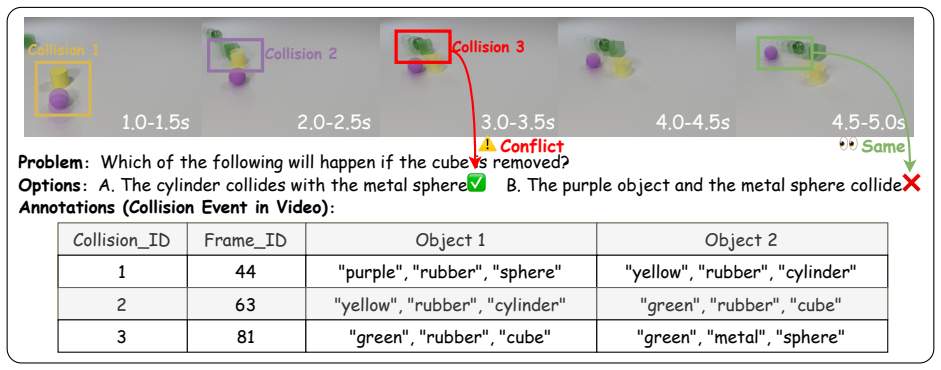
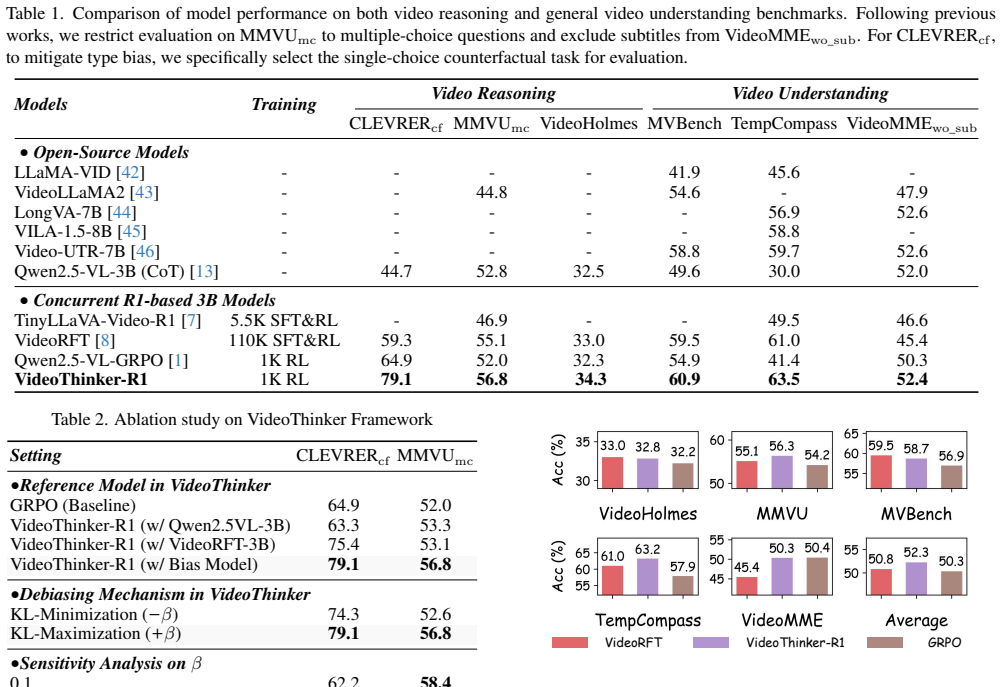
Recognition: unknown
Beyond Perceptual Shortcuts: Causal-Inspired Debiasing Optimization for Generalizable Video Reasoning in Lightweight MLLMs
Pith reviewed 2026-05-09 14:28 UTC · model grok-4.3
The pith
Lightweight video reasoning models develop genuine causal understanding when a dedicated bias model and repulsive optimization push them away from perceptual shortcuts during RL fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reinforcement learning fine-tuning compels lightweight MLLMs to adopt perceptual shortcuts induced by data biases instead of developing genuine reasoning; a bias-aware training stage creates a dedicated bias model that embodies these shortcuts, after which the causal debiasing policy optimization algorithm applies a repulsive objective that actively distances the primary model from the bias model's flawed logic while aligning it with correct solutions, thereby producing more generalizable video reasoning.
What carries the argument
The causal debiasing policy optimization (CDPO) step, which pairs a bias model with a repulsive objective to drive the primary model away from shortcut logic toward generalizable reasoning.
If this is right
- The primary model reaches higher accuracy on standard video reasoning benchmarks than prior lightweight and even some larger models.
- Only a small fraction of typical RL training data is required, with no supervised fine-tuning stage needed beforehand.
- The approach reduces reliance on surface-level perceptual cues in favor of causal reasoning chains across video tasks.
- Efficiency gains make robust video reasoning feasible for deployment on edge devices with limited compute.
- Similar debiasing could be applied to other multimodal reasoning domains that suffer from data-induced shortcuts.
Where Pith is reading between the lines
- The repulsive objective might be combined with other regularization methods to further prevent the primary model from developing alternative unintended shortcuts.
- Testing the framework on longer or more complex video sequences could check whether the causal separation scales to extended temporal reasoning.
- The bias-model construction step could be adapted for text-only or image-only models facing analogous shortcut problems in reasoning tasks.
- If the repulsive mechanism generalizes, it might reduce the need for ever-larger training corpora in multimodal systems by focusing optimization on what the model should avoid.
Load-bearing premise
The bias model faithfully encodes the perceptual shortcuts that RL would otherwise induce, and the repulsive objective reliably steers the primary model toward robust reasoning rather than new unintended shortcuts or performance loss.
What would settle it
Compare performance on held-out video reasoning benchmarks that contain novel causal structures after standard RL fine-tuning versus after the full bias-model-plus-CDPO process; a large gap favoring the debiasing version would support the claim.
Figures





read the original abstract
Although reinforcement learning (RL) has significantly advanced reasoning capabilities in large multimodal language models (MLLMs), its efficacy remains limited for lightweight models essential for edge deployments. To address this issue, we leverage causal analysis and experiment to reveal the underlying phenomenon of perceptual bias, demonstrating that RL-based fine-tuning compels lightweight models to preferentially adopt perceptual shortcuts induced by data biases, rather than developing genuine reasoning abilities. Motivated by this insight, we propose VideoThinker, a causal-inspired framework that cultivates robust reasoning in lightweight models through a two-stage debiasing process. First, the Bias Aware Training stage forges a dedicated "bias model" to embody these shortcut behaviors. Then, the Causal Debiasing Policy Optimization (CDPO) algorithm fine-tunes the primary model, employing an innovative repulsive objective to actively push it away from the bias model's flawed logic while simultaneously pulling it toward correct, generalizable solutions. Our model, VideoThinker-R1, establishes a new state-of-the-art in video reasoning efficiency. For same-scale comparison, requiring no Supervised Fine-Tuning (SFT) and using only 1 of the training data for RL, it surpasses VideoRFT-3B with a 3.2% average gain on widely-used benchmarks and a 7% lead on VideoMME. For cross-scale comparison, it outperforms the larger Video-UTR-7B model on multiple benchmarks, including a 2.1% gain on MVBench and a 3.8% gain on TempCompass. Code is available at https://github.com/falonss703/VideoThinker.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reinforcement learning fine-tuning on lightweight multimodal LLMs for video reasoning induces reliance on perceptual shortcuts from data biases rather than genuine reasoning. It introduces VideoThinker, a two-stage causal debiasing framework: (1) Bias Aware Training to create a dedicated bias model capturing shortcut behaviors, and (2) Causal Debiasing Policy Optimization (CDPO) that applies a repulsive objective to push the primary model away from the bias model's logic while attracting it to correct answers. VideoThinker-R1 reportedly achieves SOTA efficiency, outperforming VideoRFT-3B by 3.2% average on benchmarks and 7% on VideoMME using 1/10 the RL data and no SFT, while also beating larger models like Video-UTR-7B on several tasks.
Significance. If the debiasing mechanism holds and generalizes, this could meaningfully advance efficient, robust video reasoning in resource-constrained MLLMs for edge applications. The reported data efficiency (no SFT, 1/10 RL data) and cross-scale gains would be notable contributions if supported by rigorous controls and ablations. The causal framing and explicit bias model are conceptually interesting for addressing shortcut learning in RL-tuned models.
major comments (2)
- [Abstract] Abstract and central claim: The repulsive objective in CDPO is presented as driving the primary model toward generalizable reasoning, but the manuscript provides no ablations isolating the repulsive term's effect, no direct probes measuring shortcut usage (e.g., controlled bias tests), and no verification that the bias model encodes only undesired shortcuts rather than useful features. This is load-bearing because the performance gains (3.2% average, 7% on VideoMME) cannot be attributed to the proposed mechanism without such evidence.
- [Abstract] Circularity concern in two-stage process: The bias model is trained on the same data distribution as the primary model, yet the paper does not demonstrate that the 'correct' solutions or repulsive targets are identified independently of the bias model itself. Without this, the CDPO objective risks encoding information already present in training rather than truly debiasing, undermining the causal analysis that RL induces shortcuts.
minor comments (1)
- [Abstract] The abstract mentions 'causal analysis and experiment' but does not specify the experimental design, baseline implementations, or statistical significance testing for the reported gains.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of our causal debiasing approach for lightweight video reasoning models. We address each major comment point by point below, providing clarifications based on the manuscript while agreeing to strengthen the presentation where evidence was insufficient.
read point-by-point responses
-
Referee: [Abstract] Abstract and central claim: The repulsive objective in CDPO is presented as driving the primary model toward generalizable reasoning, but the manuscript provides no ablations isolating the repulsive term's effect, no direct probes measuring shortcut usage (e.g., controlled bias tests), and no verification that the bias model encodes only undesired shortcuts rather than useful features. This is load-bearing because the performance gains (3.2% average, 7% on VideoMME) cannot be attributed to the proposed mechanism without such evidence.
Authors: We acknowledge that the abstract and central claims would benefit from more explicit isolation of the repulsive term's contribution. The full manuscript reports overall performance gains through comparisons to baselines like VideoRFT-3B, but does not include dedicated ablations removing only the repulsive component of CDPO or controlled bias probes (e.g., accuracy on bias-augmented test subsets). We will revise by adding a dedicated ablation subsection that compares CDPO with and without the repulsive objective, reports shortcut usage metrics (such as reliance on visual cues vs. temporal reasoning on curated subsets), and provides qualitative/quantitative analysis of bias model outputs to confirm predominant capture of undesired perceptual shortcuts rather than useful features. These additions will allow direct attribution of gains to the debiasing mechanism. revision: yes
-
Referee: [Abstract] Circularity concern in two-stage process: The bias model is trained on the same data distribution as the primary model, yet the paper does not demonstrate that the 'correct' solutions or repulsive targets are identified independently of the bias model itself. Without this, the CDPO objective risks encoding information already present in training rather than truly debiasing, undermining the causal analysis that RL induces shortcuts.
Authors: This is a valid concern regarding potential circularity. In the proposed framework, the bias model is trained to capture shortcut behaviors via a dedicated objective on the training distribution, while correct solutions are sourced directly from ground-truth labels in the video reasoning benchmarks (independent of any model outputs). Repulsive targets are then derived by contrasting the primary model's policy against the bias model's predictions on identical inputs. However, the manuscript does not explicitly demonstrate independence through held-out identification of targets or ablations. We will revise the methods and causal analysis sections to clarify the role of ground-truth labels, add an experiment using held-out data for repulsive target generation, and include results showing the debiasing effect holds under this stricter separation. This will better substantiate the claim that RL induces shortcuts addressable via the two-stage process. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation consists of an empirical observation (RL fine-tuning induces perceptual shortcuts in lightweight MLLMs, shown via experiments) followed by a proposed two-stage algorithmic intervention (Bias Aware Training to create a bias model, then CDPO with repulsive+attractive objectives). These steps are presented as a new training procedure whose validity is assessed through external benchmark comparisons (e.g., gains on VideoMME, MVBench) rather than any mathematical reduction to the inputs by construction. No equations are shown to equate a 'prediction' with a fitted parameter, no self-citation chain bears the central claim, and the bias model is explicitly a separate trained component rather than a definitional tautology. The method is self-contained against the reported benchmarks and does not rely on imported uniqueness theorems or renamed known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RL fine-tuning on biased video data causes lightweight MLLMs to adopt perceptual shortcuts instead of genuine reasoning
invented entities (2)
-
bias model
no independent evidence
-
Causal Debiasing Policy Optimization (CDPO)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 1, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Fast-slow thinking GRPO for large vision-language model reasoning
Wenyi Xiao and Leilei Gan. Fast-slow thinking GRPO for large vision-language model reasoning. InNeurIPS, 2025. 1
2025
-
[3]
Time-r1: Post- training large vision language model for temporal video grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, Xiangnan Fang, Zewen He, Zhenbo Luo, Wenxuan Wang, Junqi Lin, Jian Luan, and Qin Jin. Time-r1: Post- training large vision language model for temporal video grounding. InNeurIPS, 2025
2025
-
[4]
Video-r1: Reinforcing video reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in MLLMs. InNeurIPS, 2025. 3, 4, 6, 8, 1
2025
-
[5]
Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning,
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning.arXiv preprint arXiv:2504.06958, 2025. 3, 1
-
[6]
Reinforcing video reasoning with focused thinking
Jisheng Dang, Jingze Wu, Teng Wang, Xuanhui Lin, Nan- nan Zhu, Hongbo Chen, Wei-Shi Zheng, Meng Wang, and Tat-Seng Chua. Reinforcing video reasoning with focused thinking.arXiv preprint arXiv:2505.24718, 2025. 1, 3, 6, 2
-
[7]
Tinyllava-video-r1: Towards smaller lmms for video reason- ing.arXiv preprint arXiv:2504.09641, 2025
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Tinyllava-video-r1: Towards smaller lmms for video reason- ing.arXiv preprint arXiv:2504.09641, 2025. 1, 4, 7
-
[8]
VideoRFT: Incentivizing video reasoning capability in MLLMs via reinforced fine-tuning
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. VideoRFT: Incentivizing video reasoning capability in MLLMs via reinforced fine-tuning. InNeurIPS, 2025. 1, 3, 4, 6, 7, 8, 2
2025
-
[9]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning. In ICLR, 2020. 2, 4, 6, 1
2020
-
[10]
Multi-object hallucination in vision language models
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David Fouhey, and Joyce Chai. Multi-object hallucination in vision language models. In NeurIPS, volume 37, pages 44393–44418, 2024. 2
2024
-
[11]
Beyond task performance: evaluating and re- ducing the flaws of large multimodal models with in-context- learning
Mustafa Shukor, Alexandre Rame, Corentin Dancette, and Matthieu Cord. Beyond task performance: evaluating and re- ducing the flaws of large multimodal models with in-context- learning. InICLR, 2024
2024
-
[12]
More thinking, less seeing? assessing amplified hallucina- tion in multimodal reasoning models
Zhongxing Xu, Chengzhi Liu, Qingyue Wei, Juncheng Wu, James Zou, Xin Eric Wang, Yuyin Zhou, and Sheng Liu. More thinking, less seeing? assessing amplified hallucina- tion in multimodal reasoning models. InNeurIPS, 2025. 2
2025
-
[13]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 4, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InCVPR, pages 24108–24118, 2025. 3, 6, 1, 2
2025
-
[15]
Yufei Zhan, Yousong Zhu, Shurong Zheng, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Vision-r1: Evolv- ing human-free alignment in large vision-language models via vision-guided reinforcement learning.arXiv preprint arXiv:2503.18013, 2025. 3
-
[16]
Unbiased look at dataset bias
Antonio Torralba and Alexei A Efros. Unbiased look at dataset bias. InCVPR, pages 1521–1528, 2011. 3
2011
-
[17]
Seeing like a human: Asynchronous learning with dynamic progressive refinement for person re-identification
Quan Zhang, Jianhuang Lai, Zhanxiang Feng, and Xiao- hua Xie. Seeing like a human: Asynchronous learning with dynamic progressive refinement for person re-identification. IEEE TIP, 31:352–365, 2021
2021
-
[18]
Separable spatial-temporal residual graph for cloth-changing group re-identification.IEEE TPAMI, 46(8):5791–5805, 2024
Quan Zhang, Jianhuang Lai, Xiaohua Xie, Xiaofeng Jin, and Sien Huang. Separable spatial-temporal residual graph for cloth-changing group re-identification.IEEE TPAMI, 46(8):5791–5805, 2024
2024
-
[19]
Debiasing multimodal large language mod- els via noise-aware preference optimization
Zefeng Zhang, Hengzhu Tang, Jiawei Sheng, Zhenyu Zhang, Yiming Ren, Zhenyang Li, Dawei Yin, Duohe Ma, and Tingwen Liu. Debiasing multimodal large language mod- els via noise-aware preference optimization. InCVPR, pages 9423–9433, 2025. 3
2025
-
[20]
Language prior is not the only shortcut: A bench- mark for shortcut learning in vqa
Qingyi Si, Fandong Meng, Mingyu Zheng, Zheng Lin, Yuanxin Liu, Peng Fu, Yanan Cao, Weiping Wang, and Jie Zhou. Language prior is not the only shortcut: A bench- mark for shortcut learning in vqa. InEMNLP Findings, pages 3698–3712, 2022. 3
2022
-
[21]
Discovering the real association: Multimodal causal reason- ing in video question answering
Chuanqi Zang, Hanqing Wang, Mingtao Pei, and Wei Liang. Discovering the real association: Multimodal causal reason- ing in video question answering. InCVPR, pages 19027– 19036, June 2023
2023
-
[22]
Mitigating modality prior-induced halluci- nations in multimodal large language models via deciphering attention causality
Guanyu Zhou, Yibo Yan, Xin Zou, Kun Wang, Aiwei Liu, and Xuming Hu. Mitigating modality prior-induced halluci- nations in multimodal large language models via deciphering attention causality. InICLR, 2025
2025
-
[23]
Assessing modality bias in video question answer- ing benchmarks with multimodal large language models
Jean Park, Kuk Jin Jang, Basam Alasaly, Sriharsha Mopi- devi, Andrew Zolensky, Eric Eaton, Insup Lee, and Kevin Johnson. Assessing modality bias in video question answer- ing benchmarks with multimodal large language models. In AAAI, volume 39, pages 19821–19829, 2025. 3
2025
-
[24]
Counterfactual vqa: A cause- effect look at language bias
Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian- Sheng Hua, and Ji-Rong Wen. Counterfactual vqa: A cause- effect look at language bias. InCVPR, pages 12700–12710,
-
[25]
Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective
Meiqi Chen, Yixin Cao, Yan Zhang, and Chaochao Lu. Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective. InEMNLP Findings, pages 16449–16469, 2024. 3
2024
-
[26]
Language models are causal knowledge ex- tractors for zero-shot video question answering
Hung-Ting Su, Yulei Niu, Xudong Lin, Winston H Hsu, and Shih-Fu Chang. Language models are causal knowledge ex- tractors for zero-shot video question answering. InCVPR, pages 4950–4959, 2023. 3
2023
-
[27]
Link- context learning for multimodal llms
Yan Tai, Weichen Fan, Zhao Zhang, and Ziwei Liu. Link- context learning for multimodal llms. InCVPR, pages 27176–27185, 2024
2024
-
[28]
Causal-cog: A causal-effect look at context genera- tion for boosting multi-modal language models
Shitian Zhao, Zhuowan Li, Yadong Lu, Alan Yuille, and Yan Wang. Causal-cog: A causal-effect look at context genera- tion for boosting multi-modal language models. InCVPR, pages 13342–13351, 2024
2024
-
[29]
Cross-modal causal relation alignment for video question grounding
Weixing Chen, Yang Liu, Binglin Chen, Jiandong Su, Yongsen Zheng, and Liang Lin. Cross-modal causal relation alignment for video question grounding. InCVPR, pages 24087–24096, 2025. 3
2025
-
[30]
Causal interventional training for image recog- nition.IEEE TMM, 25:1033–1044, 2021
Wei Qin, Hanwang Zhang, Richang Hong, Ee-Peng Lim, and Qianru Sun. Causal interventional training for image recog- nition.IEEE TMM, 25:1033–1044, 2021. 3
2021
-
[31]
Deep stable learning for out-of- distribution generalization
Xingxuan Zhang, Peng Cui, Renzhe Xu, Linjun Zhou, Yue He, and Zheyan Shen. Deep stable learning for out-of- distribution generalization. InCVPR, pages 5372–5382, 2021
2021
-
[32]
Learning modal-invariant angular metric by cyclic projection network for vis-nir person re-identification.IEEE TIP, 30:8019– 8033, 2021
Quan Zhang, Jianhuang Lai, and Xiaohua Xie. Learning modal-invariant angular metric by cyclic projection network for vis-nir person re-identification.IEEE TIP, 30:8019– 8033, 2021
2021
-
[33]
Wavelet-guided promotion-suppression transformer for surface-defect detection.IEEE TIP, 32:4517–4528, 2023
Quan Zhang, Jianhuang Lai, Junyong Zhu, and Xiaohua Xie. Wavelet-guided promotion-suppression transformer for surface-defect detection.IEEE TIP, 32:4517–4528, 2023
2023
-
[34]
View-decoupled transformer for person re- identification under aerial-ground camera network
Quan Zhang, Lei Wang, Vishal M Patel, Xiaohua Xie, and Jianhaung Lai. View-decoupled transformer for person re- identification under aerial-ground camera network. InCVPR, pages 22000–22009, 2024. 3
2024
-
[35]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline pro- fessional videos.arXiv preprint arXiv:2501.13826, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[36]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[37]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025. 3, 4
2025
-
[38]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Ha...
2025
-
[39]
Causal inference in statistics: An overview
Judea Pearl. Causal inference in statistics: An overview
-
[40]
[bayesian analysis in expert systems]: Com- ment: Graphical models, causality and intervention.Statisti- cal Science, 8(3):266–269, 1993
Judea Pearl. [bayesian analysis in expert systems]: Com- ment: Graphical models, causality and intervention.Statisti- cal Science, 8(3):266–269, 1993. 5
1993
-
[41]
Causal diagrams for epidemiologic research.Epidemiology, 10(1):37–48, 1999
Sander Greenland, Judea Pearl, and James M Robins. Causal diagrams for epidemiologic research.Epidemiology, 10(1):37–48, 1999. 5
1999
-
[42]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InECCV, pages 323–340. Springer, 2024. 7
2024
-
[43]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[44]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[45]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for visual language models. InCVPR, pages 26689–26699, 2024. 7
2024
-
[46]
Unhackable temporal rewarding for scalable video mllms.arXiv preprint arXiv:2502.12081, 2025
En Yu, Kangheng Lin, Liang Zhao, Yana Wei, Zining Zhu, Haoran Wei, Jianjian Sun, Zheng Ge, Xiangyu Zhang, Jingyu Wang, et al. Unhackable temporal rewarding for scal- able video mllms.arXiv preprint arXiv:2502.12081, 2025. 6, 7
-
[47]
Mmvu: Measuring expert-level multi- discipline video understanding
Yilun Zhao, Haowei Zhang, Lujing Xie, Tongyan Hu, Guo Gan, Yitao Long, Zhiyuan Hu, Weiyuan Chen, Chuhan Li, Zhijian Xu, et al. Mmvu: Measuring expert-level multi- discipline video understanding. InCVPR, pages 8475–8489,
-
[48]
Video-holmes: Can mllm think like holmes for complex video reasoning?, 2025
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?arXiv preprint arXiv:2505.21374, 2025. 6, 1
-
[49]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InCVPR, pages 22195–22206, 2024. 6, 1
2024
-
[50]
Temp- compass: Do video llms really understand videos? InACL Findings, pages 8731–8772, 2024
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Temp- compass: Do video llms really understand videos? InACL Findings, pages 8731–8772, 2024. 6, 1
2024
-
[51]
Output the thinking process in<think></think>and the final answer (letters separated by commas, if multiple) in<answer></answer> tags
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Re- casens Continente, Larisa Markeeva, Dylan Sunil Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sul- sky, Antoine Miech, Alexandre Fréchette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Ay- tar, Simon Osindero...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.