
[19]
H. K. Dwivedi, Rajeev, A novel fast second order approach with high-order compact difference scheme and its analysis for the tempered fractional Burgers equation, Math. Comput. Simul. 227 (2025) 168-188
2025
-
[20]
H. K. Dwivedi, Rajeev, A novel fast tempered algorithm with high-accuracy scheme for 2D tempered fractional reaction-advection-subdiffusion equation, Comput. Math. Appl. 176 (2024) 371-397
2024
-
[21]
J. Cao, A. Xiao, W. Bu, Finite difference/finite element method for the tempered time fractional advection-dispersion equation with fast evaluation of Caputo derivatives, J. Sci. Comput. (2020) 83:48
2020
-
[22]
Y. Yan, Z. Z. Sun, J. Zhang, Fast evaluation of the Caputo fractional derivative and its ap- plications to fractional diffusion equations: a second order scheme, Commun. Comput. Phys. 22(4) (2017) 1028-1048
2017
-
[23]
X. Li, H. L. Liao, L. Zhang, A second-order fast compact scheme with unequal time-steps for subdiffusion problems, Numer. Algor. 86 (2021) 1011–1039
2021
-
[24]
Luchko, W
Y. Luchko, W. Rundell, M. Yamamoto, L. Zuo, Uniqueness and reconstruction of an unknown semilinear term in a time-fractional reaction diffusion equation, Inverse Probl. 29(6) (2013) 065019
2013
-
[25]
Kern, Numerical methods for inverse problems, Wiley, Hoboken (2016)
M. Kern, Numerical methods for inverse problems, Wiley, Hoboken (2016)
2016
-
[26]
Lukyanenko, R
D. Lukyanenko, R. Argun, A. Borzunov, A. Gorbachev, V. Shinkarev, M. Shislenin, A. Yagola, On the features of numerical solution of coefficient inverse problems for nonlinear equations of the reaction-diffusion-advection type with data of various types, Differ. Equ. 59(12) (2023) 1734-1757
2023
-
[27]
X. An, Q. Wang, F. Liu, V. V. Anh, I. W. Turner, Parameter estimation for time-fractional Black-Scholes equation with S&P 500 index option, Numer. Algor. 95(1) (2024) 1-30
2024
-
[28]
Srati, A
M. Srati, A. Oulmelk, L. Afraites, A. Hadri, M. A. Zaky, A. Aldraiweesh, A. S. Hendy, An in- verse problem of determining the parameters in diffusion equations by using fractional physics- informed neural networks, Appl. Numer. Math. 208 (2025) 189-213
2025
-
[29]
L. Ma, R. Li, F. Zeng, L. Guo, G. E. Karniadakis, Bi-orthogonal fPINN: a physics-informed neural network method for solving time-dependent stochastic fractional PDEs, Commun. Comput. Phys. 34(4) (2023) 1133-1176
2023
-
[30]
X. Fang, L. Qiao, F. Zhang, F. Sun, Explore deep network for a class of fractional partial differential equations, Chaos Solitons Fractals 172 (2022) 113528
2022
-
[31]
J. Shi, X. Liu, X, Yang, Data-driven solutions and parameter estimation of the high-dimensional time-fractional reaction-diffusion equations using an improved fPINN method, Nonlinear Dyn. 113 (2025) 9577-9604
2025
-
[32]
G. Pang, L. Lu, G. E. Karniadakis, fPINNS: fractional physics-informed neural networks, SIAM J. Sci. Comput. 41(4) (2019) 2603-2626 . 31
2019
-
[33]
S. Wang, H. Zhang, X. Jiang, Fractional physics-informed neural networks for time-fractional phase field models, Nonlin. Dyn. 110(3) (2022) 2715-2739
2022
-
[34]
Z. Ma, J. Hou, W. Zhu, Y. Peng, Y. Li, PMNN: physical model driven neural network for solving time-fractional differential equations, Chaos Solitons Fractals 177 (2023) 114238
2023
-
[35]
H. Ren, X. Meng, R. Liu, J. Hou, Y. Yu, A class of improved fractional physics-informed neural networks, Neurocomputing 562 (2023) 126890
2023
-
[36]
H. L. Liao, , D. Li, J. Zhang, Sharp error estimate of nonuniform L1 formula for time-fractional reaction-subdiffusion equations, SIAM J. Numer. Anal. 56 (2018) 1112–1133
2018
-
[37]
A. A. Alikhanov, A new difference scheme for the time fractional diffusion equation, J. Comput. Phys. 280, (2015) 424-438
2015
-
[38]
H. L. Liao, W. Mclean, J. Zhang, A second-order scheme with nonuniform time steps for a linear reaction-subdiffusion problem, Commun. Comput. Phys. 30(2), (2021) 567-601
2021
-
[39]
A. D. Jagtap, K. Kawaguchi, G. E. Karniadakis, Adaptive activation functions accelerate convergence in deep and physics-informed neural networks, J. Comput. Phys. 404, (2020) 109136
2020
-
[40]
H. Gao, L. Sun, J. Wang, PhyGeoNet: physics-informed geometry-adaptive convolutional neu- ral networks for solving parametrized steady-state PDE on irregular domain, J. Comput. Phys. 428, (2021) 110079
2021
-
[41]
J. Shi, X. Liu, X. Yang, Data-driven solutions and parameter estimation of the high-dimensional time-fractional reaction-diffusion equations using an improved fPINN method, Nonlin. Dyn. 113 (2025)9577-9604
2025
-
[42]
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
M. Abadi, A. Agarwal, P. Barham, E. Brevdeo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al., Tensorflow: Large-scale machine learning on heterogeneous distributed systems, arXiv:1603.04467 (2016)
work page Pith review arXiv 2016
-
[43]
Barkat, P
A. Barkat, P. Bianchi, Convergence and dynamical behavior of the ADAM algorithm for non- convex stochastic optimization, SIAM J. Optim. 31(1) (2021) 244-274. 32
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.