Recognition: unknown
PACE: Post-Causal Entropy Modeling for Learned LiDAR Point Cloud Compression
Pith reviewed 2026-05-09 14:31 UTC · model grok-4.3
The pith
PACE decouples context aggregation from probability prediction to cut latency in LiDAR compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
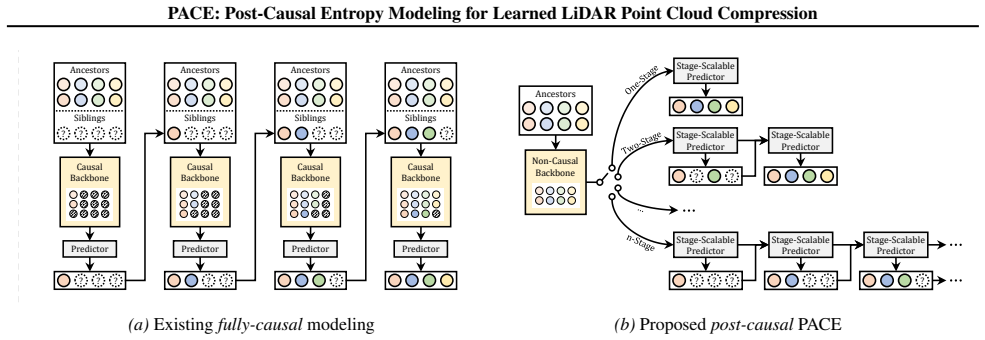
PACE reformulates ancestral context aggregation as a non-causal backbone and confines causality to a lightweight, stage-scalable predictor. This breaks the tight coupling that forces repetitive backbone runs, eliminates the rigid performance-latency trade-off, and supports an arbitrary number of prediction stages without reloading parameters.
What carries the argument
Post-causal entropy modeling that uses a non-causal backbone for context aggregation and a lightweight predictor whose number of stages can be chosen at runtime.
Load-bearing premise
A non-causal backbone still supplies enough context for the lightweight predictor to produce accurate probability estimates without loss of modeling power.
What would settle it
If experiments on standard LiDAR datasets show that the reported BD-BR savings disappear or that decoding latency does not drop by the claimed amount when the backbone is made non-causal, the central claim would be falsified.
Figures










read the original abstract
LiDAR point cloud compression is vital for autonomous systems to handle massive data from high-resolution sensors. While learned entropy modeling built upon octree structures yields high compression gains, it faces two critical bottlenecks: 1) prohibitive latency, particularly during decoding, caused by causal, multi-stage context modeling; and 2) a rigid performance-latency trade-off, preventing a single model from adapting to varying constraints. These limitations stem from the tight coupling between context aggregation backbone and probability prediction. To address this, we propose PACE, a new framework that reformulates ancestral context aggregation as a non-causal backbone and confines causality to a lightweight, stage-scalable predictor, eliminating repetitive backbone executions and reducing computational overhead. The predictor supports an arbitrary number of prediction stages, supporting seamless adaptation across diverse performance-latency trade-offs without reloading parameters. Experiments demonstrate that PACE sets a new state-of-the-art in compression efficiency, achieving notable BD-BR savings and reducing decoding latency by over 90% in autoregressive mode, highly attractive for practical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PACE, a framework for learned LiDAR point cloud compression that decouples ancestral context aggregation into a non-causal backbone while confining causality to a lightweight, stage-scalable predictor. This reformulation is claimed to eliminate repetitive backbone executions during decoding, support arbitrary numbers of prediction stages for flexible performance-latency trade-offs without parameter changes, and deliver new state-of-the-art results including notable BD-BR savings and over 90% reduction in autoregressive decoding latency.
Significance. If the decoupling preserves modeling power without causality violations or unquantified approximation errors, the work could meaningfully advance practical deployment of learned compression for high-resolution LiDAR in autonomous systems by resolving the latency bottleneck that has limited prior octree-based autoregressive models. The stage-scalable predictor is a potentially useful contribution for adapting to varying constraints.
major comments (2)
- The abstract asserts experimental superiority with BD-BR savings and >90% decoding latency reduction, but supplies no datasets, baselines, ablation details, or quantitative tables; the support for the central claim cannot be evaluated.
- Architecture description (non-causal backbone): the claim that backbone outputs supply exactly the same information as the original tightly-coupled causal model without leakage of undecoded voxels or siblings is load-bearing for both the SOTA and latency claims, yet no equation, masking schedule, or computation diagram is referenced showing how the backbone remains available at decode time under strict octree causality (each probability depending only on prior decoded nodes).
minor comments (2)
- The abstract could be strengthened by briefly naming the datasets and primary baselines used to support the SOTA claim.
- Consider adding a diagram of the decoupled backbone-predictor information flow to aid readability of the core architectural change.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating revisions made to strengthen the presentation.
read point-by-point responses
-
Referee: The abstract asserts experimental superiority with BD-BR savings and >90% decoding latency reduction, but supplies no datasets, baselines, ablation details, or quantitative tables; the support for the central claim cannot be evaluated.
Authors: We agree that the abstract, by design, offers only a high-level summary. The full experimental details—including the datasets (SemanticKITTI, KITTI, and others), baseline methods, ablation studies, and quantitative tables reporting BD-BR savings and latency reductions—are provided in Sections 4 and 5 of the manuscript. To improve the abstract's standalone support for the claims, we have added a concise sentence referencing the key experimental configurations and results while respecting length constraints. revision: partial
-
Referee: Architecture description (non-causal backbone): the claim that backbone outputs supply exactly the same information as the original tightly-coupled causal model without leakage of undecoded voxels or siblings is load-bearing for both the SOTA and latency claims, yet no equation, masking schedule, or computation diagram is referenced showing how the backbone remains available at decode time under strict octree causality (each probability depending only on prior decoded nodes).
Authors: This is a valid and important observation regarding the core technical contribution. The original manuscript described the decoupling in Section 3 but did not include sufficient formalization. In the revised version, we have added explicit equations in Section 3.2 defining the non-causal backbone computation, a detailed masking schedule that restricts context to only prior-decoded nodes (preventing leakage from undecoded voxels or siblings), and a new computation diagram (Figure 3) illustrating data availability and flow during both encoding and autoregressive decoding. These additions confirm that the backbone outputs match those of the original causal model while enabling the reported latency gains. revision: yes
Circularity Check
No circularity: architectural separation presented without self-referential derivations
full rationale
The paper proposes PACE by decoupling a non-causal backbone from a causal predictor to address latency in octree-based entropy modeling. No equations, fitted parameters, or first-principles derivations are shown that reduce to inputs by construction. The abstract and description contain no self-citations invoked as uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known results as new organization. The central claim rests on empirical BD-BR and latency measurements rather than tautological redefinition of context aggregation or probability prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qi, Charles Ruizhongtai and Yi, Li and Su, Hao and Guibas, Leonidas J , journal=. Point
-
[2]
Cao, Chao and Preda, Marius and Zaharia, Titus , booktitle=. 3
-
[3]
Octree-Based Progressive Geometry Coding of Point Clouds , booktitle =
Yan Huang and Jingliang Peng and C. Octree-Based Progressive Geometry Coding of Point Clouds , booktitle =
-
[4]
3rd Symposium on Point Based Graphics, PBG@SIGGRAPH 2006 , pages =
Ruwen Schnabel and Reinhard Klein , title =. 3rd Symposium on Point Based Graphics, PBG@SIGGRAPH 2006 , pages =
2006
-
[5]
Wu, Yutian and Wang, Yueyu and Zhang, Shuwei and Ogai, Harutoshi , journal=. Deep 3. 2020 , publisher=
2020
-
[6]
Communications of the ACM , volume=
Arithmetic coding for data compression , author=. Communications of the ACM , volume=. 1987 , publisher=
1987
-
[7]
2020 , publisher=
Li, You and Ibanez-Guzman, Javier , journal=. 2020 , publisher=
2020
-
[8]
Information Fusion , volume=
Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy , author=. Information Fusion , volume=. 2021 , publisher=
2021
-
[9]
A comparative analysis of
Zou, Qin and Sun, Qin and Chen, Long and Nie, Bu and Li, Qingquan , journal=. A comparative analysis of. 2021 , publisher=
2021
-
[10]
Huang, Lila and Wang, Shenlong and Wong, Kelvin and Liu, Jerry and Urtasun, Raquel , booktitle=. Oct
-
[11]
Que, Zizheng and Lu, Guo and Xu, Dong , booktitle=. Voxel
-
[12]
2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW) , pages=
Multiscale deep context modeling for lossless point cloud geometry compression , author=. 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW) , pages=
2021
-
[13]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Lossless coding of point cloud geometry using a deep generative model , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2021 , publisher=
2021
-
[14]
Wang, Sukai and Jiao, Jianhao and Cai, Peide and Wang, Lujia , booktitle=. R-
-
[15]
Fu, Chunyang and Li, Ge and Song, Rui and Gao, Wei and Liu, Shan , booktitle=. Oct
-
[16]
European Conference on Computer Vision , pages =
Point cloud compression with sibling context and surface priors , author =. European Conference on Computer Vision , pages =
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Efficient hierarchical entropy model for learned point cloud compression , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[18]
Cui, Mingyue and Long, Junhua and Feng, Mingjian and Li, Boyang and Kai, Huang , booktitle =. Oct
-
[19]
2023 IEEE International Conference on Multimedia and Expo (ICME) , pages =
Large-Scale Spatio-Temporal Attention Based Entropy Model for Point Cloud Compression , author =. 2023 IEEE International Conference on Multimedia and Expo (ICME) , pages =
2023
-
[20]
Jin, Yiqi and Zhu, Ziyu and Xu, Tongda and Lin, Yuhuan and Wang, Yan , booktitle =
-
[21]
Luo, Ao and Song, Linxin and Nonaka, Keisuke and Unno, Kyohei and Sun, Heming and Goto, Masayuki and Katto, Jiro , booktitle =
-
[22]
Proceedings of the 2024 International Conference on Multimedia Retrieval , pages=
Octree-Retention Fusion: A High-Performance Context Model for Point Cloud Geometry Compression , author=. Proceedings of the 2024 International Conference on Multimedia Retrieval , pages=
2024
-
[23]
A Versatile Point Cloud Compressor Using Universal Multiscale Conditional Coding – Part I: Geometry , year=
Wang, Jianqiang and Xue, Ruixiang and Li, Jiaxin and Ding, Dandan and Lin, Yi and Ma, Zhan , journal=. A Versatile Point Cloud Compressor Using Universal Multiscale Conditional Coding – Part I: Geometry , year=
-
[24]
Improving Occupancy Prediction for Multiscale Point Cloud Geometry Compression , year=
Li, Zehong and Zhu, Jiahao and Ding, Dandan and Ma, Zhan , journal=. Improving Occupancy Prediction for Multiscale Point Cloud Geometry Compression , year=
-
[25]
Stachniss and Juergen Gall , journal=
Jens Behley and Martin Garbade and Andres Milioto and Jan Quenzel and Sven Behnke and C. Stachniss and Juergen Gall , journal=. Semantic. 2019 , pages=
2019
-
[26]
Video-based point-cloud-compression standard in
Jang, Euee S and Preda, Marius and Mammou, Khaled and Tourapis, Alexis M and Kim, Jungsun and Graziosi, Danillo B and Rhyu, Sungryeul and Budagavi, Madhukar , journal=. Video-based point-cloud-compression standard in. 2019 , publisher=
2019
-
[27]
Schwarz and M
S. Schwarz and M. Preda and V. Baroncini and others , journal=. Emerging. 2019 , volume=
2019
-
[28]
An overview of ongoing point cloud compression standardization activities: Video-based (
Graziosi, D and Nakagami, O and Kuma, S and Zaghetto, A and Suzuki, T and Tabatabai, A , journal=. An overview of ongoing point cloud compression standardization activities: Video-based (. 2020 , publisher=
2020
-
[29]
IEEE Journal of Selected Topics in Signal Processing , volume=
Adaptive deep learning-based point cloud geometry coding , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2020 , publisher=
2020
-
[30]
Draco 3D graphics compression , howpublished=
-
[31]
High Efficiency Video Coding test model, HM-16.18+SCM8.7 , howpublished=
-
[32]
Caesar, Holger and Bankiti, Varun and Lang, Alex H and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar , booktitle=. nu
-
[33]
McBride and Ryan M
Gaurav Pandey and James R. McBride and Ryan M. Eustice , TITLE =. International Journal of Robotics Research , YEAR =
-
[34]
2020 , publisher=
Guo, Yulan and Wang, Hanyun and Hu, Qingyong and Liu, Hao and Liu, Li and Bennamoun, Mohammed , journal=. 2020 , publisher=
2020
-
[35]
Proceedings of the IEEE , volume=
Compression of sparse and dense dynamic point clouds--methods and standards , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[36]
Emerging
Schwarz, Sebastian and Preda, Marius and Baroncini, Vittorio and Budagavi, Madhukar and Cesar, Pablo and Chou, Philip A and Cohen, Robert A and Krivoku. Emerging. IEEE Journal on Emerging and Selected Topics in Circuits and Systems , volume=. 2018 , publisher=
2018
-
[37]
A comprehensive study and comparison of core technologies for MPEG 3-
Liu, Hao and Yuan, Hui and Liu, Qi and Hou, Junhui and Liu, Ju , journal=. A comprehensive study and comparison of core technologies for MPEG 3-. 2019 , publisher=
2019
-
[38]
Sparse Tensor-Based Multiscale Representation for Point Cloud Geometry Compression , year=
Wang, Jianqiang and Ding, Dandan and Li, Zhu and Feng, Xiaoxing and Cao, Chuntong and Ma, Zhan , journal=. Sparse Tensor-Based Multiscale Representation for Point Cloud Geometry Compression , year=
-
[39]
Frontiers in Signal Processing , volume=
Survey on deep learning-based point cloud compression , author=. Frontiers in Signal Processing , volume=. 2022 , publisher=
2022
-
[40]
Liu, Gexin and Wang, Jianqiang and Ding, Dandan and Ma, Zhan , booktitle=
-
[41]
2022 , publisher=
Huang, Tianxin and Zhang, Jiangning and Chen, Jun and Ding, Zhonggan and Tai, Ying and Zhang, Zhenyu and Wang, Chengjie and Liu, Yong , journal=. 2022 , publisher=
2022
-
[42]
Deng, Jiangwei and An, Yuhao and Li, Thomas H and Liu, Shan and Li, Ge , booktitle=
-
[43]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Lossy point cloud geometry compression via end-to-end learning , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2021 , publisher=
2021
-
[44]
2021 Data Compression Conference (DCC) , pages=
Multiscale point cloud geometry compression , author=. 2021 Data Compression Conference (DCC) , pages=
2021
-
[45]
2023 Data Compression Conference (DCC) , pages=
Lossless Point Cloud Attribute Compression Using Cross-scale, Cross-group, and Cross-color Prediction , author=. 2023 Data Compression Conference (DCC) , pages=
2023
-
[46]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Lossless point cloud geometry and attribute compression using a learned conditional probability model , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2023 , publisher=
2023
-
[47]
ISO/IEC , pages=
Information technology - Coded representation of immersive media Part 9: Geometry-based point cloud compression , author=. ISO/IEC , pages=. 2023 , month=
2023
-
[48]
Information technology - Coded representation of immersive media - Part 5: Visual volumetric video-based coding (
, journal=. Information technology - Coded representation of immersive media - Part 5: Visual volumetric video-based coding (. 2023 , month=
2023
-
[49]
Common Test Conditions for
-
[50]
Compression of 3
De Queiroz, Ricardo L and Chou, Philip A , journal=. Compression of 3. 2016 , publisher=
2016
-
[51]
Overview of the high efficiency video coding (
Sullivan, Gary J and Ohm, Jens-Rainer and Han, Woo-Jin and Wiegand, Thomas , journal=. Overview of the high efficiency video coding (. 2012 , publisher=
2012
-
[52]
and Wang, Ye-Kui , journal=
Bross, Benjamin and Chen, Jianle and Ohm, Jens-Rainer and Sullivan, Gary J. and Wang, Ye-Kui , journal=. Developments in International Video Coding Standardization After. 2021 , volume=
2021
-
[53]
Zhang, Junteng and Chen, Tong and Ding, Dandan and Ma, Zhan , booktitle=
-
[54]
IBM Journal of research and development , volume=
Arithmetic coding , author=. IBM Journal of research and development , volume=. 1979 , publisher=
1979
-
[55]
Sparse Convolution Based Octree Feature Propagation for
Lodhi, Muhammad Asad and Pang, Jiahao and Tian, Dong , booktitle=. Sparse Convolution Based Octree Feature Propagation for
-
[56]
Advances in Neural Information Processing Systems (NIPS) , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems (NIPS) , volume=
-
[57]
IEEE Transactions on Multimedia , volume=
Video-based point cloud compression artifact removal , author=. IEEE Transactions on Multimedia , volume=. 2021 , publisher=
2021
-
[58]
Multiscale latent-guided entropy model for
Fan, Tingyu and Gao, Linyao and Xu, Yiling and Wang, Dong and Li, Zhu , journal=. Multiscale latent-guided entropy model for. 2023 , publisher=
2023
-
[59]
You, Kang and Liu, Kai and Yu, Li and Gao, Pan and Ding, Dandan , booktitle =
-
[60]
Proceedings of the 3rd ACM International Conference on Multimedia in Asia , pages=
Patch-based deep autoencoder for point cloud geometry compression , author=. Proceedings of the 3rd ACM International Conference on Multimedia in Asia , pages=
-
[61]
You, Kang and Gao, Pan and Li, Qing , booktitle=
-
[62]
Proceedings of the 1st International Workshop on Advances in Point Cloud Compression, Processing and Analysis , pages=
Transformer and upsampling-based point cloud compression , author=. Proceedings of the 1st International Workshop on Advances in Point Cloud Compression, Processing and Analysis , pages=
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Density-preserving deep point cloud compression , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[64]
7th International Conference on Learning Representations,
Decoupled weight decay regularization , author=. 7th International Conference on Learning Representations,
-
[65]
G. Bj. Calculation of average. 2001 , booktitle=
2001
-
[66]
Zeng, Yiming and Hou, Junhui and Zhang, Qijian and Ren, Siyu and Wang, Wenping , journal=. Dynamic. 2024 , volume=
2024
-
[67]
2022 , publisher=
Zhang, Qijian and Hou, Junhui and Qian, Yue and Chan, Antoni B and Zhang, Juyong and He, Ying , journal=. 2022 , publisher=
2022
-
[68]
2019 IEEE International Conference on Image Processing (ICIP) , pages=
Learning convolutional transforms for lossy point cloud geometry compression , author=. 2019 IEEE International Conference on Image Processing (ICIP) , pages=
2019
-
[69]
A Comprehensive Study and Comparison of Core Technologies for
Liu, Hao and Yuan, Hui and Liu, Qi and Hou, Junhui and Liu, Ju , journal=. A Comprehensive Study and Comparison of Core Technologies for. 2020 , volume=
2020
-
[70]
Biswas, Sourav and Liu, Jerry and Wong, Kelvin and Wang, Shenlong and Urtasun, Raquel , journal=. Mu
-
[71]
2024 , booktitle =
Zheng, Huiming and Gao, Wei and Yu, Zhuozhen and Zhao, Tiesong and Li, Ge , title =. 2024 , booktitle =
2024
-
[72]
Point Cloud Compression for
Tu, Chenxi and Takeuchi, Eijiro and Carballo, Alexander and Takeda, Kazuya , booktitle=. Point Cloud Compression for. 2019 , volume=
2019
-
[73]
and Zhou, Yin and Anguelov, Dragomir , title =
Zhou, Xuanyu and Qi, Charles R. and Zhou, Yin and Anguelov, Dragomir , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , month =. 2022 , pages =
2022
-
[74]
2019 , volume=
Milioto, Andres and Vizzo, Ignacio and Behley, Jens and Stachniss, Cyrill , booktitle=. 2019 , volume=
2019
-
[75]
Real-Time Spatio-Temporal
Feng, Yu and Liu, Shaoshan and Zhu, Yuhao , journal=. Real-Time Spatio-Temporal
-
[76]
Efficient
Wang, Guangming and Wu, Xinrui and Jiang, Shuyang and Liu, Zhe and Wang, Hesheng , journal=. Efficient. 2022 , publisher=
2022
-
[77]
Yang, Bochun and Li, Zijun and Li, Wen and Cai, Zhipeng and Wen, Chenglu and Zang, Yu and Muller, Matthias and Wang, Cheng , booktitle=
-
[78]
2023 , publisher=
Mao, Jiageng and Shi, Shaoshuai and Wang, Xiaogang and Li, Hongsheng , journal=. 2023 , publisher=
2023
-
[79]
2022 , organization=
Heo, Jin and Phillips, Christopher and Gavrilovska, Ada , booktitle=. 2022 , organization=
2022
-
[80]
Real-time
Zhao, Lili and Ma, Kai-Kuang and Lin, Xuhu and Wang, Wenyi and Chen, Jianwen , journal=. Real-time. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.