Recognition: unknown
On Stable Long-Form Generation: Benchmarking and Mitigating Length Volatility
Pith reviewed 2026-05-09 15:04 UTC · model grok-4.3
The pith
Large language models exhibit unstable output lengths when generating long-form text, but a lightweight decoding adjustment raises average length by 148 percent and cuts volatility by 69 percent without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
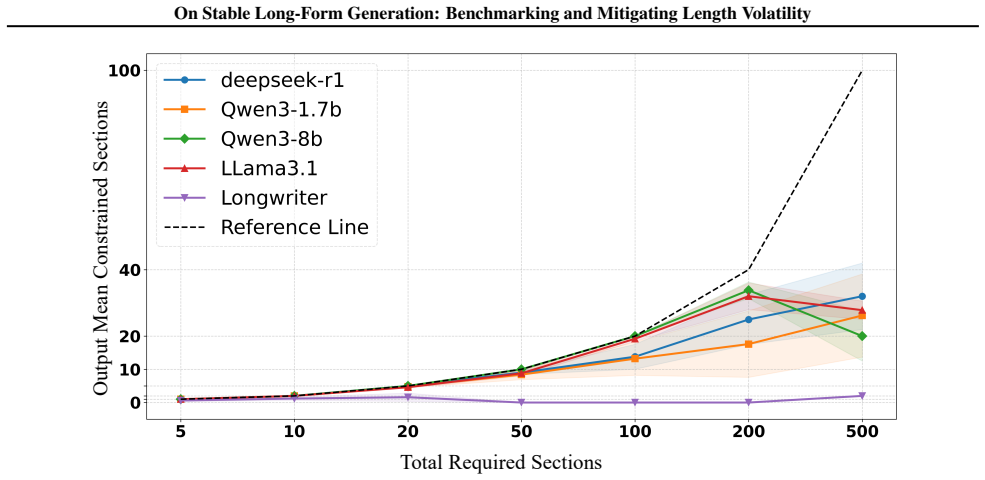
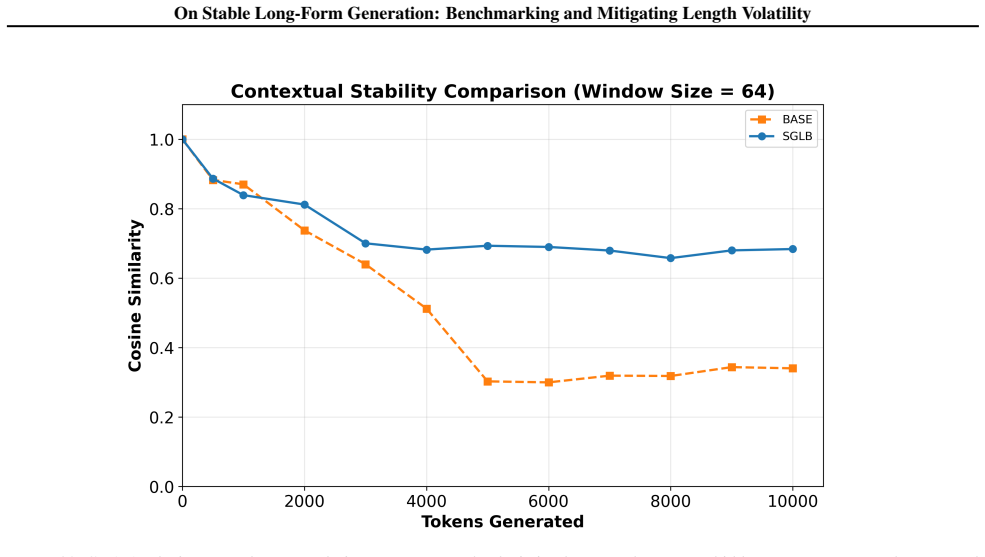
The paper claims that severe length volatility is widespread in mainstream LLMs for long-form tasks, driven by specific attention patterns, and that GLoBo mitigates it effectively. Experiments confirm an average 148% increase in output length and 69% drop in volatility on VOLTBench, with no loss in generation quality.
What carries the argument
GLoBo, a logits-boosting strategy applied at the decoding stage to promote stable continuation in long-form text generation.
Load-bearing premise
The attention patterns identified through probing are the actual drivers of length volatility rather than just correlated symptoms, and the VOLTBench tasks represent the length consistency requirements of real-world long-form use cases.
What would settle it
A replication study on new long-form generation tasks showing that GLoBo produces no statistically significant change in length mean or variance would falsify the mitigation results.
Figures





































read the original abstract
Large Language Models (LLMs) excel at long-context understanding but exhibit significant limitations in long-form generation. Existing studies primarily focus on single-generation quality, generally overlooking the volatility of the output. This volatility not only leads to significant computational costs but also severely impacts the models' reliable application. To address this gap, our work unfolds in three stages: benchmarking, probing, and mitigation. We first propose the VOlatility in Long-form Text Benchmark (VOLTBench), a novel heterogeneous-task benchmark designed to systematically quantify the length volatility of long-form generation. Subsequently, by analyzing attention traces, we conduct an in-depth probe to identify several common internal patterns that cause this volatility. Finally, to mitigate long-form output volatility, we propose Stable Generation via Logits Boosting (GLoBo), a lightweight decoding-stage optimization strategy, designed to significantly enhance both the length accuracy and stability of long-form generation without additional training. Extensive experiments on VOLTBench provide the first systematic confirmation of severe long-form output instability in mainstream models and validate that our proposed method successfully improves the mean output length of the base model by 148% and reduces the length volatility by 69%, while maintaining high generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mainstream LLMs exhibit severe length volatility in long-form generation. It introduces VOLTBench, a heterogeneous-task benchmark to quantify this instability, probes attention traces to identify common internal patterns causing volatility, and proposes GLoBo, a lightweight logits-boosting decoding strategy that improves length accuracy and stability without training. Experiments on VOLTBench are said to confirm the instability and show that GLoBo increases mean output length by 148% while reducing volatility by 69%, with maintained generation quality.
Significance. If the empirical results hold under rigorous controls, the work addresses a practically important but understudied limitation in LLM deployment: output length instability that raises compute costs and harms reliability. VOLTBench provides a new standardized evaluation resource, and GLoBo offers a simple, training-free intervention with potentially broad applicability. The focus on decoding-stage mitigation and the reported scale of improvements are notable strengths.
major comments (2)
- [§4 (Probing)] §4 (Probing): The analysis identifies attention patterns correlated with length deviations via trace inspection on generated outputs, but presents no interventional tests (e.g., targeted head masking, attention logit intervention, or controlled ablations) that directly modify the flagged patterns and measure resulting changes in length statistics. This makes the causal claim that the patterns 'cause this volatility' unsupported and weakens the justification that GLoBo targets the root mechanism rather than a downstream correlate.
- [§6 (Experiments)] §6 (Experiments) and associated result tables: The abstract reports precise gains (148% mean length increase, 69% volatility reduction). These require (a) an explicit mathematical definition of the volatility metric, (b) full per-model/per-task tables with standard deviations across seeds, (c) statistical significance tests, and (d) comparisons against multiple length-control baselines. Without these, the central performance claims cannot be verified as robust.
minor comments (2)
- [Abstract] Abstract: Briefly enumerate the 'several common internal patterns' identified in probing to improve reader understanding before the detailed section.
- [§3 (VOLTBench)] VOLTBench description: Clarify task selection criteria and how the benchmark ensures coverage of real-world long-form scenarios where length consistency is critical.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which helps us improve the clarity and rigor of the manuscript. We respond to each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§4 (Probing)] The analysis identifies attention patterns correlated with length deviations via trace inspection on generated outputs, but presents no interventional tests (e.g., targeted head masking, attention logit intervention, or controlled ablations) that directly modify the flagged patterns and measure resulting changes in length statistics. This makes the causal claim that the patterns 'cause this volatility' unsupported and weakens the justification that GLoBo targets the root mechanism rather than a downstream correlate.
Authors: We agree that the probing analysis in §4 relies on observational trace inspection and identifies consistent correlations between specific attention patterns and length deviations, without direct interventional validation of causality. The patterns were selected because they appeared reliably across models and tasks in the VOLTBench evaluations. GLoBo was motivated by these observations as a practical, training-free way to counteract the downstream effects on token selection. In the revision we will (i) explicitly qualify the language to describe the patterns as strongly correlated rather than causal, (ii) add a dedicated limitations paragraph discussing the correlational nature of the analysis and the value of future interventional work, and (iii) include a brief additional ablation that perturbs the relevant logit regions to show measurable impact on length statistics. These changes will be made without claiming stronger causal evidence than the data support. revision: partial
-
Referee: [§6 (Experiments)] The abstract reports precise gains (148% mean length increase, 69% volatility reduction). These require (a) an explicit mathematical definition of the volatility metric, (b) full per-model/per-task tables with standard deviations across seeds, (c) statistical significance tests, and (d) comparisons against multiple length-control baselines. Without these, the central performance claims cannot be verified as robust.
Authors: We accept that the current presentation of the experimental results is insufficient for full verification. In the revised manuscript we will: (a) insert the precise mathematical definition of the volatility metric (standard deviation of normalized output lengths across repeated generations), (b) expand all result tables to report per-model and per-task means together with standard deviations computed over multiple random seeds, (c) add statistical significance tests (e.g., paired Wilcoxon tests) for the reported improvements, and (d) include direct comparisons against additional length-control baselines such as length-penalized decoding and controlled-temperature sampling. These additions will be placed in §6 and the appendix so that the 148 % and 69 % figures can be independently assessed. revision: yes
Circularity Check
No circularity; claims rest on new benchmark and empirical validation
full rationale
The paper introduces VOLTBench as a new heterogeneous-task benchmark to quantify length volatility, performs attention trace analysis to identify patterns, and proposes the GLoBo decoding strategy as mitigation. Central results (148% mean length improvement, 69% volatility reduction) are obtained via direct experiments on the newly defined benchmark and models, without any fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that reduce the derivation to its inputs. The chain is self-contained with independent empirical measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLM tropes: Revealing fine-grained values and opinions in large language models
URL https://aclanthology.org/2023. findings-emnlp.613/. He, Z., Cao, P., Wang, C., Jin, Z., Chen, Y ., Xu, J., Li, H., Liu, K., and Zhao, J. AgentsCourt: Build- ing judicial decision-making agents with court debate simulation and legal knowledge augmentation. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.), Findings of the Association for Computat...
-
[2]
Metacognitive Prompting Improves Understanding in Large Language Models
URL https://aclanthology.org/2024. findings-emnlp.549/. He, Z., Liu, Z., Li, P., Fung, Y . R., Yan, M., Zhang, J., Huang, F., and Liu, Y . Advancing language multi-agent learning with credit re-assignment for interactive environ- ment generalization.arXiv preprint arXiv:2502.14496, 2025a. He, Z., Yang, H., Qin, Z., and Fung, Y . R. Medtutor- r1: Socratic ...
-
[3]
URL https://aclanthology.org/2021. emnlp-main.677/. Quan, S., Tang, T., Yu, B., Yang, A., Liu, D., Gao, B., Tu, J., Zhang, Y ., Zhou, J., and Lin, J. Language models can self-lengthen to generate long texts, 2024. URL https://arxiv.org/abs/2410.23933. Que, H., Duan, F., He, L., Mou, Y ., Zhou, W., Liu, J., Rong, W., Wang, Z. M., Yang, J., Zhang, G., Peng,...
-
[4]
URL https: //aclanthology.org/D19-1331/
doi: 10.18653/v1/D19-1331. URL https: //aclanthology.org/D19-1331/. Tan, H., Guo, Z., Shi, Z., Xu, L., Liu, Z., Feng, Y ., Li, X., Wang, Y ., Shang, L., Liu, Q., and Song, L. Prox- yqa: An alternative framework for evaluating long-form text generation with large language models, 2024. URL https://arxiv.org/abs/2401.15042. Team, F.-L. The falcon 3 family o...
-
[5]
URL https://dl.acm.org/doi/abs/10. 1145/3746027.3755221. Wang, M., Chen, L., Fu, C., Liao, S., Zhang, X., Wu, B., Yu, H., Xu, N., Zhang, L., Luo, R., Li, Y ., Yang, M., Huang, F., and Li, Y . Leave no document behind: Benchmarking long-context llms with extended multi-doc qa, 2024a. URLhttps://arxiv.org/abs/2406.17419. Wang, Y ., Ma, D., and Cai, D. With ...
-
[6]
FC-Attack: Jailbreaking multimodal large language models via auto-generated flowcharts
URL https://openreview.net/forum? id=NG7sS51zVF. Xie, E., Xiong, G., Yang, H., Coleman, O., Kennedy, M., and Zhang, A. Leveraging grounded large language mod- els to automate educational presentation generation. In Large Foundation Models for Educational Assessment, pp. 207–220. PMLR, 2025. Yang, H., Zhang, J., He, Z., and Fung, Y . R. Mars-sql: A multi-a...
-
[7]
URL https://aclanthology.org/2025. findings-emnlp.1320/. Zhang, J., Zhang, R., Kong, F., Miao, Z., Ye, Y ., and Zheng, Y . Lost-in-the-middle in long-text generation: Synthetic dataset, evaluation framework, and mitigation, 2025b. URLhttps://arxiv.org/abs/2503.06868. Zhang, W., Zhou, Z., Wang, K., Fang, J., Zhang, Y ., Wang, R., Zhang, G., Li, X., Sun, L....
-
[8]
findings-emnlp.773/
URL https://aclanthology.org/2023. findings-emnlp.773/. Zhou, Z., Li, C., Chen, X., Wang, S., Chao, Y ., Li, Z., Wang, H., Shi, Q., Tan, Z., Han, X., Shi, X., Liu, Z., and Sun, M. LLM ×MapReduce: Simplified long- sequence processing using large language models. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Proceedings of the 63rd Annual...
2023
-
[9]
"" This function calculates the area of a circle given its radius. Parameters: radius (float): The radius of the circle. Returns: float: The area of the circle
Association for Computational Linguistics. ISBN 979-8-89176-251-0. URL https://aclanthology. org/2025.acl-long.1341/. 13 On Stable Long-Form Generation: Benchmarking and Mitigating Length Volatility A. LLM Usage This paper addresses the challenge of output volatility in the long-form generation of Large Language Models (LLMs). We introduce VOLTBench, a no...
2025
-
[10]
21 On Stable Long-Form Generation: Benchmarking and Mitigating Length Volatility Figure 24.Model performance on theKeyword Presence Constraint
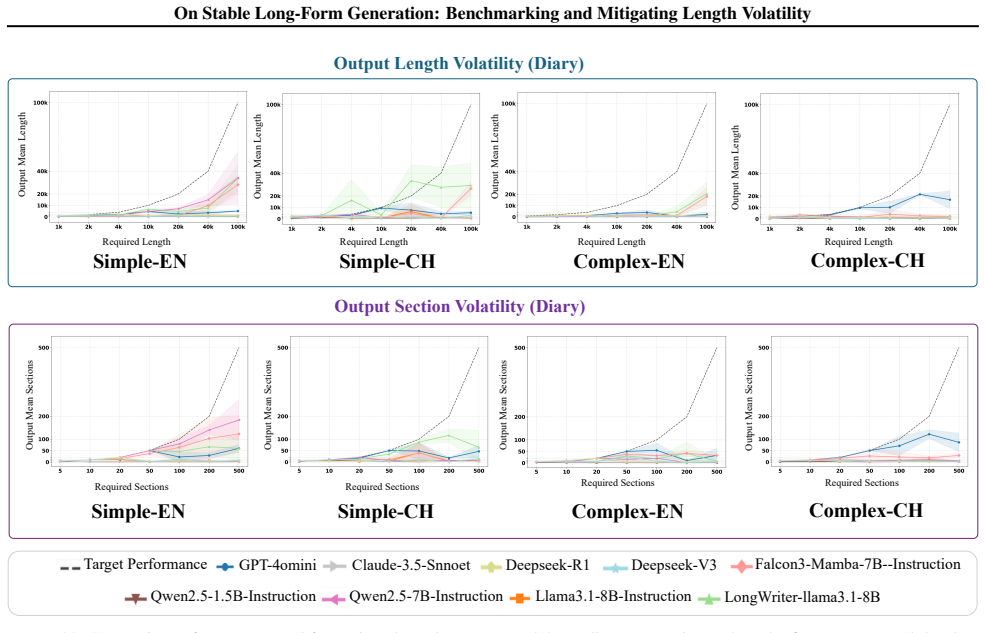
Premature Termination:The model failed to complete the generation, stopping abruptly after only three short paragraphs, far short of the required 40 entries. 21 On Stable Long-Form Generation: Benchmarking and Mitigating Length Volatility Figure 24.Model performance on theKeyword Presence Constraint. The x-axis represents the total number of generated sec...
-
[11]
Dialogue Hallucination:The model’s output terminates by hallucinating a user’s follow-up question. This suggests that the model incorrectly inferred a conversational context, switching from a content generation role to a chatbot role, and then stopped, awaiting human intervention. The generation of such special tokens associated with user queries is a dir...
-
[12]
Traveler,
Underlying Cause - Attention Degradation:The root cause of this failure pattern can be linked to the model’s internal state. As shown in the attention trace analysis (see Figure 26), the model’s attention scores became progressively lower towards the end of the generated sequence. This indicates that the model was losing its ability to focus on the contex...
-
[13]
Task Mismatch:Similar to the previous case, the model was prompted for a 40-day EN-simple-diary but generated a fantasy story instead
-
[14]
It correctly produced the first 10 chapters, but then jumped directly to the final chapter (Chapter 40), omitting the 29 chapters in between
Section Skipping:The primary failure is the model’s inability to generate the content sequentially. It correctly produced the first 10 chapters, but then jumped directly to the final chapter (Chapter 40), omitting the 29 chapters in between. This behavior fulfills the superficial requirement of ending at Chapter 40 without performing the actual work of ge...
-
[15]
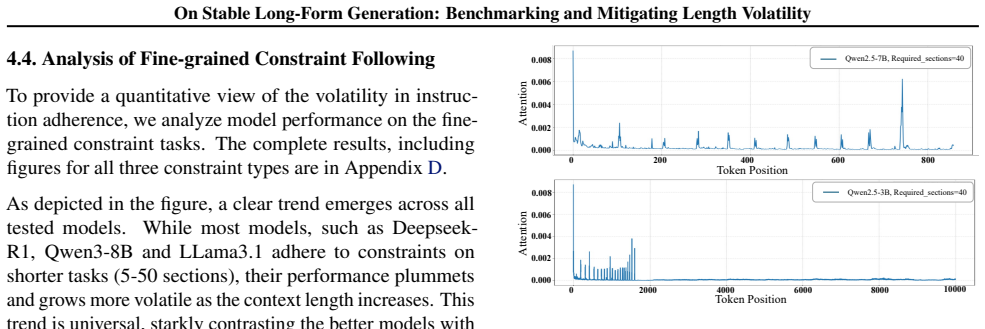
Underlying Cause - Attention Spike:This “lazy” behavior is correlated with a distinct attention pattern. As shown in the attention trace (see Figure 4), a sharp spike in the attention peak occurs immediately before the model generates the skipped section (”Chapter 40”). This suggests the model recognized the start (”Chapter 1”) and end (”Chapter 40”) poin...
-
[16]
However, its output quality begins to degrade significantly (Chapters 19-20), losing grammatical structure and becoming a stream of loosely related words
Content Degradation:The model initially generates coherent content (Chapters 1-18). However, its output quality begins to degrade significantly (Chapters 19-20), losing grammatical structure and becoming a stream of loosely related words
-
[17]
greatly esteemed,
Repetitive Loop:The degradation culminates in Chapter 21, where the model enters a terminal repetitive loop, endlessly 24 On Stable Long-Form Generation: Benchmarking and Mitigating Length Volatility outputting a fixed sequence of high-probability words (e.g., “greatly esteemed,” ”highly revered”). This indicates a complete collapse of its ability to gene...
-
[18]
Underlying Cause - Attention Collapse:This failure is symptomatic of an “attention collapse.” After generating a substantial amount of text, the model’s attention mechanism is no longer able to produce meaningful peaks or focus on relevant parts of the context. Without sufficient attention to guide its next token selection, the model falls back into a sim...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.