Recognition: unknown
PACE: Parameter Change for Unsupervised Environment Design
Pith reviewed 2026-05-09 14:19 UTC · model grok-4.3
The pith
PACE selects training environments in unsupervised environment design by the squared L2 norm of the induced policy parameter update.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PACE assigns environment value using a first-order approximation of the policy optimization objective, where the improvement induced by an environment is proportional to the squared L2 norm of the corresponding parameter update, enabling low-variance and computation-efficient evaluation without additional rollouts.
What carries the argument
the squared L2 norm of the policy parameter update after training on an environment, used as a direct proxy for the improvement that environment produces in the policy optimization objective
If this is right
- Environment evaluation requires no extra rollouts beyond the normal training step on the sampled environment.
- Selection becomes lower variance because the signal is computed directly from the gradient update rather than from noisy value estimates or regret calculations.
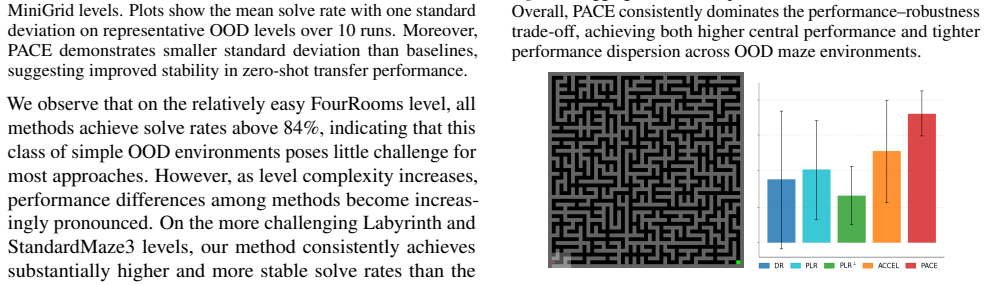
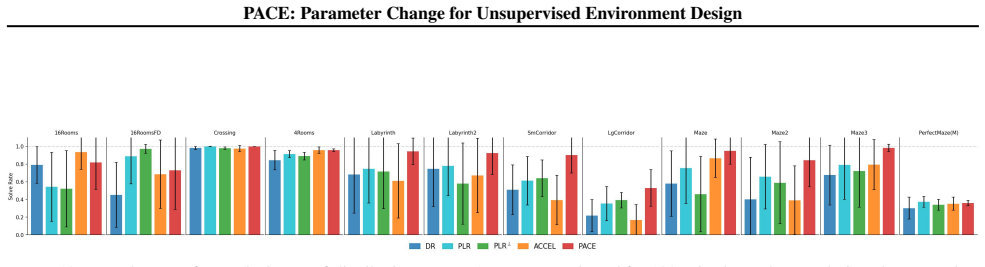
- Agents trained under PACE achieve higher interquartile mean scores and smaller optimality gaps on out-of-distribution test environments compared with prior UED baselines.
- The method remains computationally lighter than Monte-Carlo or regret-based alternatives while still adapting the environment distribution during training.
Where Pith is reading between the lines
- The same parameter-change signal could be reused to decide when to retire or re-weight environments inside a fixed curriculum rather than only at generation time.
- Because the norm is a first-order quantity, second-order curvature information from the Hessian might further refine the ranking without requiring new environment samples.
- The approach suggests that any RL setting in which one must choose among many candidate tasks or data sources could substitute parameter-update magnitude for more expensive performance proxies.
Load-bearing premise
The squared L2 norm of the policy parameter update induced by training on an environment accurately reflects realized learning progress and the true improvement in the policy optimization objective.
What would settle it
An experiment in which environments ranked highest by squared parameter-update norm produce no better or worse out-of-distribution performance than environments ranked by existing proxies such as regret.
Figures






read the original abstract
Unsupervised Environment Design (UED) offers a promising paradigm for improving reinforcement learning generalization by adaptively shaping training environments, but it requires reliable environment evaluation to remain effective. However, existing UED methods evaluate environments using indirect proxy signals such as regret, value-based errors, or Monte Carlo, which suffer from bias, high variance, or substantial computational overhead and fail to reflect agent realized learning progress. To address these limitations, we propose Parameter Change Environment Design (PACE), which evaluates an environment through the policy parameter change induced by training on that environment, directly grounding environment selection in realized learning progress. Specifically, PACE assigns environment value using a first-order approximation of the policy optimization objective, where the improvement induced by an environment is proportional to the squared L2 norm of the corresponding parameter update, enabling low-variance and computation-efficient evaluation without additional rollouts. Experiments on MiniGrid and Craftax show that PACE consistently outperforms established UED baselines, achieving higher IQM and smaller Optimality Gap on OOD evaluations, including an IQM of 96.4% and an Optimality Gap of 17.2% on MiniGrid.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Parameter Change Environment Design (PACE) for Unsupervised Environment Design (UED) in reinforcement learning. It evaluates training environments by the squared L2 norm of the policy parameter update induced by training on that environment, justified via a first-order Taylor approximation to the policy optimization objective (improvement proportional to ||Δθ||²). This is claimed to yield low-variance, rollout-free environment selection that directly reflects realized learning progress. Experiments on MiniGrid and Craftax report that PACE outperforms prior UED baselines on out-of-distribution IQM and optimality gap metrics (e.g., IQM of 96.4% and optimality gap of 17.2% on MiniGrid).
Significance. If the ||Δθ||² proxy is shown to be monotonic with actual objective improvement under the optimizers and update rules used, PACE would supply a computationally cheap, low-variance alternative to regret- or value-based UED signals. The reported benchmark gains would then constitute a practically useful advance in adaptive environment generation for generalization.
major comments (3)
- [Abstract / Method description] The central justification (abstract) equates environment value with ||Δθ||² via the first-order claim J(θ+Δθ) − J(θ) ≈ ∇J · Δθ and the assumption that Δθ is collinear with ∇J. No derivation, error bound, or analysis of higher-order terms appears; the manuscript therefore provides no guarantee that the proxy remains monotonic once momentum, adaptive per-parameter scaling, or clipping (standard in PPO/Adam) are present.
- [Experiments section] The evaluation protocol uses the actual parameter update obtained after training on the candidate environment. While this is independent of the selection step itself, the paper supplies neither an ablation that isolates the effect of the ||Δθ||² metric from other implementation choices nor a direct correlation plot between ||Δθ||² and measured return improvement on the same environment.
- [Results / Tables] Table or figure reporting the MiniGrid and Craftax results (IQM 96.4 %, optimality gap 17.2 %) does not state the number of independent seeds, confidence intervals, or statistical tests against baselines; without these controls the superiority claim cannot be assessed for robustness.
minor comments (2)
- [Method] Notation for the environment value function (presumably V(e) ∝ ||Δθ_e||²) should be introduced with an explicit equation rather than described only in prose.
- [Abstract] The abstract states “without additional rollouts,” yet the method still requires a full training episode on each candidate environment; a clarifying sentence on the computational trade-off would help.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate clarifications, additional analyses, and statistical reporting where appropriate.
read point-by-point responses
-
Referee: [Abstract / Method description] The central justification (abstract) equates environment value with ||Δθ||² via the first-order claim J(θ+Δθ) − J(θ) ≈ ∇J · Δθ and the assumption that Δθ is collinear with ∇J. No derivation, error bound, or analysis of higher-order terms appears; the manuscript therefore provides no guarantee that the proxy remains monotonic once momentum, adaptive per-parameter scaling, or clipping (standard in PPO/Adam) are present.
Authors: We acknowledge that the manuscript relies on the first-order Taylor approximation without providing an explicit derivation, error bounds, or analysis of higher-order terms and practical optimizer effects. The core idea is that, under gradient ascent where Δθ is aligned with ∇J, the improvement approximates a quantity proportional to ||Δθ||². In the revised manuscript, we will add a step-by-step derivation in the methods section, explicitly state the collinearity assumption, discuss limitations arising from momentum, adaptive scaling (e.g., Adam), and clipping, and note that the proxy is an empirical approximation rather than a strict guarantee of monotonicity. We will also reference the empirical performance on MiniGrid and Craftax as supporting evidence despite these approximations. revision: yes
-
Referee: [Experiments section] The evaluation protocol uses the actual parameter update obtained after training on the candidate environment. While this is independent of the selection step itself, the paper supplies neither an ablation that isolates the effect of the ||Δθ||² metric from other implementation choices nor a direct correlation plot between ||Δθ||² and measured return improvement on the same environment.
Authors: We agree that an ablation isolating the ||Δθ||² metric and a direct correlation analysis would strengthen the experimental section. In the revised manuscript, we will add an ablation comparing the full PACE method against variants that replace the ||Δθ||² selection with alternative signals (while keeping other implementation details fixed) and include a scatter plot or quantitative correlation measure between ||Δθ||² values and the observed return improvement on the same environments. These additions will help isolate the metric's contribution and validate its alignment with learning progress. revision: yes
-
Referee: [Results / Tables] Table or figure reporting the MiniGrid and Craftax results (IQM 96.4 %, optimality gap 17.2 %) does not state the number of independent seeds, confidence intervals, or statistical tests against baselines; without these controls the superiority claim cannot be assessed for robustness.
Authors: We apologize for the omission of these details in the results presentation. In the revised manuscript, we will update all relevant tables and figures to explicitly report the number of independent seeds used, include confidence intervals, and add statistical comparisons (such as significance tests) against the baselines to allow proper assessment of robustness. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper justifies the ||Δθ||² proxy via a first-order Taylor expansion of the policy objective J(θ+Δθ) ≈ J(θ) + ∇J·Δθ, then notes that under gradient ascent this is proportional to ||Δθ||². However, the actual implementation computes Δθ by performing the real policy update on the environment, making the metric an observed quantity rather than a fitted prediction or self-referential definition. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior work are present. The central claim is an empirical proposal validated on external benchmarks (MiniGrid, Craftax) with reported IQM and Optimality Gap metrics; it does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A first-order approximation of the policy optimization objective can be used to estimate environment-induced improvement via the squared L2 norm of the parameter update
Reference graph
Works this paper leans on
-
[1]
Beukman, M., Coward, S., Matthews, M., Fellows, M., Jiang, M., Dennis, M., and Foerster, J. Refining mini- 8 PACE: Parameter Change for Unsupervised Environment Design max regret for unsupervised environment design.arXiv preprint arXiv:2402.12284,
-
[2]
Minimalis- tic gridworld environment for openai gym (2018).URL https://github
Chevalier-Boisvert, M., Willems, L., and Pal, S. Minimalis- tic gridworld environment for openai gym (2018).URL https://github. com/maximecb/gym-minigrid, 6,
2018
-
[3]
Jaxued: A simple and useable ued library in jax.arXiv preprint arXiv:2403.13091,
Coward, S., Beukman, M., and Foerster, J. Jaxued: A simple and useable ued library in jax.arXiv preprint arXiv:2403.13091,
-
[4]
Benchmarking the spectrum of agent capabilities.arXiv preprint arXiv:2109.06780,
Hafner, D. Benchmarking the spectrum of agent capabilities. arXiv preprint arXiv:2109.06780,
-
[5]
Matthews, M., Beukman, M., Ellis, B., Samvelyan, M., Jackson, M., Coward, S., and Foerster, J. Craftax: A lightning-fast benchmark for open-ended reinforcement learning.arXiv preprint arXiv:2402.16801,
-
[6]
Monette, N., Letcher, A., Beukman, M., Jackson, M. T., Rutherford, A., Goldie, A. D., and Foerster, J. N. An optimisation framework for unsupervised environment design.arXiv preprint arXiv:2505.20659,
-
[7]
Supervision via competition: Robot adversaries for learning tasks
Pinto, L., Davidson, J., and Gupta, A. Supervision via competition: Robot adversaries for learning tasks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 1601–1608. IEEE,
2017
-
[8]
Automatic curriculum learning for deep rl: A short survey.arXiv preprint arXiv:2003.04664,
Portelas, R., Colas, C., Hofmann, K., and Oudeyer, P.-Y . Automatic curriculum learning for deep rl: A short survey. arXiv preprint arXiv:2003.04664,
-
[9]
Unsupervised partner design enables ro- bust ad-hoc teamwork.arXiv preprint arXiv:2508.06336,
Ruhdorfer, C., Bortoletto, M., Oei, V ., Penzkofer, A., and Bulling, A. Unsupervised partner design enables ro- bust ad-hoc teamwork.arXiv preprint arXiv:2508.06336,
-
[10]
Samvelyan, M., Khan, A., Dennis, M., Jiang, M., Parker- Holder, J., Foerster, J., Raileanu, R., and Rockt¨aschel, T. Maestro: Open-ended environment design for multi-agent reinforcement learning.arXiv preprint arXiv:2303.03376,
-
[11]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Towers, M., Kwiatkowski, A., Terry, J., Balis, J. U., De Cola, G., Deleu, T., Goul˜ao, M., Kallinteris, A., Krimmel, M., KG, A., et al. Gymnasium: A standard interface for 9 PACE: Parameter Change for Unsupervised Environment Design reinforcement learning environments.arXiv preprint arXiv:2407.17032,
work page internal anchor Pith review arXiv
-
[13]
Wang, R., Lehman, J., Clune, J., and Stanley, K. O. Paired open-ended trailblazer (poet): Endlessly generating in- creasingly complex and diverse learning environments and their solutions.arXiv preprint arXiv:1901.01753,
work page Pith review arXiv 1901
-
[14]
Research in this area follows a clear trajectory
studies how to automatically construct training environment curricula that match an agent current learning stage, with the goal of improving generalization and robustness in unseen environments. Research in this area follows a clear trajectory. Early work emphasizes environment diversity as a heuristic for generalization, later developments introduce game...
2017
-
[15]
develops a unified optimization perspective for UED, analyzing stability and convergence properties across different methods within a common framework. Together, these studies highlight a key trend in UED research from 2024 to 2025: the focus gradually moves away from how to generate environments toward whether environment evaluation signals faithfully re...
2024
-
[16]
This work demonstrates that UED can influence emergent collective behavior, rather than merely adjusting difficulty
introduces MAESTRO, a representative multi-agent UED approach that automatically generates environments promoting cooperation, competition, and mixed interaction patterns. This work demonstrates that UED can influence emergent collective behavior, rather than merely adjusting difficulty. This direction also connects closely to broader open-ended reinforce...
2019
-
[17]
proposes Unsupervised Partner Design, which shifts the focus from environment parameters to the automatic construction of diverse training partners with distinct behavioral profiles. By exposing agents to varied interaction partners, this line of work improves zero-shot ad-hoc teamwork and suggests that underspecified factors in UED extend beyond environm...
2022
-
[18]
Evaluation Stability.The MB estimate ∆ ˆJMB is computed as the difference between two Monte Carlo return estimates
As a result, PACE reduces the evaluation cost by several orders of magnitude and incursno additional sampling costbeyond the standard training update. Evaluation Stability.The MB estimate ∆ ˆJMB is computed as the difference between two Monte Carlo return estimates. Its variance therefore satisfies Var(∆ ˆJMB)≈Var(V new) + Var(Vold). In sparse-reward or h...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.