Sequentially decoupling estimators for Box-Jenkins model estimation
Pith reviewed 2026-05-09 18:28 UTC · model grok-4.3
The pith
A sequentially decoupling estimator for Box-Jenkins models, refined by one Gauss-Newton step, is asymptotically equivalent to the prediction error method when the ARX order grows mildly with sample size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that the sequentially decoupling estimator, constructed from three sequential least-squares steps consisting of a high-order ARX model followed by an auxiliary output-error model for the dynamics and another auxiliary output-error model for the noise, is consistent for Box-Jenkins models under standard regularity conditions. One Gauss-Newton iteration started from this estimator yields an estimator that is asymptotically equivalent to the prediction error method, provided the ARX model order satisfies a mild growth condition with the sample size.
What carries the argument
The sequentially decoupling estimator, built by chaining three least-squares steps (high-order ARX, auxiliary OE for dynamics, auxiliary OE for noise), which supplies a consistent initial value that one Gauss-Newton iteration converts into an asymptotically efficient result.
If this is right
- The sequentially decoupling estimator itself is consistent for Box-Jenkins models under open-loop and closed-loop conditions.
- The one-step Gauss-Newton refinement from the initial estimator achieves the same asymptotic efficiency as direct prediction-error minimization.
- The procedure provides a simpler computational alternative to weighted null-space fitting methods.
- All stages rely on standard least-squares solvers without needing specialized nonlinear optimization from the outset.
Where Pith is reading between the lines
- The decoupling structure may offer robustness advantages in closed-loop data where full prediction-error methods encounter correlation between input and noise.
- In practice the mild growth condition could be met by setting the ARX order to grow like log of sample size, which is easy to implement and check via Monte Carlo trials.
- The same sequential pattern might apply to other linear model classes where dynamics and noise can be isolated through auxiliary output-error fits.
Load-bearing premise
The ARX model order must grow mildly with sample size so that the one-step Gauss-Newton refinement achieves asymptotic equivalence to the prediction error method.
What would settle it
A simulation study or asymptotic analysis in which the ARX order is held fixed while sample size increases, showing that the refined estimator's covariance exceeds the prediction error method's covariance.
Figures

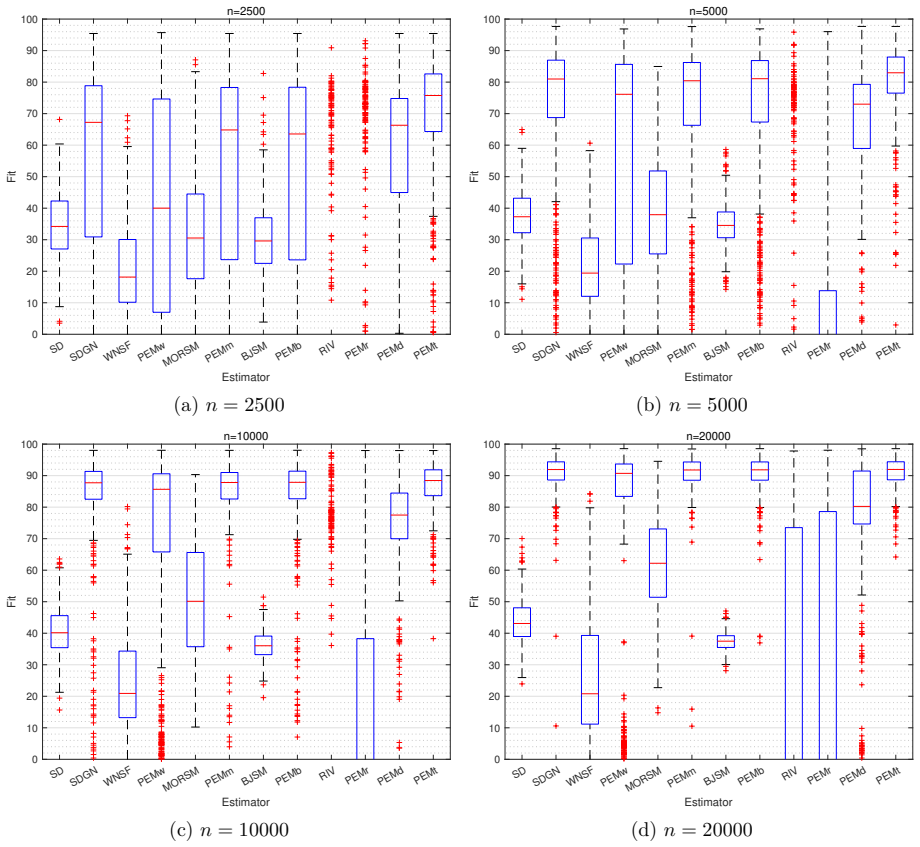
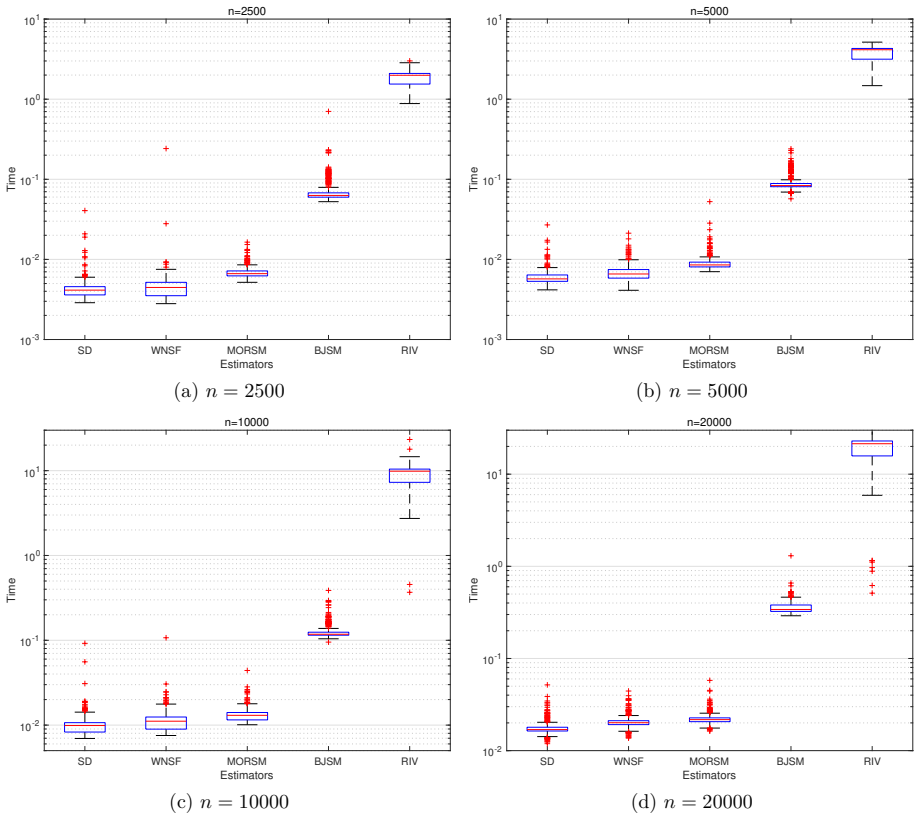
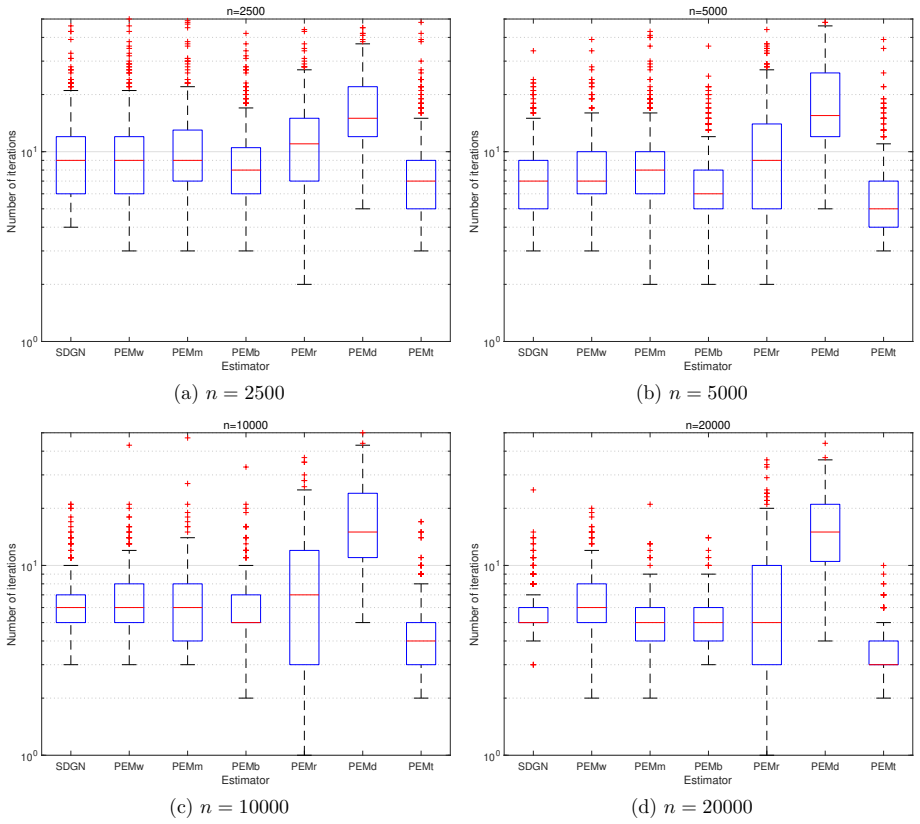
read the original abstract
In this paper, we propose a consistent and asymptotically efficient estimation method for Box-Jenkins (BJ) models that is applicable under both open-loop and closed-loop data conditions, serving as a possible alternative to the weighted null-space fitting approach. The method comprises two stages: an initial sequentially decoupling (SD) estimator, followed by Gauss-Newton (GN) refinement step. The SD estimator is constructed from three sequential least squares (LS) estimators: (i) estimation of a high-order autoregressive model with exogenous inputs (ARX) model; (ii) estimation of the BJ model's dynamic model via an auxiliary output-error (OE) model; and (iii) estimation of the noise model of the BJ model using another auxiliary OE model. We establish the consistency of the SD estimator under standard regularity conditions, leveraging the consistency of the underlying LS estimators for both the ARX and OE models. Moreover, we show that one-step GN iteration starting from the SD estimator yields an estimator that is asymptotically equivalent to the prediction error method, provided the ARX model order satisfies a mild growth condition. Simulation studies confirm the theoretical properties of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a sequentially decoupling (SD) estimator for Box-Jenkins models consisting of three least-squares steps (high-order ARX, auxiliary OE for the dynamics, auxiliary OE for the noise model) followed by a single Gauss-Newton iteration. It claims that the SD estimator is consistent under standard regularity conditions by leveraging consistency of the underlying ARX and OE LS estimators, and that the one-step GN refinement is asymptotically equivalent to the prediction-error method (PEM) when the ARX order satisfies a mild growth condition with sample size. The method is positioned as applicable to both open- and closed-loop data and as an alternative to weighted null-space fitting.
Significance. If the asymptotic equivalence holds with the stated growth condition, the approach would supply a computationally attractive, consistent and asymptotically efficient estimator for BJ models that avoids the iterative optimization of full PEM while retaining its statistical properties; this would be particularly useful in closed-loop identification settings where direct PEM can be sensitive to initialization.
major comments (1)
- [Abstract / asymptotic-equivalence derivation] Abstract and the section deriving asymptotic equivalence: the claim that one GN step from the SD estimator is asymptotically equivalent to PEM requires the initial estimator to satisfy ||θ_SD − θ_0|| = o_p(N^{−1/4}) so that the linearization remainder vanishes. The manuscript only invokes consistency of the three LS stages plus a “mild growth condition” on the ARX order n(N); no explicit rate bound (e.g., n = o(N^{1/5}) or similar) is derived that guarantees the required o_p(N^{−1/4}) rate, especially under closed-loop feedback where the ARX bias-variance trade-off depends on the relative growth of n(N) and the feedback bandwidth.
minor comments (1)
- [Simulation studies] The simulation section should report the exact ARX orders used relative to sample size and the observed convergence rates of the SD estimator to confirm the growth condition is satisfied in the reported experiments.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and insightful comments on our manuscript. We address the major concern regarding the asymptotic equivalence derivation below.
read point-by-point responses
-
Referee: [Abstract / asymptotic-equivalence derivation] Abstract and the section deriving asymptotic equivalence: the claim that one GN step from the SD estimator is asymptotically equivalent to PEM requires the initial estimator to satisfy ||θ_SD − θ_0|| = o_p(N^{−1/4}) so that the linearization remainder vanishes. The manuscript only invokes consistency of the three LS stages plus a “mild growth condition” on the ARX order n(N); no explicit rate bound (e.g., n = o(N^{1/5}) or similar) is derived that guarantees the required o_p(N^{−1/4}) rate, especially under closed-loop feedback where the ARX bias-variance trade-off depends on the relative growth of n(N) and the feedback bandwidth.
Authors: We agree with the referee that establishing the o_p(N^{-1/4}) rate for the SD estimator is necessary to rigorously justify the asymptotic equivalence of the one-step GN refinement to the PEM. The manuscript relies on a mild growth condition for the ARX order to ensure consistency and the desired asymptotic properties, but we acknowledge that the explicit rate bound guaranteeing ||θ_SD − θ_0|| = o_p(N^{-1/4}) was not derived in detail, particularly for the closed-loop case. In the revised version, we will include a derivation of the convergence rate of the SD estimator under the specified growth condition on n(N). This will involve analyzing the bias-variance trade-off in the high-order ARX estimation step and showing that the condition ensures the required rate even in the presence of feedback, by relating n(N) to the feedback bandwidth. We believe this addition will strengthen the theoretical contribution without altering the main results. revision: yes
Circularity Check
No circularity; claims derived from external standard results on LS consistency
full rationale
The paper constructs the SD estimator explicitly from three sequential LS steps (high-order ARX, auxiliary OE dynamics, auxiliary OE noise) and invokes the known consistency of those underlying LS estimators under standard regularity conditions to establish consistency of the SD estimator. The one-step GN refinement is shown to be asymptotically equivalent to PEM by appealing to general one-step Newton theory once the initial estimator satisfies a rate condition, which the paper claims follows from a mild growth condition on ARX order. No step reduces by construction to its own fitted values, renames a known result, or relies on a load-bearing self-citation whose content is unverified; the derivation chain remains independent of the target quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- ARX model order
axioms (1)
- domain assumption Standard regularity conditions for consistency of least-squares estimators for ARX and OE models
Reference graph
Works this paper leans on
-
[1]
System Identification: Theory for the User
Lennart Ljung. System Identification: Theory for the User . Upper Saddle River, NJ: Prentice-Hall, 1999
work page 1999
-
[2]
Torsten S¨ oderstr¨ om and Petre Stoica.System identification . Prentice Hall, 1989
work page 1989
-
[3]
George E. P. Box, Gwilym M. Jenkins, Gregory C. Reinsel, a nd Greta M. Ljung. Time Series Analysis: Forecasting and Control . Wiely, 2015
work page 2015
-
[4]
Box–Jen kins identification revisited— Part II: Applications
Rik Pintelon, Yves Rolain, and Johan Schoukens. Box–Jen kins identification revisited— Part II: Applications. Automatica, 42(1):77–84, 2006
work page 2006
-
[5]
Ronald J Triolo, DH Nash, and Gordon D Moskowitz. The iden tification of time series models of lower extremity EMG for the control of prostheses u sing Box–Jenkins criteria. IEEE Transactions on Biomedical Engineering , 35(8):584–594, 1988
work page 1988
-
[6]
Refined instrumental variable methods for identification of LPV Box–Jenkins mode ls
Vincent Laurain, Marion Gilson, Roland T´ oth, and Hugue s Garnier. Refined instrumental variable methods for identification of LPV Box–Jenkins mode ls. Automatica, 46(6):959–967, 2010
work page 2010
-
[7]
Es timation of jump Box–Jenkins models
Dario Piga, Valentina Breschi, and Alberto Bemporad. Es timation of jump Box–Jenkins models. Automatica, 120:109126, 2020
work page 2020
-
[8]
System Identification Toolbox for Use with MATLAB
Lennart Ljung. System Identification Toolbox for Use with MATLAB . The MathWorks, Inc., Natick, MA, 2025
work page 2025
-
[9]
Some results on identifying linear syste ms using frequency domain data
Lennart Ljung. Some results on identifying linear syste ms using frequency domain data. In Proceedings of 32nd IEEE Conference on Decision and Control , pages 3534–3538, 1993
work page 1993
-
[10]
Frequency domain identification metho ds
Tomas McKelvey. Frequency domain identification metho ds. Circuits, Systems and Signal Processing, 21(1):39–55, 2002
work page 2002
-
[11]
Box–Jenkins identifi cation revisited—Part I: Theory
Rik Pintelon and Johan Schoukens. Box–Jenkins identifi cation revisited—Part I: Theory. Automatica, 42(1):63–75, 2006
work page 2006
-
[12]
Peter C Young. Refined instrumental variable estimatio n: Maximum likelihood optimiza- tion of a unified Box–Jenkins model. Automatica, 52:35–46, 2015
work page 2015
-
[13]
Model reductions of high-order estimated models: the asymptotic ML ap- proach
Bo Wahlberg. Model reductions of high-order estimated models: the asymptotic ML ap- proach. International Journal of Control , 49(1):169–192, 1989
work page 1989
-
[14]
E. L. Lehmann and George Casella. Theory of Point Estimation . Springer-Verlag, New York, 1998. 24
work page 1998
-
[15]
The Box–Jenkins Stei glitz–McBride algorithm
Yucai Zhu and H ˚ akan Hjalmarsson. The Box–Jenkins Stei glitz–McBride algorithm. Auto- matica, 65:170–182, 2016
work page 2016
-
[16]
Open-loop asymptotically effi- cient model reduction with the Steiglitz–McBride method
Niklas Everitt, Miguel Galrinho, and H ˚ akan Hjalmarss on. Open-loop asymptotically effi- cient model reduction with the Steiglitz–McBride method. Automatica, 89:221–234, 2018
work page 2018
-
[17]
Parametric identification using weighted null-space fitting
Miguel Galrinho, Cristian R Rojas, and H ˚ akan Hjalmars son. Parametric identification using weighted null-space fitting. IEEE Transactions on Automatic Control , 64(7):2798– 2813, 2019
work page 2019
-
[18]
Estimating models with high-order noise dynamics using semi-parametric weighted null-space fitting
Miguel Galrinho, Cristian R Rojas, and H ˚ akan Hjalmars son. Estimating models with high-order noise dynamics using semi-parametric weighted null-space fitting. Automatica, 102:45–57, 2019
work page 2019
-
[19]
System identification with multi-step least-squares metho ds
Miguel Galrinho. System identification with multi-step least-squares metho ds. PhD thesis, KTH Royal Institute of Technology, 2018
work page 2018
-
[20]
Recursive Weighted Null-Space Fitting Method for Identification of Multivariate Systems
Mengyuan Fang, Miguel Galrinho, and H ˚ akan Hjalmarsson. Recursive Weighted Null-Space Fitting Method for Identification of Multivariate Systems. IF AC-PapersOnLine, 54(7):345– 350, 2021
work page 2021
-
[21]
Stefanie JM Fonken, Karthik Raghavan Ramaswamy, and Pa ul MJ Van den Hof. A scal- able multi-step least squares method for network identifica tion with unknown disturbance topology. Automatica, 141:110295, 2022
work page 2022
-
[22]
Identification of diffus ively coupled linear net- works through structured polynomial models
EMM Kivits and Paul MJ Van den Hof. Identification of diffus ively coupled linear net- works through structured polynomial models. IEEE Transactions on Automatic Control , 68(6):3513–3528, 2023
work page 2023
-
[23]
Jiabao He and H ˚ akan Hjalmarsson. Weighted null space fi tting (wnsf): A link between the prediction error method and subspace identification. arXiv preprint arXiv:2411.00506 , 2024
-
[24]
Lennart Ljung and Bo Wahlberg. Asymptotic properties o f the least-squares method for estimating transfer functions and disturbance spectra. Advances in Applied Probability , 24(2):412–440, 1992
work page 1992
-
[25]
A W van der Vaart. Asymptotic statistics . Cambridge University Press, 1998
work page 1998
-
[26]
Biqiang Mu, Er-Wei Bai, Wei Xing Zheng, and Quanmin Zhu. A globally consistent non- linear least squares estimator for identification of nonlin ear rational systems. Automatica, 77:322–335, 2017
work page 2017
-
[27]
A gauss-newton algorithm for explor atory factor analysis
Robert I Jennrich. A gauss-newton algorithm for explor atory factor analysis. Psychome- trika, 51(2):277–284, 1986
work page 1986
-
[28]
Time series: theory and methods
Peter J Brockwell and Richard A Davis. Time series: theory and methods . Springer, New York, 2nd edition edition, 1991
work page 1991
-
[29]
Pierre Duchesne, Pierre Lafaye de Micheaux, and Joseph Francois Tagne Tatsinkou. On strong consistency and asymptotic normality of one-step Ga uss-Newton estimators in ARMA time series models. Statistics, 54(5):1030–1057, 2020
work page 2020
-
[30]
Discrete multivariate analysis: Theory and practice
Yvonne M Bishop, Stephen E Fienberg, and Paul W Holland. Discrete multivariate analysis: Theory and practice . Springer-Verlag, New York, 2007. 25
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.