Recognition: unknown
Assistance Without Interruption: A Benchmark and LLM-based Framework for Non-Intrusive Human-Robot Assistance
Pith reviewed 2026-05-09 14:47 UTC · model grok-4.3
The pith
Robots can provide proactive help on human tasks without interrupting by deciding timing and actions from the ongoing plan alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper's central claim is that non-intrusive assistance can be formalized as a joint decision over timing and action content, with the human's plan treated as the primary process; a hybrid LLM-plus-scoring architecture solves this by applying semantic retrieval to prune candidate robot actions and a learned ranker to score human-step and robot-action pairs, thereby capturing cross-step dependencies and enabling proactive yet non-disruptive support.
What carries the argument
The hybrid architecture that integrates an LLM with a scoring model using semantic retrieval to prune candidate actions followed by a ranker that evaluates human-step and robot-action pairs for timing and cross-step dependencies.
If this is right
- Assistance decisions no longer require explicit human commands or explicit negotiation.
- Human effort drops while task completion rates stay comparable to unassisted performance.
- New metrics in NIABench make it possible to quantify both the benefit and the non-intrusiveness of robot actions.
- The same retrieval-plus-ranker pipeline works across simulated benchmarks and physical robot setups.
Where Pith is reading between the lines
- If the timing inference holds in varied settings, robots could join shared workspaces such as kitchens or workshops without forcing humans to pause or explain their next move.
- The method might extend naturally to domains like collaborative assembly or remote guidance where timing errors are costly.
- Real-world deployment would still need checks for cases where semantic similarity alone fails to capture subtle human intent shifts.
Load-bearing premise
Semantic retrieval combined with a learned ranker can reliably determine the best moment and action for assistance solely from the human's visible ongoing plan.
What would settle it
A controlled trial in which the robot's chosen assistance moments and actions are compared against independent human ratings of optimal timing in tasks with ambiguous next steps, measuring whether effort decreases without added interruptions or task failures.
Figures



read the original abstract
Human-robot interaction (HRI) has long studied how agents and people coordinate to achieve shared goals. In this work, we formalize and benchmark the non-intrusive assistance as an independent paradigm of HRI, where a robot proactively supports a human's ongoing multi-step activities while strictly avoiding interruptions. Unlike conventional HRI tasks that rely on direct commands, explicit negotiation, or proactive interventions based on user habits and history, our task treats the human's plan as the primary process and formulates assistance as a joint decision over when to act and what to do. To systematically evaluate this problem, we establish a simulation benchmark, NIABench, along with new metrics tailored to the non-intrusive assistance task. We further propose a hybrid architecture that integrates an LLM with a scoring model. The scoring model first applies semantic retrieval to prune large candidate action sets, and then a ranker evaluates human-step and robot-action pairs, enabling reasoning over timing and cross-step dependencies. Comprehensive experiments on both NIABench and real-world scenarios demonstrate that our method achieves proactive, non-intrusive assistance that reduces human effort while preserving task effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes non-intrusive assistance as an HRI paradigm in which a robot proactively supports a human's ongoing multi-step plan while strictly avoiding interruptions, without relying on explicit commands, negotiation, or history-based prediction. It introduces NIABench as a simulation benchmark together with new task-specific metrics, proposes a hybrid architecture that pairs an LLM with a scoring model (semantic retrieval to prune candidates followed by a ranker over human-step/robot-action pairs), and reports comprehensive experiments on NIABench plus real-world scenarios that claim to demonstrate reduced human effort while preserving task effectiveness.
Significance. If the empirical claims hold, the work would make a useful contribution by defining a distinct assistance paradigm and supplying a benchmark that could standardize evaluation in proactive HRI. The hybrid retrieval-plus-ranker design offers a concrete way to operationalize timing and cross-step reasoning with LLMs. The creation of NIABench and tailored metrics is a clear positive, provided the benchmark inputs genuinely require inference from partial observations.
major comments (2)
- [Abstract / §4 (Experiments)] Abstract and experimental sections: the central claim that the method 'achieves proactive, non-intrusive assistance that reduces human effort while preserving task effectiveness' is asserted without any quantitative results, baseline comparisons, metric definitions, or error analysis. Because these numbers are load-bearing for the experimental success statement, their absence prevents assessment of whether the reported gains are meaningful or statistically supported.
- [Benchmark / Method sections] Benchmark description (likely §3): the skeptic concern is load-bearing. If NIABench supplies complete plan sequences or step labels as direct input to the scoring model, the ranker performs only intra-plan matching rather than recovering latent timing from partial observations. The manuscript must explicitly state the exact observation provided at each decision point (e.g., whether the current human step is labeled or only raw actions are visible) so that the non-intrusive claim can be evaluated.
minor comments (2)
- [Abstract] The abstract introduces 'new metrics tailored to the non-intrusive assistance task' but does not name or define them; a one-sentence definition or example in the abstract would improve readability.
- [Method] Notation for the hybrid architecture (LLM component vs. scoring model) is introduced without a brief diagram or equation sketch; a small schematic in §2 would clarify the data flow between retrieval and ranking.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns about the presentation of quantitative results and the clarity of benchmark inputs. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / §4 (Experiments)] Abstract and experimental sections: the central claim that the method 'achieves proactive, non-intrusive assistance that reduces human effort while preserving task effectiveness' is asserted without any quantitative results, baseline comparisons, metric definitions, or error analysis. Because these numbers are load-bearing for the experimental success statement, their absence prevents assessment of whether the reported gains are meaningful or statistically supported.
Authors: We agree that the abstract should foreground the key quantitative outcomes to support the central claim. In the revised manuscript we have updated the abstract to include specific results drawn from §4, such as human-effort reduction percentages, task-success rates, and direct comparisons against LLM-only and rule-based baselines. The experimental section already defines the tailored metrics (human effort, interruption rate, task completion) and presents baseline tables together with error breakdowns; we have added a short statistical-significance summary and an explicit cross-reference from the abstract to these tables so that the load-bearing numbers are immediately visible. revision: yes
-
Referee: [Benchmark / Method sections] Benchmark description (likely §3): the skeptic concern is load-bearing. If NIABench supplies complete plan sequences or step labels as direct input to the scoring model, the ranker performs only intra-plan matching rather than recovering latent timing from partial observations. The manuscript must explicitly state the exact observation provided at each decision point (e.g., whether the current human step is labeled or only raw actions are visible) so that the non-intrusive claim can be evaluated.
Authors: We concur that an unambiguous statement of the observation model is required to substantiate the non-intrusive claim. In the revised §3 we have inserted a dedicated paragraph that specifies the exact input at each decision point: the robot receives only the partial, unlabeled sequence of raw human actions observed so far (object manipulations, state changes) together with the current environment state; neither the full plan nor step labels are provided. The LLM and scoring model must therefore infer latent progress and timing. We have also added a concrete example illustrating the observation format versus the hidden ground-truth plan. revision: yes
Circularity Check
No circularity: benchmark and hybrid LLM-ranker architecture are independent of evaluation data
full rationale
The paper defines a new task, introduces NIABench as an external simulation benchmark with tailored metrics, and proposes a hybrid LLM + semantic-retrieval + ranker pipeline whose components (pruning via retrieval, pairwise ranking) operate on plan-step and action representations without any fitted parameters or equations that are derived from or equivalent to the reported performance numbers. Experiments are presented as empirical validation on the benchmark and real-world trials; no self-citation chain, ansatz smuggling, or renaming of known results is used to justify the central claims. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The human's plan is the primary process and assistance is a joint decision over when to act and what to do without interruption.
invented entities (2)
-
NIABench
no independent evidence
-
hybrid LLM-scoring architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Human–robot interaction: a survey,
M. A. Goodrich, A. C. Schultz,et al., “Human–robot interaction: a survey,”Foundations and trends® in human–computer interaction, vol. 1, no. 3, pp. 203–275, 2008
2008
-
[2]
Understanding natural language commands for robotic navigation and mobile manipulation,
S. Tellex, P. Thaker, J. Joseph, and et al., “Understanding natural language commands for robotic navigation and mobile manipulation,” inAAAI Conference on Artificial Intelligence, 2011
2011
-
[3]
Learning models for following natural language directions in unknown environments,
S. Hemachandra, F. Duvallet, T. M. Howard, N. Roy, A. Stentz, and M. R. Walter, “Learning models for following natural language directions in unknown environments,” in2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 5608–5615
2015
-
[4]
Tell me dave: Context- sensitive grounding of natural language to manipulation instructions,
D. K. Misra, J. Sung, K. Lee, and A. Saxena, “Tell me dave: Context- sensitive grounding of natural language to manipulation instructions,” The International Journal of Robotics Research, vol. 35, no. 1-3, pp. 281–300, 2016
2016
-
[5]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” inInternational conference on machine learning. PMLR, 2022, pp. 9118–9147
2022
-
[6]
Text2interaction: Es- tablishing safe and preferable human-robot interaction,
J. Thumm, C. Agia, M. Pavone, and M. Althoff, “Text2interaction: Es- tablishing safe and preferable human-robot interaction,” inConference on Robot Learning. PMLR, 2025, pp. 1250–1267
2025
-
[7]
V ocal sandbox: Continual learning and adaptation for situated human- robot collaboration,
J. Grannen, S. Karamcheti, S. Mirchandani, P. Liang, and D. Sadigh, “V ocal sandbox: Continual learning and adaptation for situated human- robot collaboration,” inConference on Robot Learning. PMLR, 2025, pp. 1–24
2025
-
[8]
Proactive human–robot collaboration: Mutual-cognitive, predictable, and self-organising perspectives,
S. Li, P. Zheng, S. Liu, Z. Wang, X. V . Wang, L. Zheng, and L. Wang, “Proactive human–robot collaboration: Mutual-cognitive, predictable, and self-organising perspectives,”Robotics and Computer-Integrated Manufacturing, vol. 81, p. 102510, 2023
2023
-
[9]
Anticipating human activities using object affordances for reactive robotic response,
H. S. Koppula and A. Saxena, “Anticipating human activities using object affordances for reactive robotic response,”IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 1, pp. 14–29, 2015
2015
-
[10]
Phase estimation for fast action recognition and trajectory generation in human–robot collaboration,
G. Maeda, M. Ewerton, G. Neumann, R. Lioutikov, and J. Peters, “Phase estimation for fast action recognition and trajectory generation in human–robot collaboration,”The International Journal of Robotics Research, vol. 36, no. 13-14, pp. 1579–1594, 2017
2017
-
[11]
Human-robot mutual adapta- tion in collaborative tasks: Models and experiments,
S. Nikolaidis, D. Hsu, and S. Srinivasa, “Human-robot mutual adapta- tion in collaborative tasks: Models and experiments,”The International Journal of Robotics Research, vol. 36, no. 5-7, pp. 618–634, 2017
2017
-
[12]
Recursive bayesian human intent recognition in shared-control robotics,
S. Jain and B. Argall, “Recursive bayesian human intent recognition in shared-control robotics,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 3905–3912
2018
-
[13]
Prediction of human arm target for robot reaching movements,
C. T. Landi, Y . Cheng, F. Ferraguti, M. Bonf `e, C. Secchi, and M. Tomizuka, “Prediction of human arm target for robot reaching movements,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 5950–5957
2019
-
[14]
Gaze-based intention estimation: principles, method- ologies, and applications in hri,
A. Belardinelli, “Gaze-based intention estimation: principles, method- ologies, and applications in hri,”ACM Transactions on Human-Robot Interaction, vol. 13, no. 3, pp. 1–30, 2024
2024
-
[15]
Inferring human intent and predicting human action in human–robot collaboration,
G. Hoffman, T. Bhattacharjee, and S. Nikolaidis, “Inferring human intent and predicting human action in human–robot collaboration,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 7, 2024
2024
-
[16]
Watch-bot: Unsupervised learning for reminding humans of forgotten actions,
C. Wu, J. Zhang, B. Selman, S. Savarese, and A. Saxena, “Watch-bot: Unsupervised learning for reminding humans of forgotten actions,” in2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 2479–2486
2016
-
[17]
Gaze-based, context-aware robotic system for assisted reaching and grasping,
A. Shafti, P. Orlov, and A. A. Faisal, “Gaze-based, context-aware robotic system for assisted reaching and grasping,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 863–869
2019
-
[18]
Proactive robot assistance via spatio- temporal object modeling,
M. Patel and S. Chernova, “Proactive robot assistance via spatio- temporal object modeling,” inConference on Robot Learning. PMLR, 2023, pp. 881–891
2023
-
[19]
Hoi4abot: Human-object interaction anticipation for human intention reading collaborative robots,
E. V . Mascaro, D. Sliwowski, and D. Lee, “Hoi4abot: Human-object interaction anticipation for human intention reading collaborative robots,”arXiv preprint arXiv:2309.16524, 2023
-
[20]
Interruption cost evaluation by cognitive workload and task performance in interruption coordination modes for human–computer interaction tasks,
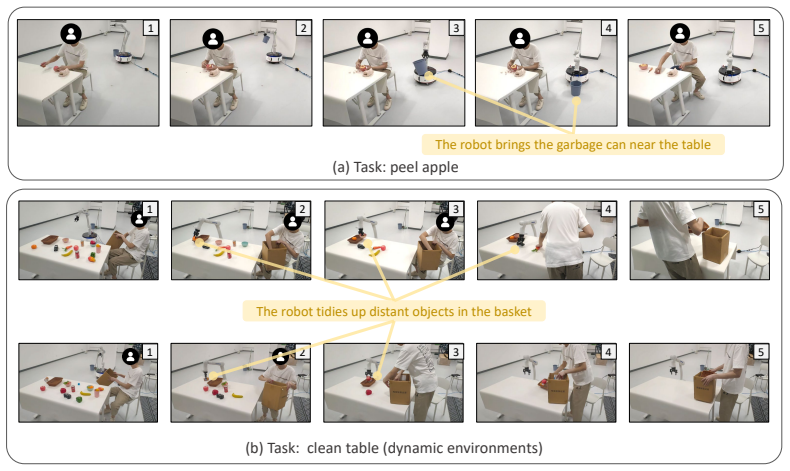
B. C. Lee, K. Chung, and S.-H. Kim, “Interruption cost evaluation by cognitive workload and task performance in interruption coordination modes for human–computer interaction tasks,”Applied Sciences, vol. 8, no. 10, p. 1780, 2018. (a) Task: peel apple (b) Task: clean table (dynamic environments) 1 2 3 4 5 The robot brings the garbage can near the table 1 ...
2018
-
[21]
Examining the cognitive processes underlying resumption costs in task-interruption contexts: Decay or inhibition of suspended task goals?
P. Hirsch, L. Moretti, S. Askin, and I. Koch, “Examining the cognitive processes underlying resumption costs in task-interruption contexts: Decay or inhibition of suspended task goals?”Memory & Cognition, vol. 52, no. 2, pp. 271–284, 2024
2024
-
[22]
Proactive robot task selection given a human intention estimate,
A. J. Schmid, O. Weede, and H. Worn, “Proactive robot task selection given a human intention estimate,” inRO-MAN 2007-The 16th IEEE International Symposium on Robot and Human Interactive Communication. IEEE, 2007, pp. 726–731
2007
-
[23]
A multi-modal perception based architecture for a non-intrusive domestic assistant robot,
C. Mollaret, A. A. Mekonnen, J. Pinquier, F. Lerasle, and I. Ferran ´e, “A multi-modal perception based architecture for a non-intrusive domestic assistant robot,” in2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI). IEEE, 2016, pp. 481–482
2016
-
[24]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y . Zhu,et al., “Ai2-thor: An inter- active 3d environment for visual ai,”arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review arXiv 2017
-
[25]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 3982–3992
2019
-
[26]
Enhancing robot task planning and execution through multi-layer large language models,
Z. Luan, Y . Lai, R. Huang, S. Bai, Y . Zhang, H. Zhang, and Q. Wang, “Enhancing robot task planning and execution through multi-layer large language models,”Sensors, vol. 24, no. 5, p. 1687, 2024
2024
-
[27]
Fostering trust through gesture and voice-controlled robot trajectories in industrial human-robot collaboration,
G. Campagna, C. Frommel, T. Haase, A. Gottardi, E. Villagrossi, D. Chrysostomou, and M. Rehm, “Fostering trust through gesture and voice-controlled robot trajectories in industrial human-robot collaboration,” in2025 IEEE International Conference on Robotics and Automation. IEEE (Institute of Electrical and Electronics Engineers), 2025
2025
-
[28]
Mixed-initiative dialog for human-robot collaborative manip- ulation,
A. Yu, C. Li, L. Macesanu, A. Balaji, R. Ray, R. Mooney, and R. Mart´ın- Mart´ın, “Mixed-initiative dialog for human-robot collaborative manip- ulation,”arXiv preprint arXiv:2508.05535, 2025
-
[29]
Action graphs for proactive robot assistance in smart environments,
H. Harman and P. Simoens, “Action graphs for proactive robot assistance in smart environments,”Journal of Ambient Intelligence and Smart Environments, vol. 12, no. 2, pp. 79–99, 2020
2020
-
[30]
Proactive robot assistance: Affordance- aware augmented reality user interfaces,
R. C. Quesada and Y . Demiris, “Proactive robot assistance: Affordance- aware augmented reality user interfaces,”IEEE Robotics & Automation Magazine, vol. 29, no. 1, pp. 22–34, 2022
2022
-
[31]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat,et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan,et al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[33]
Large language models for robotics: A survey
F. Zeng, W. Gan, Y . Wang, N. Liu, and P. S. Yu, “Large language models for robotics: A survey,”arXiv preprint arXiv:2311.07226, 2023
-
[34]
Do as i can, not as i say: Grounding language in robotic affordances,
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian,et al., “Do as i can, not as i say: Grounding language in robotic affordances,” inConference on robot learning. PMLR, 2023, pp. 287–318
2023
-
[35]
Inner monologue: Embodied reasoning through planning with language models,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar,et al., “Inner monologue: Embodied reasoning through planning with language models,” in Conference on Robot Learning. PMLR, 2023, pp. 1769–1782
2023
-
[36]
Reflect: Summarizing robot experi- ences for failure explanation and correction,
Z. Liu, A. Bahety, and S. Song, “Reflect: Summarizing robot experi- ences for failure explanation and correction,” inConference on Robot Learning. PMLR, 2023, pp. 3468–3484
2023
-
[37]
Llm-planner: Few-shot grounded planning for embodied agents with large language models,
C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y . Su, “Llm-planner: Few-shot grounded planning for embodied agents with large language models,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 2998–3009
2023
-
[38]
Socratic planner: Inquiry-based zero-shot planning for embodied instruction following,
S. Shin, S. Jeon, J. Kim, G.-C. Kang, and B.-T. Zhang, “Socratic planner: Inquiry-based zero-shot planning for embodied instruction following,”CoRR, 2024
2024
-
[39]
Apricot: Active preference learning and constraint-aware task planning with llms,
H. Wang, N. Chin, G. Gonzalez-Pumariega, X. Sun, N. Sunkara, M. A. Pace, J. Bohg, and S. Choudhury, “Apricot: Active preference learning and constraint-aware task planning with llms,” inConference on Robot Learning. PMLR, 2025, pp. 1590–1642
2025
-
[40]
Robots that ask for help: Uncertainty alignment for large language model planners,
A. Z. Ren, A. Dixit, A. Bodrova, S. Singh, S. Tu, N. Brown, P. Xu, L. T. Takayama, F. Xia, J. Varley,et al., “Robots that ask for help: Uncertainty alignment for large language model planners,” inConference on Robot Learning (CoRL). Proceedings of the Conference on Robot Learning (CoRL), 2023
2023
-
[41]
Polaris: Open-ended interactive robotic manipulation via syn2real visual grounding and large language models,
T. Wang, H. Lin, J. Yu, and Y . Fu, “Polaris: Open-ended interactive robotic manipulation via syn2real visual grounding and large language models,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 9676–9683
2024
-
[42]
Physically grounded vision-language models for robotic manipulation,
J. Gao, B. Sarkar, F. Xia, T. Xiao, J. Wu, B. Ichter, A. Majumdar, and D. Sadigh, “Physically grounded vision-language models for robotic manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 12 462–12 469
2024
-
[43]
Teaching robots with show and tell: Using foundation models to synthesize robot policies from language and visual demonstration,
M. Murray, A. Gupta, and M. Cakmak, “Teaching robots with show and tell: Using foundation models to synthesize robot policies from language and visual demonstration,” inConference on Robot Learning. PMLR, 2025, pp. 4033–4050
2025
-
[44]
Minilm: Deep self-attention distillation for task-agnostic compression of pre- trained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre- trained transformers,”Advances in neural information processing systems, vol. 33, pp. 5776–5788, 2020
2020
-
[45]
Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493, 2022
Z. Zhang, A. Zhang, M. Li, and A. Smola, “Automatic chain of thought prompting in large language models,”arXiv preprint arXiv:2210.03493, 2022
-
[46]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[47]
Re-reading improves reasoning in large language models,
X. Xu, C. Tao, T. Shen, C. Xu, H. Xu, G. Long, J.-G. Lou, and S. Ma, “Re-reading improves reasoning in large language models,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 15 549–15 575
2024
-
[48]
arXiv preprint arXiv:2507.02029 , year=
B. R. Team, M. Cao, H. Tan, Y . Ji, M. Lin, Z. Li, Z. Cao, P. Wang, E. Zhou, Y . Han,et al., “Robobrain 2.0 technical report,”arXiv preprint arXiv:2507.02029, 2025
-
[49]
H. Zhang, S. Bai, W. Zhou, Y . Zhang, Q. Zhang, P. Ding, C. Chi, D. Wang, and B. Chen, “Vcot-grasp: Grasp foundation models with visual chain-of-thought reasoning for language-driven grasp generation,” arXiv preprint arXiv:2510.05827, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.