Recognition: unknown
CUE: Concept-Aware Multi-Label Expansion to Mitigate Concept Confusion in Long-Tailed Learning
Pith reviewed 2026-05-09 14:35 UTC · model grok-4.3
The pith
Multi-label concept signals from CLIP visuals and LLM semantics preserve inter-class feature sharing disrupted by single-label training on long-tailed data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
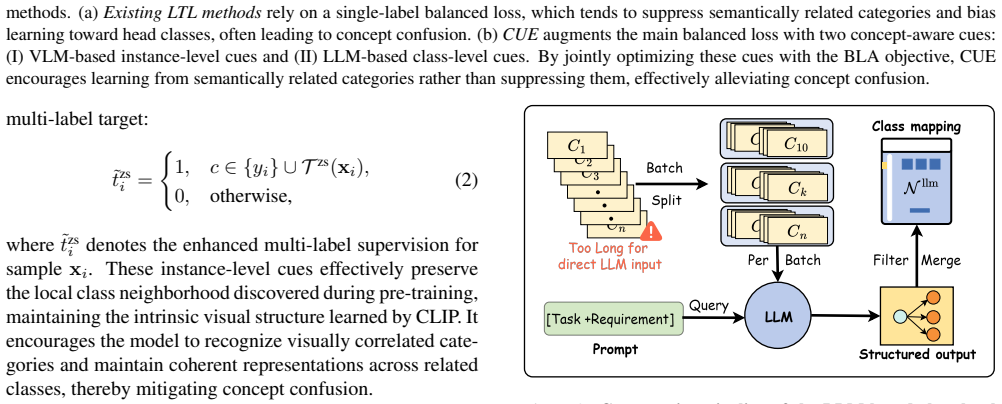
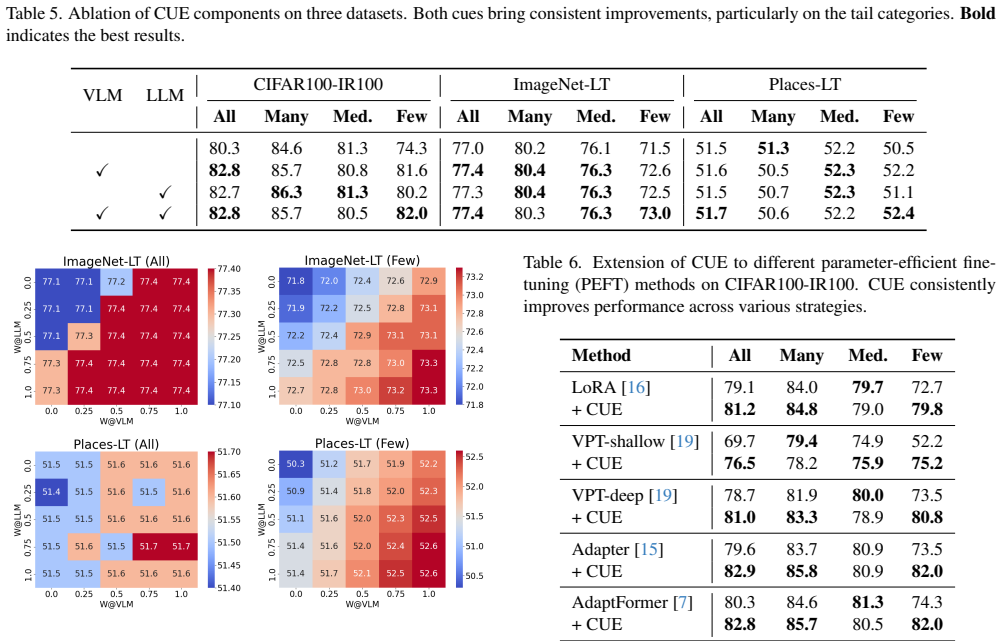
CUE constructs concept sets by extracting instance-level visual cues from zero-shot CLIP and generating class-level semantic cues with an LLM; the two cues are incorporated via separately weighted Binary Logit-Adjustment auxiliary losses and jointly optimized with the baseline Logit-Adjustment loss, which mitigates the concept confusion caused by mutual exclusivity of single-label supervision under long-tailed distributions.
What carries the argument
CUE, the concept-aware multi-label expansion that builds auxiliary concept sets from CLIP visual cues and LLM semantic cues and folds them into weighted Binary Logit-Adjustment losses.
If this is right
- The auxiliary losses let the model learn shared features among concept-related classes without undoing the tail-class boost from logit adjustment.
- Performance becomes more balanced because head-class dominance is reduced while tail-class accuracy rises.
- The same cue construction and loss weighting can be applied on top of other logit-adjustment or re-weighting baselines.
- Joint optimization of the main loss and the two auxiliary losses ensures the added signals reinforce rather than compete with distribution correction.
Where Pith is reading between the lines
- If cue quality scales with future improvements in vision-language and language models, long-tailed recognition accuracy would continue to rise without new labeled data.
- The same multi-label expansion idea could be tested in non-vision long-tailed settings by swapping CLIP for domain-appropriate cue extractors.
- Manual inspection of the extracted concept sets on a small held-out set would show whether the method's success depends on high cue precision.
Load-bearing premise
The cues pulled from zero-shot CLIP and generated by the LLM correctly identify genuine inter-class relationships and do not add enough noise or wrong multi-label assignments to hurt overall discriminability.
What would settle it
Retraining the identical baseline with the same auxiliary losses but replacing the CLIP and LLM concept sets with random or shuffled labels; if accuracy falls back to or below the plain Logit-Adjustment baseline, the specific content of the cues is required for the reported gains.
Figures



read the original abstract
Long-tailed distributions are common in real-world recognition tasks, where a few head classes have many samples while most tail classes have very few. Recently, fine-tuning foundation models for long-tailed learning has gained attention due to their excellent performance. However, most existing methods focus solely on mitigating long-tailed distribution bias while overlooking concept confusion caused by the long-tailed distribution. In this paper, we study this problem and attribute it to the mutual exclusivity of single-label supervision under long-tailed distributions, which suppresses feature sharing among related classes and amplifies the dominance of head classes, leading to disrupted inter-class discriminability. To address this, we propose CUE, Concept-aware mUlti-label Expansion, which introduces multi-label concept signals to preserve disrupted inter-class relationships. Specifically, CUE constructs concept sets by (i) extracting instance-level visual cues from zero-shot CLIP and (ii) generating class-level semantic cues with LLM; the two cues are incorporated via separately weighted Binary Logit-Adjustment (BLA) auxiliary losses and jointly optimized with the baseline Logit-Adjustment (LA) loss. Experiments on several long-tailed benchmarks, CUE achieves balanced and strong performance, surpassing recent state-of-the-art methods. Code is available at: https://github.com/zhangruichi/CUE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that long-tailed distributions cause concept confusion by enforcing mutual exclusivity in single-label supervision, which suppresses feature sharing among related classes and amplifies head-class dominance. To address this, CUE extracts instance-level visual cues via zero-shot CLIP and class-level semantic cues via LLM to expand labels into multi-label concept sets; these are incorporated through separately weighted Binary Logit-Adjustment (BLA) auxiliary losses that are jointly optimized with the baseline Logit-Adjustment (LA) loss. Experiments on long-tailed benchmarks are reported to yield balanced performance that surpasses recent state-of-the-art methods.
Significance. If the central claim holds, the work usefully identifies an overlooked source of inter-class discriminability loss in long-tailed learning and demonstrates a practical way to restore it by leveraging foundation-model cues without extra labeled data. The open-sourced code at the provided GitHub link is a clear strength for reproducibility.
major comments (2)
- [§3.2] §3.2 (Concept Set Construction): the central claim that the CLIP and LLM cues accurately recover disrupted inter-class relationships rests on an unverified assumption; the manuscript should report quantitative validation of cue quality (e.g., precision/recall of the generated multi-label assignments on a held-out subset or human annotation study), broken down by head vs. tail classes, because zero-shot CLIP accuracy is known to degrade on tail classes and LLM cues are generic.
- [§4] §4 (Experiments): the reported gains on long-tailed benchmarks do not isolate whether improvements stem from faithful concept signals or from the mere addition of auxiliary regularization; an ablation replacing the extracted cues with random or empty multi-label targets while keeping the BLA losses should be added to test this.
minor comments (2)
- [Abstract] Abstract: the phrase 'several long-tailed benchmarks' should name the specific datasets (e.g., CIFAR-100-LT, ImageNet-LT) for immediate clarity.
- [§3.3] Notation: the weighting factors for the two BLA losses are introduced as free parameters; a brief sensitivity analysis or default-value justification would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the presentation of our central claims. We address each major comment below and will incorporate the suggested analyses into the revised manuscript to strengthen the evidence for our approach.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Concept Set Construction): the central claim that the CLIP and LLM cues accurately recover disrupted inter-class relationships rests on an unverified assumption; the manuscript should report quantitative validation of cue quality (e.g., precision/recall of the generated multi-label assignments on a held-out subset or human annotation study), broken down by head vs. tail classes, because zero-shot CLIP accuracy is known to degrade on tail classes and LLM cues are generic.
Authors: We agree that direct quantitative validation of cue quality would provide stronger support for the assumption that the CLIP and LLM cues recover meaningful inter-class relationships. While the downstream performance gains on long-tailed benchmarks offer indirect evidence of cue utility, we acknowledge that explicit metrics are needed, especially given known limitations of zero-shot CLIP on tail classes. In the revision, we will add a cue-quality analysis including precision/recall of the generated multi-label assignments against a held-out subset (where ground-truth multi-label annotations can be obtained) and a small-scale human annotation study on randomly sampled images. Results will be broken down by head versus tail classes to quantify any degradation. revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains on long-tailed benchmarks do not isolate whether improvements stem from faithful concept signals or from the mere addition of auxiliary regularization; an ablation replacing the extracted cues with random or empty multi-label targets while keeping the BLA losses should be added to test this.
Authors: We concur that an ablation isolating the contribution of the specific concept signals versus generic auxiliary regularization is necessary to substantiate our claims. To address this, we will include a new ablation in Section 4 where the extracted multi-label concept sets are replaced with random or empty targets while retaining the Binary Logit-Adjustment (BLA) losses and their weighting scheme. This will allow direct comparison to the original CUE results and clarify whether the observed balanced performance improvements arise from the faithful visual and semantic cues or from the multi-label loss structure alone. revision: yes
Circularity Check
No circularity: method and losses defined independently of results
full rationale
The paper defines CUE by constructing concept sets from external zero-shot CLIP instance cues and LLM class cues, then applies separately weighted BLA auxiliary losses jointly optimized with baseline LA loss. This construction and optimization are specified without reference to the final performance numbers or to any fitted parameter that is later renamed as a prediction. No equations reduce the inter-class discriminability claim to a self-definition, no self-citation chain supplies a uniqueness theorem, and no ansatz is smuggled via prior work by the same authors. Evaluation occurs on standard external long-tailed benchmarks, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- BLA auxiliary loss weights
axioms (2)
- domain assumption Zero-shot CLIP extracts reliable instance-level visual concept cues
- domain assumption LLMs generate accurate class-level semantic concept cues
Reference graph
Works this paper leans on
-
[1]
Cdul: Clip-driven unsupervised learning for multi-label image classification
Rabab Abdelfattah, Qing Guo, Xiaoguang Li, Xiaofeng Wang, and Song Wang. Cdul: Clip-driven unsupervised learning for multi-label image classification. InICCV, pages 1348–1357, 2023. 3
2023
-
[2]
Application and development of artificial intelligence and intelligent disease diagnosis.Current pharmaceutical design, 26(26):3069–3075, 2020
Chunyan Ao, Shunshan Jin, Hui Ding, Quan Zou, and Liang Yu. Application and development of artificial intelligence and intelligent disease diagnosis.Current pharmaceutical design, 26(26):3069–3075, 2020. 2
2020
-
[3]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani. On the opportunities and risks of founda- tion models.arXiv preprint arXiv:2108.07258, 2021. 2
work page internal anchor Pith review arXiv 2021
-
[4]
Lan- guage models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners. 33:1877–1901, 2020. 2
1901
-
[5]
Learning imbalanced datasets with label- distribution-aware margin loss
Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label- distribution-aware margin loss. InNeurIPS, 2019. 2, 5
2019
-
[6]
Softmatch: Addressing the quantity-quality tradeoff in semi- supervised learning
Hao Chen, Ran Tao, Yue Fan, Yidong Wang, Jindong Wang, Bernt Schiele, Xing Xie, Bhiksha Raj, and Marios Savvides. Softmatch: Addressing the quantity-quality tradeoff in semi- supervised learning. InICLR, 2023. 3
2023
-
[7]
Adaptformer: Adapt- ing vision transformers for scalable visual recognition
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapt- ing vision transformers for scalable visual recognition. In NeurIPS, pages 16664–16678, 2022. 3, 5, 7
2022
-
[8]
Reslt: Residual learning for long-tailed recogni- tion.IEEE TPAMI, 45(3):3695–3706, 2022
Jiequan Cui, Shu Liu, Zhuotao Tian, Zhisheng Zhong, and Jiaya Jia. Reslt: Residual learning for long-tailed recogni- tion.IEEE TPAMI, 45(3):3695–3706, 2022. 7, 8
2022
-
[9]
Class-balanced loss based on effective number of samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InCVPR, pages 9268–9277, 2019. 2
2019
-
[10]
LPT: Long-tailed prompt tuning for image classifica- tion
Bowen Dong, Pan Zhou, Shuicheng Y AN, and Wangmeng Zuo. LPT: Long-tailed prompt tuning for image classifica- tion. InICLR, 2023. 2, 3, 5, 6
2023
-
[11]
Dtl: Parameter-and memory-efficient disentangled vision learn- ing.IEEE TPAMI, 2025
Minghao Fu, Ke Zhu, Zonghao Ding, and Jianxin Wu. Dtl: Parameter-and memory-efficient disentangled vision learn- ing.IEEE TPAMI, 2025. 3
2025
-
[12]
Improving diffusion models for class-imbalanced training data via capacity manipulation
Feng Hong, Jiangchao Yao, Yifei Shen, Dongsheng Li, Ya Zhang, and Yanfeng Wang. Improving diffusion models for class-imbalanced training data via capacity manipulation. In ICLR, 2026. 2
2026
-
[13]
Disentangling label dis- tribution for long-tailed visual recognition
Youngkyu Hong, Seungju Han, Kwanghee Choi, Seokjun Seo, Beomsu Kim, and Buru Chang. Disentangling label dis- tribution for long-tailed visual recognition. InCVPR, pages 6626–6636, 2021. 2
2021
-
[14]
Learning to explore sample relationships
Zhi Hou, Baosheng Yu, Chaoyue Wang, Yibing Zhan, and Dacheng Tao. Learning to explore sample relationships. IEEE TPAMI, 2025. 2
2025
-
[15]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InICML, pages 2790–2799. PMLR, 2019. 3, 7
2019
-
[16]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In ICLR, 2022. 2, 3, 7
2022
-
[17]
Simple: Similar pseudo label exploitation for semi- supervised classification
Zijian Hu, Zhengyu Yang, Xuefeng Hu, and Ram Neva- tia. Simple: Similar pseudo label exploitation for semi- supervised classification. InCVPR, pages 15099–15108,
-
[18]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InICML, pages 4904– 4916, 2021. 2
2021
-
[19]
Vi- sual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning. InECCV, pages 709–727, 2022. 2, 3, 7
2022
-
[20]
Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019. 2
2019
-
[21]
Exploring balanced feature spaces for representation learn- ing
Bingyi Kang, Yu Li, Sa Xie, Zehuan Yuan, and Jiashi Feng. Exploring balanced feature spaces for representation learn- ing. InICLR, 2020. 7
2020
-
[22]
Decou- pling representation and classifier for long-tailed recogni- tion
Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decou- pling representation and classifier for long-tailed recogni- tion. InICLR, 2020. 2
2020
-
[23]
Long-tailed visual recognition via gaussian clouded logit adjustment
Mengke Li, Yiu-ming Cheung, and Yang Lu. Long-tailed visual recognition via gaussian clouded logit adjustment. In CVPR, pages 6929–6938, 2022. 2
2022
-
[24]
Improving visual prompt tuning by gaussian neighborhood minimization for long-tailed visual recognition
Mengke Li, Ye Liu, Yang Lu, Yiqun Zhang, Yiu-ming Che- ung, and Hui Huang. Improving visual prompt tuning by gaussian neighborhood minimization for long-tailed visual recognition. InNeurIPS, pages 103985–104009, 2024. 2
2024
-
[25]
Large-scale long-tailed recognition in an open world
Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Boqing Gong, and Stella X Yu. Large-scale long-tailed recognition in an open world. InCVPR, pages 2537–2546,
-
[26]
Retrieval augmented clas- sification for long-tail visual recognition
Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, and Anton Van den Hengel. Retrieval augmented clas- sification for long-tail visual recognition. InCVPR, pages 6959–6969, 2022. 2, 5, 6
2022
-
[27]
Long-tailed recognition with model re- balancing.NeurIPS, 2025
Jiaan Luo, Feng Hong, Qiang Hu, Xiaofeng Cao, Feng Liu, and Jiangchao Yao. Long-tailed recognition with model re- balancing.NeurIPS, 2025. 2
2025
-
[28]
Teli Ma, Shijie Geng, Mengmeng Wang, Jing Shao, Jiasen Lu, Hongsheng Li, Peng Gao, and Yu Qiao. A simple long- tailed recognition baseline via vision-language model.arXiv preprint arXiv:2111.14745, 2021. 5, 6
-
[29]
Lessons and insights from a unifying study of parameter-efficient fine-tuning (peft) in visual recognition
Zheda Mai, Ping Zhang, Cheng-Hao Tu, Hong-You Chen, Quang-Huy Nguyen, Li Zhang, and Wei-Lun Chao. Lessons and insights from a unifying study of parameter-efficient fine-tuning (peft) in visual recognition. InCVPR, pages 14845–14857, 2025. 3
2025
-
[30]
Long-tail learning via logit adjustment
Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. InICLR, 2021. 2, 3, 7, 8
2021
-
[31]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, pages 8748–8763, 2021. 2
2021
-
[32]
How re-sampling helps for long-tail learning? InNeurIPS, pages 75669–75687, 2023
Jiang-Xin Shi, Tong Wei, Yuke Xiang, and Yu-Feng Li. How re-sampling helps for long-tail learning? InNeurIPS, pages 75669–75687, 2023. 2
2023
-
[33]
Long-tail learning with foundation model: Heavy fine-tuning hurts
Jiang-Xin Shi, Tong Wei, Zhi Zhou, Jie-Jing Shao, Xin-Yan Han, and Yu-Feng Li. Long-tail learning with foundation model: Heavy fine-tuning hurts. InICML, pages 45014– 45039, 2024. 1, 2, 3, 5, 6
2024
-
[34]
Lift+: Lightweight fine-tuning for long-tail learning.arXiv preprint arXiv:2504.13282, 2025
Jiang-Xin Shi, Tong Wei, and Yu-Feng Li. Lift+: Lightweight fine-tuning for long-tail learning.arXiv preprint arXiv:2504.13282, 2025. 2
-
[35]
Fixmatch: Simplifying semi-supervised learning with consistency and confidence
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. InNeurIPS, pages 596–608, 2020. 3
2020
-
[36]
Adapters strike back
Jan-Martin O Steitz and Stefan Roth. Adapters strike back. InCVPR, pages 23449–23459, 2024. 2
2024
-
[37]
Rethinking classifier re-training in long-tailed recognition: Label over- smooth can balance
Siyu Sun, Han Lu, Jiangtong Li, Yichen Xie, Tianjiao Li, Xiaokang Yang, Liqing Zhang, and Junchi Yan. Rethinking classifier re-training in long-tailed recognition: Label over- smooth can balance. InICLR, pages 26681–26697, 2025. 7, 8
2025
-
[38]
Vl-ltr: Learning class-wise visual-linguistic repre- sentation for long-tailed visual recognition
Changyao Tian, Wenhai Wang, Xizhou Zhu, Jifeng Dai, and Yu Qiao. Vl-ltr: Learning class-wise visual-linguistic repre- sentation for long-tailed visual recognition. InECCV, pages 73–91, 2022. 2, 5, 6
2022
-
[39]
The inaturalist species classification and de- tection dataset
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and de- tection dataset. InCVPR, pages 8769–8778, 2018. 2, 5
2018
-
[40]
Kill two birds with one stone: Rethinking data augmentation for deep long-tailed learning
Binwu Wang, Pengkun Wang, Wei Xu, Xu Wang, Yudong Zhang, Kun Wang, and Yang Wang. Kill two birds with one stone: Rethinking data augmentation for deep long-tailed learning. InICLR, 2024. 7, 8
2024
-
[41]
Debiased learning from naturally imbalanced pseudo-labels
Xudong Wang, Zhirong Wu, Long Lian, and Stella X Yu. Debiased learning from naturally imbalanced pseudo-labels. InCVPR, pages 14647–14657, 2022. 3
2022
-
[42]
Exploring vision-language models for imbalanced learning
Yidong Wang, Zhuohao Yu, Jindong Wang, Qiang Heng, Hao Chen, Wei Ye, Rui Xie, Xing Xie, and Shikun Zhang. Exploring vision-language models for imbalanced learning. IJCV, 132(1):224–237, 2024. 2, 6
2024
-
[43]
Lmpt: Prompt tuning with class-specific embedding loss for long- tailed multi-label visual recognition
Peng Xia, Di Xu, Ming Hu, Lie Ju, and Zongyuan Ge. Lmpt: Prompt tuning with class-specific embedding loss for long- tailed multi-label visual recognition. InALVR, pages 26–36,
-
[44]
Yi Xin, Siqi Luo, Haodi Zhou, Junlong Du, Xiaohong Liu, Yue Fan, Qing Li, and Yuntao Du. Parameter-efficient fine-tuning for pre-trained vision models: A survey.arXiv preprint arXiv:2402.02242, 2024. 3
-
[45]
Learning imbalanced data with vision trans- formers
Zhengzhuo Xu, Ruikang Liu, Shuo Yang, Zenghao Chai, and Chun Yuan. Learning imbalanced data with vision trans- formers. InCVPR, pages 15793–15803, 2023. 5, 6
2023
-
[46]
An auto-driving system by interactive driving knowledge acquisition
Seiji Yasunobu and Ryota Sasaki. An auto-driving system by interactive driving knowledge acquisition. InSICE 2003 Annual Conference (IEEE Cat. No. 03TH8734), pages 2935– 2938, 2003. 2
2003
-
[47]
A systematic review on long-tailed learning.IEEE TNNLS, 2025
Chongsheng Zhang, George Almpanidis, Gaojuan Fan, Bin- quan Deng, Yanbo Zhang, Ji Liu, Aouaidjia Kamel, Paolo Soda, and Jo ˜ao Gama. A systematic review on long-tailed learning.IEEE TNNLS, 2025. 2
2025
-
[48]
Otamatch: Optimal transport assign- ment with pseudonce for semi-supervised learning.IEEE TIP, 2024
Jinjin Zhang, Junjie Liu, Debang Li, Qiuyu Huang, Jiaxin Chen, and Di Huang. Otamatch: Optimal transport assign- ment with pseudonce for semi-supervised learning.IEEE TIP, 2024. 3
2024
-
[49]
Distribution alignment: A unified framework for long-tail visual recognition
Songyang Zhang, Zeming Li, Shipeng Yan, Xuming He, and Jian Sun. Distribution alignment: A unified framework for long-tail visual recognition. InCVPR, pages 2361–2370,
-
[50]
Long-tailed diffusion models with oriented calibration
Tianjiao Zhang, Huangjie Zheng, Jiangchao Yao, Xiangfeng Wang, Mingyuan Zhou, Ya Zhang, and Yanfeng Wang. Long-tailed diffusion models with oriented calibration. In ICLR, 2024. 2
2024
-
[51]
Deep long-tailed learning: A survey.IEEE TPAMI, 45(9):10795–10816, 2023
Yifan Zhang, Bingyi Kang, Bryan Hooi, Shuicheng Yan, and Jiashi Feng. Deep long-tailed learning: A survey.IEEE TPAMI, 45(9):10795–10816, 2023. 2
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.