Recognition: unknown
DiagramNet: An End-to-End Recognition Framework and Dataset for Non-Standard System-Level Diagrams
Pith reviewed 2026-05-09 14:34 UTC · model grok-4.3
The pith
A Perception-Reasoning-Knowledge workflow and new dataset let a 3B model outperform GPT-5 and the 2025 EDA challenge winner on non-standard chip system diagrams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
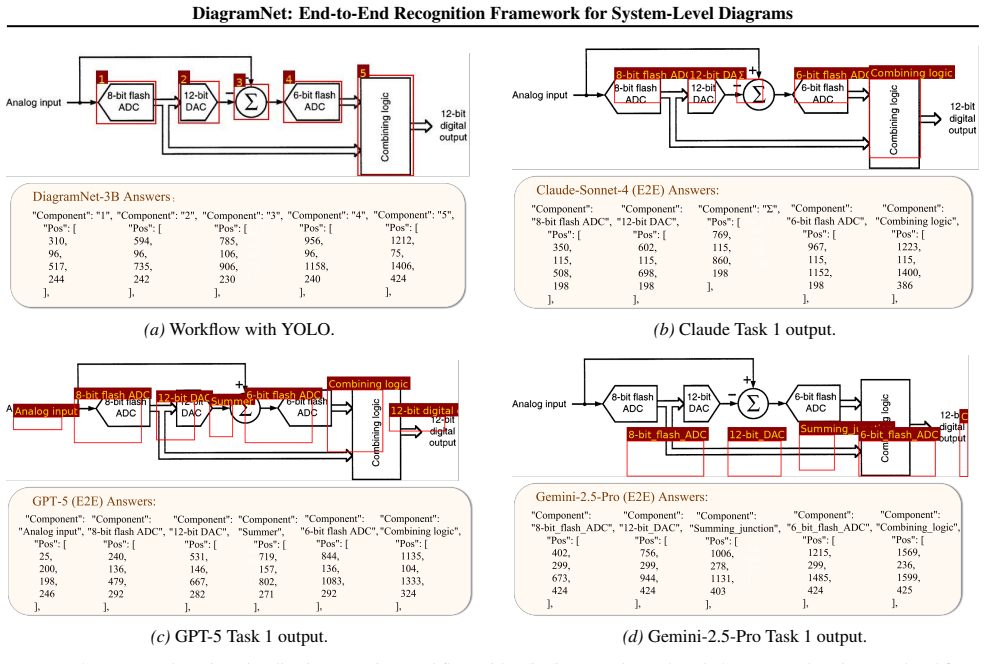
By releasing DiagramNet and training on its four tasks, a decoupled multi-agent workflow that decomposes diagram interpretation into Perception, Reasoning, and Knowledge stages enables a 3B model to surpass both the 2025 EDA Elite Challenge winner and leading frontier models by more than 2x in end-to-end accuracy while generalizing to boost those larger models and to zero-shot connectivity reasoning on AMSBench.
What carries the argument
The decoupled multi-agent workflow that decomposes complex visual reasoning into separate Perception, Reasoning, and Knowledge stages, trained progressively on the DiagramNet dataset of connection annotations and QA pairs.
If this is right
- The workflow lifts Task 1 performance of Gemini-2.5-Pro by 128.7x and of GPT-5 by 12.4x without changing the underlying models.
- With only 60 images for detector adaptation the method reaches parity with GPT-5 and Claude-Sonnet-4 on zero-shot connectivity reasoning for AMSBench.
- The same decomposition surpasses the prior AMS state-of-the-art method Netlistify on connectivity reasoning.
- End-to-end evaluation on DiagramNet becomes the new reference point for system-level diagram understanding in EDA.
Where Pith is reading between the lines
- Engineers could insert the workflow into existing design-review pipelines to reduce manual tracing of module connections.
- The same staged decomposition may apply to other domains that mix visual layout with domain-specific rules, such as electrical schematics or floor plans.
- Future work could test whether the Perception stage alone can be replaced by an off-the-shelf detector without retraining the full pipeline.
Load-bearing premise
The four defined tasks and the Perception-Reasoning-Knowledge decomposition accurately represent the real difficulties engineers face when interpreting non-standard system-level diagrams in production chip design flows.
What would settle it
Running the trained model and workflow on a new collection of proprietary, previously unseen system-level diagrams drawn directly from active chip design projects and measuring end-to-end accuracy against human experts.
Figures






read the original abstract
System-level diagrams encode the architectural blueprint of chip design, specifying module functions, dataflows, and interface protocols. However, non-standardized symbols and the scarcity of structured training data hinder existing multimodal large language models (MLLMs) from recognizing these diagrams. To address this gap, we introduce DiagramNet, the first multimodal dataset for system-level diagrams, comprising 10,977 connection annotations and 15,515 chain-of-thought QA pairs across four tasks: Listing, Localization, Connection, and Circuit QA. Building on this dataset, we propose a progressive training pipeline together with a decoupled multi-agent workflow that decomposes complex visual reasoning into Perception, Reasoning, and Knowledge stages. On the DiagramNet benchmark, integrating our 3B-parameter model with the proposed workflow surpasses the 2025 EDA Elite Challenge winner and outperforms GPT-5, Claude-Sonnet-4, and Gemini-2.5-Pro by over 2x in end-to-end evaluation. Notably, the workflow generalizes beyond our model, boosting Task 1 performance by 128.7x for Gemini-2.5-Pro and 12.4x for GPT-5. Furthermore, with only 60 images for detector adaptation, the method transfers effectively to AMSBench, achieving zero-shot connectivity reasoning on par with GPT-5 and Claude-Sonnet-4 while surpassing the AMS state-of-the-art method Netlistify.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DiagramNet, the first multimodal dataset for non-standard system-level diagrams in chip design, comprising 10,977 connection annotations and 15,515 chain-of-thought QA pairs across four tasks: Listing, Localization, Connection, and Circuit QA. It proposes a progressive training pipeline and a decoupled multi-agent workflow that decomposes visual reasoning into Perception, Reasoning, and Knowledge stages. The central empirical claims are that a 3B-parameter model integrated with this workflow surpasses the 2025 EDA Elite Challenge winner and outperforms GPT-5, Claude-Sonnet-4, and Gemini-2.5-Pro by over 2x in end-to-end evaluation on DiagramNet, that the workflow generalizes to deliver large boosts (e.g., 128.7x on Task 1 for Gemini-2.5-Pro), and that the approach transfers effectively to AMSBench with only 60 images for detector adaptation.
Significance. If the four tasks and Perception-Reasoning-Knowledge decomposition are shown to be faithful proxies for real production difficulties in interpreting non-standard system-level diagrams, the work would provide a valuable new benchmark and practical method for domain-specific multimodal reasoning in chip design. The creation of a sizable annotated dataset and the observed cross-model generalization of the workflow are clear strengths. The minimal-data transfer result to AMSBench is also noteworthy. However, the current lack of validation for task realism and incomplete experimental reporting limit the assessed significance.
major comments (3)
- [§3] §3 (Dataset Construction and Task Definitions): The four tasks (Listing, Localization, Connection, Circuit QA) and the Perception-Reasoning-Knowledge decomposition are introduced without any description of derivation from actual chip-design engineer workflows, common error modes, expert review, or user studies. This is load-bearing for the headline claims because the reported 2x end-to-end superiority and 128.7x/12.4x generalization boosts rest entirely on these tasks serving as accurate proxies for production difficulties.
- [§5] §5 (Experimental Results): No error bars, standard deviations, or details on the number of runs are provided for any performance numbers, including the end-to-end comparisons and the specific multipliers (128.7x, 12.4x). Ablation studies isolating the progressive training pipeline from the multi-agent workflow stages are absent, and the full evaluation protocol (prompting templates, metric definitions, and baseline implementations) is not fully specified, preventing independent verification of the central empirical claims.
- [§5.3] §5.3 (AMSBench Transfer): The zero-shot connectivity reasoning result on AMSBench after adapting with only 60 images is presented without details on the adaptation procedure, exact baselines (including how Netlistify was re-implemented), or statistical comparison to GPT-5/Claude-Sonnet-4, making the transfer claim difficult to assess.
minor comments (2)
- [Abstract and §5] The abstract and §5 use multipliers such as 'over 2x' and '128.7x' without immediately defining the underlying metric (e.g., exact accuracy or F1) or the precise baseline configuration for each comparison.
- [§4] Figure captions and the workflow diagram in §4 could more explicitly label the interfaces between the Perception, Reasoning, and Knowledge agents to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that clarifying the grounding of the tasks in real workflows and providing fuller experimental details will strengthen the paper. We address each major comment below and will make the corresponding revisions.
read point-by-point responses
-
Referee: §3 (Dataset Construction and Task Definitions): The four tasks (Listing, Localization, Connection, Circuit QA) and the Perception-Reasoning-Knowledge decomposition are introduced without any description of derivation from actual chip-design engineer workflows, common error modes, expert review, or user studies. This is load-bearing for the headline claims because the reported 2x end-to-end superiority and 128.7x/12.4x generalization boosts rest entirely on these tasks serving as accurate proxies for production difficulties.
Authors: We agree that explicit documentation of task derivation is important for validating the proxy relationship to production difficulties. The tasks and Perception-Reasoning-Knowledge decomposition were developed from analysis of common challenges in non-standard system-level diagrams as described in chip-design literature and from preliminary input by EDA domain experts during dataset curation. In the revised manuscript we will add a dedicated subsection in §3 that details this process, including observed error modes in baseline MLLM outputs, how each task maps to engineer workflows, and a summary of expert feedback obtained during annotation. This will directly support the reported performance gains. revision: yes
-
Referee: §5 (Experimental Results): No error bars, standard deviations, or details on the number of runs are provided for any performance numbers, including the end-to-end comparisons and the specific multipliers (128.7x, 12.4x). Ablation studies isolating the progressive training pipeline from the multi-agent workflow stages are absent, and the full evaluation protocol (prompting templates, metric definitions, and baseline implementations) is not fully specified, preventing independent verification of the central empirical claims.
Authors: We acknowledge that the current experimental reporting lacks statistical rigor and reproducibility details. In the revision we will recompute and report all key metrics (including the 2x end-to-end gains and the 128.7x/12.4x multipliers) with error bars and standard deviations over 5 independent runs. We will insert new ablation experiments that separately measure the contribution of the progressive training pipeline versus each stage of the multi-agent workflow. A new appendix will supply the complete evaluation protocol: all prompting templates, exact metric definitions, and step-by-step baseline re-implementations. revision: yes
-
Referee: §5.3 (AMSBench Transfer): The zero-shot connectivity reasoning result on AMSBench after adapting with only 60 images is presented without details on the adaptation procedure, exact baselines (including how Netlistify was re-implemented), or statistical comparison to GPT-5/Claude-Sonnet-4, making the transfer claim difficult to assess.
Authors: We will expand §5.3 with a full description of the detector adaptation procedure using the 60 images, the precise re-implementation steps for Netlistify following its original publication, and direct statistical comparisons (means and standard deviations over multiple runs) of our method against GPT-5 and Claude-Sonnet-4 on the AMSBench connectivity tasks. These additions will make the transfer results and zero-shot performance claims fully verifiable. revision: yes
Circularity Check
No circularity: performance claims rest on new dataset and external model comparisons
full rationale
The paper introduces DiagramNet as a new multimodal dataset with four tasks and a decoupled Perception-Reasoning-Knowledge workflow, then reports empirical results of its 3B model plus workflow against external baselines (GPT-5, Claude-Sonnet-4, Gemini-2.5-Pro, EDA winner, AMSBench SOTA). No equations, parameter fits, self-citations, or ansatzes are invoked to derive the reported gains; the 2x end-to-end and 128.7x Task-1 improvements are direct measurements on held-out or transferred data rather than reductions to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Non-standardized symbols and scarcity of structured training data prevent existing MLLMs from recognizing system-level diagrams.
Reference graph
Works this paper leans on
-
[1]
2025 china postgraduate ic innovation competition: Eda elite challenge contest, 2025
2025 EDA Elite Challenge Contest . 2025 china postgraduate ic innovation competition: Eda elite challenge contest, 2025. URL http://www.edachallenge.cn. Accessed: 2026-01-26
2025
-
[2]
Bai, S., Chen, K., Liu, X., et al. Qwen2.5-vl technical report, 2025. URL https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Chai, Z., Zhao, Y., Liu, W., et al. CircuitNet : An Open - Source Dataset for Machine Learning in VLSI CAD Applications With Improved Domain - Specific Evaluation Metric and Learning Strategies . IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 42 0 (12): 0 5034--5047, December 2023. ISSN 1937-4151. doi:10.1109/TCAD.2023.3287...
-
[4]
Guo, D., Yang, D., Zhang, H., et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645 0 (8081): 0 633–638, September 2025. ISSN 1476-4687. doi:10.1038/s41586-025-09422-z. URL http://dx.doi.org/10.1038/s41586-025-09422-z
-
[5]
Hiippala, T., Alikhani, M., Haverinen, J., Kalliokoski, T., Logacheva, E., Orekhova, S., Tuomainen, A., Stone, M., and Bateman, J. A. AI2D-RST : a multimodal corpus of 1000 primary school science diagrams. Language Resources and Evaluation, 55 0 (3): 0 661–688, December 2020. ISSN 1574-0218. doi:10.1007/s10579-020-09517-1. URL http://dx.doi.org/10.1007/s1...
-
[6]
Ho, C.-T., Ren, H., and Khailany, B. VerilogCoder : Autonomous verilog coding agents with graph-based planning and abstract syntax tree (ast)-based waveform tracing tool. Proceedings of the AAAI Conference on Artificial Intelligence, 39 0 (1): 0 300--307, Apr. 2025. doi:10.1609/aaai.v39i1.32007. URL https://ojs.aaai.org/index.php/AAAI/article/view/32007
-
[7]
Huang, C.-Y., Chen, H.-I., Ho, H.-W., Kang, P.-H., Lin, M. P.-H., Liu, W.-H., and Ren, H. Netlistify: Transforming circuit schematics into netlists with deep learning. In 2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD), pp.\ 1--8, 2025 a . doi:10.1109/MLCAD65511.2025.11189145
-
[8]
Boosting mllm reasoning with text-debiased hint-grpo.arXiv preprint arXiv:2503.23905,
Huang, Q., Dai, W., Liu, J., et al. Boosting mllm reasoning with text-debiased hint-grpo, 2025 b . URL https://arxiv.org/abs/2503.23905
-
[9]
CircuitNet 2.0 : An advanced dataset for promoting machine learning innovations in realistic chip design environment
Jiang, X., zhuomin chai, Zhao, Y., Lin, Y., Wang, R., and Huang, R. CircuitNet 2.0 : An advanced dataset for promoting machine learning innovations in realistic chip design environment. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=nMFSUjxMIl
2024
-
[10]
A diagram is worth a dozen images
Kembhavi, A., Seo, M., Schwenk, D., et al. A diagram is worth a dozen images. In European Conference on Computer Vision, pp.\ 235--251, 2016
2016
-
[11]
Lin, Y., Jiang, Z., Gu, J., Li, W., Dhar, S., Ren, H., Khailany, B., and Pan, D. Z. DREAMPlace : Deep learning toolkit-enabled gpu acceleration for modern vlsi placement. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 40 0 (4): 0 748--761, 2021. doi:10.1109/TCAD.2020.3003843
-
[12]
URLhttps://doi.org/10.1109/ICCAD57390.2023.10323812
Liu, M., Pinckney, N., Khailany, B., and Ren, H. Invited paper: VerilogEval : Evaluating large language models for verilog code generation. In 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), pp.\ 1--8, 2023. doi:10.1109/ICCAD57390.2023.10323812
-
[13]
Chipnemo: Domain- adapted llms for chip design,
Liu, M., Ene, T.-D., Kirby, R., et al. ChipNeMo : Domain - Adapted LLMs for Chip Design , April 2024 a . URL http://arxiv.org/abs/2311.00176. arXiv:2311.00176 [cs]
-
[14]
Liu, S., Fang, W., Lu, Y., Zhang, Q., Zhang, H., and Xie, Z. RTLCoder : Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution. In 2024 IEEE LLM Aided Design Workshop (LAD), pp.\ 1--5, 2024 b . doi:10.1109/LAD62341.2024.10691788
-
[15]
RTLLM : An open-source benchmark for design rtl generation with large language model
Lu, Y., Liu, S., Zhang, Q., and Xie, Z. RTLLM : An open-source benchmark for design rtl generation with large language model. In 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), pp.\ 722--727, 2024. doi:10.1109/ASP-DAC58780.2024.10473904
-
[16]
X., Tan, J
Masry, A., Long, D. X., Tan, J. Q., et al. ChartQA : A benchmark for question answering about charts with visual and logical reasoning. In Findings of ACL, 2022
2022
-
[17]
Mathew, M., Karatzas, D., and Jawahar, C. V. DocVQA : A dataset for vqa on document images. In IEEE Winter Conference on Applications of Computer Vision, pp.\ 2200--2209, 2021
2021
-
[18]
A graph placement methodology for fast chip design
Mirhoseini, A., Goldie, A., et al. A graph placement methodology for fast chip design. Nature, 594: 0 207--212, 2021
2021
-
[19]
OpenAI, Achiam, J., Adler, S., et al. GPT-4 Technical Report , 2024. URL https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Hybridflow: A flexible and efficient rlhf framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., and Wu, C. HybridFlow : A flexible and efficient RLHF framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys '25, pp.\ 1279–1297, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 9798400711961. doi:10.1145/3689031.3696075. ...
-
[21]
Amsnet 2.0: A large ams database with ai segmentation for net detection
Shi, Y., Tao, Z., Gao, Y., Huang, L., Wang, H., Yu, Z., Lin, T.-J., and He, L. Amsnet 2.0: A large ams database with ai segmentation for net detection. In 2025 IEEE International Conference on LLM-Aided Design (ICLAD), pp.\ 242--248, 2025 a . doi:10.1109/ICLAD65226.2025.00014
-
[22]
Shi, Y., Zhang, Z., Wang, H., et al. AMSbench : A Comprehensive Benchmark for Evaluating MLLM Capabilities in AMS Circuits , October 2025 b . URL http://arxiv.org/abs/2505.24138. arXiv:2505.24138 [cs]
-
[23]
D., Agarwal, R., et al
Singh, A., Co-Reyes, J. D., Agarwal, R., et al. Beyond human data: Scaling self-training for problem-solving with language models. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=lNAyUngGFK. Expert Certification
2024
-
[24]
AMSNet : Netlist Dataset for AMS Circuits , October 2024
Tao, Z., Shi, Y., Huo, Y., et al. AMSNet : Netlist Dataset for AMS Circuits , October 2024. URL http://arxiv.org/abs/2405.09045. arXiv:2405.09045 [cs]
-
[25]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., et al. Gemini: A family of highly capable multimodal models, 2024. URL https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Thakur, S. et al. VeriGen : A large language model for verilog code generation. In International Conference on Computer-Aided Design, 2023
2023
-
[27]
RTLFixer : Automatically Fixing RTL Syntax Errors with Large Language Model
Tsai, Y., Liu, M., and Ren, H. RTLFixer : Automatically Fixing RTL Syntax Errors with Large Language Model . In Proceedings of the 61st ACM / IEEE Design Automation Conference , pp.\ 1--6, San Francisco CA USA, June 2024. ACM. ISBN 979-8-4007-0601-1. doi:10.1145/3649329.3657353. URL https://dl.acm.org/doi/10.1145/3649329.3657353
-
[28]
Weste, N. H. E. and Harris, D. CMOS VLSI Design: A Circuits and Systems Perspective. Addison-Wesley, 4th edition, 2011
2011
-
[29]
ChatEDA : A large language model powered autonomous agent for eda
Wu, H., He, Z., Zhang, X., Yao, X., Zheng, S., Zheng, H., and Yu, B. ChatEDA : A large language model powered autonomous agent for eda. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 43 0 (10): 0 3184--3197, 2024. doi:10.1109/TCAD.2024.3383347
-
[30]
Xu, H., Liu, C., Wang, Q., Huang, W., Xu, Y., Chen, W., Peng, A., Li, Z., Li, B., Qi, L., Yang, J., Du, Y., and Du, L. Image2Net : Datasets, benchmark and hybrid framework to convert analog circuit diagrams into netlists. In 2025 International Symposium of Electronics Design Automation (ISEDA), pp.\ 807--816, 2025. doi:10.1109/ISEDA65950.2025.11100581
-
[31]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Zheng, Y., Zhang, R., Zhang, J., et al. LlamaFactory : Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguistics. URL http://arxiv.org/abs/2403.13372
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.